{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 4.4 - Advanced - Word Embeddings (R)\n",
"\n",
"*R Version*\n",
"\n",
"\n",
"\n",
"*This notebook was prepared by Laura Nelson in collaboration with [UBC\n",
"COMET](https://comet.arts.ubc.ca/) team members: Jonathan Graves, Angela\n",
"Chen and Anneke Dresselhuis*\n",
"\n",
"## Prerequisites\n",
"\n",
"1. Some familiarity programming in R\n",
"2. Some familarity with natural language processing\n",
"3. No computational text experience necessary!\n",
"\n",
"## Learning outcomes\n",
"\n",
"In the notebook you will\n",
"\n",
"1. Familiarize yourself with concepts such as word embeddings (WE)\n",
" vector-space model of language, natural language processing (NLP)\n",
" and how they relate to small and large language models (LMs)\n",
"2. Import and pre-process a textual dataset for use in word embedding\n",
"3. Use word2vec to build a simple language model for examining patterns\n",
" and biases textual datasets\n",
"4. Identify and select methods for saving and loading models\n",
"5. Use critical and reflexive thinking to gain a deeper understanding\n",
" of how the inherent social and cultural biases of language are\n",
" reproduced and mapped into language computation models\n",
"\n",
"## Outline\n",
"\n",
"The goal of this notebook is to demystify some of the technical aspects\n",
"of language models and to invite learners to start thinking about how\n",
"these important tools function in society.\n",
"\n",
"In particular, this lesson is designed to explore features of word\n",
"embeddings produced through the word2vec model. The questions we ask in\n",
"this lesson are guided by Ben Schmidt’s blog post, [Rejecting the Gender\n",
"Binary](%22http://bookworm.benschmidt.org/posts/2015-10-30-rejecting-the-gender-binary.html).\n",
"\n",
"The primary corpus we will use consists of the\n",
"150 English-language novels made\n",
"available by the .txtLab at McGill University. We also look at\n",
"a Word2Vec model trained\n",
"on the ECCO-TCP corpus of 2,350 eighteenth-century literary texts\n",
"made available by Ryan Heuser. (Note that the number of terms in the\n",
"model has been shortened by half in order to conserve memory.)\n",
"\n",
"## Key Terms\n",
"\n",
"Before we dive in, feel free to familiarize yourself with the following\n",
"key terms and how they relate to each other."
],
"id": "d3bcd253-d9a3-4381-ab13-dce0115e3b66"
},
{
"cell_type": "raw",
"metadata": {
"raw_mimetype": "text/html"
},
"source": [
""
],
"id": "f3152375-c59d-4ad2-8732-e939246204b8"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
],
"id": "f2065b82-c866-4391-8bdb-0b5c00171337"
},
{
"cell_type": "raw",
"metadata": {
"raw_mimetype": "text/html"
},
"source": [
""
],
"id": "a47de43f-5ef1-4139-917f-0a0885cb18bc"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Artificial Intelligence (AI):** this term is a broad category that\n",
"includes the study and development of computer systems that can copy\n",
"intelligent human behaviour (adapted from [*Oxford Learners\n",
"Dictionary*](https://www.oxfordlearnersdictionaries.com/definition/english/ai#:~:text=%2F%CB%8Ce%C9%AA%20%CB%88a%C9%AA%2F-,%2F%CB%8Ce%C9%AA%20%CB%88a%C9%AA%2F,way%20a%20human%20brain%20does.))\n",
"\n",
"**Machine Learning (ML):** this is branch of AI which is uses\n",
"statistical methods to imitate the way that humans learn (adapted from\n",
"[*IBM*](https://www.ibm.com/topics/machine-learning))\n",
"\n",
"**Natural Language Processing (NLP):** this is branch of AI which\n",
"focuses on training computers to interpret human text and spoken words\n",
"(adapted from\n",
"[*IBM*](https://www.ibm.com/topics/natural-language-processing#:~:text=the%20next%20step-,What%20is%20natural%20language%20processing%3F,same%20way%20human%20beings%20can.))\n",
"\n",
"**Word Embeddings (WE):** this is an NLP process through which human\n",
"words are converted into numerical representations (usually vectors) in\n",
"order for computers to be able to understand them (adapted from\n",
"[*Turing*](https://www.turing.com/kb/guide-on-word-embeddings-in-nlp))\n",
"\n",
"**word2vec:** this is an NLP technique that is commonly used to generate\n",
"word embeddings\n",
"\n",
"## What are Word Embeddings?\n",
"\n",
"Building off of the definition above, word embeddings are one way that\n",
"humans can represent language in a way that is legible to a machine.\n",
"More specifically, they are an NLP approach that use vectors to store\n",
"textual data in multiple dimensions; by existing in the\n",
"multi-dimensional space of vectors, word embeddings are able to include\n",
"important semantic information within a given numeric representation.\n",
"\n",
"For example, if we are trying to answer a research question about how\n",
"popular a term is on the web at a given time, we might use a simple word\n",
"frequency analysis to count how many times the word “candidate” shows up\n",
"in tweets during a defined electoral period. However, if we wanted to\n",
"gain a more nuanced understanding of what kind of language, biases or\n",
"attitudes contextualize the term, “candidate” in discourse, we would\n",
"need to use a method like word embedding to encode meaning into our\n",
"understanding of how people have talked about candidates over time.\n",
"Instead of describing our text as a series of word counts, we would\n",
"treat our text like coordinates in space, where similar words and\n",
"concepts are closer to each other, and words that are different from\n",
"each other are further away.\n",
"\n",
"\n",
"\n",
"Comparing word frequency count and word\n",
"embedding methods\n",
"\n",
"\n",
"For example, in the visualization above, a word frequency count returns\n",
"the number of times the word “candidate” or “candidates” is used in a\n",
"sample text corpus. When a word embedding is made from the same text\n",
"corpus, we are able to map related concepts and phrases that are closely\n",
"related to “candidate” as neighbours, while other words and phrases such\n",
"as “experimental study” (which refers to the research paper in question,\n",
"and not to candidates specifically) are further away.\n",
"\n",
"Here is another example of how different, but related words might be\n",
"represented in a word embedding: \n",
"\n",
"## Making a Word Embedding\n",
"\n",
"So, how do word embeddings work? To make a word embedding, an input word\n",
"gets compressed into a dense vector.\n",
"\n",
"\n",
"\n",
"Creating a word embedding\n",
"vector\n",
"\n",
"\n",
"The magic and mystery of the word embedding process is that often the\n",
"vectors produced during the model embed qualities of a word or phrase\n",
"that are not interpretable by humans. However, for our purposes, having\n",
"the text in vector format is all we need. With this format, we can\n",
"perform tests like cosine similarity and other kinds of operations. Such\n",
"operations can reveal many different kinds of relationships between\n",
"words, as we’ll examine a bit later.\n",
"\n",
"## Using word2vec\n",
"\n",
"Word2vec is one NLP technique that is commonly used to generate word\n",
"embeddings. More precisely, word2vec is an algorithmic learning tool\n",
"rather than a specific neural net that is already trained. The example\n",
"we will be working through today has been made using this tool.\n",
"\n",
"The series of algorithms inside of the word2vec model try to describe\n",
"and acquire parameters for a given word in terms of the text that appear\n",
"immediately to the right and left in actual sentences. Essentially, it\n",
"learns how to predict text.\n",
"\n",
"Without going too deep into the algorithm, suffice it to say that it\n",
"involves a two-step process:\n",
"\n",
"1. First, the input word gets compressed into a dense vector, as seen\n",
" in the simplified diagram, “Creating a Word Embedding,” above.\n",
"2. Second, the vector gets decoded into the set of context words.\n",
" Keywords that appear within similar contexts will have similar\n",
" vector representations in between steps.\n",
"\n",
"Imagine that each word in a novel has its meaning determined by the ones\n",
"that surround it in a limited window. For example, in Moby Dick’s first\n",
"sentence, “me” is paired on either side by “Call” and “Ishmael.” After\n",
"observing the windows around every word in the novel (or many novels),\n",
"the computer will notice a pattern in which “me” falls between similar\n",
"pairs of words to “her,” “him,” or “them.” Of course, the computer had\n",
"gone through a similar process over the words “Call” and “Ishmael,” for\n",
"which “me” is reciprocally part of their contexts. This chaining of\n",
"signifiers to one another mirrors some of humanists’ most sophisticated\n",
"interpretative frameworks of language.\n",
"\n",
"The two main model architectures of word2vec are **Continuous Bag of\n",
"Words (CBOW)** and **Skip-Gram**, which can be distinguished partly by\n",
"their input and output during training.\n",
"\n",
"**CBOW** takes the context words (for example, “Call”,“Ishmael”) as a\n",
"single input and tries to predict the word of interest (“me”).\n",
"\n",
"\n",
"\n",
"**Skip-Gram** does the opposite, taking a word of interest as its input\n",
"(for example, “me”) and tries to learn how to predict its context words\n",
"(“Call”,“Ishmael”).\n",
"\n",
"\n",
"\n",
"In general, CBOW is is faster and does well with frequent words, while\n",
"Skip-Gram potentially represents rare words better.\n",
"\n",
"Since the word embedding is a vector, we are able perform tests like\n",
"cosine similarity (which we’ll learn more about in a bit!) and other\n",
"kinds of operations. Those operations can reveal many different kinds of\n",
"relationships between words, as we shall see.\n",
"\n",
"## Bias and Language Models\n",
"\n",
"You might already be piecing together that the encoding of meaning in\n",
"word embeddings is entirely shaped by patterns of language use captured\n",
"in the training data. That is, what is included in a word embedding\n",
"directly reflects the complex social and cultural biases of everyday\n",
"human language - in fact, exploring how these biases function and change\n",
"over time (as we will do later) is one of the most interesting ways to\n",
"use word embeddings in social research.\n",
"\n",
"#### It is simply impossible to have a bias-free language model (LM).\n",
"\n",
"In LMs, bias is not a bug or a glitch, rather, it is an essential\n",
"feature that is baked into the fundamental structure. For example, LMs\n",
"are not outside of learning and absorbing the pejorative dimensions of\n",
"language which in turn, can result in reproducing harmful correlations\n",
"of meaning for words about race, class or gender (among others). When\n",
"unchecked, these harms can be “amplified in downstream applications of\n",
"word embeddings” ([Arseniev-Koehler & Foster, 2020,\n",
"p. 1](https://osf.io/preprints/socarxiv/b8kud/)).\n",
"\n",
"Just like any other computational model, it is important to critically\n",
"engage with the source and context of the training data. One way that\n",
"[Schiffers, Kern and Hienert](https://arxiv.org/abs/2302.06174v1)\n",
"suggest doing this is by using domain specific models (2023). Working\n",
"with models that understand the nuances of your particular topic or\n",
"field can better account for “specialized vocabulary and semantic\n",
"relationships” that can help make applications of WE more effective.\n",
"\n",
"## Preparing for our Analysis\n",
"\n",
"#### Word2vec Features\n",
"\n",
"**Here are a few features of the word2vec tool that we can use to\n",
"customize our analysis:**\n",
"\n",
"- `size`: Number of dimensions for word embedding model\n",
" \n",
"- `window`: Number of context words to observe in each direction\n",
" \n",
"- `min_count`: Minimum frequency for words included in model\n",
" \n",
"- `sg` (Skip-Gram): ‘0’ indicates CBOW model; ‘1’ indicates Skip-Gram\n",
" \n",
"- `alpha`: Learning rate (initial); prevents model from\n",
" over-correcting, enables finer tuning\n",
" \n",
"- `iterations`: Number of passes through dataset\n",
" \n",
"- `batch size`: Number of words to sample from data during each pass\n",
" \n",
"\n",
"Note: the script uses default value for each argument.\n",
"\n",
"**Some limitations of the word2vec Model**\n",
"\n",
"- Within word2vec, common articles or conjunctions, called **stop\n",
" words** such as “the” and “and,” may not provide very rich\n",
" contextual information for a given word, and may need additional\n",
" subsampling or to be combined into a word phrase (Anwla, 2019).\n",
"- Word2vec isn’t always the best at handling out-of-vocabulary words\n",
" well (Chandran, 2021).\n",
"\n",
"Let’s begin our analysis!\n",
"\n",
"## Exercise #1: Eggs, Sausages and Bacon\n",
"\n",
"\n",
"\n",
"To begin, we are going to install and load a few packages that are\n",
"necessary for our analysis. Run the code cells below if these packages\n",
"are not already installed:\n",
"\n",
"``` r\n",
"# uncomment these by deleting the \"#\" to install them\n",
"\n",
"#install.packages(\"tidyverse\")\n",
"#install.packages(\"repr\")\n",
"#install.packages(\"proxy\")\n",
"#install.packages(\"scales\")\n",
"#install.packages(\"tm\")\n",
"#install.packages(\"MASS\")\n",
"#install.packages(\"SentimentAnalysis\")\n",
"#install.packages(\"reticulate\")\n",
"```\n",
"\n",
"``` r\n",
"# Load the required libraries\n",
"library(tidyverse)\n",
"library(repr)\n",
"library(proxy)\n",
"library(tm)\n",
"library(scales)\n",
"library(MASS)\n",
"\n",
"\n",
"# Set up figures to save properly\n",
"options(jupyter.plot_mimetypes = \"image/png\") \n",
"```\n",
"\n",
"``` r\n",
"# Time: 30s\n",
"library(reticulate)\n",
"gensim <- import(\"gensim\")\n",
"```\n",
"\n",
"#### Create a Document-Term Matrix (DTM) with a Few Pseudo-Texts\n",
"\n",
"To start off, we’re going to create a mini dataframe based on the use of\n",
"the words “eggs,” “sausages” and “bacon” found in three different\n",
"novels: A, B and C.\n",
"\n",
"``` r\n",
"# Construct dataframe\n",
"columns <- c('eggs', 'sausage', 'bacon')\n",
"indices <- c('Novel A', 'Novel B', 'Novel C')\n",
"dtm <- data.frame(eggs = c(50, 90, 20),\n",
" sausage = c(60, 10, 70),\n",
" bacon = c(60, 10, 70),\n",
" row.names = indices)\n",
"\n",
"# Show dataframe\n",
"print(dtm)\n",
"```\n",
"\n",
"#### Visualize\n",
"\n",
"``` r\n",
"# Then, we'll create the scatter plot of our data using ggplot2\n",
"ggplot(dtm, aes(x = eggs, y = sausage)) +\n",
" geom_point() +\n",
" geom_text(aes(label = rownames(dtm)), nudge_x = 2, nudge_y = 2, size = 3) +\n",
" xlim(0, 100) +\n",
" ylim(0, 100) +\n",
" labs(x = \"eggs\", y = \"sausage\")\n",
"```\n",
"\n",
"### Vectors\n",
"\n",
"At a glance, a couple of points are lying closer to one another. We used\n",
"the word frequencies of just two words in order to plot our texts in a\n",
"two-dimensional plane. The term frequency “summaries” of Novel A\n",
"& Novel C are pretty similar to one another: they both share a\n",
"major concern with “sausage”, whereas Novel B seems to focus\n",
"primarily on “eggs.”\n",
"\n",
"This raises a question: how can we operationalize our intuition that\n",
"spatial distance expresses topical similarity?\n",
"\n",
"## Cosine Similarity\n",
"\n",
"The most common measurement of distance between points is their [Cosine\n",
"Similarity](https://en.wikipedia.org/wiki/Cosine_similarity). Cosine\n",
"similarity can operate on textual data that contain word vectors and\n",
"allows us to identify how similar documents are to each other, for\n",
"example. Cosine Similarity thus helps us understand how much content\n",
"overlap a set of documents have with one another. For example, imagine\n",
"that we were to draw an arrow from the origin of the graph - point\n",
"(0,0) - to the dot representing each text. This arrow is called a\n",
"*vector*.\n",
"\n",
"Mathematically, this can be represented as:\n",
"\n",
"\n",
"\n",
"Using our example above, we can see that the angle from (0,0) between\n",
"Novel C and Novel A (orange triangle) is smaller than between Novel A\n",
"and Novel B (navy triangle) or between Novel C and Novel B (both\n",
"triangles together).\n",
"\n",
"\n",
"\n",
"Because this similarity measurement uses the cosine of the angle between\n",
"vectors, the magnitude is not a matter of concern (this feature is\n",
"really helpful for text vectors that can often be really long!).\n",
"Instead, the output of cosine similarity yields a value between 0 and 1\n",
"(we don’t have to work with something confusing like 18º!) that can be\n",
"easily interpreted and compared - and thus we can also avoid the\n",
"troubles associated with other dimensional distance measures such as\n",
"[Euclidean Distance](https://en.wikipedia.org/wiki/Euclidean_distance).\n",
"\n",
"### Calculating Cosine Distance\n",
"\n",
"``` r\n",
"# Assuming dtm_df is a data frame containing the document-term matrix\n",
"dtm_matrix <- as.matrix(dtm)\n",
"\n",
"# Calculate cosine similarity\n",
"cos_sim <- proxy::dist(dtm_matrix, method = \"cosine\")\n",
"\n",
"\n",
"# Although we want the Cosine Distance, it is mathematically simpler to calculate its opposite: Cosine Similarity\n",
"# The formula for Cosine Distance is = 1 - Cosine Similarity\n",
"\n",
"# Convert the cosine similarity matrix to a 2-dimensional array\n",
"# So we will subtract the similarities from 1\n",
"n <- nrow(dtm_matrix)\n",
"cos_sim_array <- matrix(1 - as.vector(as.matrix(cos_sim)), n, n)\n",
"\n",
"# Print the result\n",
"print(cos_sim_array)\n",
"```\n",
"\n",
"``` r\n",
"# Make it a little easier to read by rounding the values\n",
"cos_sim_rounded <- round(cos_sim_array, 2)\n",
"\n",
"# Label the dataframe rows and columns with eggs, sausage and bacon\n",
"cos_df <- data.frame(cos_sim_rounded, row.names = indices, check.names = FALSE)\n",
"colnames(cos_df) <- indices\n",
"\n",
"# Print the data frame\n",
"head(cos_df)\n",
"```\n",
"\n",
"## Exercise #2: Working with 18th Century Literature\n",
"\n",
"\n",
"\n",
"Workshop Run Here at Start\n",
"\n",
"``` r\n",
"# Load the required libraries\n",
"library(tidyverse)\n",
"library(repr)\n",
"library(proxy)\n",
"library(tm)\n",
"library(scales)\n",
"library(MASS)\n",
"\n",
"\n",
"# Set up figures to save properly\n",
"options(jupyter.plot_mimetypes = \"image/png\") \n",
"\n",
"# Time: 3 mins\n",
"# File paths and names\n",
"filelist <- c(\n",
" 'txtlab_Novel450_English/EN_1850_Hawthorne,Nathaniel_TheScarletLetter_Novel.txt',\n",
" 'txtlab_Novel450_English/EN_1851_Hawthorne,Nathaniel_TheHouseoftheSevenGables_Novel.txt',\n",
" 'txtlab_Novel450_English/EN_1920_Fitzgerald,FScott_ThisSideofParadise_Novel.txt',\n",
" 'txtlab_Novel450_English/EN_1922_Fitzgerald,FScott_TheBeautifulandtheDamned_Novel.txt',\n",
" 'txtlab_Novel450_English/EN_1811_Austen,Jane_SenseandSensibility_Novel.txt',\n",
" 'txtlab_Novel450_English/EN_1813_Austen,Jane_PrideandPrejudice_Novel.txt'\n",
")\n",
"\n",
"novel_names <- c(\n",
" 'Hawthorne: Scarlet Letter',\n",
" 'Hawthorne: Seven Gables',\n",
" 'Fitzgerald: This Side of Paradise',\n",
" 'Fitzgerald: Beautiful and the Damned',\n",
" 'Austen: Sense and Sensibility',\n",
" 'Austen: Pride and Prejudice'\n",
")\n",
"\n",
"# Function to read non-empty lines from the text file\n",
"readNonEmptyLines <- function(filepath) {\n",
" lines <- readLines(filepath, encoding = \"UTF-8\")\n",
" non_empty_lines <- lines[trimws(lines) != \"\"]\n",
" return(paste(non_empty_lines, collapse = \" \"))\n",
"}\n",
"\n",
"# Read non-empty texts into a corpus\n",
"text_corpus <- VCorpus(VectorSource(sapply(filelist, readNonEmptyLines)))\n",
"\n",
"# Preprocess the text data\n",
"text_corpus <- tm_map(text_corpus, content_transformer(tolower))\n",
"text_corpus <- tm_map(text_corpus, removePunctuation)\n",
"text_corpus <- tm_map(text_corpus, removeNumbers)\n",
"text_corpus <- tm_map(text_corpus, removeWords, stopwords(\"english\"))\n",
"text_corpus <- tm_map(text_corpus, stripWhitespace)\n",
"\n",
"## Time: 5 mins\n",
"# Create a custom control for DTM with binary term frequency\n",
"custom_control <- list(\n",
" tokenize = function(x) SentimentAnalysis::ngram_tokenize(x, ngmax = 1),\n",
" bounds = list(global = c(3, Inf)),\n",
" weighting = weightTf\n",
")\n",
"\n",
"# Convert the corpus to a DTM using custom control\n",
"dtm <- DocumentTermMatrix(text_corpus, control = custom_control)\n",
"\n",
"# Convert DTM to a binary data frame (0 or 1)\n",
"dtm_df_novel <- as.data.frame(as.matrix(dtm > 0))\n",
"colnames(dtm_df_novel) <- colnames(dtm)\n",
"\n",
"# Set row names to novel names\n",
"rownames(dtm_df_novel) <- novel_names\n",
"\n",
"# Print the resulting data frame\n",
"tail(dtm_df_novel)\n",
"```\n",
"\n",
"``` r\n",
"# Just as we did above with the small data frame, we'll find the cosine similarity for these texts\n",
"cos_sim_novel <- as.matrix(proxy::dist(dtm_df_novel, method = \"cosine\"))\n",
"\n",
"# Convert the cosine similarity matrix to a 2-dimensional array\n",
"n <- nrow(dtm_df_novel)\n",
"cos_sim_array <- matrix(1 - as.vector(as.matrix(cos_sim_novel)), n, n)\n",
"\n",
"# Round the cosine similarity matrix to two decimal places\n",
"cos_sim_novel_rounded <- round(cos_sim_array, 2)\n",
"\n",
"# Print the rounded cosine similarity matrix\n",
"print(cos_sim_novel_rounded)\n",
"```\n",
"\n",
"``` r\n",
"# Again, we'll make this a bit more readable\n",
"cos_df <- data.frame(cos_sim_novel_rounded, row.names = novel_names, check.names = FALSE)\n",
"\n",
"# Set column names to novel names\n",
"colnames(cos_df) <- novel_names\n",
"\n",
"# Print the DataFrame\n",
"head(cos_df)\n",
"```\n",
"\n",
"``` r\n",
"# Transform cosine similarity to cosine distance\n",
"cos_dist <- 1 - cos_sim_novel_rounded\n",
"\n",
"# Perform MDS\n",
"mds <- cmdscale(cos_dist, k = 2)\n",
"\n",
"# Extract x and y coordinates from MDS output\n",
"xs <- mds[, 1]\n",
"ys <- mds[, 2]\n",
"\n",
"# Create a data frame with x, y coordinates, and novel names\n",
"mds_df <- data.frame(x = xs, y = ys, novel_names = novel_names)\n",
"\n",
"ggplot(mds_df, aes(x, y, label = novel_names)) +\n",
" geom_point(size = 4) +\n",
" geom_text(hjust =0.6, vjust = 0.2, size = 4, angle = 45, nudge_y = 0.01) + # Rotate text and adjust y position\n",
" labs(title = \"MDS Visualization of Novel Differences\") +\n",
" theme_minimal() +\n",
" theme(\n",
" plot.title = element_text(size = 20, hjust = 0.6, margin = margin(b = 10)),\n",
" plot.margin = margin(5, 5, 5, 5, \"pt\"), # Adjust the margin around the plot\n",
" plot.background = element_rect(fill = \"white\"), # Set the background color of the plot to white\n",
" plot.caption = element_blank(), # Remove the default caption\n",
" axis.text = element_text(size = 12), # Adjust the size of axis text\n",
" legend.text = element_text(size = 12), # Adjust the size of legend text\n",
" legend.title = element_text(size = 14) # Adjust the size of legend title\n",
" )\n",
"```\n",
"\n",
"The above method has a broad range of applications, such as unsupervised\n",
"clustering. Common techniques include\n",
"K-Means\n",
"Clustering and\n",
"Hierarchical\n",
"Dendrograms. These attempt to identify groups of texts with shared\n",
"content, based on these kinds of distance measures.\n",
"\n",
"Here’s an example of a dendrogram based on these six novels:\n",
"\n",
"``` r\n",
"# Assuming you have already calculated the \"cos_dist\" matrix and have the \"novel_names\" vector\n",
"\n",
"# Perform hierarchical clustering\n",
"hclust_result <- hclust(as.dist(cos_dist), method = \"ward.D\")\n",
"\n",
"# Plot the dendrogram\n",
"plot(hclust_result, hang = -1, labels = novel_names)\n",
"\n",
"# Optional: Adjust the layout to avoid cutoff labels\n",
"par(mar = c(5, 4, 2, 10)) # Adjust margins\n",
"\n",
"# Display the dendrogram plot\n",
"```\n",
"\n",
"#### Vector Semantics\n",
"\n",
"We can also turn this logic on its head. Rather than produce vectors\n",
"representing texts based on their words, we will produce vectors for the\n",
"words based on their contexts.\n",
"\n",
"``` r\n",
"# Transpose the DTM data frame\n",
"transposed_dtm <- t(dtm_df_novel)\n",
"\n",
"# Display the first few rows of the transposed DTM\n",
"tail(transposed_dtm)\n",
"```\n",
"\n",
"Because the number of words is so large, for memory reasons we’re going\n",
"to work with just the last few, pictured above.\n",
"\n",
"- If you are running this locally, you may want to try this with more\n",
" words\n",
"\n",
"``` r\n",
"# Assuming dtm_df is a data frame containing the document-term matrix\n",
"tail_transposed_dtm <- tail(transposed_dtm)\n",
"\n",
"dtm_matrix <- as.matrix(tail_transposed_dtm) #remove 'tail_' to use all words\n",
"\n",
"# Calculate cosine similarity\n",
"cos_sim_words <- proxy::dist(dtm_matrix, method = \"cosine\")\n",
"\n",
"# Convert the cosine similarity matrix to a 2-dimensional array\n",
"n <- nrow(dtm_matrix)\n",
"cos_sim_words <- matrix(1 - as.vector(as.matrix(cos_sim_words)), n, n)\n",
"\n",
"# Print the result\n",
"head(cos_sim_words)\n",
"```\n",
"\n",
"``` r\n",
"# In readable format\n",
"\n",
"cos_sim_words <- data.frame(round(cos_sim_words, 2))\n",
"row.names(cos_sim_words) <- row.names(tail_transposed_dtm) #remove tail_ for all\n",
"colnames(cos_sim_words) <- row.names(tail_transposed_dtm) #remove tail_ for all\n",
"\n",
"head(cos_sim_words)\n",
"```\n",
"\n",
"Theoretically we could visualize and cluster these as well - but it\n",
"would a lot of computational power!\n",
"\n",
"We’ll instead turn to the machine learning version: word embeddings\n",
"\n",
"``` r\n",
"#check objects in memory; delete the big ones\n",
"\n",
"sort(sapply(ls(), function(x) format(object.size(get(x)), unit = 'auto')))\n",
" \n",
"rm(cos_sim_words, cos_sim_array, text_corpus, dtm_df_novel)\n",
" \n",
"sort(sapply(ls(), function(x) format(object.size(get(x)), unit = 'auto')))\n",
"```\n",
"\n",
"## Exercise #3: Using Word2vec with 150 English Novels\n",
"\n",
"In this exercise, we’ll use an English-language subset from a dataset\n",
"about novels created by [Andrew\n",
"Piper](https://www.mcgill.ca/langlitcultures/andrew-piper). Specifically\n",
"we’ll look at 150 novels by British and American authors spanning the\n",
"years 1771-1930. These texts reside on disk, each in a separate\n",
"plaintext file. Metadata is contained in a spreadsheet distributed with\n",
"the novel files.\n",
"\n",
"#### Metadata Columns\n",
"\n",
"\n",
"\n",
"
\n",
"\n",
"Filename: Name of file on disk\n",
"\n",
"
\n",
"\n",
"
\n",
"\n",
"ID: Unique ID in Piper corpus\n",
"\n",
"
\n",
"\n",
"
\n",
"\n",
"Language: Language of novel\n",
"\n",
"
\n",
"\n",
"Length: Number of tokens in novel\n",
"\n",
"
\n",
"\n",
"\n",
"\n",
"#### Import Metadata\n",
"\n",
"``` r\n",
"# Import Metadata into Dataframe\n",
"meta_df <- read.csv('resources/txtlab_Novel450_English.csv', encoding = 'UTF-8')\n",
"```\n",
"\n",
"``` r\n",
"# Check Metadata\n",
"head(meta_df)\n",
"```\n",
"\n",
"#### Import Corpus\n",
"\n",
"``` r\n",
"# Set the path to the 'fiction_folder'\n",
"fiction_folder <- \"txtlab_Novel450_English/\"\n",
"\n",
"# Create a list to store the file paths\n",
"file_paths <- list.files(fiction_folder, full.names = TRUE)\n",
"\n",
"# Read all the files as a list of single strings\n",
"novel_list <- lapply(file_paths, function(filepath) {\n",
" readChar(filepath, file.info(filepath)$size)\n",
"})\n",
"```\n",
"\n",
"``` r\n",
"# Inspect first item in novel_list\n",
"cat(substr(novel_list[[1]], 1, 500))\n",
"```\n",
"\n",
"#### Pre-Processing\n",
"\n",
"Word2Vec learns about the relationships among words by observing them in\n",
"context. This means that we want to split our texts into word-units.\n",
"However, we want to maintain sentence boundaries as well, since the last\n",
"word of the previous sentence might skew the meaning of the next\n",
"sentence.\n",
"\n",
"Since novels were imported as single strings, we’ll first need to divide\n",
"them into sentences, and second, we’ll split each sentence into its own\n",
"list of words.\n",
"\n",
"``` r\n",
"# Define a regular expression pattern for sentence splitting\n",
"sentence_pattern <- \"[^.!?]+(? 0]\n",
"```\n",
"\n",
"``` r\n",
"# Inspect first sentence\n",
"\n",
"first_sentence_tokens <- words_by_sentence[[1]]\n",
"print(first_sentence_tokens)\n",
"```\n",
"\n",
"## Training\n",
"\n",
"To train the model we can use this code\n",
"\n",
"``` r\n",
"# Time: 3 mins\n",
"# Train word2vec model from txtLab corpus\n",
"\n",
"model <- gensim$models$Word2Vec(words_by_sentence, vector_size=100L, window=5L, min_count=25L, sg=1L, alpha=0.025, epochs=5L, batch_words=10000L)\n",
"```\n",
"\n",
"However, this is both very slow and very memory instensive. Instead, we\n",
"will short-cut here to load the saved results instead:\n",
"\n",
"``` r\n",
"# Load pre-trained model word2vec model from txtLab corpus\n",
"model <- gensim$models$KeyedVectors$load_word2vec_format('resources/word2vec.txtlab_Novel150_English.txt')\n",
"model$wv <- gensim$models$KeyedVectors$load_word2vec_format('resources/word2vec.txtlab_Novel150_English.txt')\n",
"```\n",
"\n",
"## Embeddings\n",
"\n",
"> Note: the output here is different than the Python version, even\n",
"> though the model is using the same parameters and same input, which is\n",
"> *sentences*\n",
"\n",
"This create a 100-dimension representation of specific words in the text\n",
"corpus. This is a *dense* vector, meaning all of the valaues are\n",
"(usually) non-zero.\n",
"\n",
"``` r\n",
"# Return dense word vector\n",
"vector <- model$wv$get_vector(\"whale\")\n",
"\n",
"data.frame(dimension = 1:100, value = vector)\n",
"```\n",
"\n",
"## Vector-Space Operations\n",
"\n",
"The key advantage of the word-embedding is the dense vector\n",
"representations of words: these allow us to do *operations* on those\n",
"words, which are informative for learning about how those words are\n",
"used.\n",
"\n",
"- This is also where the connection with LLM is created: they use\n",
" these vectors to inform *predictions* about sequences of words (and\n",
" sentences, in more complex models)\n",
"\n",
"### Similarity\n",
"\n",
"Since words are represented as dense vectors, we can ask how similiar\n",
"words’ meanings are based on their cosine similarity (essentially how\n",
"much they overlap). gensim has a few out-of-the-box functions\n",
"that enable different kinds of comparisons.\n",
"\n",
"``` r\n",
"# Find cosine distance between two given word vectors\n",
"\n",
"similarity <- model$wv$similarity(\"pride\", \"prejudice\")\n",
"similarity\n",
"```\n",
"\n",
"``` r\n",
"# Find nearest word vectors by cosine distance\n",
"\n",
"most_similar <- model$wv$most_similar(\"pride\")\n",
"most_similar\n",
"```\n",
"\n",
"``` r\n",
"# Given a list of words, we can ask which doesn't belong\n",
"\n",
"# Finds mean vector of words in list\n",
"# and identifies the word further from that mean\n",
"\n",
"doesnt_match <- model$wv$doesnt_match(c('pride', 'prejudice', 'whale'))\n",
"doesnt_match\n",
"```\n",
"\n",
"## Multiple Valences\n",
"\n",
"A word embedding may encode both primary and secondary meanings that are\n",
"both present at the same time. In order to identify secondary meanings\n",
"in a word, we can subtract the vectors of primary (or simply unwanted)\n",
"meanings. For example, we may wish to remove the sense of river\n",
"bank from the word bank. This would be written\n",
"mathetmatically as RIVER - BANK, which in gensim’s\n",
"interface lists RIVER as a positive meaning and BANK\n",
"as a negative one.\n",
"\n",
"``` r\n",
"# Get most similar words to BANK, in order\n",
"# to get a sense for its primary meaning\n",
"\n",
"most_similar <- model$wv$most_similar(\"bank\")\n",
"most_similar\n",
"```\n",
"\n",
"``` r\n",
"# Remove the sense of \"river bank\" from \"bank\" and see what is left\n",
"\n",
"result <- model$wv$most_similar(positive = \"bank\", negative = \"river\")\n",
"\n",
"result\n",
"```\n",
"\n",
"## Analogy\n",
"\n",
"Analogies are rendered as simple mathematical operations in vector\n",
"space. For example, the canonic word2vec analogy MAN is to KING as\n",
"WOMAN is to ?? is rendered as KING - MAN + WOMAN. In the\n",
"gensim interface, we designate KING and WOMAN as\n",
"positive terms and MAN as a negative term, since it is\n",
"subtracted from those.\n",
"\n",
"``` r\n",
"# Get most similar words to KING, in order\n",
"# to get a sense for its primary meaning\n",
"\n",
"most_similar <- model$wv$most_similar(\"king\")\n",
"most_similar\n",
"```\n",
"\n",
"``` r\n",
"# The canonic word2vec analogy: King - Man + Woman -> Queen\n",
"\n",
"result <- model$wv$most_similar(positive = c(\"woman\", \"king\"), negative = \"man\")\n",
"result\n",
"```\n",
"\n",
"### Gendered Vectors\n",
"\n",
"Can we find gender a la Schmidt (2015)? (Note that this method uses\n",
"vector projection, whereas Schmidt had used rejection.)\n",
"\n",
"``` r\n",
"# Feminine Vector\n",
"\n",
"result <- model$wv$most_similar(positive = c(\"she\", \"her\", \"hers\", \"herself\"), negative = c(\"he\", \"him\", \"his\", \"himself\"))\n",
"result\n",
"```\n",
"\n",
"``` r\n",
"# Masculine Vector\n",
"\n",
"result <- model$wv$most_similar(positive = c(\"he\", \"him\", \"his\", \"himself\"), negative = c(\"she\", \"her\", \"hers\", \"herself\"))\n",
"result\n",
"```\n",
"\n",
"## Visualization\n",
"\n",
"``` r\n",
"# Note: due to some discrepencies between Python and R, this may not be translated exactly\n",
"# Dictionary of words in model\n",
"\n",
"key_to_index <- model$wv$key_to_index #this stores the index of each word in the model\n",
"\n",
"head(key_to_index)\n",
"```\n",
"\n",
"``` r\n",
"# Visualizing the whole vocabulary would make it hard to read\n",
"\n",
"key_to_index <- model$wv$key_to_index\n",
"\n",
"# Get the number of unique words in the vocabulary (vocabulary size)\n",
"vocabulary_size <- length(key_to_index)\n",
"\n",
"# Find most similar tokens\n",
"similarity_result <- model$wv$most_similar(positive = c(\"she\", \"her\", \"hers\", \"herself\"),\n",
" negative = c(\"he\", \"him\", \"his\", \"himself\"),\n",
" topn = as.integer(50)) # Convert to integer\n",
"\n",
"# Extract tokens from the result\n",
"her_tokens <- sapply(similarity_result, function(item) item[1])\n",
"```\n",
"\n",
"``` r\n",
"her_tokens_first_15 <- her_tokens[1:15]\n",
"\n",
"# Inspect list\n",
"her_tokens_first_15\n",
"```\n",
"\n",
"``` r\n",
"# Get the vector for each sampled word\n",
"\n",
"for (i in 1:length(her_tokens)){\n",
" \n",
" if (i == 1) { vectors_matrix <- model$wv$get_vector(i) } else {\n",
" vectors_matrix <- rbind(vectors_matrix, model$wv$get_vector(i))\n",
" } \n",
" \n",
"}\n",
"\n",
"# Print the vectors matrix\n",
"head(vectors_matrix, n = 5) \n",
"```\n",
"\n",
"``` r\n",
"# Calculate distances among texts in vector space\n",
"\n",
"dist_matrix <- as.matrix(proxy::dist(vectors_matrix, by_rows = TRUE, method = \"cosine\"))\n",
"\n",
"# Print the distance matrix\n",
"head(dist_matrix, n = 5)\n",
"```\n",
"\n",
"``` r\n",
"# Multi-Dimensional Scaling (Project vectors into 2-D)\n",
"\n",
"\n",
"# Perform Multi-Dimensional Scaling (MDS)\n",
"mds <- cmdscale(dist_matrix, k = 2)\n",
"\n",
"# Print the resulting MDS embeddings\n",
"head(mds)\n",
"```\n",
"\n",
"``` r\n",
"plot_data <- data.frame(x = mds[, 1], y = mds[, 2], label = unlist(her_tokens))\n",
"\n",
"\n",
"# Create the scatter plot with text labels using ggplot2\n",
"p <- ggplot(plot_data, aes(x = x, y = y, label = label)) +\n",
" geom_point(alpha = 0) +\n",
" geom_text(nudge_x = 0.02, nudge_y = 0.02) +\n",
" theme_minimal()\n",
"\n",
"# Print the plot\n",
"print(p)\n",
"```\n",
"\n",
"``` r\n",
"# For comparison, here is the same graph using a masculine-pronoun vector\n",
"\n",
"# Find most similar tokens\n",
"similarity_result <- model$wv$most_similar(negative = c(\"she\", \"her\", \"hers\", \"herself\"),\n",
" positive = c(\"he\", \"him\", \"his\", \"himself\"),\n",
" topn = as.integer(50)) # Convert to integer\n",
"\n",
"his_tokens <- sapply(similarity_result, function(item) item[1])\n",
"\n",
"\n",
"# Get the vector for each sampled word\n",
"\n",
"for (i in 1:length(his_tokens)){\n",
" \n",
" if (i == 1) { vectors_matrix <- model$wv$get_vector(i) } else {\n",
" vectors_matrix <- rbind(vectors_matrix, model$wv$get_vector(i))\n",
" } \n",
" \n",
"}\n",
"\n",
"dist_matrix <- as.matrix(proxy::dist(vectors_matrix, by_rows = TRUE, method = \"cosine\"))\n",
" \n",
"mds <- cmdscale(dist_matrix, k = 2)\n",
" \n",
"plot_data <- data.frame(x = mds[, 1], y = mds[, 2], label = unlist(his_tokens))\n",
"\n",
"# Create the scatter plot with text labels using ggplot2\n",
"p <- ggplot(plot_data, aes(x = x, y = y, label = label)) +\n",
" geom_point(alpha = 0) +\n",
" geom_text(nudge_x = 0.02, nudge_y = 0.02) +\n",
" theme_minimal()\n",
"\n",
"# Print the plot\n",
"print(p)\n",
"```\n",
"\n",
"> \\### **Questions:**\n",
">\n",
"> \n",
">\n",
"> What kinds of semantic relationships\n",
"> exist in the diagram above?\n",
">\n",
"> \n",
">\n",
"> Are there any words that seem out of\n",
"> place? \n",
"\n",
"## 3. Saving/Loading Models\n",
"\n",
"``` r\n",
"# Save current model for later use\n",
"\n",
"model$wv$save_word2vec_format('resources/word2vec.txtlab_Novel150_English.txt') \n",
"```\n",
"\n",
"``` r\n",
"# Load up models from disk\n",
"\n",
"# Model trained on Eighteenth Century Collections Online corpus (~2500 texts)\n",
"# Made available by Ryan Heuser: http://ryanheuser.org/word-vectors-1/\n",
"\n",
"ecco_model <- gensim$models$KeyedVectors$load_word2vec_format('resources/word2vec.ECCO-TCP.txt')\n",
"```\n",
"\n",
"``` r\n",
"# What are similar words to BANK?\n",
"\n",
"ecco_model$most_similar('bank')\n",
"```\n",
"\n",
"``` r\n",
"# What if we remove the sense of \"river bank\"?\n",
"ecco_model$most_similar(positive = list('bank'), negative = list('river'))\n",
"```\n",
"\n",
"## Exercises!\n",
"\n",
"See if you can attempt the following exercises on your own!\n",
"\n",
"``` r\n",
"## EX. Use the most_similar method to find the tokens nearest to 'car' in either model.\n",
"## Do the same for 'motorcar'.\n",
"\n",
"## Q. What characterizes these two words inthe corpus? Does this make sense?\n",
"\n",
"model$wv$most_similar(\"car\")\n",
"```\n",
"\n",
"``` r\n",
"model$wv$most_similar('motorcar')\n",
"```\n",
"\n",
"``` r\n",
"## EX. How does our model answer the analogy: MADRID is to SPAIN as PARIS is to __________\n",
"\n",
"## Q. What has our model learned about nation-states?\n",
"\n",
"\n",
"model$wv$most_similar(positive = c('paris', 'spain'), negative = c('madrid'))\n",
"```\n",
"\n",
"``` r\n",
"## EX. Perform the canonic Word2Vec addition again but leave out a term:\n",
"## Try 'king' - 'man', 'woman' - 'man', 'woman' + 'king'\n",
"\n",
"## Q. What do these indicate semantically?\n",
"\n",
"model$wv$most_similar(positive = c('woman'), negative = c('man'))\n",
"```\n",
"\n",
"``` r\n",
"## EX. Heuser's blog post explores an analogy in eighteenth-century thought that\n",
"## RICHES are to VIRTUE what LEARNING is to GENIUS. How true is this in\n",
"## the ECCO-trained Word2Vec model? Is it true in the one we trained?\n",
"\n",
"## Q. How might we compare word2vec models more generally?\n",
"```\n",
"\n",
"``` r\n",
"# ECCO model: RICHES are to VIRTUE what LEARNING is to ??\n",
"\n",
"ecco_model$most_similar(positive = c('learning', 'virtue'), negative = c('riches'))\n",
"```\n",
"\n",
"``` r\n",
"# txtLab model: RICHES are to VIRTUE what LEARNING is to ??\n",
"model$wv$most_similar(positive = c('learning', 'virtue'), negative = c('riches'))\n",
"```\n",
"\n",
"## Concluding Remarks and Resources\n",
"\n",
"Throughout this notebook we have seen how a number of mathematical\n",
"operations can be used to explore word2vec’s word embeddings. Hopefully\n",
"this notebook has allowed you to see how the inherent biases of language\n",
"become coded into word embeddings and systems that use word embeddings\n",
"cannot be treated as search engines.\n",
"\n",
"While getting inside the technics of these computational processes can\n",
"enable us to answer a set of new, interesting questions dealing with\n",
"semantics, there are many other questions that remain unanswered.\n",
"\n",
"For example: \\* Many language models are built using text from large,\n",
"online corpora (such as Wikipedia, which is known to have a contributor\n",
"basis that is majority white, college-educated men) - what kind of\n",
"impact might this have on a language model? \\* What barriers to the\n",
"healthy functioning of democracy are created by the widespread use of\n",
"these tools and technologies in society? \\* How might language models\n",
"challenge or renegotiate ideas around copyright, intellectual property\n",
"and conceptions of authorship more broadly? \\* What might guardrails\n",
"look like for the safe and equitable management and deployment of\n",
"language models?\n",
"\n",
"## Resources\n",
"\n",
"- [UBC Library Generative AI Research\n",
" Guide](https://guides.library.ubc.ca/GenAI/home)\n",
"- … other UBC resources…\n",
"- [What Is ChatGPT Doing … and Why Does It\n",
" Work?](https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/)\n",
" by Stephen Wolfram\n",
"\n",
"## References\n",
"\n",
"This notebook has been built using the following materials: -\n",
"Arseniev-Koehler, A., & Foster, J. G. (2020). Sociolinguistic Properties\n",
"of Word Embeddings \\[Preprint\\]. SocArXiv.\n",
"https://doi.org/10.31235/osf.io/b8kud - Schiffers, R., Kern, D., &\n",
"Hienert, D. (2023). Evaluation of Word Embeddings for the Social\n",
"Sciences (arXiv:2302.06174). arXiv. http://arxiv.org/abs/2302.06174\n",
"\n",
"- [TensorFlow word2vec\n",
" tutorial](https://www.tensorflow.org/text/tutorials/word2vec)\n",
"\n",
"- Anwla, P. K. (2019, October 22). Challenges in word2vec Model.\n",
" TowardsMachineLearning.\n",
" https://towardsmachinelearning.org/performance-problems-in-word2vec-model/\n",
"\n",
"- Chandran, S. (2021, November 16). Introduction to Text\n",
" Representations for Language Processing—Part 2. Medium.\n",
" https://towardsdatascience.com/introduction-to-text-representations-for-language-processing-part-2-54fe6907868"
],
"attachments": {
"media/creating_a_word_embedding.png": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAABsIAAAMFCAYAAADOUePjAAAACXBIWXMAAAsTAAALEwEAmpwYAAAA\nAXNSR0IArs4c6QAAAARnQU1BAACxjwv8YQUAAQGSSURBVHgB7P1rrGVXfSj4zl0vlx+4yjxc4AZc\nDsLdOOQYc4nUIWkZh9M4alqyfSCROjeS7YR8aClXLl+6pdb9cG3rfjw3sa2O1B9CUrZ0kqtzAte2\ndGiF3CTGOglpKbkYGkJOoMFlzDHYAcoFxi6XXbV7/Vd5FGPPPceccz33WnP/fmKxy+sxH2OOOeZa\n//8cY2zsO/KRzQoAAAAAAAAGZk8FAAAAAAAAAyQRBgAAAAAAwCBJhAEAAAAAADBIEmEAAAAAAAAM\nkkQYAAAAAAAAgyQRBgAAAAAAwCBJhAEAAAAAADBIEmEAAAAAAAAMkkQYAAAAAAAAgyQRBgAAAAAA\nwCBJhAEAAAAAADBIEmEAAAAAAAAMkkQYAAAAAAAAgyQRBgAAAAAAwCBJhAEAAAAAADBIEmEAAAAA\nAAAMkkQYAAAAAAAAgyQRBgAAAAAAwCBJhAEAAAAAADBI+6o5e/V7n6sAAAAAAABgUvvfenM1T3qE\nAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAyS\nRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADA\nIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAA\nAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAA\nAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAA\nAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEG\nAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgS\nYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACD\nJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAA\nMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAA\nAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAA\nAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIO2rAICVs7l5ttp87Uy1ee610b9fq6pz\nZ0dPxmNz9L9zFQAAsHwbG3vi/0aPvaPHntH/9o/+OXrs2Td+AACrxxUaAFbAOPH16unq3Gsvj5Je\nr0l2AQDAChp/T9+Mf509/9/V6QuvjZNko2TYnn0XV3v2HzyfLAMAdpxEGADslM3N6uyZF6vN116q\nNs+drQAAgPU1TpKdPVOdjccrp6qNPXtHCbHLJMUAYIdJhAHAkm2Ofxj/aPwXAAAYprjZLRJi46TY\n3gPVngOjpNi+gxUAsFwSYQCwJBJgAACwO41/C7z8w+pc9BI78IZqz/5LKgBgOSTCAGDBJMAAAIAw\n7iV2+oXq3JkfV3sPXjHuKQYALJZEGAAsSswBdvpkde610xUAAEASCbHXXvr+uGfY3oveYA4xAFgg\niTAAWIBIfp07/cL5CbMBAAAanHv1pWrz7CuGSwSABZIIA4B5il5gr/xo9IP2JxUAAECXNFzi5tnX\nXu8dtlEBAPMjEQYA8xLDm7z8/fEPWQAAgEmce/XFUTLs5WrfJW82VCIAzNGeCgCY3blXq9de+mdJ\nMAAAYGpp7rDN0e8LAGA+JMIAYEYxrv9rL/3AfGAAAMDMzifDfjD+nQEAzM7QiAAwg/hxGuP5AwAA\nzM3muQu/M/bsv6QCAKanRxgATEkSDAAAWKT4vaFnGADMRiIMAKZx7tXq3Cs/qgAAABbp7Oh3hznD\nAGB6EmEAMKkYs//lH5oTDAAAWLzR746YM6zaPFsBAJOTCAOASWxujpJg3x9PYA0AALAU42TY98e/\nRwCAyUiEAcAEzg9LIgkGAAAsV/wOOfvKjysAYDISYQDQU0xSfe7Vn1QAAAA74dyrL1bnXjtdAQD9\nSYQBQB/nzlbnzrj7EgAA2FlnT79giEQAmIBEGAD0cHaUBDMkIgAAsONivrDTJysAoB+JMADosHn2\nzHhYRAAAgFWw+drp0e+UVyoAoJtEGAB0OOtuSwAAYMWcfcXQ7QDQh0QYALSInmCGRAQAAFZNjFyh\nVxgAdNtXAQBF5864yxIW5Uff+LPq1Nc/V+09eHl12Tt/obr83b9SAcNx9pUfVaef+2rja/sPvaM6\nMHowX6ef/2p19vSPtj2/5+Ch6uIrf7bajZZZDxexLtdKukSvsH2XXFQBAGUSYQBQMB53X28wmLsI\nFH7rjz9evfz8P1x47vt/96nqzR/4RHXVv7yvAoYhEgLf/JNfbXztv/jv/7eK+Tvxmd+qzpz6zrbn\nj/zSJ3dtImyZ9XCe63KtpK/UK2xjr2QYAJQYGhEACs6eebFifiKg8+qpZ8YPdreTX/l3WwJ7yff/\n/lOjIN8fVMCwHdAbbOmiJxFbLbMeTrMu10omYa4wAGinRxgANDl3dnx3JdOLxNfJr/zb8XA+p0eB\nnPpQTREQunQUmDt07c2G+dllTn39z4qv/fCrf1q9+ed/u4JZPPuX92xrc974c782bnOm9dxf/151\nppbIP/JL/3cJnTXVdDznIXrq7L3o8gpm5VrJJMa/WzY3q2pjowIAtpMIA4AG5147XTGdSIDFncpx\nx3LTPCVJBCDPfOWZ8R3PEUh++0fvd8f6LnHulR9VsEg/+fbfVi8/t7UnxcVXXjdTIizm6akv0/Bk\n6+vFb39hXE/mLZKjEmHMg2slk4rRLPZe9IYKANhOIgwAGpx71bCI04gg8dP/399snJ+kTSTFvvUn\nHx8HEGMeE5Yrhqs8+8qp0fH72vkE5ej4nT19apzUfNevf7qat8vfffO2hEJySO9A5uDglT+7rY6d\n+dFk7VJdvfdQJDskPIBFca1kUpuvvVRVEmEA0EgiDADqYljE0YPJRLDmW/+fj7f2AusSQ1UFybDl\n+uYoCdmUvHzzBz5RLUIM53TqG5+rTtcCfJG8iGQozKopQVVqm2IOnm/80Ucu/PfPjJK/Tb1T65/f\nf9iQiMDiuFYyqfj9srl5ttrY2FsBAFtJhAFAjWERJzfu0dWRBNtz8PLxEIgRoI7A87nCeyMZduk7\nP2iYxBVw6NrF3HEedeDaO/+8+uFX/t14aMz470uv/oXqLR8w3wnzceDw27c9F+1Ok598+wtb/juG\nQKy3P2cbhig7cPn2dQDMi2sl0zj36ulq74FLKwBgK4kwAKg599rLFZOJYQ1LSbBIgEXQ5s0//4kt\nvTTiDud//vtPjYM7dd/57N3Vu3/zzw07tiSTDmU5L2/8uV8bP2DeDhx657bnSsn3F5/eOk9U01Bk\n9WERx+vQI2yQoqdN3LQxrb0HD1UwT66VTGIzfsdIhAHANhJhAFCzee61iv6e++vfLSZSYvieox/7\nw8ag4sEjP1u946P3j1+LZeReG89X9Q96he2w/Yf0eGE9Hbzyum3PNSWzwulaT7HTDYmwc6dPbXtO\nj7BhuuydH6wude0B1pTfMQDQbE8FAFywee7V+L+K/pp6dIX9owRXKQmWi7vvr8judI7Pveu/+7Qk\n2ArQs4F1VWp36smw+O96Ij+GQXzx239be+7H25Z18ZH3VgCwUka/Y2KeMABgKz3CACB3zg/HSUQS\nrNQb7F2//qe9h5eKRFgsKyaGj8RY25CIrxZ6dewZJW3yz0Uw+0df/7NxQPvs6705Yiizi6/82fHd\n/tMOfZWWG/MNxXCQEUiP9V585GfHj8vfPZ95tU4//9Xxtkf55uuJ5NSBQ28fJwpjLrVJt73es6XU\nSybEe5t6wiT7e5Rh0zrb1I9jH6V19K0Th95988RlWRfzTJ36xufGw+ydfeX1ZY/KJ+pE0/KjHp/6\nxqgePfe1C8fg6Mf+aOWGA11EPVyW2L6mJFfuJ7WEV3L6ua9uScafOfXtbe+JYV/7ivoRbUYc76h7\nsR3n68d14/UcvHK6pNpOtoepzp954ZkL5Rr1PfZnXu3gEDQdo9R25mWYjscVtSHw0nvS+VdqUyax\nqOtj0zrya2UsN87LeV4rl1kPF7ku18r1vlaums3XXqk29l9SAQA/JREGAJlzZ1+t6O+Hhd5gEcib\nJJAWAZCrPnzfeB6xLt/+7N2NwetYZwy1GL7/939QPffXv1ectyy9f5K5YGKoxmf/8p5i4PxHo8BO\niOVd8XO/Ok7qTROk+v7f/cFo+z/Vuu3huSp6bF0+Dr713Y8IbD0zKr++/vF/+S9bX/8X/9N/qro8\n+xf3FHsNNoljeMWEc6FEmcXxrutbJ77/d58al9/PTJC8TSKoF2XalBB+dfRc1JdYftTxq//VH46D\net8bbUdTPRoHuUeB6J226Hq4LOMejbXjUi/jFwvnczwf53DSVA599jXqfrSTTcf7J9Xfjl4//+8Y\nRvYto/Zv0rq/E+1htHXP/sX/s7HOp/oey3nbv7yv2nfRG6rd7pt/8vFtZfWuX/90dWrUHsc5Vhd1\nLx27aD/r70llHMfryC99sprUIq6PubZrZdT5ZJZrZVhmPVzGulwr1+9auco23dgHANtIhAFA7pxE\nWF8RLC8lhSad1D2CYH2SYH1EoKVPMOnk68HpPgGdmMOsKXjUJAI08d6TX/nTiYJFfYKTdfHe2I9I\ncF01CsBNGhTbDaKe9gkwxnH7j6PE3yTBxUnqRQSH/2NHYjHmptrp4N6Q6mEkl16uzff16gtbe+fU\n5wdL6m1bPXg77hXXEryP+vRMIUnVJLYj3h9JkHkmFOfdHjYlZprE/j/9md+s3vyB+bTrQ/O9UdtR\nqhtxLA68Pj9jW1nHeRq9ZyYZRnjS+nD1x/5wojZpGdfKsMx6uFvqvGvlsBgaEQC2M0cYAGQ2zQ/W\nWwwd1iSGfLp0h+b3imDLJHdUR0CnK8AVgcO+AZz6sr/xRx9pHXowRPApegw8+xf3TpR8qC8jtjPu\n9marZ/79sYnqRAQCu45ZmCSw11ef9S7KEOthSibk8qER49/1RFn+Wn48ztaGEzt4pByEjc99a1SW\nfZNguair3/qTX51LXZh3e9g3IZCb9P27RVfdiJ4xfdqXOMZ9fW+K+vCtP/74eGjDPhZ9rUyWWQ93\nU52ftEfabr1Wro1zr1UAwFYSYQCQcwdlb6Xg2MVXXlfthHR3+aTa7t6eNJBcF8H0CGrX5yXa8p5R\ngH1eQZ3YfwGin/rRN/7swpCVfaVkTptIApfqWswbFUmStkRJel8ajirmO4mh0nZyrq0h1sOmHiZ5\nz66uZET+ev0cLvUGS0mw0tyJfZxfRnu70WcZ82wPo6egpNb8XTqeW+rmbc/nx37PeOjRm8dDkNZF\nHe1bT+r1PZa7vyFZXN+Opz/zW53rWMa1MiyzHu6mOh/XykmP3269Vq4Nv2cAYBtDIwJAZnNzs6Kf\nmLi8ycVHdma4mnqQbxxgvPbmat9Fh8b/HUOOvfjtL4znokja5jKL+SxKAZz43BvHn337eJL5GG4t\nJn//4Vf+7Zblh3FA+j/87njIuCax/gjsRG+c/LNp+9/wjg+OA6DR0y6GA3pplICMoOOrDYH2FJiK\n5TWJba331ovPnC70iplHz74DhR6CMRTctD2P+sqXH9vw1l/65DjoFkmMqC/f/uyxxnL8ybiu/G1x\nyLH/9Jf3Nj4fc93EsHYpSfLTob+2BxjfMko4TDO/z6Issx4uS1OANU/Qvfj0F7a8FgHXc1mdiTqQ\nhv56tZbYK7Vz55OAzUmwKLs3//xvVZdc+d7xf7/0/FfHPX+ayrCr3egyz/Zw3FPs75oTAlFmb/nA\nb4/aw18d718c+5j7qlQ3+Kk4/6O9CCc+85uNSfv94/Py/LCBkZiJHpt1k86XFMcs5uQ8dO2vXGir\nYh670jE7f/z/oNheLetaucx6uBN1fl2vlVFWpe9RQ7xWrgu/ZwBgO4kwAMgZGrG3Uo+Pg0d2dt6G\nCEy986P3bwsoRUAutjmG80kBxxSEbFK607lpXoy9r9/VfMUoMFZPJIS4q/zIf/XJYi+SlIT4xvGP\nVBG6eOsvfrJxzrR093QEFktzvaQeAk3rOvTum8ePre//wmibf7W4TbOKMj5SbS/nb045dNx02/DJ\nbcc66kcq86YgY5RLUyIs6lDTdjetI8ow6kvTZ2JenFUL7i2rHi5L07rzczPv1RrvjeOXJxraeoQ1\nBX6jHEq9KqLNiAB/vk1RByOgXirDaDcuHyUrLpshIT2P9vB8sHt7EDwSAu/67z69JSkY+xf1Ira5\nqS1cB7Hdk5pkvqQQxyUv70hKNSXC8vniLn/3rzQmws5NkCSJY3btnX++rf6mY1ZqDyMpVGqvlnWt\nXGY93Ik6v67XypgbMhJbdUO+Vq4Fv2cAYBtDIwIAc5V6HOyEdPd8qSdTBFtiaJ0YDqqrN1hTECw+\n0xbsPDAObjYHbLrmTYrP/swowBZBtqbkQ904qH6wOclw8n//t1Vfpd4rew7uXAJjnuJ4lQL8UeZX\nvLf5eJbmjjr9/PaekCmJUtLUwyECfqs4jOVO1cNFiH2pb1s+11cecB0n917vqZXE8UkJsHoAuKnt\nKA2jFu1RBHlLScF3NCSqkknmgKqbV3tY2oZI4pV6xp0PbD9Q0aye3Nx7sPm6+cbselM6PpOIY1Za\nTjx/ZeH6FefBiw1JjWVeK5dZD3djnZ/2WvliIUk39GslALB+JMIAgKmcm2H+mkXJ755vf98nW4Mx\nP/zKnxaX32U83FRDYuDFHnd0R4Ct79CSEVAqJnGe/1o1q53syTNPXcesVN6nC2WYJ1KSrl6QMWxZ\nU504u4LnUFilejirej2OMo9HBPBzkZiIR/04vTgO9G8PwtYTxdG7rJQ8jURXl/Kwc3/bq+1oXubs\n7WHsV1OiI8q1K1HaVJ6cd6A2N9fei96w7T3zGJq2LnpitYlh6ErHrH7OhGVdK5dZD3drnXetBACG\nTiIMAJhKU5BjJ0WQKgJrfbyxpfdDiInj6yIo2SeoHNvR9L7SPFyzKAWmJrl7+uwrq3Uc56nPMTs4\nlzLsDtIteo6XnTSPergoBxvmToq2Kx8WMVz2zg82vj8N8VhXn5Mphgdrcvm7b+7VbkQAvZT4aEpA\ndJlXe9g2f2CfZHkM58d28+jdNam+17BJesku61q5zHq4G+v8LNfKSez2ayUAsLPMEQYAuY09xtXv\naTyU0wrN/5Imdp/Vy4WJ6eO5vsOUNSUJIwDUNql8yennvzoKQH7t9eGBvtO5njDJHCWloNNOBGrn\nrW8wdhJNQ5i9+sIzrfNhlRIZ61TGi66Hi9JUxnGOn/r61vmYUpA3Elz5kInRO6U+r17TMku9tiaZ\n3+vQtTc3zqnz8hRJ9Lm1h4V19+0xePGR66qTX6lYAf2PWb+eP8u8Vi6zHu7GOj/LtbJ0w8P+hmXu\nhmvlythwzzsA1EmEAUBmY2Oj2tys6GFPS1Dk0mr+Qzp1uXgOdyuHc4Wg/ulR0O/087P16up1N/Tr\nw7b98999arw+d0evlktfH/oqPy5xzJ77D7/bOL9JvPbMZ+/e9vy8EhWLMpR6eODw27c9d260L/m5\nnB+Ly67+4Ja5vqJ3SL332P5D25f5aiEYfPGR91a9t/XQOxufPz3FEJPzag9LbVbfwPTeHZwzclrv\n+vVPL2RYwp124PK393pfqedPPWm1zGvlMuvhbqzzi9DUBg3xWrmq4vcMALCVRBgA5Db2jv7vbEW3\nUmBip4ZMnFeg5MwCe7Gc60gmfP/v/6B67q9/byWSDub2aRb17NJ3/EL1o29s7VEUyZMI5OXzMkUi\n6dm/uLexTr35A5+oVtUq1cNZNSWXTn39z7bsW95rqykB8uLTf1tb5vaAeKndaEqalRy88rrG56cZ\nYnJ+7WHzuvXQWD9NvVkb31e6ttcSRMu8Vi6zHqrz8xH1KIaGHfK1cqWNf88AADmJMADIbOzZV22e\nPVPRrRQUOvOj1RkucV1EUOjZv7inOvmVf1ctWymY6Q7ssrib/SfP/O22RFEcv3ikJGIpkRRDRsW8\nTKtmJ+vhojQll+LY5fLk1/l5i96+5byoD1d4YILk1m6nrFbHbk7kLLMeqvM/NdRr5VqQCAOAbSTC\nACDnh2NvTUOOhdJcOZR7hzzz749tu2s6t2cULLrsHb8wvqM/AkcRrI9AffS+a/scixEB5bd9+L7q\nOw3DOIW2nlQR2HvXr/9ptYqGWA+besHUj0/MC5a79J0frM5kycB6T5imoePqw2VOo8/Qqcu2d8Yh\ncM++8uOK1TDrsMXLvDmifq1cZj1U5+dnqNfKdRA39gEAW7k6AkBmY49EWF8Hr2ye+ybm1GmbDH3V\nlYaPevPPf6J6y4xD9DRNHv/cX/9uMYkQPVXe+kufLM5XE8MJSYTtjEPX/kr1/OjYTTI8WArsrWLP\njKHWw2iH2pJUcUzqxyOGSmzrFbevYQ6gWE/TOmJ+sb7HuzTn0sE5zfc1jVJ72HcI3NL79hh6dWWV\n5rur14VlXiuXWQ/V+fka2rVyXezZu78CALaSCAOAzMbeiyr6iYnQSwHm7//dH1RHRoHzdVSapyf2\nc/8CgjKlgHuUX8yh0SaC7CxfJHq/8Uf/9ZbAXgQ5S3PAxWtv+cBvjwPEq5ogHnI9jGDqy6ebt/Hi\nhvO9lPBLmhJTB6/82cZA76sv9J/fq9SbdifrTGmYt5ef/1rVR2m+JUOvLl/fueZKPZrqvbSWea1c\nZj1U5+dniNfKtbEh1AcAda6OAJAZ9wjb2FNVm+cq2kWQIoK/P2kI3n7/7z41CmT8du9Axir1IIug\neVOC70df/7Oq+uj91TxFL5qm4HkEEbuSD+HFp2cfhrIU9Jvk7u3dJubRysvn8nffXB392B+Nz4WX\nnv/qhSBfBPUuufK9nYmVnbYK9XCRop16+bnmRNjl1/7KtudKbUAY9zBraKvixoCmXnGnRs9FW9hH\nKRl5aFS/dkqpR0bf9tBQuaujdA7UnYpj2+DiWgJ4mdfKZdZDdX5+hnatXBuj3zEbe4X6AKBuTwUA\nbGFc/f5Kvb4isfXcf/jdqq947zOfvXtl5sg5eOX2Hh+xbW3DpU3j5ee+2vj8oWu7A99x1/k8hqPb\nWxiuSW+zZlEu9Xpw5L86fx5EEC/uZj/fi+qT43+vQ2BvFerhIpWSveHiwrCDl76j+bjtP9wcJI95\nxZpEwLdPYPxH3/izYvK5KVm3LKV1R3vYtV/xnp9ICqyMOBZ9rrEx1GmTprZsWdfKZdZDdX4+hnit\nXBd+xwBAM4kwAKjZs+/iin5iLp39hSDz9//+U72CYd//+z+48N5v/NFHeg/ftEilBN/5u5v7b18E\nt6fRNoF88txf/141D11zvbWZd7BzHTQFiaMH5CrU23lbZj1cpFIPj+jZdfGVzYmwy67+heJnGt8/\nagtLgdxoN9rOpXgt3tMklrmT8+TE/pb26zsdNy/EELmsjjhWXcck2vSmhGzUg0Pv3p4gWta1cpn1\nUJ2fj910rVw1G37HAEAjiTAAqNnYd7Civ7a5wKKX13N/3dwzbNxrbPTas39x74XnIkDyH/+X/7L4\nmWUpJfhim7/1J7/aeVd47Mc3/+Tj1YnP/NZU+xJDMLUF22KZ80pClXrEjNdT6NUXAa5IWq5SL75l\naUoOxbGIenv+mP/m+PjEI5K88Vp6RLD39PNfrdbFMuvhIu09eKjx+bYeCKUEcdv5UmoLTz//D9Uz\n//5YYwB43Kb88ceLvcHeugJzLV7xc7/W+Py4nRtv+/b9ijZiHZKku01bIiKGTnz2L5sTsqVeUsu8\nVi6zHqrzs9tN18pVs2e/3zEA0ESfaQCoiXnC4rF57mxFtzeOAkYRuCgNBxSBoZNf+dNRIO3m8RBl\nERyJoG8EOko9TlZhfqp3fPSBUSDv49uejwBYPB9zXRwaBQdjn6LHxtlXTo0CiV8bB/7yfUuBsaYg\n+fnh1LYHzs5PMP+R8fxMFx+5rtp70flAfiz7hy1lPY1093vjXG9//6nx8EYxRF5sQ/w7gqX5eyNZ\nUgoahm82lGE4XRh6Mdb5w4bkyrt+/dPVKigds5DKpWuowBiO8vJ3/8r4+O5kb59kFerhIh288rrG\n5y9rSYSVEl4HLi8Ps5h6hTWVS9SJ089/bdwOpl5oaeiwUjsY59UqDBcWbXwEq19taJfjPI6ER75f\nUT/Wubdoqc3q61/8T/+pWlUpQZWf03FNi2PWlsRpmytwGdfKsMx6uBN13rVyu1W7Vq6D8W+Yjb0V\nALCdRBgANNiz75Lq7JkfV/QTk59//Y/+68agUYiAWNyJ3sf+UbCjLei2LBHUjoBc6S71COD0nRsp\nAnwRFKoH3iPYHoGepkB4lFn0uFqGCLiXkhrxfFvCIwKAbYmwSZMlkWhbZXEMD46O2+kZtjOO9/iu\n91ES8ap/eV9r+S3DqtTDRSkFUC8+8t7iZ0oJ4tIcYUlbWzhpOxh1Y1WUkh1hkv1i5016Tsd1sC0J\nsYxrZbLMerjsOu9aud2qXSvXwcb+yyoAoJmhEQGgwZ4Dl1b0F0HjuAu5NF9YXxH8fdev/+nK3Pkb\nCbkjcxiaLJbRFNiLcrtyhuXvn1M5xd3vB1uGfGvz4rfXo1fQPB39V384l5460TsjAtIvP7+zAc1V\nqYeLdKChbeo6hk3zh3W1TfNoC1M7WJqPbCdE+/W2KRJzpTJ+dQV6/e4m0StrmjoZiYc+N6Ys+lqZ\nLLMeqvOzG9q1ch0YFhEAyiTCAKDJxp5qY++Biv4iQHztb/7/qjd/4LeraUSwZJWSYEkE+N7+0fun\nCiLuOXh5ddWH72sNJL7lA5+YKoAYn3njz/1qNS8RsJp0H9Mx223Oz18yv4Dcs39xT7XTVqUeLsrB\nWlKrT3D2sqs/uO25Pu3TgXEi69NT9V5488//9qgd/fOVHAYs6sgkiYHzvXub69TZ06cqlueKf/Fr\nEydooy6+Y3Tt62vR18pkmfVQnZ/NEK+Vqyx+txgWEQDKDI0IAAV7L3pD9dpLP6joL3owXPUv7x0F\n0H7r9bnBuufMiIB0BIzfuMJD3sS2xd3h5+dR+d3OO7sjqPeWUULwzT//iV69OiL4F8HDmPOjaxih\nKK+3jgJt8bc0FNU0UvC+67jFvkVPmbQNu02UeT6XTpTHNf/qj8bH+cyPvlO9/NxXx3ev58MMxjBa\nIe5mP9cw/GAMiRWf2ekeQKtQDxdl78FDW/774h49IOv1O45P32MU51MkEaLt+N6ofLqGPcvLc5VF\nYuDQu2/ubCeiTY+hzEpDTEZ9j/b0sl3YhixbJGcOvftXxv/u08ZH0vg/Gx27aerioq+VyTLroTo/\nnSFfK1fV3gOGRQSANhv7jnxks5qjV7/Xb/xvAFgHr730/Wrz7JmK6UTAIgLqLz3/1XFALAIeMRdR\nBDEiUHz5tb+ylgGN2KcUyDnzeqAvhl6LfYok0bTDDKZl//iZL1worxBlFgmKN7zjgzMtu68IRp1+\n/mvj/UsiiHXJle8dr3+3BqEiCFqfW+e/+O//t4l67/zzKMn03Ya72t/9m3/eOBTfTlmFejgk0RZG\nELd+Tl106J3joPk6nlN5OxHt4N7Xk+Tr2q7vJnHsIikTvXXS+X3wyHXjNn6eydhFXiuTZdZDdb6f\n3XStXBUbe/ZW+y49UgHAkOx/683VPEmEAUCLzbOv6BUGjH3zTz6+5S7/80NDfrqa1DeOf2QUSN3a\n4yqWsxt72AEwLK6Vy7f34OFqz/5LKgAYknknwswRBgAtNvZeZK4wYKxpqKtpNM0VE72DAGDduVYu\nV/QGkwQDgG4SYQDQIeYKA9hbC8DFsF+Tzo/17F/cc2GIsGT/68OEAcC6c61crugNBgB021cBAK3G\nvcL2Haw2XztdAbvXwVEArn6n+3N//XvVya/8aXX5tTdXl70+11N9HpSXn/+H8fBO3//7T12Yjyf3\nxp/7tQoAhsC1cnmiJ1j8TgEAupkjDAD62DxXvfqT58d/gd3ph1/5d9V3Pnt3NU9xh/u1v/nn46Ag\nAKw718rliCER917y5mpjY28FAENkjjAA2Akbe6p9hh6BXS3uRn/zB367mpcI7L3r1/9UYA+AwXCt\nXI49B94gCQYAE5AIA4CeYnjEvQcurYDd66p/eW915Jc+Wc3q0nf+wjiwVx8aCgDWnWvlYu05cNl4\nWEQAoD9DIwLAJDbPVa+99M+jP2crYPc6c+qZ8ZwnL377C9Wrp77T6zN7Dl5eXXzlz1ZvHQUHI7gH\nAEPmWjl/54dEvLLa2NioAGDI5j00okQYAEwokmCRDDNfGBBOP/cP1Zkffad6+bmvjoJ+WwN9e0cB\nvf2H3l5dcuV7q4NHftbQTgDsSq6VszMvGAC7iUQYAKyAzXOvjpJhP5AMAwAAFmpjY88oCfamUTJs\nfwUAu8G8E2HmCAOAKcSPUHerAgAAi7Zn9LtDEgwApicRBgBTikmq9x48XAEAACxC/N6I3x0AwPT2\nVQDA1NKP0rOv/MgwiQAAwFzEcIjRE0wSDABmJxEGADOKH6cbe/dXZ1/+4SgXdrYCAACYljnBAGC+\nDI0IAHMwnjPs4jeP/u6tAAAAphG/J/Ze+hZJMACYI4kwAJiT+NG675K3VHsPXFoBAABMYs+By6q9\nl1xZbWy4uQ4A5snQiAAwT+Ox/A/FeInVuTM/NlQiAADQajwf2MHD1Z59BysAYP4kwgBgAc7PG3bR\nOBl27tWXKgAAgLpIfu05eMUoGbZRAQCLIREGAAsyHt8/7uzcf3F19vQLeocBAABjG3sPVHsvesP4\n5jkAYLEkwgBgweLH7b5Lj4x7hhkuEQAAdi8JMABYPokwAFiSGC4xHpuvna7Onnmx2jx7pgIAAIZP\nAgwAdo5EGAAs2ca+g9W+0SN6hkVS7NyrL+olBgAAAxNDpY/nDt5/mTnAAGAHSYQBwA6JH8YbBy6t\n9oweF5Jir71cjf6v2tw8VwEAAOtjY2NPVe3ZN/rfxaPk10Wj/xZ2A4BV4IoMACsgT4qFzXOvjhJi\nZ0f/e/X8vyMxtnl29NiUJAMAgB0yTnZF766NvaOk195xsmv8XX7fAYkvAFhRrtAAsII29uyPScWq\nvfsOVgAAAADAdPZUAAAAAAAAMEASYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAA\nMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAA\nAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAA\nAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgA\nAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmE\nAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAyS\nRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADA\nIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAA\nAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAA\nAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAA\nAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEG\nAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAABr5b777qs2NjbGj3X3wgsvXNiXhx56qFol\nsT1p22I7J5Hv14MPPrjttRMnTlSsrjhm0x57FivOHcdk2G666abxuRd/J/GlL32pAqCZRBgAAMAK\niSTPNddcM34IdjZLwb73ve991brLA5dHjx6tVsmXv/zl8d/Dhw+PH5PI9+v666/f8toNN9wwrt9R\n11lN+Tk26bFncSI57fowfNNc4+6+++4LbSsA2+2rAAAAWAlxp/8DDzxwIcAZwbAPfehDFVul3kSr\nljiaRko2hVVL7M2ScCztV94b7POf/3x1zz33VKsuyiGVxR133FHtBukYzTsJ9uijj47rQJy72rbJ\nPfHEE+O/UYZDuT6knrDRTgzh5oZZxbFN3wHqNxG0eeSRR8Z/593bdje2f6sgjmNcI8Ott97qhgSY\nA4kwAACAFRE9ZPK7/COZIFi83ZB6hKVA1yr2vJmlnPNESr5f8e/7779/HNBfhyRYiPMyEjhRDrsl\nEJyO/bzbnyjLWPaxY8e0bVOIcyauEZEgGUL5xb7ceeed439HIkcibPpewnETzcMPP1zdeOON1TzF\nMmPZu6n9WwXx/S+dG5LEMB8SYQAAACsgEgfpzvhIFqQ7/tmqbci9dZQSn6vWuy3vlTDNtrUl0SIJ\nEo91MaQeiH3EsZumR0rfZYfdUpbzFuWWev4MQd6e6/Fy3rS9hKPXUDzmzTm7M/JzQxIM5sMcYQAA\nACsgzZcUwaZ77713/O/UW2iVzTJPTZ5s6fv6008/feHfswTmZp1fp+vzXfuW5D3CJv1sab3TfKb+\nuUkSjk1Dcc2z1940+zTP4cEm7R2VD//Y9p5Zz51FfW6Sc2yS/Zgmib3M86DPMhfZ3i3CLOfBMrZ1\nlYeGTWYphyj/Sa9xy+olPOl52/f4LLKez3vYx2kto+2e5hq6yLoKQyARBgAAsMPy3mDHjx+/ECSe\nNjDx4IMPVjfddFN19913N74eAZZ4PR6l7UmvNyXjYlvjtY2NjeqKK64Y/43/jiGUSuK1eM9tt902\nXuYNN9ww/mw86p+L5eevxyP2Je8lFwHCSQOn8flYTlpmbPc111xzIQnZJJVDDI1X3+94xNBF6RjF\n31hWLDO93rb8emJgks/mmo5HlHNX0DD2KT6Xl3PsT3yuK0Cd6kjazlQHUp1NZVIfpiv2J96XhnzK\nyyKVdSwj6nBabt+ySMto2qYQZVKq03WxffHeqIdJKudYTr0cUh3J11/fx1hvvbzjfW3nTdTX+Ezs\ne17m+XnXdpzzOlmvt6XPdfVEaKrnbctM5ZOXR6oHTW1ULKPpPI060Sa2O9bRdH7PklCbZF/TdqR9\nnrRNaNPWLuf1pOs8qEufjfJNdTRvS9r2NW/XS+rHOi+fGHIvRHuezs+u4xzS+Vk6d9I1sFTO6VxN\nxyg3zTkT8mMQ60/lH3/zdaTll9qBaXritu1PXmfqx7d+DavvS768fB11TfvUp8y61I9F+jvNctva\nnCSvm/VzrL6Pfb4/1Ndd/85U34d0PuXr7/o+1nfZuXR+RDnGcc3ralpHlEX8d1wDJcgYjH1HPrI5\nzwcAAACT+dCHPrQ5+nk2/htOnjw5/u94PP7445uTuvfee8efHQXSWtcXj1hX2+efeuqpC8/He/PP\nNj3is01uvfXW8eujgOe2z+T7eMcddxSXHetOy0ll1deTTz7ZuO70iPU2fSa9PkoItG5XlFOUV+k9\nx44d27b8UQDqwutt29b02XQ82sorlhn70CQd46ZH7EdablMdeuSRR4rbG8+PgtvF+pvKMY5jLv9M\nWx2L9zUZJalatym2Of13qUxybXU8r3ttxzA/bm3HqVT/QlpmlFtp/+IYNZ3HXXW+VD/SORbrnKSc\nm5aZn0N96nbUl0nP05DXn0nKqE1bPW8rv7Qt8Xpbu1GqyyV5Xauvd5Z6kt7f1n6VPtunPa6f813H\nKsq9S1pmU33I2+KmOhzq19wkyrWtHNra1LZybNq2Up1IyyldS5vEedS0v/n519au1suhrd7X19F1\nzta/R/Q1bfvVVUal70UhlVH9PdN8fwix321tQDyiTU3S+VR65Ps76bKb9rNtHfk1q7QcWLR5560k\nwgAAAHbQ8ePHLwQb8mDR1VdffSEwNu0yI3BTF+soBVaSFKirB3fyoMs999xzITAay8gDK03Ju/yz\nsV0RlIrtjEfa7zw5E8uL5cRrsfwUlEnBqFLgqUksIw8Up+2L52M/SsGePPCc9jltaz1gmpaf3hNl\nE+tJ74nX64HkejKqbflNZZoHzfLjka+3KUCdB6JTeaRyzsuj6fN5WcbftM3xiGNZD/LWpefrQd4U\npKyXRVM5Nh3f/Djcf//9E21Tk/T5tF2x3PRcfp7Wj2GUV6rX6dzK9+2uu+66cJxiObfffnvxGOcJ\n8fxYxfP1Y1UvzzzgHn+jTOJz8Yhty8+HulKyMi/nWGa+vfkym+pMHrRNieN0fJuW33ae1supnrBO\nZVT/3CSJhWn3NeTHOz9H+tTlNnldy9XrSWo7m+pJ/XrS9dk8GN5UfqW60rT8tO50bPK2JNbTVCdK\n0nY1XQeirufHri4/tvlxrZ8zqRxCftyakoL1hG+8J8o9tQVJ3hZFW5D2OZZfT2r0SQgmpcRe/RoW\n5ZUf33yd9SRLPPI619T+NZ0nqWy62pk2ed2oLzdPUE9yQ0xeFk11LN+X/JiVvj/EMtq+P4T8XK9/\nZ2r6bpDOjfzGjfh3vdzjfX2X/VRDEjJP6qXPp7qalpPOo2kTmTAPEmEAAAADUko6pSTHJAmfJA/4\n1NUTSvVgWykxlwfE8iBREsGTtuBUHixrCqrkQahSUDUPME+SIGwLYIZSEDHf5wgK1UVALA8yNr0n\nPxb1ss4TWU2JrrxM6j1n8uPUdDzybasHe/MAY1uPwKb15j37mo5jPSlReq1eFnkita2XTdPr+V38\nTduUl8WkAdmuHi/5MWw6/nkioKlnX37eNPWO6jon0mfrr+f1o6s862VWSnzkvQSbyjmvN031KgXd\nSz0cp+3Fk29XW6+ltp4gdbPs6yR1eZIAc6mn3iT1pH49yT8bwfAmaX+aEndd7XGpHQr5uTFJ0iek\na0HTeVlPfNePT6m3a36d6GpH6udGvY1pqof5OdlU1vGZUmKqS6kXWX7NbFpnvt1NiZxST7Ok69qa\nL3+SY5xvd9f51/ccyq+nTWXbp15M+/2haX35tbh+/rT1/sy3tfR623Ulvw53JbnSzROwU+adtzJH\nGAAAwA6JOYfSPA6jINWW19L8IH3mM6pLc4yFfJ6INBdZLDvN/fP0009v+Wyap2QUaLmwDfG5UVDn\nwvPxqIs5XkYBlwvbnM8pke9D7GfT3Cf5PBujhELV5JZbbqma9rFNXsajoNx4O+tuv/328d98bqT8\nv6Os0r7lRoGvLf9uek++nadOndryWtquUfB6y7KSKKf0fH3bUnmVjkd87uqrrx7/O5/vK45vOjal\n8sjLOZ/jK7Yh5hMJd911V+NxjLJK662/nte1+mtp/2JfmualysuxXrdS/SrVrbwsjk4w705Ix6j0\nufR6bHfT8Q9RzvGon+Mhyv/QoUPjf9fnYcmPW+mcSGVV/2xe1k3lGcc4zunY5vyz9XnrcnHMYz9G\nAe3G8khl3CSf36/ps/l5GstvUjpP0+diP5vqc2x37GvTOVYyyb7Wy76rLufLm2Seo1JdnKSe1NeX\nf7ZUf6N9CrGf+efb6kqSt3n1ssg/P+l5mV+bcqkeRdmnY5QfnxPZfJz5+Vi/FpfakVSH6tflJ554\n4sK/o8401cPUZsey0/U0F59JZR36zoEZ5Zj2sX4cUhnHdjetMz8nmuaB6nvOlq4ledv72GOPVX3F\nuR7LHCVtJm5rSmI5aRvzeh/61ItJvj/UvzOV2oH0fOm7R9NcqPVtbVp2fC59L0jvTfLjXGrf8uU0\n7TOsq30VAAAAOyJPZtSDESmgFUGPCFxMEozI35sHPdL6InCTJkWvJ8rypEJST2SV5AGZWFb67zwY\nmgf6cinB0lQWSR686hskTIm9CMiVlpuej7LKy7orCZKXbWm/8vKtB+/yRFtJU8A3P24pCNckJr+P\nhEj+2RQUayuPfL/y96SyDE3JtyQlYdoC3/lrqdxDnnjL5XUor99pm/LA3yTb1KXtGOXJndJyY7u6\nEjBp3+rHIx23WEbXsaq3D3lde/DBB8eJnVwsr+lcbktWdpVd+mxT8LQraTLpedr0fDov6p/PExh9\nTbKv+frypESeUJ52Pbk8qZHLE4Fd9aRUx0pJxFC/sSItI68rpc+ma0dTnZimPU9S8rguv8bFPsc2\nRrkdrd1YEv+dtxcpSVN/vi62M5bRdtNE0zHI2+y2a2ifa0Jdqb0O+fFtW19oSi61bU+0K6HtnA03\n3XTT+LozyU09XfufXw8mSaLmxy+/duZJyvz4T9oupfOj73emSFzH50o3hrSVe2irq+m8zbcr5Enb\nSc87WHcSYQAAADsgAi9tgbE82JknlfpIQcc8wZDfRRzBkxSEzJMkKRhUD/qkIGFboDXkwcmmHmGl\nu4vzHmRtweM8MdAnMRjLTOuOz0ZArm25daXAc/31UOoRUQr29vlsSX5nfRyzvDddLi/3EPuZ90Ir\n6drmtqBg236VyrNPz5BSEq3rGHVtU5uuz02y3DgWcdxSQLyp90WpvNrO/dJ74vhGwDRej54+Dzzw\nwLiM4vxqO/ZtPRFCbHcsN+1H07nT9Lm2nkGznqfRfkYiPZYTyd9YftrXSRNg9e2adF/bkhJJXsZ9\nb3Doc161tc2lepJvy6S66krbekNXkqZNUw+31HsnJT5TEiNP2KW2sn7NTfWv7dwIqZzq52/XTRN5\n8qFtHV3L6Vp2/QaDSW7mqL8n//5Qr3P5TQBdZTatWEccw5S46tvWtEmJsBMNPeVDqV60tUt5Gab6\nkY5J13em0vbn33Xq+lyH20yTbIWhkAgDAABYsjzwkgIzbSKoMs0d8+mO+FDvfZaCNykoEtuUemXV\ng0HTBOdyXYGXPCg1TTC3pB7sOtFjGLIUeJolydW0DfWgd1vPm1xTT4582/rcZV/v4RbaEjdpmfV9\nKj2fa9uvUnCvTzl2BfKn3aY2XcML9j3+d95555bjFNuQhulqGzKwa9/a6mgsO4byuvvuuy8kCOJv\nGho12oGmBHxXT4QY7ivvhXb09X1Jny31Xm1LhteHFOs6T+ufj/XHEGrRxsX+xfLiEcm/o68PQ9fW\nc7LJtPvap7fFNIHotro4Sz3psy2l3pizJGrz145OcV3JtyP1dqknuerJsrzHYP1Gk64eqUmpB2bf\nY9DW867Pcib5zKzXsLYbFCa5CaBUZm36nn+T1p20rfn2l3qDTdoupe1M70/LnEbbDR5tr/Ux67bB\nOpMIAwAAWLK8N1gENSJQ3iYPyPSVhsVLd4XX73g+WhtmLPXKqgcJw8mTJ8d/u4JzXT2JSp/vSjj0\nXU5dfqd2BMVLw2klkyaqTvTooVba5jwx0LY/bXeGx3HqE+BPx7NvwrEpUNanp0so9dzKXyv1CGsL\nEjdt06QJ1LSOvrp67vQ5/tGLIN4Xr8fwhNE7K39vBHzT3EyTDhfZVUdjPcePHx8Pv1XvkRZB5vgb\nrzftU3150WalOW+iB0jsS/04bmxsjP+2BW+7yn/S8zSJ7Y19ifYt7Wsk9k+8Pl9UlGV9eMiS/JhM\nuq999nOanlClRGLb/FBJaQjD/LNtCaDS+dPWNoW8DjfVz1l6ptSXl5K9+fXraG1Y2dJQfnk70pWs\nadrmPkmhPsmgfDldCbnciR5zx5XKuO3mhr5DV3YlVCZNvMSxTOdfHKs4p+vnWQzt3LVdTfJrYaqf\npd5gs3x/eOqpp7Y911dXfWrqTdwkHb+m4VuDHmHsRhJhAAAAS1TvDdYWKEl3IU+TCMsTXU1zkcV6\nY06QlCwrDRmV6wrApB5l+X51BUP7mnU5EVicNvB8tGOIs2mSd30D5ul9TUNGds2LNa0+815N+tm8\nR1Q9uNcnUDpL8G7az07Sy6NJCs6H6J01yfBwbb0xmt7Ttm9xvCKhk4Ywi15iEdiN7YtEagoOt815\nlg+rWk+e1belLXjbdQyins/STqReHfGIsr3tttvG2xZJvL6JsCibMM2+9hmKbpqeUKXj0idhXxrC\nsG9PyXTulpJ+0wwd2zbsXl/p+hVl3nT9SnNepetoqcdzKeFfVzo/pu1xWtdnzrUmpbrRJ1Hfdk3t\n0wO4S9c1rEk6ltFePfLII9ten6XuHM164sa29Z0bbtLvD7Poe2NQl/z7WDJJTz4Yoj0VQEH6opcm\nNu175wkAAGX5MDwR5IkAeemR7orO79zvKwW24ntcCmjVA4DpruqYhyPdTd8UDIreZWk7SuLzaT15\nwLlP4CUFLNNymkwTwMmDe/nd7X3MOuxXaEve9ekVknowhDzYnA8PNYl0vPP115XKOQ+mdtWDfBuT\ntjmi+iac6ttU6tXRd5u6dB2jru3O59brWsY0vTlK648epvFIgdC6/PzMg66lcs7n1Cn1QGwL4ncl\nf/Ln8qEFu6TetPFoOv6x3LSv+XxJbfJ9LQXu2/Z12rrcpU/CdNphRds+m7fr+bHv04tq2mH3+krt\nWephXb9+5T3Cmm4Gadr+/NjWpXnoQtM1rq1379Fa77QmfZZT+kyY5xyDoS1J1vecLV3D2rbnRMc8\nlrPWnbSvUT9Tgj96zdbN8v3hhhtuGP9tO95RNtF21ef47OqJnCd4S0pt9ryStrCuJMLWRPrSduLE\nicEmI/Ivx9N8NoYmiEfpy/4qigtf2u5VO66xbRHwiAt4XJxjSI8+8w/0kfY5/1KU1rmq5VHX94cU\nixOBhVRfpm07AGDZ8t5gEZzoCkTkga1Jv3vkSYs0PFh9fSkglIY8K/UGSwGsPEhVFz0vQj40VegT\n0M+fj6Rck/z5vkHCdPd3SOXeJHrI1PerKwnSp4daKUiZf5fMg6v19ec9U/J15HPflL6jx7rrAbZ8\nuK1S8DIlb0KpvpS+e6W5mUI96Dmvod3q25TWUyqHqDddPVdK2pI3k/RKKP22id8/s8zHVkrwRZ2K\n+l46l/K6XkpCt9X7pudS0r4piN+V/JnlPE3znuX1Npe3P/MI/Ob7GibtbdGWEG5bZ+lYTzIUYylp\nF8+X2vU0bG+8Jz9/8mWV6kRqv/LjW9+mrm1vk9/sEerXr9TrObal9J70vrRvpXhSWzKtzzHI2+ym\n9jMfom/aueMmrRtdbW/b52Nd6fnSOdt2DZtWbG8+lPQ0dSf/3hPbGMe+KekW25vax0nbpfxa2XZ9\nj+XWX+/67pG+a5W+O+RldLQw79kkyVYYEomwFReNYiQg4k6XSErEI/4dyYnSl9p1FfuUki6Tyr9I\nTDMG707JL3CrtN3xBS++3Oc/7Ju+vE6jzzASbV33V0FsZzofh3YerpO+82oAwCrJgxMp+dQmv8ZN\n0lMirSOk73RNAcD8PfUEVi7ufk/DCUUQJg/6xL/jN0v6nhd3Vjf11Gn7Phn7mdYdwaH68mOdfYeT\nrEv7Hd8d6omheC62PdaZ/w5pCzwnfYLeXXOmhVhPvUdL2q4Q+1o/dpFETWVQ/2wa5jI+H3UsTxDl\nAd/Y5zzoG5+LgF5eL+vfsVKwsF6W+TqTvr0TJhnarenzeSKsaZvyIOCkQ0G19YDr0yuhqUdK+u8o\n6zyhUl9GV5I134Z6maR9juNbv/kwyilvh5qS1vXfY/ny86BvSjDE7/i28yVfVqkdS2UxyXka25XW\nF6/Vj1Psez6kYx+T7Os0dbmUEG4zy1CM+efr7Xu+b2kuuyS19Xkv33wdKckU6m12Ol59ti3fvknl\n5VcP+Cep11hKeJS2pc91IvU6q7fHffYz75XT1N631as2pcRGnzkGu+Z9THNilZKkaZ/ayiwtu23I\n5Vz+PSElqvJldrU1faRzKC2nbdumaZdC/p2pdH1P9ak0ZGspiZb3cq0vO30fO5ENyVtfZmirY3Hd\niFhXnP9GhWJw9h35yOY8H8zHU089tTlqmDZHh6j1MbowbA5F2qfY70mNLjwXPn/y5MnNVfHII49s\nHj9+fHN08Wl8ffRFbLzNox+Um6si6l5+LOK/52l0Ub2w/CeffHLLa6k84u8qi2Oa9mH0xWiTnbEu\n9QUAkvw7RPy7r1GwcfyZUZBvcxLxXSutr/TZfJu6lp+/N12DR0GcLc+NkmDbPtf3mh3fmfNlxbLr\ny5/22p+2IR6j4NS2bY9/599N820pfZfv8xskviumdZY+G2WWb0e8N9/f+E3Rp7ziu3s88s+PAnzb\nPhf7mb8n/p2XRXqt9Lss/52aPlvf5njUf0ek99S/P8dv2vSZkvi9VNqmKPv69ufblG9b/fdHl6Z6\nk/Q5/lEG9bKpl3369yhhs+WzXb/58/O7Xke6yiQ9N8nvsVSXm7a9z/lZf3/TfvU5T+v1qlSf8+ea\nPtdm2n1Ndbl+vjft4yTtWFtdm6Se1Nuy9HycX/l5X49FjRIejcvO266m9qt0zte3K7231NaV5G1H\n6Zoa17XS/tflx73PdSLE8Uivx3FqE+1xqbzycutaTi61jfX6NOk1rElb+5dE3ai/Z5ZzL9TrVakN\njWVPI4959TkPJ/3+UNqP+uea2uCQH5f0vvp532fZTedEOrfb4lj5/nadM7Bo885bSYStoGiU8wYs\nLpb5hSMayvyLyaRfFlZVNORxEZ/0x0lo+2G0k9IFuvSltOv1nZB/mZx3EiyUggGh7YvyKokvIfGF\nOh6LKCP66fMlDgBWSfqOP2nwZtrvunmwpxTMyIORfb7XxG+PUnKqtI5JvuM1LT/+O55PwZlpr/3x\nu6opoBbLq+/7LEmuXCnonT6bnq8HSLvKNCndQBmfbfudGMe9Xs6xH+k3WQqOl9aZ3pN/9q677rqQ\nLK2XSVuwuE/9TvvYtk31cohtiHJNgfC241RSL6d8/ekYdp2X9d/3+bbl519eLm1JrqTtBsO03tj3\npjof9aPpfO86V9vqaSrnUvtWT6SXgv1t52lbwjEP3tbLeZqbZafZ11JSIjfNb5hSWzNLPal/ttQm\nNCXTc23l1LVt9c9OGnRPdartmpriG32vu7FNTeUQx7ypHvVJONWX31RebQnLNqk+1W9k6Upyha62\nt952lep16Zyd9txLy+w6/6Zp05O0vX3LepLvD7moo6X6VPpclFn9etZ32amcmpbdN2mbkmzTJDFh\n3uadt9oYZ8Pm6NXvfa5iNtEFNbqxRjfa6MZamrQydQmO7t317q67TZRFdPGNoTpiwvFVENuTJsiM\nbaqPOdz1+k5Jc4Etql6Vlh91Og1bEF3LS93DIagvALCz8iF7FjHM9yKHQM6XfXROw3/PQz5nchqa\nvK8Tr88nPelnZynntM5VKsdUL/Ntmsfvm/j8rPvZtG3LMs86P0s9TZ/tsx3TbPMs27aM5a2SmFMt\nxSBGSZhtcxotq9xTO7Jq5bvI68S61au+7d+8y2wVy2nafZzmvEqf6dr3RVxb0rV9Vb4fsXvtf+vN\n1TxJhK2YGL86jS07yu63jmMd412n8WpHWfrWhjH9SJ31C++kn5/mM13Sl6TcxsbG+G+MIdw19vC0\n2zRpGeZjIudfLJPSF89Ztm8eZR3JhTQBcMzvMO91p0Rvffl5ecUP1K6JrBdRtxZl2m1tquurapZt\nTeOXlz7f9Pqk9QUAgGFq+66d5vYNXb+vYTeJ+Y7SfICbm3MNCwLAXMw7EbanYqWkyRcjQdL1JT2f\n8LJpwtk0OXB88Y/kRnrUJ1Osi9cjwPzwww9fCDanz0bCqevzaeLftN74TPy77XOR1Iv11CeYTOIO\nh7QdsaxYZpoAss8k1ZFgjPfH59I21Sf5zsXkkPH+NDlsXgZRLm37Hu+t70uURzyXT65Zn1w5XsvL\nOXqL5ZNXl9YX66l/rm0bm6TyjUdK+KUySHWhrqludK27bdLx0kTiuabjmO7wbJIm7I7yb5If5yb5\n8czXEe+P5+oTT8e+p+Wl82/SY5rKNZ03+Tmbb0+fSUvz7enav9LySvuab2t+XnbVgWir0jrr53Vp\n8tn0el4WpfqS9ineP+2kywAArIf4/phGSqmL77fpxqn47eHGKfip9FvJeQHArmGOsNWRj93cZ5za\nGN81xjuOR31M8PqEsfVH21iv6T1NY83nn28a6zcm+J1mvWk876Yx39uWGc/nc1o1TVyaT47a9Pmm\n8dTTWMlN4+22HZv6hNX1Rz4XWFrH4drk1H3XV59As21dXbqWVR/TOy/zpkdpovW28bPTcWoan7o0\n5nvX/qZllsayTuVeGlu6aez3PvMbHC1M7N51TNvKNZbXZ/LlXD4Of9v+xaPpvMw/n7/edV611b98\nfPv6eZ1PEN5VFqVxwfNtLtVDAADWX3wnPZrNuxffzeN7dvx2ie+S+XfNocyrDfPSNe8eAOy0eeet\nJMJWyDwmfAwRsE5f+uMHQfwYSEmrfDLFow2TheYTdKYEQvp8vJZPilz/MVFabzzSZIulpET6XD14\nnk/wnSZvjufi0TQxZF0erM8n6oxtS59t2p48CZgmwIz1xaNtsshYftq+/Itlei5PHubriG1J+9an\nvPJgfyw/JVbqE1f3nfgzbXc9qdi03fl7onxTIjHel09o2jT5Ztuk423J0Lys8uMY685fq+9v28S4\neeK5KREU60j1Mso7aUvmzXJM87KJ5cSy47Oxj/WJYtsmXy7tY72883OrFBwoTbybn1cxKXoquzQh\nd9sy6wnNeH/93JqlLPJJngU8AACGLb4jtt2AFt/n8+/yQPvNnQCwKiTCBiwFnfsGuUvyRFdT0iYP\n5Ne/9OSB8wg41+VfmCI5lMsTJE3rzV/Pg/J58q0euE5B89K+5J+t9yTKk0VNAfG2hEaezGhLfLUp\nJff6riPvMZbLf+yVerykcqsfoy55b50mUY5t9aO+3fXkS9vyS+WV15um45gnrOrnTqoDTeurJ2Tq\nPQPTZ+vHpy2ZN49jWuptmSfS+h7XPNlV3556j656W5CfH3nZ5OdVbFOTVLZNvfvSsSr1xpxHWaQE\nPAAAu0N8R43v2vH9M75Dxr/zG+iAn0o3MOY3tgLAqpl33socYSskjdFcmh+pj5hDKY2PHpMB1+dh\nCjEG9NVXXz3+d31upfTfMdlwmjg1F8+nz9bnFErrje1vWu8tt9wyXmZ97rN8OfnnYlvS9ox+xDQu\nM9aVtqf+eppvKNYXc67V5eWQzzeUzytUWm+XWEbar6Z5y/J1jIL6xX0L9XKO/Yqyjs/E9jVJny3N\nndW23fnn69I8UbHupvoR7rrrriptd32OptLyS+UV+5nWUzqOUSdHyZDxv2N/m+pTvQxT3YrXU33M\n60BI9SfqSX58Uj2P9eaTcvepN6VjGtuSljtKQDVO9p3ve986mS8nnzch/h1tRUhlV59XIc3zFfuf\nH6/8vEqfrbv99tvHf6NM8uXGfqd9j+PaVM/6lEXehjSVRf3YAAAwbPH98JFHHqlGQf1qFOQf/zu+\nb/pOCNvFb6iIF8VjlvgTAKwTibAVkQfRZ/kikgev2yY9TZMG901U5E6dOjX+Ww9Ap/+OZaTtyMUy\nI0EQX7byHyRPPPHElvfU9yXeW0+e5Z5++unx33x/82B6Cso3ueaaa8Z/88REWl59eyaRL6MpUN/1\ner5N9ddTcqueoMmVEkBd2o5/lGeemCzJP1tPLpWWXyqPPJHXd5154qUpgRVSQi+Wmepi/npef+rr\n7bMPpXqTjkf9B3nanrZjmm9fU3K1SZ4QyutCOrfivErLKiXK8vPnscce63Ve5edifn7n7U1pH/qU\nRZ/lAAAAAACEfRUrIQ9Sp15K00iJg6aeM310JcLaejpFT6DUIy0C7HEHXmxH9ARrS8q19RIKfT5b\n354I2CfRgyX1Yqlr6jGVlhkJhGkTYV2JzT7rSO/JkwF5D5v4d0po1tV79/SR99ZpSkDkZdpWv/Ik\nT16v8+XX606pvNI6S70Mk0OHDjWus2lbomweffTRC73BUsInL7M8UVRfb1d97XNM89fznnNt5Zon\nFSepl1E2sY6UwM6TXJHky8slSedF3mMufz72se28LOnah0WXBQAAAACw+0iErYhpEhd1s/aS6EqE\npPck9fdEcDyGMoukU0qIPfDAA+NHGkqvqRdJ2ve+CYdc3gunNExdn+EBmz47S4C9T0Kx7fXSe/L9\nrffmazLJUCBd9Sc/TtMMMZIvv++xzofbnEbqEZXX7ZQUTT29rrjiivHfPCGUJ4py+XJuvPHGqs8+\ndL2n73lbGpKxyw033DCuN+nzqbdbSvI1JcLqZdS2/U3ydiJPUubHs2kf+pZFvh2GuwEAAAAA2kiE\nrakIBKdgcOqxMckweE3Jpz5B6K6eGGms6QigR8A9evTkgff42ye4Xhreri7vodK0PdFrpW0It/x9\n9XX3nYepSdcyuhI8paRkXi5Rzl0mSRL06a1T354mpXrUtvxSeZ08ebLx+bq2ZaceUSkZFEmuWF46\n5mkb03a3Dc2X71u9bLuOeZ9j2raf0yZo60Mj1pNc9WRhDGWY5qArDUnaVa9KQ13mveaa5GXRto55\nnKMAAAAAwO4gEbYi6kOldbn77rvHSaD4XApW90165HM95cOP9RluLH2uKxifgugp+RW9wWK4ufgb\nQyimbZ21F1tXcqAtmN8kH5ptHj3CmoaPy9cxyxxIcezm2Rumq7dO0lU/S3O+tfXi6SrzrnXGUIel\nZaceUbGMlASK5Ggq+/Q37X9aVtOcZPk5kh/bPvVm0XW9JJ8vLvXUrCf54t9p2M3owRniPJ1WKsNY\nblMd6DOsYlsdnMc5CgAAAADsDnsqVkI+3FyeSGgSyaiUkMqD1XlgO++RUZfmPwoxf1fSZ+i1ph4t\n8dydd945fjQNQ1hPRuUJgVLPkVJPtbpSz6r0+T7DIuZmTVb0WcYsPe/6lss0unrrpO3oGsYzJVIi\nUdfU86mtl1W9PK655ppt76nLE7tNyZs86ZqGPKwnR9O8fJEoS72hmpI1pUTwLMe01BMy1zYkY5e0\nb3kisJ7kS9uQenCGpjm60rHrOh4pEZaXYdv8gvXtSMtp0mc5AAAAAACJRNiKiGB9ChqnXhtN4vlI\nOIV6sL6+jNLnU6IizRGUTDvHUVpfPEpJvNKQZ3nypb7MtC+loHsacjHUkyt50qaUDIvlpsRAcurU\nqW3LmFTee6kpqZSXRWkdpaRkJEHSf+cJzfr6o45MMlRm6Dr+KekQyy2VaUokhfvvv7/X8kvJ0JDX\ngdI5cdttt134bFPyKi0zT4LV1xO9xkL0WAxNvcFCaXjIWY5pvqzS+ZOGa0yfn0SaAy2SU6k3WL2c\n0jaU2oYkJc7bzquoA6mc8nJsm1+w6flSWUSyrms5AAAAAACJRNgKSUHjCBjfdNNN2wL/EXjOn49E\nQz0QnObDivfWkzzp87H8+Fyfubrqrzf1xMgTcBFIrydo8m0pDZVWmt+r/vmQerakBEh9e6rXyyEl\nDCIplJdl+nyURSQ+8oB+PufYPIYdbEpGpZ5BbesolUu8P/VmisRO0zGOpE68lpdPn+3s6nGUJ1Ca\nyjSG68wTSfUka6kXT1syNA2jGZ+N/cnXGf+OY5g+33Q+hNQjKmlKctV7I5aG0ywdl1mPaX7+pN5U\noV6uTZ/vUt//pjnz8l5joZQIzIdULNWBlHCs14E+Q6/mZZGGU60vv1QWqT5E/e/qtQgAAAAA7CL7\njnxkc54PZjMK5m+ODsuFxygwvDkKJo//5s8dP368uIxRoHvLe0eB5fEy0nPx76eeemrLZ06ePHnh\n9UceeaRxuY8//viF9zz55JNbXovl5eto2u6m9Y4C2ePXRomHbeuLbepaZnrEe9u2Nx6xrnjknx8F\n67d8Jsoqno+/04ptqR+vUYJjonWkzx87dmyzT7n0OcZt2o5trn6cm8o06l/dKLlTXP6tt97aWh5R\n1/PjWN/XeMR5U5Kvu6mehTg+6T2lcyu2u3SOzHpMY9n1OlM/xqm8J5Wf27HMrn0rlVFpW1MdyI9H\n/bwK6Th37UPUsWnKYpQgu/Ce+DcAAAAAsJ7mnbfSI2zFjILk1SjIfqEnRfSCiN4N8Td6S8Tro0B0\nscdKiB4Z0Rsj9aRJQwjGf8fz8fm2eZpKw4219eiIz4ySKRe2q7Td9bnF2nqExedimamHSFpmiP1I\nw7iVeuHE50ZB9QvLjnWlnknxWpRz3rskvae0PX2lcs73s2k4yNI68t5ZTccilUte1n2OcZs+vXXS\n9uTHJC/T+NwoidQ4LGdev+rLL83zlsR+5udEPiRmbEdsT9SvkrwHWqmnU1p2aXjF0DaE46zHND4X\n+1E/7+N4Rk+3tNxphgLM615p//u8J9/WqF/18yqk41E/r0JpGNO6VMdKZZHmLqsvJ+/JaO4wAAAA\nACDZiGxYNUevfu9zFfMRwd88eDxNEDwf6i8+P4/h/rrkCa6m4e6mkZIt0+7HPMpyUmmd8yqDJoso\n62nWvawyzYdYjH1dRn1etvycTccz5vmK/Y4EU1eiapkWfV41lUWbVDeGWC8AAAAAYLfY/9abq3mS\nCAPYYfVeg7noYRfzcYW8JxYAAAAAwBDNOxG2rwJgx6QkVwwrWRc94O67777xv2NIQEkwAAAAAIDJ\nSIQB7JAYVvDRRx+9MM9bDH149dVXj//7iSeeGPcGi3/HkIMxPxYAAAAAAJMxNCLADopeX7fddtuF\nubbqIgn2+OOPL2UONgAAAACAnWZoRIABieEOY+6v6Bn28MMPj3uAxSOev+WWW6o77rijAgAAAABg\nOnqEAQAAAAAAsBLm3SNsTwUAAAAAAAADJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgA\nAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmE\nAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAyS\nRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADA\nIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAA\nAAySRBgAAAAAAACDJBEGAAAAAADAIEmEAQAAAAAAMEgSYQAAAAAAAAySRBgAAAAAAACDJBEGAAAA\nAADAIEmEAQAAAAAAMEgSYQAAAAAAAAzSvgoAAADo9MoLJ6qXv/ul6swPn65e+t7o78kT1ZnRc+PX\nTp7Y8t69Bw9XF11xdPz3wOjvgcNHq0uuur665G3vG/8bWF/aAgBYLxJhAAAA0ODs6ReqF772aPXj\np56oXnzq89sC3F2ffWkUKB97autrEQx/wzUfqg5fd8v4bwTIgdWlLQCA9bax78hHNqs5evV7n6sA\nAABgXf14FOj+7l/eNw5eRxB70Q6/59ZRIPzW6k3vv70CVoe2AAB2xv633lzNk0QYAAAAu14EuZ//\nmwer577wwFIC3k2id8ibb7ijetP/5XZDpsEO0RYAwM6TCAMAAIA5WYWgd5M3vf+O6qoP3yMIDkui\nLQCA1SERBgAAAHMQQ55NGvS+5G3vqy675kPVRYevrg688Wh18ei/w0W1IPUrL5yozr78wnjZLz/7\npdF/P129/N0vjYda6yt6hRz5hWPVlb94VwUsjrYAAFaLRBgAAADMIALQz3z27nEwusu+g4erN77/\njurwdbeMA997R/89iwiGx3xDP/jiw9WLo+145eSJzs9EEPw//8TjeoTAnGkLAGA1SYQBAADAlL4z\nCnpHz48uh99z67j3xRuu+VC1SBGIj0D4D774UOd7r/rle6u3ffieCpidtgAAVpdEGAAAADvm85//\nfPXEE0/0fv/tt99eHT16tNppZ06eqE585s7W4ciix8dbRgHvIx88NnNvj0nF9j37V/d1BsGjJ8q7\nfuMRPUJgStoCgMV48MEHqxde6D/E7D33SOhTJhEGAADAjrnvvvuqe++9t/f7H3/88epDH/pQtZNi\n2LP/449vGweYS6LHR/SyWHbQu65PENzwaDAdbQHA4sSNT08//XTv929uzjUtwcDMOxG2pwIAAICB\niqHG/ulTNxUD39Gr4tpRIPkd/80DOx74DhHYPvqx49XP/Q9PVReN/t0k9uVr//MN1Qv/+GgF9KMt\nAIDdSyIMAACAQYrA94nP3FGdPd08TE/MsfOe33ly4XP/TCOC4O8dBcBL8wDFPn3z39w23kegnbYA\nAHa3fRUAsCO+9KUvVY899lg1rRtvvHHHh5oCgFWVAt9NonfF1R87vpJB77oYou3we26tvvXHt1Wv\nNPRkSfv4pvffXgHbaQsAAImwFRUTUD/88OjL2okT1eHDh6tbb711PMk0u8tDDz00nog86kGMsxsB\nb/Vgd4lJRmOy0UiYxL/f9773VXfddddKTDjP7OK4TjLHSl18dhmJsKh7cU2Ka1Oqh7fccosk3C6j\nPQLWSQwTVgp8x/Bn7/qNR9ZqTp3xkG2/9Xj19T+8qRgAP3DF1WsRzIdl0hYAAGFj35GPzHVWule/\n97mK2ZQmn45A05NPPjlOjDF8N9xwwzjYWBd145577qkYvkiA3nTTTeO/dZEklRRdf3Ec77zzzmpa\ny2gP2uqh9mj3iOtR1INIgOXiO8njjz8+TooBu0fp90qI3yzRLuSirVjmb5jxnDm/f0PjEGgRHI7A\n9yrM/zON2Kevf+qm6qXvbv+dEPsU8xtFoBzQFmgLgGWrxw1iBJxjx44V37+5Ode0BAOz/603V/Nk\njrAVEw1G6UdlvBZ3YjN8DzzwQGMSLET9iF4ZDF8kSJqSDyG+SNQD0rAIEews1UPt0e5x2223NbY5\n8Vy8BpCLZFj+WHYS7J/+8KbGwHcMFxbB4XUNfIfY9pjHqGnos/E8QX98W3EOJNhNtAXaAmD56t8B\nDx06VMGqkAhbMTH0VJvoPcDwdc0ZNMucQqyHCC63JRi6Xod5KSXlky9/+csVwxZ1oJQMDfFaVz0B\nWJZnPnv3OABeFz0jjn7soWoo3vHRBxp7e8S+f/PfuEEBtAXaAgDImSMMqvMJxqeffrrxteuvv348\nR9sydfX0WURPoOhtWFrujTfeuCvmAoqeLyUxH9Iyh/7S24tV0ZYACerq/KW5uEpiWNRVm5dLPQBW\nwXf/8r7xfEB1F11xdNz7Y0jS0Gf/+Ps3bJsn6MdPfb56/m8erK78xbsq2I20BedpCwDgpyTCVkwk\nXdqYg2MxoideqXfNHXfcsfREWCSd2u6uj8TUvN1///3FZGAMf7YbEmGlYUlDBJ2Xef6lYYTagsva\ng/UXx7Ct3oUYKnUnkwyxjW29D7uuW0wujndbvYhrwDITYdojmE3ccBXnUJwnq5bEHpLo/fDsX927\n7fkU+F7nIdBKxgHw33q8cQ6kKIvDP3tLdeDw0Qp2E22BtgAAmkiErZhIuMSP5KYkSPyAjmQFw3fX\nXXeNgyZNQccIoCw7McfOuOeee6q777678bWoI4Jp6y/a+64EwvHjx3c0ERbXnZtuuqlxG2LbtUfD\nF98/2tqjeG2Z8//AOrnhhhsufK+P6/bjjz/u+r0gMR9Ok7d/9P5BB4APjIL77/qNR6qvf+qmLc9H\nMPzEp+8cXO8X6KIt0BYAQBNzhK2g+IEcvZDyoFL0xvHDefeI4/zkk09u6YUV9SHqRdQDAcfd4dix\nY+MkSJ4oSQHp6CUEyxD1r6k9inoY7RG7Q2qP8u8h8e9IlHb1aoTdKuZ0zW9ui6Fm48aCriFnmdwP\nvvhQ9dJ3t99I+LYPjxL17xn+DRtvuOZD1ZW/eGzb8zEs2g+++HAFu4W2QFsAACV6hK2gCDBGsCn1\nApD02J3SXcMhAiaSoLtTJD/jEbQH7JS8PVIPdy/tEUzm5MmT255LyTA3uM3Xs3+1fZ7XGAbtql++\nt9otrvrle6pTX3t02xxBz3z2WHX4ulsGORwc1GkLtAUAUKJH2IoTZCIIlBC0B6wC9ZCgHkC3GDq2\n6TucnmHzFT1AztQCviGGQdtNIrh99ceOb3s+hkV77m8erGDotAXnaQsAoJlEGAAAwJxFwrjU80sy\nbH6aeoC86f137Iph0OpiWLR41D3/hQfGQXAYMm3BT2kLAGA7QyMuWQwl9OCD09+Fc8stt2yZL2gS\njz76aPXlL3+58bWY6yWXtvPzn//8eG6D+O8k1h+Pu+66a+ptqYvlP/zww+N1xTrjv/N1pvVGICHu\nrr3xxhsn7iUVgYZYR+m1ktim++67r+rj9ttv77VdscyYN2JaUfbT3I3ftt5Tp04VPxfHpK+ubWs7\nDqFeF0va6vPVV199YfiuutiXJ554oppUrK9vsKrvPjz00EPV008/XU0jyjjKet7ivIsyinrSdC7G\neuNcjPMw2qNpeyuW9r1pv1J7lI5B2p60Lak9mkfPyVh2Ok9i//P1JbO2Ratm2nMi6Vvf67ragnmJ\nY5TPb9ZH/ZpUP/dT3YtjH+dB1IVplNqxep2ri23rc8wmaSdmaY/a2txZRDlEGcW+Nh2HKP94xLpn\nORejfWkq86b9ytvHfO6nebWNDE8aWrYp6WWYxNmVeoBc9eHprk1DcPRjx6uv/L+v2fJcBL6///9/\nuDryi/P/7girQFuwnbYAAGr2HfnI5jwftHvqqac2R8U+9WMUqNqc1iiYU1xubFdy7733bo4COr22\nJ5aZf3aa8mjbrrbHKLC5OQoc9F5XvHeWsu/z6Ls9x48fn2k905b5rOudx7Z1HYe+2upN1I2SqN+L\nLoO+YjunXccoYLY5b5Oc++kxbRvQtu/JyZMnN48dOzbRtsRnphGfm2b/ZymDvkbB+OK6Y5tnNes5\nMa1ltMmTltG016Q4H2M9k9a/aa9/k2xXX7O0R21t7jSmPR+nPRdL51hefrFNoyTXQuodu0PUzahT\npbq2yOvIIrRdOxbxHaXkf//XRzf//v9RbXk89ek7Nne7KIN6ufzD//y+TRgqbUEzbQGw07rikNBm\n3nkrQyMyFndCx12pN9xwQzX6Ydt5N3oSd5BPO6xL3IEd64tlTCPuxo5133nnnb23F9humnM/ifP3\nmmuu6d1rsu/2pG164IEHen8utUeT7kP06ph2/9N64/Oz9PZl581yTYr6GvUnPm+Ys9nMcj7O+1xM\nxzK1R9E7ra/Y/ttuu62CJPUMM0zi/Pz4qc/rAVLwpvffvu25l7/7pXGZwdBoC8q0BQDwUxJhjMWw\nQ/EDPB/mp6/40R7JqElE0PzYsWNzSWClwJdkGEwuBd+mOfdzEfSdVzIstmXagGB8dpL2aJZ15aL9\niTZtnglBlmde16SUMJn1fNqt5nE+zvtcTDfdTLNNkTi7++67K0gkw+brB1/cPrxuzIlz4PDRarcr\nzQ/0wtemH5odVpW2oExbAAA/JRHGWPS6mOWHdwSK+s71EndqR9B8nmLb3XkNk5l30G1eybBIZM2y\nTRF87jOvXWo35plEjzKYZE49dl7Ul3lek6I+zbte7QapPZpXucUxnUfPsDiWs7RHs36/Yngkw+an\nqUdDU++H3erKhjmAYh4lGBptQTttAQCct6+Cqmr8wZ1+oPf9MR49s26//fbO9XQNdfahD33owkTz\nMfl8iLvEI9HWdpd9BJ/jEZ9vEssqTUTeto/xubQd604ZVNWhQ4d2fRkkfRNOk7QFEXy+8cYbi+dh\nH02B8NiGeL5vkDwScl3bEO/pOua33nprdf3114//+9SpUxfamVnXzXJEvem6LnX12Il6cMcdd1RX\nX331+L+ffvrpcfKsre7Ea5GEueee9iF5pm2PSp+Z9n2roG8SbNL2KH2fmNY82qOoC/fff38FSUqG\nNSW9UjKslCzjvKah0PYePDwKft9RcV70AokyOXv6p21V/DvKrqmHCKwjbUE3bQEAnCcRtmQRUOu6\n83zevaUmET+4jx8/Xr3vfe/bEvRPPb7a5k6J90SiKj7b9p5S8CrW98gjjzQGkOO5GOookmhtQcu2\nAHRs11NPPdX4WgQcSsHtCIRHmcxTbEvbcY4ymnbutDaxL/FoEsc+ArxNouy7ArrrIvYlHk02NjaK\nn4u61xVQn1Qsry1hEsH2RQ2xFvWrK6ETxzzKKm8L0lBfbUHoSLCVzrVJRNnENjS1R3Gut21/vBZB\n6lLyMl5rO8dinRGErH8+tqfrjv2upPyqicRlW3sUdXCSuZH6ijKepW2NetiWiGjrdZG0XZPCXXfd\n1XjzRiQ1uq5H8Xp8vi2BHu9pWn5sU8y9VxLlNu/61dUexfmyqF4qfZLSUZb19ii2qe2zUT+iPYp6\nMKvUHuVlFMuPOtTVJsZ2SoRRJxk2m6ZhvQR0t4rA9+H33Fr94MmHtjwfZaesGAptQTdtAQCcJxG2\nZBHA6Uoo7FQiLIJgEZBrCtpF4Cce8Vpbj66Ya6wtEfbYY+WxqCNI1BXYiyBY9MoolVFX8HtVRBl1\nJQwXkQhjtUQvkzYRCFtUIqxrCMMItDdtXyRS4zxtm1cstnvWRFC0k6XzPLVHMWRZW4ImtqGU+O0q\n19j/UjsSQclI2sdcUCXR1q1LIiyVZ0m0RYtIhKWeVtPoSoKlGyu6Asht16T4bNv1rut6FNsX9Wxd\n6kHXsehKGs6i7XoXxzKSAU3XzNjm1B4tMjFdao9Sr9GuNjHVhbbrPruTZNj0XmwYCu3wdbdUbPWG\nn7lxW/C7qexgXWkL+tEWAIA5wnhd/MCOQFRXAimCQW3v6Qoud92930cMczTtOoDugHac521B8RSY\nbmsLZpkrLILKfW4I6Lqp4Mtf/nLxta7eJ10B63i9LbC+qIQB5+tW1xC7qWdzl7brRZ/Pd/X4aquD\nnNfV0yxukmk7FimR0KYt4dkl2sKu9ijqQFePL3WBEnOGTS6G9Hrpu9t/c7zhZz5UsdXh67bfEBRl\nlw+RButKW9CftgAAJMJ4Xd8kVFeAeJYkVPQm6yMNcVh6uGsW2rUFhfv20on3lYaYDKl35jT6nsPR\nFqR5m5q0BQ5jHzc3NxsfJ0+erPquv0RCfjEiCdaVlIgEaaknYF0kzEr1IHqUdYnzIOb5KlEPunX1\nyuvTHnW9b5Ye1n3bo9RrvkQigzaSYZNpCnxf8rb3VQcOH63YKoZEu+iK7d+VmsoQ1o22oD9tAQAY\nGpEpRPC3NDdPV9Cv7bMR3EzzgHSR7ILptc2tFQmEvudXDKfalpRoG5pwXmJ4wtLcdou26kOwDk0M\nz9gnCbaT82wyua72qK9oj0oJr2UNTRhtZ9vwiDsp1h9zvUrOrrZIqDbVY8MkbvXSs9t7WAp8l112\n9KbqlZMPbXkuytDcQKw7bcFktAUA7HYSYUxsluBvDGvYNedKvB7BrxtvvHH8Y9+cGjBfbUOYxnnX\nV5yf0R6UAqvLSFAtKhkV+5SC56X9W9T8bWwXZX3nnXe2viduoph3EiyOfddcfTFPGNNJ51lJ11DI\nua7vCjE04aK/T7S1RzuZgNKjaBjScXzyySd3/Y0YZ144se25i9/m90LJuGye3PpcUxnCutEWTEZb\nAMBuJxHGUsWdrnHXdtyVXBI/9CMZlhJmaTjGeESQPv66Gxam0xUInfTcausBsW6JotjeGKYteqi0\n9VJhuaLO3nbbba2JhLi2dM0b1lcc+6gH0QNN4mCxutqISdqj+K4QQ6WWEvC7+VhGfVaXhyGOY3yH\n7jN6wpC93Dgc2vUVzfZdvH0I3zMnT1Sw7rQFk9EWALDbSYSxdBGsjDuz+wbJI/iZAtMp0BlBz5gP\nJPUaA/qZdyIsEtPr3jMqyiR6G0l+rZ4+PVmizvaZz6tLHP+Yg0w9WB2TtkdXXHFFMRFmSEAYjrOn\nt5/Pey82XHHJJQ09ZPQCYQi0BZPRFgCw2+2pYMniru0Y1iXmcplWBCojERYB0ghcAqtnHXogxJ31\nMc+Y5MfqicRF9ATrSoLFnDmzDhMW15G4nqgHyzXvNmJVhybcadET301DwxDHcZIhQ4fq7OmT2547\ncMXRimZ7D25vG1877eYA1p+2YDLaAgB2Oz3C2DExl0sks2bpiRFBtFhODGE1j2AosHtEuxFtEKsp\nrg1tvQ1TEmzWAH8kweY9txiskvhuFOdKtHnmtFtt8b32oYceanxtXm3eELxycnvPz30H/QYoaeoh\nc/ZlwW/Wn7ZgMtoCAHY7iTB2VPpRHz/8H3zwwXFCbJph1uIzaQJxoGzeAbSu3jqr7O677259Pc1p\nGH+b9kUCZXHi2ETQvk0MhzhrHUs3U7SJZGnUgxgGtOlmi9iG0nB8tOs6ftGLa5IbXNp6fe325EHs\n/7FjxypWVxoKtokkWLe9gt9FTWVzVi8QBkpbUKYtAGC3kwhjJcQP+/vvv3/87wgERGLriSeeGP+N\nR58hjeJ9EZieZchFGLquoHKcR5ME2trOzVXuoRl33Lcl8aIdkeTaGdGOp/kgS44fPz5OTM1jXSVR\nfyPZFolQFqOrjZg0EdZ2Tusxziprmw9REgwAAGB25ghj5cQP/VtvvXWcGIsf/idPnhz/jTuZu4IA\nXcHTEgGy1bEO80qts6jrbfV90p4tXUPXraqYG6wkEh+SYDsjegZ3lX0kKec1pGVpCLK0Hkmwxepq\nI+KGmL66bpq5/vrrK1hFkmAAAACLJxHGWohgZCTGnnrqqdahfSIINs3Qim2JgT690YbgiiuuKL42\nz+TUuiYdh1QP2oL7XcPR5R577LHW12+88cZqVbW1E5GIZ/mi7nUN3TbPnnpdc1PuZD3oaieHMhRj\n7Gdbz75J2qOua/88ehDCvEmCTcfwXpNRNgyVtmAyygaA3U4ijKW57bbbqo2NjcbHJMGuSIgtM3HV\nFSwdirYynWcibF49ABaRmLr66quLr02TYF1VbYmwqO9963xbb5o4zqsceG6rP231gMWINubOO+9s\nfU/M07XMnno7GXzuM4TpUHS1R33b+rZhLkvzu8FOkgSb3r6LD2177jUB3qKzL28vmwNXHK1g3WkL\nJqMtAGC3kwhjadp+zHf1LKk7dOhQNU9t2xZBuEkSdeuqrQwmSY506Rqary25km/PIo5JW6+4WN9Q\nhm2MhEKbu+++u+oSx6ntGKzzkHJ9ettEXehTV+mWgsFtCY9IZCy7vPskm+IcWFTvrLaEbJTFUHqp\n3nLLLcXXYh+7EqQhkmBt7fNdd91VwSqRBJvN3oPbv6+de1nwu+SVF05se27fQTcHsP60BZPRFgCw\n2+2rYEki2FWawyuCehE47wrQh67A4zSBg66eKxGI69PDJQIa6xq46FMGfQIzfcogjnUpiRJJrpgn\nqBS4jM/1CYxOI7arFPyOgGz0anzkkUc6E6dhlXsfxLbFHEulxEKUQexr9L5s2tc4Bl3JshjCbpVF\nGZQSCdFORXtVOs5RR6MOms9udm3B4CSOQ5x389Z1jkZypW29feYzm8UNN9xQvNalBFHpHM3fF1a5\nPYp2Nx6lmy1SexP72qTrOET5mOuNVSIJNrsDh49WL3136/e1l7775erit61uT/SddPb0qW3P7Z1j\n8Du+N5a+P8fvC0PT7g5xvS59t47hphfxXURbMJlFtwWh9Psyjr/h53eH+H5T+l7vezmw0yTCliwu\nCtdcc001rQhex6Mk5tBa1R/PccGLbSsFPGO/4oIZCZCmH0zxxToCXqVkWr6OScVcRm2B8Xg+gpKx\n/HyIpXg+zUuW9uvkyZNVl/iCOEsyp60Oxf5HPZhUBP7b5udJdTcFLZN6GcT6n3zyyapNJDzbehPF\ndsTrsZ7oFXHq1KnxshfdK6stWRtiH6MM4kt8Xkdj/2O7UhlEXT5+/HjVJQJh0/a0i/XEsKIlERhu\nS0bFa20/WOO12J84BmmurzgO8XzXNsf+r3oQL45h6YdaClJGGUb9i32JcophO/vsf+jbW2fWtiC2\nsS0JEMcvgqptIuEzS0KnrR62rT8ll7vO6XhfHI9ZNAWWU1vedg7E+R5lc/3114/fG9ua6sGihyds\nu2EgbV9sQz3IGNuYt8nRnpaSSLlZ2qP43KztUdu6o12O/Y3zNo5F6NsexfVGUoFVIQk2H01Deb2m\nF0jRS89uv17NM1EQI3uUvkdE+y0RtjvE7/TSNTm+0ywkEaYtmMii24JQ+l0T1zaJsN2hbcj7iBNI\nhAE7SSKMpYrkQFtAM4LC8YgvyvXAXp8ESJ8eZU1SD5m2JEjoM0RgBCDXcS6SdHdO1/51lUGf45R+\nDLUlC+Y5HGNfXcnaJIKvbQHqdZi/J/Yzgs9tPbvS8H+TDEmXlrvqoq1o26+U0JzWUIatW6QImPQ5\nV1KyfREiSdSWBJy1HsySuE9zorXte7o2trVHi7x5YF6i7Y1j0XYNjv3oukbXRXu0zHnloI0k2PxE\nL5C6l7+3+t+9dsrL391eNk1luAjmZ2SRtAWT2cm2AABWgTnCWKoIdvUJkkfgLyVC4tEnkBfLnSVg\nGT3R5vFjbR2CjiXzSGD0CVpHOc+6rlmOdZs+PSe6rEsdiMBzWy/AScVxXZdAXr1n47ytczuwLKtQ\nRtHuL7K+zpLAm0c7GdYhMR+i7Z32ZpYmKbEAq0ASbL4uuer6bc/9+KnPVzQ70zAvUFMZwrrRFkxG\nWwDAbicRxtLF3dnzSDbkIlg4613fEYCYx3Z9+ctfrtZV30Rllz4B7kjATBv0jG1cVK+jGLJh1mUv\nsgfLvEWdn0dZrmMgr2u+ty5dw3usSwJiN4tkU9SDWW6CaBvyadZerbO0k8k69U6MXprzSM5LLLBK\nJMHm75KGobzOnDxRnT2tN3ZdlMtLDb1ALjGHEgOgLehPWwAAEmHskAh0xTxWs/bISAGEeQ19FL2M\nZg2O95kjbJV1zeXSR9+eHtMEPSNxE9u4yKFWllkGqyD2N4YtnbbeR0IozsN1mwMi9WCbtHdhfC7q\nYdc8cDFnBqsv6m3Mazhp/U/zIbZdf1Lv5lnMmhxKcxiuizi34jFtexS9/KY5nrAIkmCLsffg4cbg\n7Qtfc92ta+odE2UXZQjrTlvQn7YAACTC2EEpAJAC0X0DARGEjgRafG4eybS6FNSPbeqbbElzjMXn\n5jnU3E6JwG6U7SQJgjh+se9RBpNMhJsSCl1JlDjOsU2pfKPMF50Mi/VNsi95GaxbUiiOdQSP+xyL\nkJ+HsyaPd1Jsd+xzPLraktjnOL5RTvE3lUFJ27xNrJaoB3G+90kIpyELox7EuXLjjTe2tkXzSIim\ndnKS611sW2xn7Ne6nZ+pHe2bEEvnZnwm5hEzJw2rIkYJkARbjMuu+dC25wyJtl1TQqCp7GBdaQv6\n0RYAQFVt7Dvykc1qjl793ucqmFYMJRYBg/rwgocOHRoHtiKwF0GDZQa54m7+2K5Tp05tef7qq6/e\nsk1DFb0JYv9LZRD7HmUwr/nVYj358Y91RDJqJwObpTLYyXq5aE3HIsz7mK+atN/xNx3rOM6xv0Pd\nZ7ZruhZF3U/1YCeVzs0ht0el7warckygJHp03nnnnVueG0oS7L777iv2iE03FyxSBLq//qmbtjwX\nPRt+7n98aq49HOJ3QPTqW5R0U9GifOn/dcW2YeKu/cTj1RvmGABvqwtxDsxz/sed0raP8zCP0Sh2\nWpwnpV7wMWLKor6XLKstCNG2Pf3009WiRFuwqDmMl9EWhI2Njcbn0wgM6y6+j15zzTXVIm1uzjVE\nu3Rt180htHWh6fvdPMVNyl2jz6yTrvJa9zrPYu1/683VPO2rYIWkgNYkvXAWLb6MLuoL6TpIvV6W\nUQbx4yIeq3T8wzLLYFWs6rFYtLTf7G6reC1KduO5ucrHA9pEIOPBBx+8MGeknmDzE8HbCHLngd34\n94+/9fnq8HXaivCDLz60LfB90RVH5x74bhM3LLC7LXoUD21Bt2W1BW3z0rru7R71m6dzbioFdpqh\nEQEAABYg7oCPIYTjzl7z183Xm95/x7bnnv/CgxXn/eCLD297bhFDobXNQ6nH7u6REv51y6gD2oJ2\nq9AW7OYbi3ebtnpw/fXXVwA7SY8wAACABdltvRmbho6KZOC8A+KHr7tlFOx+YMtzMUxaPN6wy+e+\nOXPyROM8SW96//yHKSwFPSPw7e7/3SF6ApV6Ay1jaExtQdky24K2YSNjTl12h1JSPG4EkhDdHWJo\nzPy7QVtvUVg2iTAAAADmpp4cWUQQJALcl7ztfdVL390adIveD7s9+P3sX9237blFDIUWx7k0L9QQ\n5gajnyeeeKL42jIC39qCsmW1BeHRRx9tfD7NL83uULomSILtHjFP7CLnU4RZSIQBAACwdt54wx2j\n4PexLc/FfDhXffie6sDho9Ws0jyxi7KIYaKiB0iUQd3bfvmeat5KAc8IfMcceUMRc50tsh6s+1xq\npQRI1IFlDQe76LYg3HDDDdt6u87TvHtQLrMtCKX24J57FrO+nSKhUxZ1oNRLeEj1YB2/GwDnbew7\n8pHNao5e/d7nKgAAAIbpvvvuq+69997e73/88ccXEjQ6e/qF6iv/+prx31z0drj2E49Xu9GJz9y5\nLfgdPUDe+z88Vc1bDH/UFPyOOfGGlAijrGko1CR6BSwrEaYt2G6ZbcFDDz1U3Xnnnduej+Mf9YDd\nIepA1IW6uB7EdYHdIc77SXqEbW7ONS3BwOx/683VPO2pAAAAYM3sPXi4uvKDx7Y9n+YH2m1e+MdH\nl9obrCkJNrTeYLR7+OGHG5+P3h/LSoIFbcFWy2wLQqkeSH7sHpEUb0qCRTswtF6BwPoyNCIAAAC9\nHTp0aKlB7jZHfvGu6vkvPLCtJ0j0hrjud54cB8h3i2c+e/e256IHyJvef0c1b4899ti252K4qOj9\nx+4Qc/+VkqGT9BidF23BTy2zLfjSl77UWA8i+WEYwd0j6kGT+++/f2W+L7Ac0Ut4Y2OjglVkaEQA\nAADWVvR8iGB3XfQQecdH7692g+/+5X3Vs39177bnj37s+EKC3yHu/o9hMtOcMI888kh16623Vuwe\nqRfIgw8+OE6MRcA7kqE7FfjWFuxMWxD1INqC1CPo9ttvb+wdxLDVrwmRDN2JpDgwHPMeGlEiDAAA\ngLX29U/d1DgEWswPFPMEDVkMg/bNf3Pbtucvedv7qvf8zpPVoqWAtyERd68IfEcy7K677trx3h/a\ngp1rC6IePProo+O2IHqIsjvFNSES48eOHasAZiERBgAAAJkzJ09UX/v9G7YNixbDoV33f3uyOnD4\naDVEsd//9Ic3jf/W/dz/+NRg9xtKtAUntr2mLQBgHc07EbanAgAAgDV24Iqj1VUfvmfb8xEM/6dP\n3bQtKD4E430rBL7fNioLgW92I23BVtoCADhPIgwAAIC1F/MANQ19FsHhrw8wAB5B/abA9+H33Fpd\n9cv3VrBbaQvO0xYAwE9JhAEAADAI7/qNR6qLrji67fmXvvul6pnP3l0NxdOfubN6ebRPdbHv7/hv\n769gt9MWaAsAICcRBgAAwCDEPEA/8399ZPy37gdffKj6x4a5g9ZJbHv0aPn+aF/q9o32+dpPPG4Y\nNKi0BdoCANhKIgwAAIDBuORt7xv3BmkSvUG+NgqAn3nhRLVuYuizGALtx099vvH1qz9+XOAbMtoC\nACCRCAMAAGBQYn6gox873vhaCiK/1DCc2KqKgPc//eFNjUOghatH+xrzAQFbaQsAgCARBgAAwOC8\n6f13tAbAY2i07/7lfdWqi22MIdBim5tE4PvNo30FmmkLAICNfUc+slnN0avf+1wFAAAAq+Cb/+a2\n6oV/fLT4+oErjlb/+QrOpxM9P5757N3Fnh8xD9B/9tH7Bb6hp2gHTnz6zuLcYOveFpz62mPV2z58\nz3hISABYd/vfenM1T3qEAQAAMEjRg6ItCRaid8VX/vU11YnP3LkS8wVFkP47o6B39PwoBb4vGgXs\nrx0F7CXBoL8YMvC633lyfP40Wee24PR3vzxu66J32/N/82AFAGylRxgAAACDE0mwZ//q3mpSMYza\nVR++Z+m9QiLoHQHs577wQLHHShjPefTx4yvXawXWRSS8vvnHt3XODbYubcEL//BY9cz/emzLa1f9\n8r3j3mEAsK7m3SNMIgwAAIBBiSByPTCcRPA4hhrrEkHwN73/9vH7Fym2Jba3q+dauPIX76re8d88\nUAGzi0R5n7nBVrktiJ5iX/v9GxrfE0Mkvus3HpE0B2AtSYQBAABAwQ+++HB14jN3NL4WPSSip0T0\nCPn6H95UvTL62yXmDYoAeATCI7C89+DhahbRwyN6orzwtcdG2/pQa4+PJNb79o/ev/BAPOw2694W\ndPVuW9V5zwCgi0QYAAAANGhLgjX1pnr+Cw+MHg/2CoInEYC+eBSMvmgUWL74quvHwfC9Fx8e/3fu\nldfnGIoeG2d++PT4v1986vOdw7Hl9o2W/ZbRdkfyDlicdW8Lnvlf766e/5vm3qKxXfG5aAMBYF1I\nhAEAAEBNBJn/6VM3NfaqiB4cRz/2UOPnokfFs39137hHxqpIQe8jHzw2c68ToJ91bwu6hno0bxgA\n60QiDAAAADLTJsFyEQT//pMPVT/84sMT9QqZJwkw2Hnr3BZEL7Nv/fFtxe0+/J5bq3f8t/cbKhGA\nlScRBgAAAK+LoPXXfv+GxiRYzKdz7ScenzipFD1CYt6eF/7x0WrRIuAdw6tFTw1zgMFqWce2oGve\nM/OGAbAOJMIAAACgOh/w/adRwPdMQ8B32iRYLpJrP37q8+NAeMzpM6/eIReNAtGXjQLdb7jmxurw\ndbfq/QUrbt3agtjeGOaxbd6wox8/Pu4hBgCrSCIMAACAXa8tCRbB5ff8zpNzTzDFul763peql579\ncnXmhRPj/46Ac/x9rdYjLbYhRK+L6IFxyVuvrw688ei4x8dFemLAWluXtsC8YQCsK4kwAAAAdrWu\nJNi1hv0CGIthHU98+s7G4WPDm95/R/WOj96vZyrwf7Z3L3BSlff9x3/AwgqCLKDcArJAQgJqAE3S\nBNoImmijaZRom7QxitWkaaIBE+3NJmJs2qaaCNHcDFZMzD9NqwFtMTGNgmnE5qKIFyhEYAmEmyDL\nRRYWkP/5nplnePbsOXPb2Z3Lft6v17jDzJxznvOcM+cZf7/zPA9QUUqdCOtpAAAAAABUCZJgAJA/\nDX846bqVmZ5pUZoHTfMsqmcbAAC1ikQYAAAAAKAqkAQDgML1SQ8XmzQnWHhtXTgznAcNAIBaRCIM\nAAAAAFDxNKwXSTAAKI6GPhx/xeLEOcF0bV0XJMOyzSkGAEC1IhEGAAAAAKhoYRJsIUkwAOiokefN\ns8bL7kucE2zrE/Ns89IbDACAWkIiDAAAAABQsVwSrGXbc+3eqwsCuSTBAKAwQ86enXXesJ0r5tsL\nd4xl3jAAQM0gEQYAAAAAqFhblt5AEgwASkzzhk24ZpkNGDsj9n03b9jBmOsvAADVhkQYAAAAAKAi\nbXroatv17KJ2r7skWN8RUwwAUJw+6aFls80btubuqbbzqQUGAEA1IxEGAAAAAKg46gkWlwSTN1x8\nJ0kwACgRzRs2OriuJtn86FzmDQMAVDUSYQAAAACAirLt8Vttx4r5se+Nuew+O/Xs2QYAKJ2h0+ba\nWTduzDpvmHqHMW8YAKAakQgDAAAAAFQMJcG2PjEv9r1RF99JEgwAOombN6xfQo9bzRemecNIhgEA\nqg2JMAAAAABARciWBNMcNsOmzTUAQOdRMmzidStt6PT4663mDVt9F/OGAQCqC4kwAAAAAEDZ5UqC\naQ4bAEDXGH3RneG1N86xQ83hvGG6bgMAUA1IhAEAAAAAyookGABUHl171Tssad4wXbfXPzCLoRIB\nABWPRBgAAAAAoGw0vBZJMACoTJovTPOGJSXDmtcsYd4wAEDFIxEGAAAAACiL3c/eHw6vFYckGABU\nhnznDVNSDACASkQiDAAAAADQ5ZQEa3podux7Q6fPIQkGABWk10kNOecN0zCJzBsGAKhEJMIAAAAA\nAF2qZdtztnlpfM+CIWdfFQRb5xsAoPLoJoXxVyzOOW+YEmMAAFQKEmEAAAAAgC6jJJjmk4kLkioJ\n1njZIgMAVK6GiZfmnDds9d1TmTcMAFAxSIQBAAAAALqE5pFJSoL1GzHFRl9MTzAAqAZu3jAlxeK4\n6z3zhgEAKgGJMAAAAABApwuDovcmJ8EmXLssnIMGAFAddM3WMIlJ84bpus+8YQCASkAiDAAAAADQ\nqVwSTH+jNLQWSTAAqF5u3rCk67jmDdu89AbmDQMAlA2JMAAAAABApyEJBgC1T0MkTrpuZeK8YTtX\nzGfeMABA2ZAIAwAAAAB0inySYH0aGg0AUP00b9iEa5blnDfs4LbnDACArkQiDAAAAABQciTBAKD7\nUTIs17xha+6eyrxhAIAuRSIMAAAAAFBSmgeGJBgAdF+aN2z0xXfmnDcMAICuQCIMAAAAAFAyYRJs\nIUkwAOjuhk6bm3PesDXMGwYA6AIkwgAAAAAAJeGSYC0x87/UndRAEgwAuhk3b1i/EVNi39d8YeHN\nEyTDAACdiEQYAAAAAKAktiy9gSQYAKANJcMmXrfShk6fG/u+ehC/cPtY2/nUAgMAoDOQCAMAAAAA\ndNimh662Xc8uave6S4L1TegNAADoHkZfdGc4b1iSzY/OtW2P32oAAJQaiTAAAAAAQIeoJ1hcEkze\nEAQ9SYIBAETzhk3MMm/Y1ifm2TqGSgQAlBiJMAAAAABA0XT3/o4V82PfG3PZfXbq2bMNAABH84Vp\n3rCkZNj+jcuZNwwAUFIkwgAAAAAARVESTHfvxxl18Z0kwQAAsTRv2Jk3bsw6b9jqu6ba7mfvNwAA\nOopEGAAAAACgYNmSYCPOv8WGTZtrAABko3nD1GbEOXao2Zoems28YQCADiMRBgAAAAAoSK4k2Mjz\n5hkAAPlQmzHh2mVZ5w1b/8CsMDEGAEAxSIQBAAAAAPJGEgwAUGoDxs7IOm9Y85oltvruqcwbBgAo\nCokwAAAAAEBedj61gCQYAKBTaN6widettCEJ80u6ecOUFAMAoBAkwgAAAAAAOe1+9n7b/Gj8vF8k\nwQAApdDrpAZrvOy+rPOGaZhE5g0DABSCRBgAAAAAICslwZoemh373tDpc0iCAQBKSu3K+CsWh4mx\nOOqdvHnpDcwbBgDIC4kwAAAAAECilm3PBcHG+J5gQ86+ykZfNN8AACi1homX2qTrVibOG7ZzxXzm\nDQMA5IVEGAAAAAAglpJgaxfOjL3jXkmwxssWGQAAnUXzhk24ZlmYFIujecPUTh0M2isAAJKQCAMA\nAAAAtOOCi3FJsH4jptjoi+kJBgDofEqGaZjEpHnD1F6tuXsq84YBABKRCAMAAAAAtBEmwe5NToJN\nuHZZ4rwtAAB0Bs0bNvriO3POGwYAQBSJMAAAAABAhpJfSoIpGRaleVpIggEAymXotLk55w1bw7xh\nAIAIEmEAAAAAgAwluTT/VxRJMABAJXDzhqmHchzNF3aspdkAAHBIhAEAAAAA2tDwU/5cLC4J1qeh\n0QAAKDclwyZetzJ23rBRF99pfROSZACA7qnOAAAAAACIUDJMXn32fpJgAICKpLaq7qSGzNxgQ6fP\nsWHT5hoAAL4edcMuOG4ldGT7YwYAAAAAqA2aM4zhEAEAlUzDIW57/FYbf8ViAwBUv97DL7RSIhEG\nAAAAAAAAAACAilDqRBhzhAEAAAAAAAAAAKAmkQgDAAAAAAAAAABATSIRBgAAAAAAAAAAgJpEIgwA\nAAAAAAAAAAA1iUQYAAAAAAAAAAAAahKJMAAAAAAAAAAAANQkEmEAAAAAAAAAAACoSSTCAAAAAAAA\nAAAAUJNIhAEAAAAAAAAAAKAmkQgDAAAAAAAAAABATSIRBgAAAAAAAAAAgJpEIgwAAAAAAAAAAAA1\nqc4AAAAAAAAAAAA60bFDzXZw23Ph814nNVi/EVMM6Ar0CAMAAACAKrP72UX2zM09wsfh5iYrRrHL\ndZZc+1Rp5a10qi8FmwAgijYEudCGtKf66IzzaOvjt2bO3Vqm+lv/wCx77rZBtm7hzMwD6Cr0CAMA\nAACALtK85mHbsnSuFetN1y6z+oZG6ygFIprXLLE+gxrtrBs3WqVreujqMMhZLeUtty1Lb7AdK+aH\n9TXpupXhHdcAqh9tSHFoQwpDGxJv9d1TrXVPkw0YO8MmBN8lFGZtkPRqSfcEqwvOqV59Gzi30KVI\nhAEAAABAFznWsscOB0GUcmvZvjL8q4CO7tCt9EDEgY2pgFO1lLfc3Dmm+tLwQwraAah+tCHFoQ0p\nDG1IvGMtqR5y+zcut0qic7p59ZLw+YBxM6xPCZLdpaYkvkuCDTn7Kht98fyK+h7qXHfHtWHSpVwj\nahSJMAAAAADoItnuIt700Owg+LQp/MyI82+J/Ux9iYIbo4IAxO5n7rf+486tiv/Zr7bylps7f/qO\nnEwAE6ghtCHFoQ0pDG1IvMbL78ucR5VECTr1epTGyxYFiaZGqzT7NyzPPB95/ryK+x5qyEtXhxMG\nNXLe1ygSYQAAAADQRTTMkB65PtPZ/wPeMPHS8FEtqq285aaJ58dfsdgA1BbakOLQhhSGNiQe51Hx\nXG+68BpWgT3W0D30NAAAAABAzeiMye2rZZ2Frr8jZeho+YtdvrPqrVz7A6Cy0Ibkv37akNKttzOP\nZ2cfy85cX6W3rZXwPeyMZStpGygdeoQBAAAAQJXTvAbbHr81nMvD/U+5Gx4rrmfA5qU3hHM19B0x\nxUZffGe797WOnU8tsN0rF7WZj0brGnL27HB+h2Jom9p2XDmzceXVUDr+Xepax/oHZoXPtR9Hg39H\n60F3tg+dNjdT5ri6in4mye5nFwWP+9vMD6Lya9uqy6Ryu3pWnTavWZJZXvujuShGBvufdIe05q3Y\nsWJBuG1XXi3XL73OuO267UjSMGpuvXuDz7ljnE951i2cGf4dOm1OOBeJtrVjxfxM2XS396lTZ+c8\npgAqB20IbYivGtsQV2Z3jHWM/PMvrmz5fMaX67yPW6froal1Nr/0cFjG/ul/J3HnWPQ80dCMfrk0\nlJ+b985RXepYy5jg8/kMh+qOib6b/UZMDvfTbXvSdSvbnCNx3+1s9ebWfTA9P5h6hrnXJO78Svqe\nJF07/GOvOlL5NWeayjrivHlZ69qVxa9DLV+XHroxrnxJ14AhwXnbcMYl9HirYCTCAAAAAKCKvZIO\nIkXpf9T3L1we/k98NJCpQE7SZO8Kqqy9d2b4N3adwUPvFRqkUlCj6aHZllTOuGBctLzRIcEUUHH7\nsTUISrjAnU+BCm3XDcuz+dG5iZ9J2i8XLI2rM722+u6pNjIItkSX9et5UxCw2pUOTvnrVcBHn1Gw\nKTpnhpZfGwRponcc69/Ztnswy/HNtd5UAGpR7Hrd/oqOxeZHb2h3nujfW5+YF8630XjZfQagstGG\nLA+f04a03Z9qa0MOesdY+9WSTrxEy6bPvDk4p18OjkfSZ5REmXT9ynYJjWznvZZVnUTXqf3ZvSe1\nXSVXVM5sw5sqwaL9jwqP111Tw+9jv/S5fmDjsnBewGgZC9XmmCydm9jLKem77debElH+8JHR+nLn\nXpK489ytJ+naET32cdeeJHFlyVaHScdHZTi4ba7teHp+eH6RDKtMJMIAAAAAoIopgKmgyKiL7wyD\nAArWKZin/1kX/R1w7Yy81+eCHArYaJ26y1fBNQULFKA4nA5S9R05Oe+5MrQ+BVdE6z1t+pzwzl73\nntZbTPDGp312PQNcPbjeAwq8qMz6Wx+8NyYIrrlA1IENy23bE7dm9mvwOVe1u4Pavzta6x82bW5Y\nJwp8qOz6q2X7jzs3tvdEKoBjNjTYb/UaEJVvWzrwGt5ZHwSjo3ctv/y9WW3KrOMcdyySthsnDGSl\nA5i51qs6SurhoKCXjqXqI3ostbze17JMOA9UNtqQFNqQGZaPSm9D3LkXXa/rNaTnSiip/KpPnYPu\neKuXkz6n95oevDqxN1wcHQt3DkbPI/d9as1jPaq3pOVVri3BueTK9aZrl2f2z/VsGn3xfBs46ZLw\neX2ByRjXk0znmHqGiZ+087/bI84L6vec2e2Ou+rtrJtmZJKyZ960Mfy75b9uCPdD60uqV+2bS4K5\nc137oO+HO9ezna8uAab3GiZeYr36NuScU9GVT99j9bCT8R9ZHFyf2ifW/SSY32PWJQKVTHffj7jE\nNMqPOcIAAAAAoIopAOXu2FfAQP/WndguAKQAhe6szoeCOC6QoACm1uH+R17rn+j9j72CRfna+sSt\nmTuMx12xOCyfyqqHW2+/LHfz56M+HVzx60HlzwQN09v3P6OHPjPGu+tcQxf53N3tojpR2V0duLqv\nTwdaXOA4jgImoy+an9multWd025dByJ3Jbs7n8Nlz0sFW/xjMeGaZZl/q6dEvhTocQFMVxfRY+z2\nJ9ud4TLx+pXtjqVflwe3rjIAlY02JIU2JD/V0Ia4evbXq+ES3TmiMum4qT794+3+HW67gMRqapjI\n+eHzsG5jvk/59m5TYi5u+bhyuf3zE146FtHXCqEEzuj0d9f//m5LJ3lE5Rs6fW7s+aS63eF9t11Z\n/KRQXLl1vro69M91UR34xy/X98SVT+XPlUh15fATZkqgRcvneiqKf4zCzwf7puuEG3bVJaZReUiE\nAQAAAEAVU3Al7q5T3YXv5DtMzFEvYBW3Tjf/guZcGJjnnfyi4XLCMgXLxAUlUkGEOdYRKlOcYdNP\nrFdBkbjhavwytWxvG/xyAUIF9oalA6I+lX3w1NnhcwVy4oJ++szImPKF82qk6zEaaPaPWdyxUNBG\n+zwiDJCda/nQOjO9Es6LnwNF23KBSO3LrmfiA6TZ6tKVN1qXACoPbUgKbUhu1dKGuCRuVH/vOA1L\nOF/ceamy55sA9ofXSxryU2WqHzTGchn9/jtLVq5C6VxKGmJ018pF4V/tR9xn3Fxosjv92UL435OR\nCd/FYr8npaD58JykY5TqiZY6Tju9ee9QOUiEAQAAAEAV69m3Ifb1XicNtEK54Y0knLsjJtii/8nX\n8Et+cDCbFm8y8Yb0cD1dyQ8AZpuzISlA5QJc2YK2/bwhdOICxr0SjlE2fmBVw27FHQsdg5He8E+5\n7Fl9oqfCgHEzLNu2cwUis9VlXd/Czz0A5UEbkh1tyAnV3ob4xzIp4VPMtpvT9aL1d3Q44KR66Yp2\nNek883t6asjBJC7RqM8WmgRyye7+WepvkPf9379hebv3i/me5Msf9jLbuavhIkX7f7CDw7Wi9Jgj\nDAAAAAAQCu+mDYJims9EgYwXbh8bBjYVmBiQnpOh0DkPDjefmMg911wNlcafc0bBTDcHR5Qf8Dm4\nbVVigK0Q4d36wbHQEEAKpkSPRUMBvSkcFwjVMcw1kbvuytZ2WwjkAMgTbUhbtCHdow1xx69fCY5b\nJfK/gxqmdOeKBQmfa8o8V+/QfL/rqj9Xh/l+T44d2mtdySW1cl2D+g2ffGKZrauYJ7XCkAgDAAAA\nAGRongMF4RQ8U0BC//Ovx8703A26c1yBzlxBMOdYyx6rVv4wX+UI5rk5ThR0csfBHYtwSKxJlxZ4\nLFL7k89d0y6AdZShfQAUgDbkBNoQ2pBa4H8HO+M8dueVKIGe71CsXckl4fL9rvjLoHKQCAMAAAAA\ntKE7WAdcOyMzH8j+jU/ageDv4eDfu59dFL42/iOLa/buZ6fOu5s5Nel67nlUdKd9KbkJ67Mdizdf\nu6yw4ExL/sGZugJ7bwAAbUgKbQhtSK0ZffH8vIZNLfa4l+t7kosSu37PNVQnEmEAAAAAgFgaAmbI\noNmZ+UMUNHNDXm0J/k4Igme5+IHO1j2bzMZa1Wgzn8jwKXnPo9IZosdCd/S7Y7H5v26w8VcszrmO\ncLitlSeGIco2bJEb4qiQ4CgA+GhDaEO6Qxvi6uFwzDxstaBX30GZ530axoQ9CUu7/hPnkeqynN+T\nJJqjTed8rh5x/jnQb8RkQ2XpaQAAAAAAWGruh6aHrratj98a+767s1x0F3k+FHxzQaJqmzjcL/ve\nNUusK21eOjc8Fjueip+LQ8OPubknDm7Pr177jTwRlNn1zP2Jn1Ogxw1N1OBNTg8A2dCGtEUb0j3a\nkP7petQ+12IyzO+hpR6FpabviDsXK3VOuYETZ4V/dQ3K1its97Mnvhf9RtZ2j9dqRCIMAAAAABBq\nfTU1VJLuFE/6H333er6ToOtz7o5+rbs1IUjUvPphq0QKFoqCts1ZApmaD6e1hAGwlm2rwvra9sS8\nxGPhjkG+QxAp0FQfBGZl59PJx3jHihOB0wHjZhgA5IM2pD3akBlW607xhunbmZB4DJNk6tFYhfxE\nVbbvoM4HJV+LOY9dMlHfk6Q6FL3XWoZko0voah+TEv06xs2rU99xJfzpUV95SIQBAAAAAEJDzrkq\n/Kv/0V+3cGa7YIMCFAqCSCFD44w4/5bMetcG6/Xv6tdrm4LASXMX3y2fr2HT52QCf00PXt0uQKPy\nr39glm0Ngo2qs1Lx60zbjR4LlcPVWd8C5tkZc9l94V8FbKLHWNvScGXuGKsMBHIA5Is2pD3akEar\ndaq/homp81lJYCU1/SShzvu195bu2Eb5Qwvm29OyUKMuvjMzT5a+g37PJ7fd1OuLwvOtUP73ZPOj\nc2O/Jzq39N7qu6aWfK4uPxkcl1RXInDI2anrmzvGPneMXblGpr9/qCzMEQYAAAAACOl/9BW40v/g\nK9D4wu1jw8CEgh+Hg6CX+x98vVbI/+RrvaODIIqbj2TN3VPDddb1Ta1XdMd/JQ57pXKO+8hi2/C9\nWWFZFYRRwFLlVQDQlV9BlPEfyT3HSr78Y6FgpR6uV0RHj0X0GGu9Wt/RlhMTwSvgM/K8eQYA+aIN\naY82pHtovPy+4Lx8LqxbHV89VLeuTnR8XSKp1FyPLZdodr2SNO+b68nVUTrG+g6GPb6CfWx6aHY4\n/Gb0PNY+qy6K2YcJ1yyzdUEyKdv3RFxSrpSUzHTHR4kul8yd8rk9mc+Mvnh+2NNS573KtiP4nPZX\ny/jlU7KYm4gqEz3CAAAAAAAZClw1Bv8T7wfM3JwICuRomKcJ1y4r+H/ytZzW6+74dYEDrVNBjcbL\nCg+cdBXVhQI0bm4blV0BJxf4UKBp4vUrC7qrPh/uWLg603Hwj4WCkROvW1nwsdB6dQzdMdY6XWD0\nxPFYZABQKNqQ9mhDap9L5LhjLK5OdHxVX3V9B1pniX43OiPhpn0768aNmd5v/nnsvtvFnE+O5tRz\ndViXTkpFvyeTgvWf6tVxKekYZatDHWPtn743LgHmzv2uKB86rkfdsAuOWwkd2f6YAQAAAACqn/uf\nfFEAwN3Z31EuEOfP/VJN3NBDpayTXML5RdJDUJWy3vxjrCBUPXcxAygR2pB4tCG1LalOnrttUPie\nEj2dlbh151ZnH4vO+m77/O95V31PJN86LFf5upPewy+0UiIRBgAAAAAAAABAkVxSJI4SkS/cMTZ8\nPuqi+eGcWACyK3UijKERAQAAAAAAAAAows6nFtjqu6eG81nF0fx2zqAzLjEAXa/OAAAAAAAAAABA\nwXY+PT/s9bX6rqnWMOlSG3L2VeHrLVtXWfOaJZnh9jS/VB+GjwTKgqERAQAAAAAAAAAogpJg6vWl\npFeSodPn2OiL5huA/JR6aER6hAEAAAAAAAAAUIQ+gxpt/BWLw55fzasftpZtz4XDJGrOsP5jZ1jD\npEtsQPAXQPmQCAMAAAAAAAAAoAOU7CLhBVSmngYAAAAAAAAAAADUIBJhAAAAAAAAAAAAqEkkwgAA\nAAAAAAAAAFCTSIQBAAAAAAAAAACgJtUZAAAAAACIdXDbc3bsUHP4vN+IKdbrpAYDAKC7ONzcZK17\nmsLn9YMarU9DowFAtSERBgAAAAA1SIGruiBpU+rEzTM39wj/jjhvno08/xarVc1rlljTg1dnkmDS\neNkiG3L2VYbs1i2cafs3LrcBY2fYhGuXGYCu9+IdjXZ4z6bgmjU7uHbdZ+iYbPWpduJo8KivsQSR\nkl9ND10dXs+dhomX2vgrFltHaZ1qK0TthNoLZOfa1j5BMvKsGzdapelo21+u35e7n10UnufCuVjb\nSIQBAAAAQI3hf+o7Rkmw9Q/Myvxbd8ADABClZNHqu6eGybDRF823odPnWC3Qfq29d2amJ1h4Y03f\n1AMAqhGJMAAAAACoMUdb9mae79/wZEUlwg5sXG6Hg8Cagmm6s7wSbXv81vCvAn/jrlhccYlEJeqO\ntTSHCbr+ZSibEq2ioSL7Bg8AXUtJl+bVS8LnA8bNYKi6MtKxcD2HdW2OJsJcmyfqTVYttj5xayYJ\nNuL8W2zkefOsENW63wBqF4kwAAAAAKgxp55zlbVsfy7zvJLseuZ+271yUTi0TyUmwhTQ1LxgMnDS\npRXZm27nUwu84YdmWFdzvQ01fBGJMKDrKRHuvoepIVsbDeWha+DQ6XOt9dUmG/3+O9u979o8qaaE\nUEu6HVQ7U2gSTKp1vwHULhJhAAAAAFBjNC8Yc8IURwFmhyElAQC5jL7oTqs1xw7tCf/2YWhgADWi\npwEAAAAAKoIbXqmjn+mM7XbFOjrT4eYm60wd2f+uqrtKOEbFlqHSzy+gWlTatarc3+3ucm2ppv2s\ntHaiK+quXN/Laly2lOtA90KPMAAAAADoQvof9/UPzAqfD502J5znafPSG8Lh+Nz/1GvupaHT5tqQ\ns1PDGmqIolyf8e3f+KRte3xe+Hz0xXfGDl8Xt071gNIQRg2TLsmUcczl91l9wvwzWk7D9O1YMT+z\nDt09furU2eGcInHlccMOqufVuoUzw+ea52qk9/kku5+9PzM/1YRrl4Vzeblta5jF8Vcstrb1sDz8\nTD715tbtB1a0brc91Ut0Gc2fsmPFgjbLaf8HpPcnOm9P9NhbD8uUT8754nHLZ9/d5/XX1WFc+dzx\n0fBUbq4W9RZU+TSPTSE93nSuuKGyMmUK1qt5YCTpPBOVYefT89uUoWHSpbF15Cvk+AHdgYZD1HUn\n6TqVdL2OuxbEXavjaN26/uxPf9fFtRXFfg+ztT8Dxp6bGfYxuj9u/3Wt0TUnjrtWJX0mri6k2GuL\nf113daL92hKUQw561013vXZlc/sjatPi6H1XH2rnonOQZaN6UBul+eTyaaP8ch/esyn8q+MeLXeS\nfPc7qaxx54T2N9swykm/Q5L2MV9x7bvOkSHBdybuGPj7rvNWy0fbL5VJ3zfX9sa1cfl+t7J9p1U+\ntbOF7Fu+dRZtz/3lcsn3N2M2Sdcj/abS74ok7nsUV9foPkiEAQAAAEAXUgLI/Q+8AhXNa5a0+4z+\nR73podnhZ3v1bQifJ31Gf6OBpdY9GzPbOBpzx6yCCHHr1DJ6NKy+tE2QIU5rc5OtvntqJoh3YttN\ntvWJeWEPLDc8o18eR4EI91q+Qy8p8OKWUcBJwRRH9eRTcEnliHL1psCgnzjz1+34iZ/+kaSR3lsb\nBPeidyRr/3fvWRSu681BYNMPKPnHXimvAznq2BdXPr8Oo+VTOdbeO7Pd8dEyOuf00Lwv+QaftL/R\n7Wvdbv1HE+7MVgA0rtwKZun1SdetjA3Y5Tp+cec9UOsObFyWSVA40QR1lL6j2a7V+h4mJWE2BYHj\nXekkm8+1FVpHvtcQJ2f7MzG5/Ynb/6i4a5WTdF0Ud23RsoUMLexf19112L82+6KvqX1wSUw372PU\nntUPZ5Yr5JqnhMPmR+e2e921UWoDG4OEjZ9kiiu3f53PJd/9jvJv9Igup4fa6rhkmI71y9+bFXtu\nJ7XD+VB5Ni+d26591zlycNtc2xEkgqJtl7/vW/7rhtjfduH+LEztT8vWVbFtnNtnnVfZkp7ZvtO7\nguRYUttazG8XJ+564C9XlyP5Fvfdc2WOqy+fytv04NXJ9Ro8kn7TJO2zW465TrsPEmEAAAAAUCb6\nH3p3h7CSQQp8uLui9T/sCg7or3qNjTjvFus/bka4XEv6zmMlR3YGySD14Mq3d4+CDgrwiIIWpwWB\nFndHrN5ToCNXQEIUtNLyKnt0eZVL7+uOZpVLd+memS67CxBpf13wNVvwJImSYKm7s68Kk2B+rwFt\n2wWY3B30KofKpwCRkiwqw9bgr7uLeZjq4Zyrws+4u9dHXzzfBgZ1Gy1jGNBJB1V0bMYEQdN+6UCK\ngos6fuHdx0HQJinAfCAdNBoc1F2/EZPbzE0Wx5VPNjwwKwzIaZ9053ls+dIBJ3eMh02bGwbF3F3r\nCv6ojvRaPj0MFLhzya4Xbx8b/lXvCbds3DF0QUF9Rp8V7aer//B4PHN/uG8+PwnmltXxTQXMbg2P\nr857vVZI7wig2r3p2uXh36TrVFxvMBegTrpWu2BwtA3RdcIFvf3voa4hmWto8D3tP+7cDrU//rXJ\nrbez+NdFXTtVbm07Va5U26TrS6qnSPG9TrX8mTdtDJ/7SRH3mqNr37b0ta45SHjF1ePe9LJqa/IN\n2GsfXBJMbdOoIIHmt1Hbguuojr16sk0MEibuPb/cv1k4I0w6qg0d9f78EnD57ndceV053W8htZGb\n0z2s9DeaCNMxc0mwuHbY7aPa6qSkUBx9F1yi1pVJ++Vu4HDtu+ouqX3XfrteXW5/9JrOb3E9CKP7\nHP39pzY/rtwumRRtW3eme3m53x/RXvId+e2isrvrQdyx0u+pbAlTtd3uffe7zC3vyp2Nf23QtSzu\nuhF3PXLnifY56TdvrpsJUDtIhAEAAABAmdR7yaBQQyrAoMSOAiXu7tUJkbtzFYxUAMAFQg9uXZV3\nIFLBCLfecUGQxF9O61VQTOs9mEdgYOL1K9uVS4GVaLlUVhfM8YM69UUOWSRxQyGKS5bEfUZBF90x\nfOzQXtv51PwwmTIsPYSQe/TwRifUv+PKqOF1XCApemwUYHHHLynALHHLZlNIHfoBJ23DD57q/NJr\nrqdWtmBb0vb913IdQwXLhk3zeiUEq1AvhBduXx7WoQJofiLM3R0uqsvRF83PvKfjp54arengfb5l\nB2qF+77lc53yRa8D+vyEa5bZC3ekktrRJIy+X67HrYLOum46uobourrm7qmZIPSAa2dYPvz2Z0yk\nN5Jbr66dnZEMa17zcOa6GN22ri3a9nO3DcokPDo6/Ko7Jtmu126oWtW3ttm+d/eJnsADswwPGOXa\nQNfO+GVIDT85I+xRpH1VwtP/HdKujH0bCmqr89nvdstEy5n+LXS0ZW+YKFQ9qJe5vx7XziW1wzqm\naueSbrhI4oahjJYpvGkkaMtcmbK179p+m16F6f2x4z0yic/69DmXKbe3z1seTfVG279heeJwf7Ft\nq9c+6jsUrTOXZCv0t4uW0U1EcfXiyq3ri/vtF6VEkz/MdLRu9O8+g8ZkEoVRua5H+k2x5u7nwsRn\n9Hrk/x5SnflDIapuzrxxY+ZahtrX0wAAAAAAZTF46uzY1/3AioJ1cckSl2CSlu35/w+8C6pp+bgA\nTirYkztgFAaaSliuQiXNR+GG65LRCXexnzo1FeAMhwkMAsCF8AOT6qUXVwc6Zq4OktZ/2rvmFj13\nSTYuiCs6Rkk9CFzAVZ/f8dQC6ww6F9oE6tJc8FcORs4RzVviJB1jN/SRyk7wCshO16O464ASBfVB\n8FmiPTk0NJzUp28eiOPar3AYt4ShUaPU60TCnsIJiZ2GdO+2Uus3fHIYwNcjcdvp15VA6CouwRU3\nrKD/73wTOX7CT21U3I0COvauJ5FLepSTbqCJK2e/kSfO25atJ671rele56LhKJN+i7jeTvkOQ+z/\nfkiqu2He/Fv7NzwZu56kJOog79xO+g3gfyZpGFAdv7i2NSy31242v3Ti94f2K9OjKo/fLu4aEK5n\n9ZITyaSL7oytF7++o3Z560pq15OuM7Iz/Rsl6Xqk8qg+JXo98n/zJs0Hls9vXtQGEmEAAAAAUGH8\nIEO2oZDq+g60QuiuXBfMKOTu8jjZkjiFlqsYPfs2xL7ugjcKyCSVUXXq6rjQRMoeL7E1YNyMxM+5\nRE9SAK4uofwd5e9Pth4NqoNCg4SllNSLyw1RNCAhuCl+sE29DgEk65XHtSaayHIJq/5ZehqfMu7c\nzHP1XMlF3223nY62P8VQ8iDpBpByOtXr1Rq9ccL9O1t7FuWOhdaZFPgXP7FWqdfRXied+C2hntzO\nwe0nyputneufcMNFEr/+k+ou7IEZnEtS6JB6frtXV8T3Mh86v12C22/b8/3t4pLB/r4d3HaivpN6\nqElH2vVskuZC9cVdj0r5mxe1gaERAQAAAKCbOOoFVfqNnGy1yAWODntz6GT7XKGBJj84pHk0kriE\n1NEiAlkd4Qc0++WYT6bv8ClhOSupV5Uri3pkZDt+TmsX9twAugMFjt11UQHopO+hf+30kxRJKqX9\nUbnVwyTs/RNcPw5nmdeoKyh5oGt1dHjEsMdyugdPUu/xOK6NynX9d8Pdajud2Xu7Mxz0eodpKLxt\nFj+knuvZ15rnMXZ15w89Hbve9PqOdXH7nq8+DWPD3mR+++g/L/S3S77nVJLW5tQcccUMY9yR61F3\n+M2LwpAIAwAAAADUjGOH9qT/Nnf6cE/lHk4qjh8MyjfoVEnBPFcWBb/yCV5WaiASqAX5fg/zXVe5\nqcfw5qVzM9eNunTvHtdLpVyJMQ1nt3/h8ky7lZo37MSwe4PO6JzhItV7u9qvoZ3RDnfF74eu4CeC\njrW0Hy6wUMXOx+mGeOzVwZ7wpbweoXsiEQYAAAAAqDmp+SCuyvm5+iLn6VJAyN25n/VznTQEYj4U\nzMsncFVscKszdfbxA5CbhocbMPbcnJ8bMC73Z3r1HWTlpAB600Ozw+fq2TIquH5Hh0lUT5nDexZZ\nV+uXHq7XzVupcvnzqRUznFx3uUmg8bL7rNSUHNU8WrmUs33PR11M296R3y7FnlMaqjFpvrNCdOR6\n5CcC0X2RCAMAAACAbsIPirQqKDHWak6vkxRs3RQGbLLNj1L0+tPBIa1fc2VUWhLJzQ0iGuIo23w4\nbqgkN99JJXABs1zz2wDoHH4AvJTfw/qGE9emcrQ/W59IDZ+nfRp/xeKikkudxdXzzhXzM8Mjul47\n+dwQ4HP7latnm9owl5yopLrIh9/u9h83o2Q3RLh6ONrSXNXtj0tY+fXUkd8u+Z5TSdzvsmJ6c3Xk\neuSfF/kM34ra19MAAAAAAN1C3/Rd51ILw/7EcZOpKwnUGXfE+5PMV9LcWo4/kf3+DU8mfk4BKXcO\n9C1y3o/O0L8xNf+Hysawh0DXc3NWSUsJr3F9goS7a39cb6dCpQLqxXFBeO1bJSZ+Gialhj/UdU/z\nXrny+m1OPtz1PNfwfv4xyKdHXyXx53va/cz9Vir51l0l03njfpv0926EceeXqNdhITpaLx35XdYr\nHL40lUQv9HpUimsOaguJMAAAAADoRlwPIQUF/MnTff7cJNXGD/ZsffzWxM9prpidTy2wQmlYHhdY\naXro6sSgjoJRxay/o1Q2d4zVuyDpGO9ccaJsI8/PPQRUVxlyTqr3g+o12/FT3TavIbAFdIaBE1MJ\ndQW9s13H9F7SNSbKT7BpvcW0Py6BlRRQ13X3cMJ63XU727L7m5Zbuei67cq49Yl5mdcKTdqdGlxD\n3Xq2JVxDw+truoecegRn6zlcrM4cNlDldT2Zs7VzOqbZ2pGofOpOlJDZVsB6S82/kSXKHVcZ5P0e\n6ufdCKXzq5DfLqeec6JXYtJ+ZyuTn+TdkXA9UU/IJIOnXh3+1fr12y1J3PXI9SDT74Va/M2LwpAI\nAwAAAIBuZEQ66aGAxNqFM9v0atJrW5bekDUg0VEuOBZOep5nALUQ/txSCpBtDvbH3467215zxWx+\ndG7BdzcrkOQSR9qHdUEdRvdD61x778xw/Vs7IVjmB3Tj6nBUev4Pd4yj+69jvCOoG1GQqNBAq9v+\ngU64Y17Hz0/khT0jYsqvul3/wKya7dkIZOMnGTrjOzBs+pxMokHftWhg3P8err5rat69PKLtT9x3\nO1v743qWxCXK3XU3afg1v1eL5gJz29a/tU1/2VLOJ+T3uM11rIZOm9vm34UOiyh+G6Xt6YYNv561\nj7p2un3NZy6sYvjtSmeco2PSc4PF/ZZx29Qx3RYkfVQH+VDduWOg5cN6irSx+i5oe0omlbP9Udn8\npFD0+9MQJLP9cy/622X13VOz/nbRbyd/2aHTT9RL9HeVWy6J367reESTaapTf3tR/vVIv93irkeb\ngmOscus3WZtlp83J/GbRcfOPWVf85kVlYY4wAAAAAOhGdFew5h8JAxlBMGRNEAxRkKAuCKy6+R8U\ncCh2LohcdGfwznQS5oXbx4bb6jt8SjhnS6mMvni+tWxbFQbGtC09XE8E7ZcL2iooW8yd8AqUHU0n\n1LQN7Ufc+vWaAjilpmCw7m7WdlwdDp46OxPk0nYbgyBhGAANyuM+o+Psl0/7PjqdNCuEm8tGAaVn\nbu4RrnvEefOKCtrGUdnXBUE1lVXBRj1KefyAaud6fqZ6SCzKDPs18fqVJZkvSeufcM2yzPcwTOqn\nv4cKgPvtgxLv+c43pDLre+uG/ou7dmpdSYk19Ux55en54WfdtV3XH83p5JbRXJhHY5bXtfjVlYvC\nZXX9jOtRqrK4HmOuLB3lD+OnIL3KqyTRhGuXtfusevBsS/cGE3+o20KojTrcvClIGKTmHNND+5aa\nF6wp8zkdi86aC6uQ/S5G9FzSbxkNhVcXaee03UJ6Peuzxw43h3XnzpO49kftXbnaH3cswxt6ls4N\nf7/53wHt8+j3t2/b/d8uSd8/t/5onY0MEqYHNixv87vK/+7VpXt8Jg0ZHdeu+8u7RFfcdz/f65HK\nMDyS2O2TPv7uN6/Oxehv3mzlRm2hRxgAAAAAdDMKhigo4QceFBBQEEGBpc66Q1xc8Mrxgy+loiDH\nxOtWhgFat48KcrgAp8qgxNvIIHlTLC2rOnRBJH/9rh5VhlIEUqMU0HV3Z0tc0lLBzbNu3JgJ1B1O\nzxvil08ByWLKp6CSq9ek7XeEAldnBmUf4W0nevxU9o4cP6DaRa/hpb6O6nuo4LOuJXXp5JQSb+77\nru/hpOAad2qBiRR37Yx+t3tYKjGTLTnvAuINE08kiFwbomuxrgsDJ16addm4xI+7pgydduLGhf1B\n0L8U4tq8JOrB49oU7WNH2o/RF93Zrp79Y9fZ19BC9rtYKr/2w7VzrTHtnNrhQns9x9Wdv179tmi8\nbJGVS5hQvCa13+73m3+Di+okaZ/z+e0S99sg/P5c2/b747brtqmbmhLL7F1Pkpb3f1dkWz7peqR1\nxF2Pcv3mHf+R0t2IhcrWo27YBcethI5sf8wAAAAAANXBBUBSE5Kneg1pDoctj6YSLWfetLEkPQyi\n3Fwu/nY7iz8njIIppd4frdvdTdwZ60+Sbx12Vvn8c6ffiCnWWTr7+AHVzA311dnfjbi2ojPWqd5L\nbii7bO2PPx9Yoftejmu222au+nvhjrHhvilwX6reWuW8hvp17c9T1ZnbKWWb1JHzrCt0pH6L/R50\n9Pvj12mx54S77hV6PeqM6xg6T+/hF1opkQgDAAAAgG4m15BPCkIqGKnPTPncHgMAoCvkmwirRQru\nu6HbaHsBdHelToQxNCIAAAAAdCNKgmmS9Ohk5U7LtudOTLZe5PwkAACgMFuW3hD+pe0FgNKrMwAA\nAABAt9G8ekk4LI0mGt+zZokNmzbX+gwak5pvYcOTmSRYoRPMAwCAwqgXmNrfnU8tyAw3R9sLAKVH\nIgwAAAAAuhHNORIG3VYsCHt/NT00u91nlATT5OF9mIsJAIBOoZtSNBSib0SQBKPtBYDSIxEGAAAA\nAN3M0GlzrWHipeGd6M2rH7bW5qYwOdZ3+BQbMPZcG3LObCYQBwB0uT6DGsMbNqSuG7RD/UZMCXuC\nDRg7I9jvqzL7DgAorR51wy44biV0ZPtjBgAAAAAAAAAAABSq9/ALrZR6GgAAAAAAAAAAAFCDSIQB\nAAAAAAAAAACgJpEIAwAAAAAAAAAAQE0iEQYAAAAAAAAAAICaVGcAAAAAACCng9ues2OHmsPn/UZM\nsV4nNRgAoLLpuu1fr1ubm6xPQ6MBALoPeoQBAAAAAPKyf+Nye+bmHuFDz6MOB8FFlyiqJTufWmDP\n3TbI1tw91dYtnBk+lBQrhaYHrw7r84U7xhq6xot3NIZ13vTQ1Qagsmx9/NZMO1MK24L16fqt67i0\n7mmy1XdNbff9r9b2q1bb3d3PLmrze0PHzf1797P3Wzmpvout846e39qujjmAwpEIAwAAAAB0mIJW\nL94+1l4IHrUUlFPwdPOjczP7VD+oMXwAACqbkidbn5gXPu/Vd2D4d+29M9u1UdXafinJp3Kvvntq\nTSbDKlHzmofDxKoecTcEdTYdax3z9Q/MMgCFYWhEAAAAAECH7d/wZPhXwbj9G5Zbw6RL27yvQKMo\nidR/7AyrFjuenh/+VbnHXHafDSiw7NW63wBQ7bY+cWv4V9ffIWfPDpMYSo7JyPNvyXwuV/tVLq79\n0FC8fYNHlOuZrH3S82j7lGv5jtJ2XTJIddZZwwXXBev1E329Thpo5XL41abMc5030TpvXrPEjrU0\nd0qbrzpw528rvcKAgpEIAwAAAAB0mIKKCtL0HTk5NojohqFSMLJaEkItQWDRBZ1GnHdLwUkwqcb9\nBoBa0Lx6Sfh34MRL2/xbiSF/jrBc7Ve5uPZjxHnzYhNZI9LJPJU7rn3KtXxHKQnmtnHmuBklTYQd\n3LYq/KuEksruknrSb2Tp9yVfp55zlbVsfy7zPEq9yFUvOh4Trp1hpaT6HXXxnXYgSMANnT7HABSG\nRBgAAAAAoMP6BMGq8Vcstlpy1LsDvQ/DIQJAVXG9iFyCxt3YEE3YVGv7pYRerbW7jnpWyeCzU8km\nNy+Ybirxk5hdTedO42X3WbkMmzY3fAAoHHOEAQAAAEAFKOf8Hh2Z+L3aVNN+dodj0tn7yLw5QPE6\n+v3JZ/lq/Y4WW26uSbnrYOeK+WHSUr3BlPRRDys9NESiP6Rlremsc4NzDkihRxgAAAAAlImG0Nm9\nclFmng/daaxhmRToaX7p4fCOaA0JNPriOzPL6LNblt4QPh86bU7sME4KeriJ1JM+o6CS7rDWUFH+\nXfNu+4Xeca11uaGLxlx+n9UHy2v/3F3d/nbXLZyZKZvuaHdDKzVMvDRxuB9/XW79+ZdtUVg+f2J7\nbXdoEGAbcvZVidvyg0ebgzqvS/ciSKrT6PK+6H4nLR8ta77HRJ/f9vit4fnhyp1tH5NoHVqXekjE\n3fXun1salituOK5c6yimrP75NeHaZeHyO4JgqZbXeRPtFaH39d06nO4BorLoc7UcREXt86//ahfi\nhrtz37+k66m/jrjvsBIQO1YsCL9vhbQN/vWtV9+GTDnkzJs2trlmu2uAf01WORovL21PG3f96Zeu\nJ5X/8J6rwvL54tovR+2T6kT1OeScqzLtdty1JWloQA2zqzrNp71VW9OS/k2QKV+wvQPpuvKPe/S6\nWOjybt+ivzN8bn3uM34bcNibp2rTg1dn9iuul5rWoXXlc93Xa8eDv4PS846F50ZwLFXX+f42ceVO\naoe03+63h8obd+zi2rK476B/HNzvOf113wn1Yktq2+K+CzqfRr//zth9dcdMQy377ZlfLp3Dr7c0\nt6tv1aOuCQ0Tk3+/ALWMRBgAAAAAlMGmIJixy5vzQhSsUDDF3fl8MBLMcp9xARMFV+JoovZsn1HQ\nZesT82LXnUrELAqCPosKSqAoKOgHckTlj76mAI4bnioc4igIMLU2bwyW3xQG1ZISYS5hqMBZvkkw\nF7CLlsGVremh2WE9vDkIIPoBp7hy+4HFpHrPtnx0v+PkOicmXbcyMVgXdzzdPmrZfIdy6hmsPyz7\nxlSQL7q9/RufzOxb/w0zYhNhSgJq20MGzbZ89tEva9zxEP/8UrBPSTDHT1jq+dog+BgNBKvu1csg\nTHC27DWgGqmHjPse7NvwZGwibFdwrdT5ru9U3PV0/4YT3+HxI9omLBTQ37x0brseJH7bMPqi+fHr\n9a55cddcJ+l6pWVeuH1sJmlVCtFrrZIH/ce2/1xc++Uc2LgsbJ9EdZt0bdHrLhnly6dO/fa2JUf7\n4Q/ZG1fuQpb39y1JdH3+7wufey1uGGElDzc/Orfd6+66r/pT3fntTXT4v1ztbhyVqde2YJ0JN2S4\nMu965n4bFnNOu5stho44URb/N5iry7jj4H8uaX7QpO+C2qmwzb9+Zbu20B2zaD3723s12J+k75ge\nSvyRDEN3RCIMAAAAALqYgh8uGaCgnyY/V0JBgQzdMb7tiVtjk2CloKCbC5Bom36PAAVIlKhQUEeB\nu4ZJl3Ro8nvd0TziPak7ll+8PRV9VPBl1PtTd567HlaDp14d7PO8MFDnJpn3uaBu6rOzLV+6G9oF\nhhS41V3mSqJpfQpo6jjouZJlE4MkU7TcBzYsP3HH+EcWW9+RU9qUu6P7Hd3HXXsWZe7WVpBLAUeV\nUUGxsJdGEEyM9mhSgNEdTy2n46lzyt9HHXMF0/LpDTUoOOZb0gHL/cH+R3uu6fx09gbliq7TP1YN\nEy9p854SWO68V1DT9QiMHg8lspKSfqLgpJYbMjXVs8Pv3aF1uEC1O79dXaoe9T5QrVzvGF3X9P2L\nBu/1ukt4uMB49Hq6N91bVa/737FUD5nZ4XMl3MYEyQN9z3qlk+OZtiG4PvQdOTk2Ce7KoGvc4OA7\n3m/E5PC1Om+OLne90msjzrvFBp6RusboetuZbV9HubZE1xSXlNH+uHpxSQa/XlrTbamOhV+n4tr6\naHurJIVLsLj2Q22XSz7man86unwuup6qh5/sXf1wWHZRIisuCab2xyXB/N8c/nVfx3xr8DepV1ox\nVJ8704msuO+Bm3Ms3I+E75JLXmpd2WhZ9RaUDcHvCe2Ptjcm3cMxqc71XYi2Uzu93piqk2LmI9N6\n3W9Lt171CNyc7jGmvyTC0B2RCAMAAACALqTghoI/osCYfxe0/irApsDI6rundsq8Di7447btCwM3\nQdBFw/mkknIPF9QrLEr7E01mKGkR7dF1arCNbengqHorRANWe4JyOIPOyB6Qctyd9qIg08jz5mXe\nU2BI/1Zwyg0dpICTS+q4crd6Qb24cifJd7+jouW0hlRQ87nbBoXHI5p4CpNjT88Pn+u88QNmbh9b\n92wK60EBQQXrciU2tVz9oDHhHefq/ZUtEaZ6Uy++6JBnzoBxM9qWNd2LSwFZ9SqJllXrccM+xSX9\nMtUSMxRidBs6h9qc3w2W6U3okptANRoYnP/6nrkhz/zvtB/cF13Do9dTl2iKXtvX3psaxs21DX5P\nlPD7dM0yWxd85nB6SLmzbtxocXRdnRjTk0X87170M/Xpts9toxKpfTzV65mk64nq5YU7Ugkn1b9f\n334yJbyZwuvt5npEu/bW9UqKbT9O6mD7U8Dy+XDr6nXSwMxrYdsRs42tT6RuPoj+5nDX/WOH9trO\np+aHbVS24SUL5RK9YSIs8rvC7z0l7jj52z64dVWm3ElJX8evc38dueo82haqnVI77m4KCtvbIhJh\n0d+Wrv072rI3c9NRtO0GuoOeBgAAAADoMkouuDv2dTd8XNBHAaJSDg/lU7JFAZJxH1kc+74f8Omq\nYGQfL9C0O50k9Pk9GPKdH6Q5nTyrTwfb4uguebfd6JxeXU3nQVI53Z3bRyOJUb/3R1LSyAW7U8HA\n5ZaPgRNT87/EzXOm9ejczNTbSw9HPvNk+Dfa28QFQ/VadMirE2WdnVnvTm/ow6ikffUTpkk9C7QN\nJfqAajUo3TtF38Vo7ym/15IkfYfFT1T71xK1S3HXWV2nR6W/V61ZhhJUT7C45f1lhiR8RtsopNdv\nV9J1+NSY4fn89ro10mb6ww7G9ZbS9W5UkAgZoRsBBtfedUk3Ybg6GZOQ0Bl53onruZKBpeTazgOR\nc9Xd0KH6z7Rlq9u2Ze53R/8cSbCOSGrz3Tb1XS3mhijVddxvy34jT/yubNn6nAHdDYkwAAAAAOhC\nfjIi2tumK7jAT2cl2oo1MB2wigZY2wZP8++dlmtuDse935Lu3VQu/vB+SaJBVtf7Q8cyKUHoJ6QO\nbltl+XDDQLm7xqPbU52547U3JtAuAyPDLrnXcyUz3XIK/rUkDJHWM6GuXFmU/OxbYec3UCqu16ao\np4uj74u+szr/lWwOe7VGvsN+Lxf/e+ivx0+QRfnXk2jiwEnq0XNw+4nrT0d6GpdLtmt00j4PGHdu\n5nnTg1dba0wbo15gSu7X4lB17sYIN6RnnLC3Wvp8btle2uSMq3/Xe9Jx567Ow/7e0NC+g5khds+1\nzpJP77ejJRwZwO/Bp554QHfD0IgAAAAA0IVcMkPBzFINAVSM1LA7D4d3SqvnV2cMw1iIU8+5ypub\n6sk285Y52QK0vlZvf/oOz54Q8e+QDoPIVTRUUGtzamgyHT8Nr5XE1UVrnok+Ny+QljsQHIv6sxvD\n192x0FCWOn91vPwhpVR/7vw+ZVzb4KF7PVeCyl9OibtCElpuP/tU0TEEiqFem+o1merpkupRsy+d\nzOqfTlbpe6zv5+5n7s/0onTJ4mii2m+Xsn1/UkmLxjBJ0Fpgj+HDrzZlnsf1jqpFaseUbNFNBOqd\np4de0zFSkibXkHvVzj9HsrVRGrJPNJdVKYU3Gz10dab3ZPR3hX5T9AnKuO2JVC+xYxffmZkTL67n\nJIDqRiIMAAAAALpQuRNOsmXpDZm5lESBzbq+DZkAaNKQV53J3TEeBm5XLsoEbt2d24UMi+iry9HT\nyr9DulpF5zvpKD+IrocCuX5vE5eccsfLzW3jyhDtkVVIwLwjyeFjh/Z0eB1ANVCvTSXC/ET0q+lh\nZV1vK/3V+36yzPVycb0+i+G+X4W2ZZXQ9pVD42WLwmvltiduDW9acNdVJV+UEDx16uxwrqhavG65\nmzXybaNKfY74vyvcfHnNax7ODPGr3xR6uHkxXbLM9Zws9ncHgMpEIgwAAAAAulC5gyrbHr81kwRT\n8E1zVEQDcM/c3MPKYWg6meKGQ0wFrVI9GKpxKK2u4nod5FJIbzf1GEkFD4P6v+w+2+UNixj9jHqZ\npBJhT7b7jOQz7KNTzuEpgWrh99pU8F7fbf31h6BzvWFcsswND5dtmLrO1J0T1JoTTQ8dgwMblofX\nygPptm7rE/NsV5DEnHTdypqtI52vQ6fNyfm5QtqKfPVPJ8LcPGFufjB/LrrBU68OEpPzMsmypJ6T\nAKobiTAAAAAA6EIu0OOG7+vqwNeuTK+B2Tb6ovlWSdz8M6oXBaT8OSwKGZ7ID6Yp8DjEkpNE7s5v\nqauyIGSvkwYF/90UPtfxLCU3VKWOhZJTB2LmaXOfcQH2pLncdEzdcc01PKN/zPuk543JV9/hU1N3\n9Zd4nhmg0vi9NnWt7Ddicvi6n+Dye8Oo16YTlwQrpF1yvcoKbbvq+p7ofVttw9CWio5ZmBSaPjf8\nt5JgujlF9bHjqQWZntC1wl2TNc9VqduofGkISvW+i7ZT/jC87jO7n11koy++M3OOR4f4BVDdehoA\nAAAAoMu4gKW4YEshOpKs8edwqsS5SRRYdcEyBaTcndsNEy8tqCed3+OhJUcduzu/o8P5VYP+3nwn\nnTGkVL90fewMArTR3ibuM/q3S1xmO7fcutwxTeLeL6bXijt+rRUw5x3Q2VxvFSWpd6d7bEaHPHSf\n0XXOXevihkX0X8vWLvnXmkKHV/S/z/vT85nVuqaHrg4f7vhEqUd2fTrhf6AsQxIPss7kX5Nbivi9\nUwruBhvZvPSGdkP8+p/Rua3EpP5W428CANmRCAMAAACALqThqlxQRgGXOArUJA0RpzlFnKSApZtX\nK5ukZZPK1FVccDWVXEkO3ObieiXt94LEUW6uFhnYgTlzsunMHn9+vWzNcty0/0l1kI1LtO1MD6UZ\nDrWW8JnNS1M9HJKSVyPSPR10XJVYi6PzXgnQpG3lMsC7ez+pPhSMVQ8FoNoNSn//dS1317Ho90a9\nNqOfietd6ycLNIdkEveekgSF9NIVtV0DvGtKUrJ6d7rXci04sHFZeE1z17U4nZ2MysbdYOJ6S0Vl\n+y2Sj1O93sGbs5xXOjeT2oVSaEgnhN1xiBvy0N2E43rN96/Am4UAdAyJMAAAAADoQgo2Dp2WShoo\n+BPeoewFmhR4evl7szK9a+KWd8FEv9eUuLuZNz86N3ZZBSIzvXyCQKQfeNKyCnJqqCb/tVJxd723\nJATcHD8ge6LnQeFJEQW13L4qSRMNsqnu1z8wK122Rhs2ba51BjccmPa7tcTzX6muXIBPxzN6Lrnz\noemh2eFjf4E9DqIJyIaJ7ZOFLtDpjlXSXGUqqztvdX7GHY+1984Mn+t4FDNEmL8N1Ye7s7/NNhbO\nNKAW6Hpe7w0f6l87Hb/XpuiamNS7VkPCiZIiujZGryWbHro6cwPF4OB7Xsx8l35CfF3wXYy2feFr\nCW2fvr+av1KPQq9l5aK5p0TlDYdAjNSp2lxXp3HXTnc8i+0tlmt5l+xRWaI3D7hrctLxiNr7Uvsb\ncHSOumEgtT71jovWgdoCnW9qFzrruA6IDHGYrVek29+49i4frs4PdkKbD6BjmCMMAAAAALrYsOlz\nwmGqFCgJE1LBQwHKcD6mPIJOCibuX5gaomp9kDRT4KWub0NmWSUSktYzKgh2rksnAxR4iibNtOzR\nlubUfE55BsDy4Saj1z4/d9ugcDsjzpsXG/xTonBbOiGnhFaxvarGf2SxrQsCeaoL7aeSfK5uXGBY\n/55w7bKigrr58Pf7hdvHZt3vYjRefl9wPJvanUvi76fOmUKHGvSHiwr/PW5Gu8+4YLzrZZWtl0jj\nZffFHg//vNfQnzpuxR4Pfxtav9uGO6e1fpW5lOc2UC4DJ87K9NhMuqao94tLMGTr5aJrrXr/KGHT\nHLRPesS1S7qWaEi/YuiaouW1DXdNjLZf2mYxwwZXIiX0W5s3hj1y3fXI1am7Jolei5tDS6/p+Lok\noOpq9MXz824/3DxyeqjdlfFXLM60Beox+MrT88O6d+2Hf70UXTOPJty8EvZwD5J5+qy7puv6Oum6\nlZnPjL7oTmt9tSk8n1zvuFK1UfkKb6Z5KJWUrPd6Jvryae/yoe+Y9lXrcW3+4Kmza27+N6Aa0SMM\nAAAAALqYgi1KvviBr4PhkG1NYYBI72ULCOk9BbMUYBE/UKn3tHy2ZScGQap6b4hFR+XRey5IVcq7\ns5X86+fNt5Et4effvV3sXdmigNyEa1L1XJcOcLkhoOrS85F1ZhJMtN8N3jBMh0ucgNG5pGOmIKI7\nptpHt5/uXCk2cO3Krr9JCUnX6yFbbxPR8fDL6o6Hf+5OvH5lh+Zl8Y+544Ktbv31nXi8ga7k92xJ\nCty74RGjn4+j64SSye5a7X8/9ZreK/Za4m9Dvc+i7ZeuybpRY+i0OVZLGi9bFNabf3121yTts66H\nE73EkW9YUBd+W11oL21/u1o2dYPLiaFhw98iwfUy2kbpc+63SNwwgv7y0WMZV0a1QdE6cG1Uqc6r\nbPye9LmSwRLXuzJfavNdLzg5zE0XQMXoUTfsguNWQke2P2YAAAAAgPy4ZICEvWvSQXr12lIiKldi\nywWTFLRRkKmQ4E1Hli2Wv81+CQmP5jUP2/oHLg3LdOaNG61UXGKvK/fX6aq69ud68c+nStTZdeJ/\nt3SudeXxBqqdPz9UZ11L/GtyvxwJcPUkakr36pnyuT1V+X0u9vqcT7vZ0eU7cryTfsdkK0sx26km\nrj7L8XsDqBW9h19opcTQiAAAAABQRv6dysXo14HeMx1ZtjO36eY9K/Vk9Z017FI+uqquy3FMi9XZ\nZe3odwvozpSk6BPTc7iUCvl+Nq9OzUGVrXdqpSv2mtfRa2U+y3fkeBdyra2mNqojuuL7A6AwDI0I\nAAAAAKgYuotad/5LqebRAgBUL/Uc07xLMvr9dxoAAIWiRxgAAAAAoKxam5vCeTRatq6yHU/PD1/T\nXeP05gEAaPg8zd/UZ9CYTp3TEQBQu0iEAQAAAADKatcz99u2J+Zl/l13UoONv2KxAQCgIeYaL7vP\nAAAoFokwAAAAAKhAAydemppjomGM1br6QWPC5Jf0HTHFGi+/j7v+AQAAAJREj7phFxy3Ejqy/TED\nAAAAAAAAAAAACtV7+IVWSj0NAAAAAAAAAAAAqEEkwgAAAAAAAAAAAFCTSIQBAAAAAAAAAACgJpEI\nAwAAAAAAAAAAQE0iEQYAAAAAAAAAAICaRCIMAAAAAAAAqBLHDjXb4eYmqzbVUG6VT+WsJS/e0WjP\n3NzDmh66ut171XguVev5D6C8SIQBAAAAAAAAVWL13VPtxdvH2rqFM62auHJvffxWq0S7n10Ulu+5\n2wbZ/o3Lrda17mmyF4L91T7vfGqBVQMlwSr9PAJQmUiEAQAAAAAAAFVCCQyppJ5LKpMSSXrElUvv\nu3LvXbOk3fst257LunwpNAfb1foPJCS5Dm5blXl+rKW2eoXFUT27um6OOSblkOs80HFx59GBbpCs\nBFA6dQYAAAAAAACgKoy6+E47sOFJG3LOVVYp1IPKDb135rgZ1uukhjbv9xnUmCn3yPNvabf8ntUP\n27Yn5iUuXwpbls61w3s22ZCzZ1v/sTPavT9s2pwwyaKyDhg3w2pd3xFTbOj0udb6apONfv+dVgly\nnQe5ziMASEIiDAAAAAAAAKgSw6bNDR/VptLLrSTL+CsWW3cy+qLKSIAVolrPfwDlxdCIAAAAAFAB\nOjIUVGcNI9WZw25V4v5Wy/YBoFDFXrcONzcZkpWiPSh2HdXUFpWzrOU8RgAqBz3CAAAAAKBMUvNg\n3G8Htz2XCbL0GzElHK5IQ/70aWjMuex+b44MLTt02lwbcnZxw2WpDDufWmC7Vy6yw+k5OGTA2Bnh\nUFKFrlf7tWXpDeHzMZffZz2OWzh0VnR/c5U5rlwaLknLjgjqaUDMEFeibWmYKw2BlTSE0uagfJqT\nRHU++uITd8bv3/ikbXt8Xvh8wrXLwnre9vitbcqu7WbbPgB0hqRrW/Sa+3pLc3iNK/Sam9S+DJk6\n24ZOn5N5Tetc/8Cs8LmfMNv0YGqIRF2n/R5W6xbODP+6cheyvL9vulbrmh3lr2/otDnWMOnScD+0\nP+E29mwK/2q/XFn8ts2/7qv+6mPa4GztUbZ20rU1bt/VnvjrCIdjDN7TviUNC5nURhfb9vv15Zfd\nfz0fcXWl83PHigXhfHC52u1iz6Ns9R3XZueqp3zb/cZgf7P9PgNQmUiEAQAAAEAXc0Gf/TETvSvg\noofee3MQiIkLtigIlLRs00OzbesT82zSdSsLmmNFAbq1wXrj7nrWtvRQYGtEAXNyaF2unGHwLmby\ne1fmY0HA1g+wOtrm2ntnhn/j1r1/4XIbed682HId2LgsDHwqwJikJV3X7be7MfO6gq87Vsxv9xm3\nfQXMSIYB6CpJ17ZSXHM3BUm2XenEUXS5g9vm2o6n52faJq0j7vrpXouWL/p6Icv7+3Y0oXeOvz4l\nSURJmOg21J64NsWfK8y/7sfJ2R4FD9WTf1OF49oatcur754a/ju67t17FoWvTwza73y3Le6Yav2N\nl91n+fLry6+HpOOSLyUfNy+d2+7cS2q3iz2P+ie0u9nOYfcbKe73lX/8lQDbmp6rLLrtF24fS7sP\nVCESYQAAAADQxXRnuAu2KBCkuS4UHFOAa9fKRWEARs+bHrw6DLb49J5bVkFM3d2sO7H1+a1P3BoG\nPvVc28g3IKbPv/y9WWGQqj4IOI0JltOd0yqTAkeb0r24FBTqP+7cooI/O4NEUn16/hUFtRT4UsBP\n5dR2te5oUNYP/NUFZTkteN/VlcqjumhesyQTrCokSVcIJcFUH6OC4KYru7ar7Yv+Drh2hgFApSjm\nmqtlXAIh2r7EtU1a75k3bQw/v3f1w2HyQ9x7ufjLK3G3M33DQb7L52NYsB9Dzkn1APrNwhlhArFh\n4qU26v2pZFVdnjeM5NseaR/0flJ7pM+I3nfJOq1zS7rnnh5KJEV7LfnbVluk3m7ud4OOqdar9j/V\ng7u4XuFOr74N7X57ROtCvRJF2/N7g6Xemx0+d+2m+82g3y76PXE4/L0yzwZOuiT8TCnPA9WjO4d1\nnFXP2kb0HNaNP9luGFL5XK9v2n2gNpAIAwAAAIAupACkG6ZJQTDdFe0o2KJ/twaBOn1GQSN93g/U\nKJAjCvCMvmh+m2WV+GpN3/3evHqJHcsyxJLP9faSCZG7pBVA0mu6A9oNy1RMIkwB2Yl+0KkhtW4F\nJbcFASet2w1R6Cix55fLf0/LKsDrescpaKVgZ2cMV+TqIFp2/zhpOKd6hkoCUCGKueYqASPhEH2R\n9iWpbXLXvV4nDWzz+XyvhyeWbyhq+Vy03mg7qERPoesvZXuk5JCSaI7K4rezWoefzGpe83Bm2xqG\nUO2/0yed7HzutkGZ3xcdToQF9ZXUzvtJMJ1jGibQp3py6wiTsF4daJ3jP7I47BEX7leQPO2XrsdS\nnAep4RhT561+X/k3A7lzWOtzQ4vuCH7PJA2brDr2h2OMa/ejv88AVLaeBgAAAADoUgp46RE3fJIM\nGHtu5nl0CCjdlSwK5MVRgG1EEOwZ6gXZclFwypUpLnDn5vWQVm/+jkKol1lcwGjQpEsyzw9uW9Xm\nPSXzRAGtuPlgxA90KajVGRoTyq478p244aoAoFyKueYeO7Qn/JvUC0fzbql9GeHdwNFdlKo9Uns7\nLKZ9DpOK6XqPDpvYb/jkTBvtJ8F87vXDRbbR+fITgjrHor8ZhgXnSLbfE6q7+kFjwuetJS6rS8JJ\nUoJLx88l+XbGDHmca3n/9xntPlBd6BEGAAAAAF0o253W+VBCyvX42h0zBJLe75cQpEuioGe+ww8l\nzc1SrKS7qd3d1tIw8ZLE5VVu1WdYJ2uWJCYXO6JnQtLR7wEBANUgWw+WPg1jwx5jSUPsFdO+1IKu\nao/csYm2s4W00Z1JwwG6Hu0aMjDut0zfMp4fLoGopGC23uE6r90xjfaKdJLafV+pfw8B6FwkwgAA\nAACgTMI5PZ6531q2P2dHW5rbTSwfRz2+NnxvVjjHhpv0vd/wKWHvpAHjzu3Q0IBu6MNwqMTmpnAb\n5eLfaV2fIwDYN50c5O5sACieejStu3dmu/ZFCY+GMy7plKFnq0GltEflbKNb0/N6ic6HkTl6BaaG\nKVxgB9IJp64o68F0IixXMs5P5qpXZN9umNwFuiMSYQAAAADQxcKJ2tMT3zsKrumhO8IVNDoYGRrJ\nCeerumZZOASQ7szWOvRQUk3c5O6F9jpTcG1ret4YqUsP0+QCnyrPsS68+1m9Epxcd2YzRwcAdJx6\nHSW1L5sfnZvuJTa7w3NQVZtKaI90DJoevDqxje7MxJj7zSJx84JFqeeYS5rFlbUzfk8Usj5+MwDd\nE4kwAAAAAOhiLgmmwJDm2FByyw/MKADpJqOPo2Cl7tzXsEu6M3z/hifD4X3C53osXG6jL5pvQ6fP\nsXwoKKUgpyQl0tYtnBmuu6u4OUTycYzhiQCgJHK2L+neTiMS5lCqReVuj1Tf6x+YFT7X7wX1DI+2\n0UqSHd6zyDrD5qU3ZJ0XzKffLy4Jpt8gmq+0PvL5F+9oLHk9FZLc4jcD0D2RCAMAAACALtS85uFM\nQCkumFUIBX40F4YeovW6Ya0UiBpyzlV5BYd097YoMacJ7itBr76DMs/DpGGWwJubF6Q7zl0DAJ0h\nV/uiJEd36VlT7vZIQwyG5Qjqe/wVi7t0iEr9PnA9zvPpbb4zXVZ9TjfkdCXXo16947I53Hyih1+f\nApKcAKpbTwMAAAAAdJmDW08MeegCjPkKh0Z66OrwEXdHs+7kH3VxKvCUbXjFKBc06ju8chJJA8ae\nm3muHglJFJR0PdWS5vk41sLd3wCQzf6NT+ZsX9QbyGle/bB1pTov6dbV13S/Pcq232qP8p2nqhB+\ncq0rk2DabiHzgonb//4duMmnWC5J17x6SdZeX3rf4QYaoPsgEQYAAAAAXci/gz5uqEEFb9zd3+3e\nC4J/GnZIj6QkV6+TBlqhjh3aE/49uD1+nX6yqauonlxQa+eK+Yl3eO9+9v7M8+i8NX2HTw3/JpVd\n+3U4x53jANA9HM+0L7ueuT/np4tpazrCbzsPblsV+5l8k3OFJtL89iicOy1Le+QSMKWcR83te9Lc\nWmEb3bTcSknrfPl7qeEY85kXzHFlPZDQ7mo+Un/OtVJyw0GHv6Oeiv8dpf3SMRTNd8d8YUD3QSIM\nAAAAALpQv5GTM891572f0FLCZu3CmZm7v+V1L2DXMOnSMCDllvXvahaty80tps/lO+zi4KmpZRQg\n0jBILsinYJL+vfruqVYOmqfGDXWkevGDj3pty9IbMnerK6AV3V93R7rbD19Y1+m52gCgu9P107Uv\n24Lrqn+TgehaqbmiJGxfxs1IXNereSTSovx5uA7E9ALu47VpujnCb//cNd7NdZnEvzmitcCbIDra\nHnWE612m7WguML+NVlLHb8tK1VvOnxdMwzgfNwtvHIl7+Mk518NKdaxj4t6LO0ZxZc11HmSjOnf1\nrnM4qd1PbafRRnajee4AMEcYAAAAAHQpBWmGTp9rO5+aHwaZ1sQkmRRIcgky3fnugmAKwo37yGJb\ntzAV9Fr/vVnhawroKMh02EvqKHCVr2HT59irKxdl5n5xwTyftqH3u3JIKgU+Rwf7oeSe9veF28dm\n9jcsSzrApvoaHbO/p55zlb3y9Pw2+6Vljwb74JZ16wKA7k7ty4agXdE1semh2UEyZG54fVXixb9O\nnjat/fxgulGjV5A80bVV19odQbJK1/BJ163Ma9v+8m7b0eU1R9X+hcvDz7j2r65vQ6ZsGj7xaJYh\n8dSWaohhLa/2RNf/wVNn55UQ6Wh71BF+G63yuzm7fO53g8qhR0d6Oilh5G9j/QOzsn5+xHnzMnWo\nhKFunnHnQfT3hOpLSTXVYVwyMp/zIBvNoabfVa7d13kYPYd1noz/SNfOtQag/OgRBgAAAABdbPRF\nd4YBPXf3vaPgjBJYE65dlnktOgSiAjoKCOmOc3FzgbkAjxJtWr6Q+ccUMJtwzbLMOn1an7Z32rvm\nZrbXlcMkqkxn3bgxc5e321/9VX2pHicG5YsL+rn98u/MdwFL1aPqqX/jDAMApNoXvy1w1/to+zJs\nWvueV7reKgHk2jWXkMlXPstr+0q0+J/xyzbx+uzJEiVr/Hau0JsgXHvk2te49kj1U+rh9nK10drm\n0GlzMq/t37DcysUlreJ6xLmyDki3u3FDPbrzwCnmPDozOEbuN1bcOazzpC9zgwHdTo+6YRcctxI6\nsv0xAwAAAADkxyWVFLwpdNJ2F4Rzyyvo09EAnL9OBbTqK+iO6ej+FlJf/nxglbZfAFBp/Out6Hqb\nT/vS0TbEXz7bNl0SpZi2z7UHHWk3O9IedUQlt9FRfrub7/nj5Hse5NKR8wRAefUefqGVEokwAAAA\nAAAAAAAAVIRSJ8IYGhEAAAAAAAAAAAA1iUQYAAAAAAAAAAAAahKJMAAAAAAAAAAAANQkEmEAAAAA\nAAAAAACoSSTCAAAAAAAAAAAAUJNIhAEAAAAAAAAAAKAmkQgDAAAAAAAAAABATSIRBgAAAAAAAAAA\ngJpEIgwAAAAAAAAAAAA1iUQYAAAAAAAAAAAAahKJMAAAAAAAAAAAANQkEmEAAAAAAAAAAACoSSTC\nAAAAAAAAAAAAUJNIhAEAAAAAAAAAAKAmkQgDAAAAAAAAAABATSIRBgAAAAAAAAAAgJpEIgwAAAAA\nAAAAAAA1iUQYAAAAAAAAAAAAahKJMAAAAAAAAAAAANQkEmEAAAAAAAAAAACoSSTCAAAAAAAAAAAA\nUJNIhAEAAAAAAAAAAKAmkQgDAAAAAAAAAABATSIRBgAAAAAAAAAAgJpEIgwAAAAAAAAAAAA1iUQY\nAAAAAAAAAAAAahKJMAAAAAAAAAAAANQkEmEAAAAAAAAAAACoSSTCAAAAAAAAAAAAUJNIhAEAAAAA\nAAAAAKAmkQgDAAAAAAAAAABATSIRBgAAAAAAAAAAgJpEIgwAAAAAAAAAAAA1iUQYAAAAAAAAAAAA\nahKJMAAAAAAAAAAAANQkEmEAAAAAAAAAAACoSSTCAAAAAAAAAAAAUJNIhAEAAAAAAAAAAKAmkQgD\nAAAAAAAAAABATSIRBgAAAAAAAAAAgJpEIgwAAAAAAAAAAAA1iUQYAAAAAAAAAAAAahKJMAAAAAAA\nAAAAANQkEmEAAAAAAAAAAACoSSTCAAAAAAAAAAAAUJNIhAEAAAAAAAAAAKAmkQgDAAAAAAAAAABA\nTSIRBgAAAAAAAAAAgJpEIgwAAAAAAAAAAAA1iUQYAAAAAAAAAAAAahKJMAAAAAAAAAAAANQkEmEA\nAAAAAAAAAACoSSTCAAAAAAAAAAAAUJNIhAEAAAAAAAAAAKAmkQgDAAAAAAAAAABATSIRBgAAAAAA\nAAAAgJpEIgwAAAAAAAAAAAA1iUQYAAAAAAAAAAAAahKJMAAAAAAAAAAAANQkEmEAAAAAAAAAAACo\nSSTCAAAAAAAAAAAAUJNIhAEAAAAAAAAAAKAmkQgDAAAAAAAAAABATSIRBgAAAAAAAAAAgJpEIgwA\nAAAAAAAAAAA1iUQYAAAAAAAAAAAAahKJMAAAAAAAAAAAANSkOgMAAAAAAAAA1Kwt23bZk0+tshdW\nb7Smzdtt9dpN1rz3Ndu77zVrOXQ4/Ex9fR87ZUA/Gz3yNBsy+BR76xlj7e1T3mKTzxxv4xtHGABU\nKxJhAAAAAAAAAFBDjh49Zv/zvy/Yg//5M1uy9Cnbuas55zKHgoSYHjtf2RP++yfLfp15b/SooTbz\n9yfbn1wywy6c+TYDgGrSo27YBcethI5sf8wAAAAAAAAAAF3rYMth+/q/Pmx3fO0/bPer+6wzjAmS\nYtd89GK76VN/bHV1vQwASq338AutlEiEAQAAAAAAAEAVa973mt11zw/tq/csDp93haGnNdjHrrjI\nPnXtJXbakAYDgFIhEQYAAAAAAAAACH1z0X/ZLf98v73a3Dk9wHLRsIl/N+dP7dqPXmQAUAokwgAA\nAAAAAACgm1u3YYv9xQ132s9/8aJVgnec/Rb7f9/6OxszepgBQEeUOhHW0wAAAAAAAAAAVWP+Nx+y\nqed+omRJsLq6OuuoXz77fzbh92bblxb8mwFAJSERBgAAAAAAAABVoPXIUfvLmxbYTfPuCZ4fyXu5\nbImu3n1626lDBlspvP766/b3/3Sfzb35a3b06DEDgEpAIgwAAAAAAAAAKtzrx4/bDTd/3RZ+91Er\n1Kg3jLD6Pn1i3zvSesS279hppfS1ex+xG2/5lh0/XtJZeQCgKCTCAAAAAAAAAKCCKaF0zafvsHu+\ns9SK0bRpsx1ubY19T73BevXqZaX2tXsfDsv8OskwAGVGIgwAAAAAAAAAKpSGGJx789ftgf/4qXUG\nrb9Hjx7WGb4blPn6v74rHNIRAMql47MgAgAAAAAAAAA6xY2f/6Z9/V8fsUL17JnqA6F5u7Jp3rvX\nOpN6salH29dvn2MAUA70CAMAAAAAAACACvSlr/6bfa2IJJj06tXTzp78Jhs0sL+V2skn97M+fXrn\n/flvf/dRm//NHxqA0vrCHd+193zwJnvj26+0u+5ZbIhHIgwAAAAAAAAAKsymzTvs8/98vxXryJGj\n9squZrv6z/7Q3jLh9KzDH2qOsL4n1Vu++vXta/X1yZ9/y4Q3Wl1d28HIbv7Hf7XfbNhiAErnZyue\ntyeDh64X506fbIhHIgwAAAAAAAAAKsyf/cUX2w1rOGLYEBs8aIDlO6XXb7fssGdX/cZunvtn9r7z\n3269e8fPlKOhCye9eYydMqBfXut9Zddu27//QOL7L29osqNH284L1tp6xD7+mfkGoHT27H0t8/z0\n0cMM8UiEAQAAAAAAAEAFWfjdR+2Xz65t9/r+1w7aRe99p/3xB2bYsFMHZe3lJUF+y/7nFy/Yvz+8\n3L5485/bDX95eZBIO6Xd55Rw2/HKHvvQpTNt4Cn5JcOyiSbBnJ//7wv2zUX/ZQBKY+++EwnphlNO\nNsSrMwAAAAAAAABARXhld7P904Lvx7534ECLLVn6c/uLq95v317wGfvRT39lSx59yrbvfDXs1RXn\n2LHX7UeP/8rGjhlhN3/mIzbxTaPtjq/9h61ZtylIgJ1Y5nfbdoVB9Ws+cpF9Y9Ej1tLSap3hli/d\nbx/+4MyyBe01hFxT8JCGgSfb5DPGWyVTeZ97aX34vOGU/jb5zPEVnfBo3veaPfKjp2zgwP52yR9O\na/fekytWhc+nBPU+psJ6MKl8mzZvt1Uvpup7zOjhFV/fTqXVZaUhEQYAAAAAAAAAFeLuhQ/bb7fs\nTHz/wGst9vX7HrFX9+yzz37qj+2qP73A7vvej+2RHz+dmBA7evSY/ev3fmSNQbD841e+P0iGjbH5\n9zwYLPO/dvDgofAzWu5HT/zK/uWWj9lVH7rA7g3WqXnGSk3l/uo9P7TP3/hR6ypKJi349mL77r/9\nJEx2+JTk+MD7poXlqaRkwl33LA7LvCmdtPMpwfTl2z5R9vLqOH7120vC54//8Hb7zg/+275wx3cz\n76t8el1/tT96z6//z994hX2uC8+DJCqTyhZ3fsiVH3pvxZwf7/ngTZlErjy0aF54DitZ+sa3Xxm7\nzA+Dz7z1jHHWnfXq2X/8PCuhz1fAiQsAAAAAAAAA1UYJqys/9SV7LZ2cihp4ioY17GGHDh22F/+v\nyXa/us/ed9477LIPvNt+//fOtNePHbPtO/bYay3tl28NklovrmmyMyc22runnWXvPGeS9e/X11av\nbcpsT/N47dvfEiYofvu7V+w3G7YGrx63Unv+xQ123bWXJs5ZVkpKwHzkE/9oP1vxvB06fKTd+3pt\n1UsbgoTOYtNAk+dOm2zlpMTX5Vffavd8Z6ntjUnKyNqXN1dEeR9b9uswAatyNu87EJZJySKVS/W6\nN90D7HDw/DOf/6adVN/Hfu+ciZnk3pPBMVH5G8uYYFLvr7ef/5eZ80NJpWFDB1vDwP6Z+tf58fCP\nV9glQcJUr5fTF+54IKw/lU2Pr/3Lp8MyqY5vv+sHmdf9x59cOqOsdVyM24L9LCV6hAEAAAAAAABA\nBbjja/9uO1/Zk/h+z55BiuH46+FzJc0e+q//sV69etnff/YKe9fbJ4W9Pn7xzBq77//92P77yWdt\n9559bfJYv9u+y/55wfdtzOnDbOKbTrdPf+xSO33UUPtysN2X1m0KVn3cfv3cWnv616vtlps+GiTV\ndtszz63LmQrre9JJVhcktfbvP2D5UNLk6/c+bDde9yfWmRRM93sonTvtrXb9x2eFw/I17z1gTVt2\n2CM/WhH2ZJIvpIPv5eqlpN5I53/wpkyiSEmZ6z/+QbvqQ+8N/62eQN/5wU8qprw+lelzQQLVdZRR\nzyUlupRE0jHwe4fpdb0vSjDpuJSD6lnlUL2rrlWPV374gsxQiHpfZde+6bmOza8f/0ZZh0pUT8C9\ne098z66Zc0fm+b0LPhu7TLUlwTpDj7phF5Q0pX9k+2MGAAAAAAAAACjMG992pW3acmLYMyWXevbs\naa2Hk+fr6l3Xyy69aLrd8ldX2pvfODp8TcMd/vyXL9p3gwC+EmKv7tmfGTJR6/uTS95t//B31wRJ\niaFhL7BfPvt/tuBbPwznEjsc/PvtU99s93/tr8Ok3Mdu+Ir9ZsPv2myzvr4+nHvs6NFUD6s+vXuH\nybIjR45YvoYMHmhbnv++1QXl7wxKGF0z58vhcyUuHlw0LzHhol5BLiHiJ3O62mc/982wV5X4iaMo\nJWb8BMhPg8+VI5mkJJHruaPtqxyWKeOJ+peXf/WdzL4oCXnamy8Ln2uYxwcX3WLloKEEleDS+aGy\naz6wOKprl3ws5/kRp/fwC8O/k4MkuJJ0tcLtV6n0NAAAAAAAAABAWf1k2a/bJMGkvk+fsLdVNkeO\nHrMfLv25/c0XFtozq9aFPcX69TvJLpjxNvvqP18f9hKZ/WcX2vChg61Hjx72+uuv2+JHn7Ivf+M/\nbNuO3danT2/7/XeeZf9y61/Y38z5sI1+w9AwMfSDJcvt7Mlvsn/8+2vsjeNGttlm/5P7Bcmw3pl/\ntwYJsEKSYLL71b328/99wTrLF7yh1b58219mTRQpAaLeQOVMcigh45JgkpQEE81Zdf3HZmX+fZvX\n661crvzQBW3+PWb08Mxz1b2/LxrKz/WqUu/AclCizvW807FPSoLJl7/wiUx577pniVUKf/64cg/Z\nWOlIhAEAAAAAAABAmf17kHiKeu21g7Z3775ci4a9sx796S/txlvuscd/ttJaW4+Grw8KguMXv/ed\ndvu8j9u/3nWTXfXhC2zY0EHh+9/5t8fsvu//xPbtPxh+duzpw+1T11xqC/7xk/Z7Z08MyvNkmBD7\nowvfaV/8uz+3YacNymxv96t7wrJ11IP/+T/WGfwkh3ocXZkeWjCbT398VoeTYM1rltjuZ++31uYm\nK9SCe04kwVTeMTmGs9M8bi45o6EG/aRIvrY9fqu9eMdYa3roajt2qNk6Ilt53x2ThBzYgcRNy7bn\nbN3Cmbbm7qlhnRdjQTqh1XBK//DYZ6Mkk0uUKXFXTF07O59akKnzYs4TFIdEGAAAAAAAAACU2RNP\nrbKOUE8v9bD6uy8utMeW/Toc4tAZOOBke++5Z9s/f+5aW3jnZ8OE2MCBA+wb//qIPfLjp+3w4dRn\nBzX0twtnvs3+5daP27vfdVaQXPuF7d6z3z4QJJP+6tMfsv4n97VSWvzoz60zPBzsk/PRPJJgpbBl\n6Q22/oFZQYJjtq0NkjSFJpaUzHKivaviKDnzgfdNy/z74R+tsELsXDHftj4xzw7vaQqSd4tsR5Cg\n6YhBXdgj6eXvzbL9G5fbwSAhpjovtK41NOPzL60Pn08+c1xey/jJvCdXFPddVT1vfnRups6bHrza\nSkUJPSSrMwAAAAAAAABA2Wxo2mqbt+y0UnhhdZP90/zvW5/edTbz96dYnz4nQsBDBp9i75lxtp3x\nljF2wcxzbPHSp+wHi5fZ2NOH2TvfPsl69ewZDpU49azxdsqAWbbily/Z5t/tDJMuf/5n7wuTBw/8\n++N2LEi6Fat3sH4N0ah5z3a+0mxbtu2yUSNOtVJq+u2JHjvnTp9snU2JmB1BYslpDRIdStIMGDsj\n73W4xIxkG6bPN/kMfS41d9Uqb/l8HNzaNpmjXlYdMTDdO62zqW718BVa16te2pB5rnnh/PnW8lpm\n72tWjMN7NrX5d0d74TV5PdMGDuya+q9WJMIAAAAAAAAAoIyeKzCJkc3x48ftVyv/z27+4r0276+u\nsvfOOKfNfF51vXqF84CNHH6qTXv7GfbLlWtt89ZdNnzTdhs/NjUXWK/gMxPGjwqSYSfb1u27wmTY\n+MaRdtvf/bm9vGGrPRUkyIrVu1ed1Z/UJ0yEyc9WrLI/u+x8KyU/qdTQBQmaXic1hA8/sVE/qDHv\n5dVDyZdvmRu85MfeApMzDWdcYrtXLjrx70mXWDXoE9Srkl7qESb16X8XS8N/6tEVVMfbnpiX+ffA\nKqnzWkAiDAAAAAAAAADK6FdBMqrU1IPlb//hXjvU2mozp08Je4P5evXqaW8YcapdfGqD7djxqu3a\ns89+u3mHne7N9TR86KAgGdbXNjRtt737XrMRQwfbl7/wCbv86lvDnlzFONjSEj5OlHNjkAizqjfh\n2mW2KT3X1mnT5lifhsa8l1XddpTmripEw8RLbfwVi8OeYQPGnduhZFJXU7mbVy+xYy3NNuSc2Vao\nTZu3Z56fO+2tOedji8q3x15UvxFT7KwbN9quZ+8PEnhjbMjZsw1dg0QYAAAAAAAAAJTR80EyqBBv\nftN4W/ub7L1YBp5yiv3fb35rN//Dv9r1H7vULv+jP7Dhw4a0+5yGUBw9aqgNC5Je24KE2Nbtu23k\n8BOf69f3JJs4YbTt2NkczhF2zpQJ9o+fu9Y+dsNX7HC6V1dHbPrtdis19ahqTieX9LcreoUpyTHx\nupVWjEITMY4/RF8x61AyTI9qo953HUkijRk9PPNcc399/saPWldRj7aR599i6Fo9DQAAAAAAAABQ\nNrte3VvQ59e9vCHvz27YtM2++JXv2QMPPmG/y9KLS3ODKZly6uBT7MiRo23e01CJI0ecSI796Qdn\n2l9/+kPhXF/56tOnjw0e1NDu9ZfWbrJS83vsdNWwdx3lJ7Kefym/4+vPC1ZsMq07avTqapM3zxZq\nF4kwAAAAAAAAACijLVsLG2ZQ84DlsnffvszzXa/us9u/9u/24CM/s605hjRUQqx37/iBxDScovP3\nn/mI/cG7zrJ8vf7669azZ8+YchY2pF8+3j1tcub5bXd816qBhuhzlvzoqbyWeXLF897ykw35UdLQ\n9RJ85EdPZ3oPVptGkp95IxEGAAAAAAAAAGW0zwvED2oYaD16lD5s+2qQDPvSV//Nvr94edaeYflS\nb7BFd/2VjRxxarv3hgwZ3C7pdfToUdu1+9V2n93bCUmIqz703sxzJYv8hFGluvJDF2Se33XPkpzJ\nme/84CeZ3kxK7PiJNOT20XR9a261r97zQ6tGA70hP6ul52O5kAgDAAAAAAAAgDI63Hok87xPfZ/Y\nz0x40zjrqFd277V//ur3bdH3f2K/2fA7e/313D3Lshn9htPs3759s9XV9Wr7xvHjefVak5ZDHZ9n\nLEqJoes/Nivz72vm3JFzCLzb7nigrL3HlMhyySwlZz77uW8kflb78oWgvE5XznFVK/xkqRKPuc4P\nJSbvumexVZKGgf0zPdtWvbQhMXn65IpV4fvdGYkwAAAAAAAAAKgQO3a8EiSRXm/3+ubNWzPP+/Wr\nt6lvfaP9/jvPtLdNfbOdOWmsTRg/KkwAjRw+xE4dMjAIkp9s/U8+yfqeVJ8a7jBIVmlow737DtpX\nvvGgfWvRf9rzqze0mw+sUO962yT7x7+/Jnyu3mynnTbEdr+6J0yE9erZ0047dYiVw+dvvCIzb5aS\nHG87/5Nhoiua8FCS4D0fvClILH03TC595wf/beVy74IbM4kNlePy2bfGlvf8oLzudSXPrvSSOsiP\n5pFzyVIlHlWn6mUXx50jn/n8NytuqM2Pej0Jo8lTJcY++7lvBmX/K7s/Yd+6izoDAAAAAAAAAJSN\nklUHWw5l/cwb3jDC1m/YFCbJDh06Yq/s2mtve++b7YJzzwmSTQODJFevMKl15Mgxa209Yq16Hvw9\npOetR63l8OFwuUOHDgfbOmyvB+v53dZdYYLsTeNGBcmy4kPFN3ziMvvVyrX2Hw8/2eb1Y6+/bgcO\nZB/i76T63tYZ1Fvm8R/enkkaKdmhRJceLkG2d++BNr1oyj3EoLb/06DMSrqoXA//eEX4UNJGCTIN\nf+eXV68/uGieoThfue0T4d+7vr04PEeumfPl8PyYcsZ4GzjwRE8rf9jBjvWhLD31bFP5RcnTR36U\nOl+agv3xk6h6/Stf+IR1VyTCAAAAAAAAAKCMBp7SL2ci7OX1GzPPXw8STFu2vmL3fvdR+/FPf2Wz\nLp5ul1403SZNGGNDBp8S9sbSsIf6nPt77PXj6ddTrylJdTz9fN/+18JeZB3xtS9db8t/vspe2d3c\n5vWWQ9n365QBJ1tnUWLp1z/9epjccMkCiRsGT72qvnzbX2Z6ZJWLkhi/fvwb4XCObm6z6PxPKuP1\nH/+gffrjs8pe3mqnZNiUoM6/kO4tuCmSQHJ0LqnHXqXNxabzReXS+SJKlPpz4vnnSnfWo27YBSVN\nYh7Z/pgBAAAAAAAAAPJz1h9ca//3m81WrLpevexN499gf3TBu+w9M862syaNtVMHdyyxVYzlT62y\n9/3J39rRY8fyXubst77JfvGTu62zKbmhBMEjP3oq06tKyY3JZ4y3Kz98QUUmlJQAU5lXvZRKhA0c\n2N+mnDHOPvC+6RVRXpXPlS1apua9B+yRH68In6uOlbDxqaebeuRpny75w2lWCVQm1fdvf7s9PEd0\nfrjyVVoCLMqd388Fx0P1Gp7bQZ2fO21yVSZLew+/0EqJRBgAAAAAAAAAlNGHPvYP9sP//B/rqJ49\ne9rpbzjN3n/hO+2PLnxXkIAYZ0O6OCF26+3ftX/48gN5f/6CmW+zpd//ogGAU+pEWE8DAAAAAAAA\nAJTN2PScVUXpkUqA9ejRM5z3S3MDff1fH7GP3fCVcEjAnz75rL2yq9m6yt/M+bCd8ebGvD//1jPG\nGgB0JuYIAwAAAAAAAIAyOmvSOCtUjx49wjm/evXsFSbSzjpjnA0Y0Nf27z9or+zeZ3v27LP/eux/\n7X+efsHe9Y5J9oEL32VnT55gpw3p3B5i9X1621f/6VN2/gdvyuvzb5/yFgOAzkQiDAAAAAAAAADK\n6Nzpk61QE9/yJlvzf7+xY8eO2fpNW23n7uZwLqb3zjzH3jHlzTZk8Cl24LVDtu/AQdu377VwzqMN\nTVttx849NmLY4PD9zvLuaW+1Pzzv7fbjJ36Vec0l7qKmROaOAoBSY44wAAAAAAAAACizN5z5IdtZ\nwBCGSYmlfn3rbXKQXPrTD55n7zv/7TZ61FB7/djrQcIs9dDwia8fO251vXvZyf1OslLYt2+fvfba\na9a7d28bMGCA1dfX289WPN+mV9jYxtNtx45X7GBLS+a104Oyrf/1dw0AfKWeI4weYQAAAAAAAABQ\nZrMumm7f+s7SvD8flwSTgy2H7elfrbZfr1xrdy9cYhe/9/fsouDxjqlvsZNPLk3iy/fjH/84TH45\nSoa96U1vCnuF/f47z7Sf/++L4esbm37bbtkZv194TzgAKFRPAwAAAAAAAACU1WUfeLeV0pGjx2zd\n+i02/1s/tMuunmfv/8jN9u0g0bZt56tWKs8++6z94he/aJOUO3LkiK1bt86OHj1qlwbJvWz+5JIZ\nBgCdjUQYAAAAAAAAAJTZH7zzrJzzdvXq1cvePCF+Tq03jmuMfV1Jqn37Dtr/PP2CXf+3X7N3vOdT\nNvu6L9mPHv9lkCw7ah2xcuXKcI6yPXv2tHldSTC99oE/fFfismNGD7MLZ77NAKCzkQgDAAAAAAAA\ngDKrq+tln/3kH2f9jJJOa9etj33v5Q1NlouW377zVfveg0/YJVd83s6Ydo391bx7bNPmHVYM1xNs\nw4YN7d7THGZjRg0L9yvOtVe8zwCgK5AIAwAAAAAAAIAK8KlrLrGGU062rqAk1sbfbrc7v/mQvfHt\nV9oVf/lP9uzzvyloHWPGjAn/7t6925qamtq8179/f+vZMz78PPS0QXbjp/7EKl3zvtfCvw//eEXR\nycJ8PLniefvqPT8Mt/GdH/zEuoLbt1y+es/i2Nc/+7lv5F0nn/3cN+0Ld3zXqlXcft4V1Eu+dRhV\n7HKi8+T5l9omnqu5brsKiTAAAAAAAAAAqAD9+tbb9R//oJXDDxYvt9+74DqbNO3PbUE6KZPL9OnT\nraGhIXy+du1aW78+1Vtt1KhRdtJJJ9nqdZvs6NFj7ZZTb7CknmKlFt0PJSFcIiLbe3L57Hnh3yln\njLeBA/snrjOfuoomP6Lb0vOBQRL0A++bnlfZk7hl4j7rr++rkWMcty05d9pbYz8TLXu2cq16ab19\n/saPJn4227L51EGuuo1bj79c3LHw/33NnDvaLfeB903LJK1zLR/lzqt8y+p/Rn/37D3Q5jOX/OG0\nxPXlc850Bz3qhl1w3EroyPbHDAAAAAAAAABQuL1B0HrC7822V/fss66kxNWhQ4favPbud51lV/zx\ne+wP3vVWe+PYkbHL7d271375y1/a5s2bw15gZ599tr3xjW8M37vm03fYd/79v9t8/vRRQ+1/H7vL\nThvSYJ1NPZGO9zB7/sX1du+CG8NeTEpoXfmhC+yRH63IvPfgonlhT6xVwfO9QZJBSQ5pCpINk88c\nH75+7rTJbXpraY4zJXeU1Dj99OHhckoaad0+JSy03beemZrbTct85vPfDJMo2ra2NWb0cHtyxapw\nG+6vtqVtPPLjp+3XP/263XbHA0F5tofr0Db8BJXo88+9tCEsh7ap7f32t9vD9Wt9Sua8O1jm+Rc3\n2OduvCLs5ebKo33Q53+24vmwLi4L/t0YbPvTQVJWZf/pD28Pl1d53Gf0upbVely9KYkbVy5Xj0oo\nuvVo/79821/a+R+8KbOtyWeMa7OsejopieOOkXphuTrQfml9KsfpQf01DDw5LI/Wd264n+vb7bsr\ne6qX2/FMMknnhN7TOaJyuTKmEqAntzkPVH9ar46TtvedH/x3mzKJzi3R8td/fFZe9aHnWt4vq+rd\nHXfV70c/fEFYBtWJO876zHuCfdbft73nk+G8fCrTQ8F++vuiXocv/+o7Vi16D7/QSqnOAAAAAAAA\nAAAVQb2Cbv3rK+36v7k7r8+PHjXSNm/Zah01eFCD7dj5SjiPmPOzp18IH3LWxLE2Y/pke9973mG/\nd85EO2VAv1R5Bw609773vW3WpUD9rV+6v10STP52zp92SRKsOZ0oeHDRLWHyQMkHJTyU7NDreihJ\nMSio7+/820/sSiUZzng5fP3JdFJECQYlO7S8KMGixIoSC5fPvjX8nNb5lS98IlyuKabX0YIg6fL5\nm660twZJns8EiTkNa6ekx5Ufem+4jJI9V35oeLvltF1tx5X1uaAMnw7KuylIiiiZEk04KZnmyqbk\niZJdJ9Z/QZB0+kS4H0qwKAmjBNZVwevaByXBtKw+r8/ofe1TtDxK/mwK1u/qI1XPr4X7o+RNg9dr\nztG2XT1edvWtYb2qjErQaHtKgum1KJVLSSeXSHrkR08F2305TGSJyh9Xt+odlaqnHZkhA6//2Cy7\nJEgyKQGm9Uw5c1yQdBsflkPJNW0jlQh9OTiGO8PPa18+GyQslYR05d/02x1hPaYSS6vCdUfLtDeo\nDyWglNjTOZitPlQHOg907JTQUzlUF1r388E63PHQOax1Pfn08+Fx0vHRNrQe36eDcmt9jeExejk4\nZzbYV4Jko+rntm4+fCJDIwIAAAAAAABABfnE7D+y33/nmXl9dteuV60Utm7b3iYJJr3qelmPHqkQ\n8gtrNtpdC5fYRR/+Oxvypll2xvRr7OIP32yf+ftv2D98+Xv2pa/+m/3NFxYGyY55Nv6cj9rd9z7c\nbhvvOPstdu1HL7KuoJ516s0jY04fHiYP/GEDRUklJTWUVFIiQq8rKZFEyRlH61ayRMu7dTYMPDmm\nHAfC5KbofQ1rl888YC7R4vQIezCleh5dFel15vbFLRNdVskUJYG0b3v2vtZuuVSybXtYD0qiPO8l\nulKf2ZHuWRSXsLvCTj99mH3124szPaGycUNMDjylf3iMkoaVVN1qvSrXlCCRowTQ8aAWHP07rm4f\n+XHbMjR7++uOz8NeOR9u9/kDmfr49McubftesL1osjNaJiWiNLylknA/886XJCqftvW5mz6a6T2o\nenb1pG26+nA9BldFjo8TPa9UP6enz0/XI7G7okcYAAAAAAAAAFSYb335Bps64xPWeuRI1s+1RIYz\njFNf38dOGTDAXtm12wpx6uDBdiTY/qt7mtu9t279lvDxk+W/zmtdPXv2tP/3rb+zruJ6Uyl5pQTN\nZC8RoCH4mrbsCBMOPwsSC1POfGNmuDk9TiQhXgt7GSVuY9TQMNmhbagHjpIV6mnkUw8gzcf17umT\nw8+qJ9BtVjiVSb2NlBwqdK6jMEkXJIyUVFFvKEdJlQ/84bRwKD1XFwNjenUNDJd9LVw+Ot+UeiW5\nXki55qJSb627grpQUub5l9aHPZWSqG6VkNMyP0sn9nQMU8MjpnqS5VO3Su6FvaF6WLifqR5XyQmq\nKeEQiC8HydPJmYRTtvMgWqY9wWcHhXO9TUtMDOqzWl+qF16QjD091cuu4ZRUYtUlv+StwfmU6q22\nIVx/IbT+227/Tlg/KqM/l1h3wxxhAAAAAAAAAFCB5n/zh3bTvG9ZR/Xq1cv69etr+/cfsHK57W+v\ntr+Z82HrSuGQgi+lEgxKiKwKkg9uHqroe+7fGuZPvYLCOaGU/Dh+PExwKUGkz7jl3RCC+rvqpdTQ\ni0qCXfK+abHlCJNO75seJqRcObSdsOda8Fr0r/Xo0eazot5Lrrxx21AZ49bv5oiSVLJuXKZMSia1\nq6f0vvn76T4fDil4+vA2dZGtXP46ROVQ8idTF957uY5f3La0r0pcRdfn73tS/Uf3z9VftIxueEqt\nK1rHcWVKDZF4ILN8u/pIn1fabnRb+rcSYY1BYjJu/W2Os3cO+n/dZ9z+iRKQbgjHalDqOcJIhAEA\nAAAAAABAhfrkTQvs29991Iql3mAn9zvZXt2zp6DlegSJmOPHSxM6/uQ1l9iCL37SapGGwFPiQYmP\nL9/2l5mhEoFy8+dJUwLz0+n51qoBiTAAAAAAAAAA6CZaW4/a3L//un37O0utGH1697Z+J/ez5ua9\neS9zcvD5hoED7Xdbt+X1+WxJs09e8wH78q1/YXV1zNIDID+lToT1NAAAAAAAAABARerTp87u/ufr\n7Yo/fo8VQ3OMFZIEk9deO5h3EkxDLjaOGR37nso8/x8+SRIMQFmRCAMAAAAAAACACtazZw+7d8GN\n9sk/v8QqzcGDLbax6bftXv/4lReFZVZvMQAoJxJhAAAAAAAAAFDhlAz78hf+wj51TeUlw6I+9tGL\n7M4vfiosMwCUG4kwAAAAAAAAAKgCdXW9bP4XP2n/8LdXB0mmygvtaj6y22/9C/v67XOC5wyHCKAy\nkAgDAAAAAAAAgCry13M+bOt+scjeMfUtVin+4J1n2crl37K5f/FBA4BKQiIMAAAAAAAAAKrMmNHD\n7KkfLbBv3D7XTh81zIrVo0fHQsSDGwbYXf98nT2x5A6bMP4NBgCVpkfdsAuOWwkd2f6YAQAAAAAA\nAAC6xiu79trd9y6xhd/9ke3ctSfv5U6qr7fTTx9l636z3grVcMrJdv3HP2if/vis8DkAlErv4Rda\nKZEIAwAAAAAAAIAacPToMbv9a/9u9wYJsU1bdlhnOHXwQPvMJy+3T11zifXrW28AUGokwgAAAAAA\nAAAAWT227Nf270uW2/KnVtlvt+y0jhh66iC79OLpdvkf/UE4F1hdXS8DgM5CIgwAAAAAAAAAkLf1\nTdts1Ysv26+eW2svvLTBdr263zZvfcX27X/NDh8+En6mb996Gzignw08pb+d8ZYx1jh6uL110jg7\nd/pb7Q0jTjUA6CokwgAAAAAAAAAAAFCTSp0I62kAAAAAAAAAAABADSIRBgAAAAAAAAAAgJpEIgwA\nAAAAAAAAAAA1iUQYAAAAAAAAAAAAahKJMAAAAAAAAAAAANQkEmEAAAAAAAAAAACoSSTCAAAAAAAA\nAAAAUJNIhAEAAAAAAAAAAKAmkQgDAAAAAAAAAABATSIRBgAAAAAAAAAAgJpEIgwAAAAAAAAAAAA1\niUQYAAAAAAAAAAAAahKJMAAAAAAAAAAAANQkEmEAAAAAAAAAAACoSSTCAAAAAAAAAAAAUJNIhAEA\nAAAAAAAAAKAmkQgDAAAAAAAAAABATSIRBgAAAAAAAAAAgJpEIgwAAAAAAAAAAAA1iUQYAAAAAAAA\nAAAAahKJMAAAAAAAAAAAANQkEmEAAAAAAAAAAACoSSTCAAAAAAAAAAAAUJNIhAEAAAAAAAAAAKAm\nkQgDAAAAAAAAAABATSIRBgAAAAAAAAAAgJpEIgwAAAAAAAAAAAA1iUQYAAAAAAAAAAAAahKJMAAA\nAAAAAAAAANQkEmEAAAAAAAAAAACoSSTCAAAAAAAAAAAAUJN61A274LgBAAAAAAAAAAAANYYeYQAA\nAAAAAAAAAKhJJMIAAAAAAAAAAABQk0iEAQAAAAAAAAAAoCaRCAMAAAAAAAAAAEBNIhEGAAAAAAAA\nAACAmkQiDAAAAAAAAAAAADWJRBgAAAAAAAAAAABqEokwAAAAAAAAAAAA1CQSYQAAAAAAAAAAAKhJ\nJMIAAAAAAAAAAABQk0iEAQAAAAAAAAAAoCaRCAMAAAAAAAAAAEBNIhEGAAAAAAAAAACAmkQiDAAA\nAAAAAAAAADWJRBgAAAAAAAAAAABqEokwAAAAAAAAAAAA1CQSYQAAAAAAAAAAAKhJJMIAAAAAAAAA\nAABQk0iEAQAAAAAAAAAAoCb9f4Xu4gubkkvDAAAAAElFTkSuQmCC\n"
},
"media/word_frequency_vs_word_embeddings.png": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAABsIAAANVCAYAAADC3+sUAAAACXBIWXMAAAsTAAALEwEAmpwYAAAA\nAXNSR0IArs4c6QAAAARnQU1BAACxjwv8YQUAA1fCSURBVHgB7N0HnNREG8fxOQ6QJkVRbDQRbGAF\nC2JHwV4Qe6Wo2F4BOypi72DvYkNF7L1XRFTsigqCAoqCSEc6+85/7rLmcsmWK3u7e7/v571XWPY2\n2WSSzMwz80xBzWZ7xwwAAAAAAAAAAACQZ2oYAAAAAAAAAAAAIA8RCAMAAAAAAAAAAEBeIhAGAAAA\nAAAAAACAvEQgDAAAAAAAAAAAAHmJQBgAAAAAAAAAAADyEoEwAAAAAAAAAAAA5CUCYQAAAAAAAAAA\nAMhLBMIAAAAAAAAAAACQlwiEAQAAAAAAAAAAIC8RCAMAAAAAAAAAAEBeIhAGAAAAAAAAAACAvEQg\nDAAAAAAAAAAAAHmJQBgAAAAAAAAAAADyEoEwAAAAAAAAAAAA5CUCYQAAAAAAAAAAAMhLBMIAAAAA\nAAAAAACQlwiEAQAAAAAAAAAAIC8RCAMAAAAAAAAAAEBeIhAGAAAAAAAAAACAvFTTVLDlf71hAAAA\nAAAAAAAAgHTVWqebqUjMCAMAAAAAAAAAAEBeIhAGAAAAAAAAAACAvEQgDAAAAAAAAAAAAHmJQBgA\nAAAAAAAAAADyEoEwAAAAAAAAAAAA5CUCYQAAAAAAAAAAAMhLBMIAAAAAAAAAAACQlwiEAQAAAAAA\nAAAAIC8RCAMAAAAAAAAAAEBeIhAGAAAAAAAAAACAvEQgDAAAAAAAAAAAAHmJQBgAAAAAAAAAAADy\nEoEwAAAAAAAAAAAA5CUCYQAAAAAAAAAAAMhLBMIAAAAAAAAAAACQlwiEAQAAAAAAAAAAIC8RCAMA\nAAAAAAAAAEBeIhAGAAAAAAAAAACAvEQgDAAAAAAAAAAAAHmJQBgAAAAAAAAAAADyEoEwAAAAAAAA\nAAAA5CUCYQAAAAAAAAAAAMhLBMIAAAAAAAAAAACQlwiEAQAAAAAAAAAAIC8RCAMAAAAAAAAAAEBe\nIhAGAAAAAAAAAACAvEQgDAAAAAAAAAAAAHmJQBgAAAAAAAAAAADyEoEwAAAAAAAAAAAA5CUCYQAA\nAAAAAAAAAMhLBMIAAAAAAAAAAACQlwiEAQAAAAAAAAAAIC8RCAMAAAAAAAAAAEBeIhAGAAAAAAAA\nAACAvEQgDAAAAAAAAAAAAHmJQBgAAAAAAAAAAADyEoEwAAAAAAAAAAAA5CUCYQAAAAAAAAAAAMhL\nBMIAAAAAAAAAAACQlwiEAQAAAAAAAAAAIC8RCAMAAAAAAAAAAEBeIhAGAAAAAAAAAACAvEQgDAAA\nAAAAAAAAAHmJQBgAAAAAAAAAAADyEoEwAAAAAAAAAAAA5CUCYQAAAAAAAAAAAMhLBMIAAAAAAAAA\nAACQlwiEAQAAAAAAAAAAIC8RCAMAAAAAAAAAAEBeIhAGAAAAAAAAAACAvEQgDAAAAAAAAAAAAHmJ\nQBgAAAAAAAAAAADyEoEwAAAAAAAAAAAA5CUCYQAAAAAAAAAAAMhLBMIAAAAAAAAAAACQlwiEAQAA\nAAAAAAAAIC8RCAMAAAAAAAAAAEBeIhAGAAAAAAAAAACAvEQgDAAAAAAAAAAAAHmJQBgAAAAAAAAA\nAADyEoEwAAAAAAAAAAAA5CUCYQAAAAAAAAAAAMhLBMIAAAAAAAAAAACQlwiEAQAAAAAAAAAAIC8R\nCAMAAAAAAAAAAEBeIhAGAAAAAAAAAACAvEQgDAAAAAAAAAAAAHmJQBgAAAAAAAAAAADyEoEwAAAA\nAAAAAAAA5CUCYQAAAAAAAAAAAMhLBMIAAAAAAAAAAACQlwiEAQAAAAAAAAAAIC8RCAMAAAAAAAAA\nAEBeIhAGAAAAAAAAAACAvEQgDAAAAAAAAAAAAHmJQBgAAAAAAAAAAADyEoEwAAAAAAAAAAAA5CUC\nYQAAAAAAAAAAAMhLBMIAAAAAAAAAAACQlwiEAQAAAAAAAAAAIC8RCAMAAAAAAAAAAEBeIhAGAAAA\nAAAAAACAvEQgDAAAAAAAAAAAAHmJQBgAAAAAAAAAAADyEoEwAAAAAAAAAAAA5CUCYQAAAAAAAAAA\nAMhLBMIAAAAAAAAAAACQlwiEAQAAAAAAAAAAIC8RCAMAAAAAAAAAAEBeIhAGAAAAAAAAAACAvEQg\nDAAAAAAAAAAAAHmJQBgAAAAAAAAAAADyEoEwAAAAAAAAAAAA5CUCYQAAAAAAAAAAAMhLBMIAAAAA\nAAAAAACQlwiEAQAAAAAAAAAAIC/VNEA5xWIrTWzFMhNbtcL+eYUxq1baF/UTs/9bZQAAAJC/Cgpq\n6P/sT6H9qWH/V8v+0f7UqOl+gFTRrgAAAKi+aFegMlGCkDbXQF2+xKxasdg2TlfQKAUAAKjGXF0w\npj+tLPq7WRL/N9eYtY3WGjXrmhq16hQ1aoFitCsAAADgoV2BykQgDKmJxczKZQtNbMW/JrZqpQEA\nAACScY3ZlcvMSv0snWcKahTahmsDGq/VGe0KAAAApIl2BcqLQBgSirmby3z3XwAAAKA8FPhQw9U1\nXgtrmxq1beO1Zh2D/Ee7AgAAABWFdgXSRSAMoWioAgAAoDK5+ubi2WaVRnPWXt3UqFXPIP/QrgAA\nAEBlol2BVBAIQwk0VAEAAJBJbjTnkrlm1bIFprBOEzeiE7mPdgUAAAAyiXYFEiEQhiLK1b9kjlm1\nYokBAAAAMk0N1xX/znIjOAtXW51c/7mKdgUAAACqEO0KhCEQBtdIXWWj5W7RQQAAAKAKrVr+r4mt\nXEpakxxEuwIAAADZgnYF/AiEVWcarbl0vr0pLDIAAABAtvDSmsRWrigexVlgkMVoVwAAACAL0a6A\nh0BYdaUpootnuZsBAAAAkI1WLV9oG62LTc16TUlpkq1oVwAAACDL0a5ADYPqZ9Vys+Lfv2msAgAA\nIOt5Of5jtg6LLEO7AgAAADmCdkX1RiCsmlFu1BX//kPefgAAAOSMokbrP64ui+xAuwIAAAC5hnZF\n9UVqxGpEF7hyogIAAAA5xwZcvLosi11XLdoVAAAAyFm0K6olZoRVEzRWAQAAkA9Up2UEZ9WhXQEA\nAIB8QLuieiEQVh2sWm5WLZ1vAAAAgHyw0tZtye1fBWhXAAAAII/Qrqg+CITlO+U9XTyb3P0AAADI\nH7Zuq9z+JrbSIENoVwAAACDf0K6oNgiE5bNYzDZWZ7lFAAEAAIC84hqts1ydF5WMdgUAAADyFe2K\naoFAWB4rmtpJYxUAAAD5SXXdlUsXGFQu2hUAAADIZ7Qr8h+BsDylhf5WLV9kAAAAgHy2avlCs2rF\nEoPKQbsCAAAA1QHtivxGICwf2Qj2qmVEsAEAAFA9rFwyl1QmlYF2BQAAAKoR2hX5i0BYHlppG6uk\nLgEAAEC1obz+S+YYVCzaFQAAAKhWaFfkLQJheSa2cplLXwIAAABUJ7EVS2xdeKlBxaBdAQAAgOqI\ndkV+IhCWZ1YSsQYAAEA1xQLXFYd2BQAAAKor2hX5h0BYHtGITVKXAAAAoLrSLCZGb5Yf7QoAAABU\nZ7Qr8k9Ng7zBQtZAuCUzvzcrl8wP/bf6LTobAACQPzR6s2a91QzKjnYFgGRWLp1vlsz4PvTfajVq\nbmrbH1SsqHZtjTqNTN21NzfVUSbLYWVsa/7E1828CW+YwjoNTYMWO5qGbbsbANmDdkV+IRCWJ1zu\nUkZtAqH+ePsys2jqJ6Veb9LhcAJhAADkGW/0ZkEhjdayoF0BIBUKCEx6vGfov23Sb6xBxfvtmd5m\n2bzfS73erMvAahsIy2Q5rMhtKag2ecRhZvHMH+Kvzfr8ftO0Yx+zXtchBkB2oF2RX0iNmCdWLlto\nAKRHI64AIJ8tnzfN/aixDVQn5PQvO9oVAMqjNrPBMo52bWmZLIdl2dac754qEQTzzBp3vw2I3WcA\nZA/aFfmDGWH5YNVKF6FGdtEMpNm2cuNXuFrDco3u0Qikv8c9UOK1umtvZpp26muQm8LKSXk1atfd\nNGzbzQCofhZNHWPmTXzDzJvwug2AlR4xXN92lDRq182lXaGTCvnM1Y1jMWMKCgzSQLsCOWD6O4NL\npYdbw2V6KHswYMbom82yedNKvNasywCelTkq7HxWBLXl1aYHykt19Sizvx9FHw+QRWhX5A8CYXlg\n1YolBtlHo+/nVHAgbNn8P0p/Zqc+BrlLDbQ5FRwIq91oAwJhQDWjANhfttMnLA1syfd94n6mv32Z\nS73SbOeBdOggb2lmU+FqqxukjnYFcoGeY4tnlJxJocGB5QmEaZ2e4GeSnix3LbT1omR1orJQcJR6\nEyrCKrI1ADmFdkV+IBCWB1YtJ31JNqpjG2NBCo7pp6yV52XzppZ6rXbDDQwAoPqa/vZgl0YlXfqd\n+RPfMBsePYoR7xmmusCqJfNcShwNiNB6H5rdoE5YBScbMZihQsRW/GsMDda00K5ALqiz9ualglbL\n5v9uyiM4e0jtNQIeACqLBq4G72OeRm27GwDZhXZFfiAQluuUvoTFrLNSYZ1Goa+vtB1fYY2q357p\n5TokRaMZ2xz9dMjvlh41VKsxnZcAUF1Ne6V/uWaVquNv8uM9CYZl2PwJr7tzF6T6Qd2QgTQoG9WR\nY7GVpqCg0CAFtCuQI8LaUmHtJNGAg4kP7h3/+4a2jRW2nlLw92ljAahMSn2odOZLAsEwBfo18xBA\ndqFdkR9qGOQ00pdkLzeKsE7pRlrYgqiyaNp/qRuUxmFlyFT5sAYeHZcAUD1pJliyIFitRhu4wRV1\nmm0e+R4Fw8KCMsg8nSee6xVr1XLqyqmiXYFcUbtx6YwYkW2sqWNK/F0pEIPC2l1k3QBQmdRf1O6k\nN80G+w11dXXNEFu362WmXa83DYDsRLsi9zEjLMetWrHYIHupM2vxkpKNslUhwSw13IJBLk2TD45W\nDFvwlw6z/BQ2IzBV6vgGkN8UAEuUDlEN6nW6DCyxXoo6+rQw94zRN5nl80qmkNIAjFmf38fC3BkS\n9jxH5Yiprly7vkFytCuQK2o3alHqtVURM8IWTim5TlRYKrLQNhYzwvKSZtqUp/0clfUFKKs1Ohzu\nfgBkP9oVuY9AWI6LrVphkL1C89eHNLSWhDTIlsz4vlQgLDhakdz1+as8i30DyG96jiiYFWW9PYfY\ngFafUq/reaGGtp4tkx4/rFQwbKENhhEIq1oMbql41JVTx7FCrghbizlqgMGSwEyxsHaX1mwMYkZY\nfmrQojPtLABAmVBXzn2kRsxhsVXL9X8G2at2yMycZfNKL+SszsegecXrhfmtCgTCEqW6AgDkJ83e\nCnuWSLMuA0ODYH4KtgRnnSoA1qrHgwZVKyylMsrJ1pWVzx+J0a5ALokaNBAMhunvweelBhYG214r\nly4o9Vl1m7U3AAAAcbQrch4zwnIZi1lnvbBG2sqQEYfB3PWyJIW0HenMBlOjb/6E1+NpGPVZ+n2l\n/dDsgPotOpdpdpk+N2wUpdQKfH99z4XFHbjavo6PgoXe9suy7TnfjTSLZ4yPHxt9hwYtlWO7OyPr\nQ1Tl+fJ/rsqhzpt3Pagc6rMr6ryFlXd9bt1mm5XYRtTxqFGnUanrIZ33hlkeMVK5Vhm+b/AYat/q\nurWFynYMU923sDJRVB52rLDrLey7eWVP31EzbZNtq7znyhN2XNL9jMoQNRusSYfDU15cW8dQ503n\nskXx2gTpqOhnSqavr0yW+bBthaXmSvR+TzaUv1wUW7HUFNSqZ5AA7QrkGNULwoJcfotCBhtKMPPG\nsnlTS72nRhoDE6LqLqp3ajt11i5bUC3qeRB8FvifycvmFv2Onsd1bZ2prHU0fScNzNTnecdV9bAG\nLYraWSgSdo68uoT/GHrno0kgBZ73Hq8upWPcqG23crW1vPKg+ou/rVWe8hC1jWBby6uvV1QZyWQ5\nrMxtJWqDhylLfS/VunRU+ShvuRPvGCol7cqlxZ/t7oXh5VrXz7yJr5foz9HAvFS/u//eK/72iCuL\nrsyX7zsBQbQrchuBsBy2auVyg+wWlkN82fySDbawkYqiCooe6np4x18L5L5PJXe9Pl/ryGg9mZUR\nufNnfX6/G4WuCl66edPVkJz0eM/Qf9uk31j3WdqHaa/0L9UYXWSK/j7DFFWQtO0mKeTH1rGZ/vZg\n953CzLeVr+lvX+Y+a72uQwz+UxXny6POe5XFqHIoOm9qoOm8+ct+qopSxt3sFkIPbkf7P+c7U6Js\nqBGg7xqk76aZNX5R79X+JlvTTfv10107lHpdx1HHPVWJjqF3vspyDH8M2TdJpUx412HYMUuVrmmt\nTxX53UzJ7XoBn0T3qrDvpIbRJqd9mlLjKuqcabaVUg9WFTX4omeDpRYE8zQpTpOYzj2/sp4pmb6+\nMlnmlYYy6pwF6djpJ0p5rrPqLEaQJynaFcg1rp01r3S7yl/3WRgRCAumAg57nqXy7NLzYLb9CQu4\nefVO0SCetWz9IZ16s0wNeQ6JPqf5fkPdn2eNu8/VfRPVr1OpN3mK2lGXhj63itYTvd99zrq2nllz\ntdVNdRf2jFe9RWuyhq3lqrLnnTu1Z4Pv8Y5xWZ/3FV0egjSQZ/o7gyPLvEef3aRDT3edlWUATybL\nYSa2lajvIozKSLr3C7WldO6DUr1feN9zw6NHpV021D5RvTnsGCoVu3ccFRBreegDLgD2l92PsHIU\nvI8HJWs3BnmD/8q7PiDgoV2R2wiE5bJVNFizXVj++uVzS44aWzJzfOTvL5oyJl4JCF3EOUnu+lQq\nwh69Z05xQy7dAEciqixPfuKwpPvgdTrqv4kq/fq8Kc/2SqlTUd9H7yfVVOoq+nx5752cRkewyuDE\nB/dOuwGo862GWSrl3SvrTTv1NrkgU8cw/LPGmN+e7Z30uOpeM2/CG6bNMU+n1eBN1HCKovOnn6Yd\n+4QGu7V9NXgWlUp9ZO9z345MaR2s4KhyT1WvGaJjHKYsI3zTXZg7G54pmVDZZR6ZRwqTFNCuQI4J\nW4u5dDsrfPZtsH4QrIMkW4c5arBEFO2H3r+w+JlYUZ2x+sxUOte953GyDu6wwEwYff8pz/Ry9TCU\n9tfomyLLhs6Ft3xComOtOoZmsjRIY8Z+uuWhZY8H0hp4qAF5YYGWMN7gxDnfjUo7sJLJclhdynyy\ngcQeb3BZOoG4dMqF7tk/RQxG8ygzUlS5TLdN7P3Osu+mue/OgDJUBNoVuY01wnJYjDz+WS80NWKg\nc3XhlDFRv24W+4JkYZ2yiXLXq0KimSGpdFj6eQ27qNRb6X3W7y5olc4+uE7WiA5oV/F5Ir2Kjxqe\nqTZSq7uKPl+iyu7E4Xundc78n60KeypUsVW5TWffvQZatsvUMQyj6yeVgID//TM+Sv3eofuMZiiW\n5buJGq4TbMAvrAxGNXLC1l8Mszxin6p6zZDFEZ16lR1oyoZnSiZUdplHFWFh66RoVyDXhK3F7K8P\nuOwaEWlo9W/+QYbB1PWJ1mH2OmLL0r5QfXWyq/dMM+Wl52o6M0y8Gd1RUg0I+KX7/uoiWdnQzJhU\n2iDp1J3+KkN5mDzisMh6ZVBRXS79dpO2o8F5qZb5TJbD6lTm052Rpvencs7SCYKlKmq7ZQmCBWlf\nNYszUf8FkBTtipxGICyXEYXOCWGNNP/DfdG06IqyvxIdnu85fKRiRVRI9Puacl6+z7gp7YqKOnPD\nRmCqsqKKT7qdsEhdRZ4vcSPn0gysBamxkawceh3tZZHt5SlTxzBKusFFb3sLU+gcqqiGkwtcPNOr\n1OsaQRs2G1T31VT2L2yQgjfTrCpFjW6v2yz9VKKpypZnSiZUZplHFaLOnBzHCDkmbMChvx6bLBjh\n//dgp2iium15O2KLPqNnuTpiyzqYK2o2i2Z8E9SqePXd2lLdSr3uP/c1XCrpbpF11lTLSbC863Nr\nNUqcxUCfPeWZ3km3kW7QNWw7qZT5TJbD6lTmtWRAuudP5ypZ+1pLLkTdh1T+NKCgTpL2id7npW7U\n2mBKKxq1ple6GUSiLPKtjQaUCXXmnEZqxBwWi8UMsp/SdgQf2JppoMZbcKSiKgKrfB1wReuHTSte\nr6T0Qz9syniyhpEqGo3adXcNPG1f+cujKkb6nIb2vWVN3+GvkOu7KQ2Xt88rls4z8ye8UarSHrXG\njTpQoyo+amSs02Wgq2jpe2k6/d/Fa9jkqnQDO+r0L++MkIo8XxJVWdUC0kpJ2Lhtd7d4r4K8mv04\n+9uRLkd7kMphky2OiOyUUIdEFK9seMGLZW5B3jfMn+WYJZVJmTqGUbyAgMrDWh372jLR021bx1Gp\nTqJGquraS5TKRfuY6D7lOg7adTP1fIvL/zvz+9AyKDpGup8Fv586fMK2o9R3yVLNhI2Q1f2wKum4\nRwVpyrKmXqrbzJZnSiZURplXPaBW4DsvKV5cPkidVomOTy3WNigT6szJcYyQa8I6WP2DDYMDWoLt\nLA1g8OrOywMzEKIGl+g5FtUe8epmXt1F9RbN/AmbYe6erR/dVOa1jIN1Ia/eVHO1ovWpF7pBP2NK\nbFvfNTx4OC1ybcrgs9B7zutZuLwCOqTzmTITeO0kDdgKq5/rmLYpThuowIxm3gclWy8pSOdMa9l6\ndTPROnZR56zo/N8XmUlBdeaoeqDK1BquXG3g2iNKTap21uzvRpbaVrIyn8lyWBVl3lunKiiqPliR\n/J8f7DfRvWTqK2eHfjf9m9cXFeaPdy4LfV0p6FX2vfL3X5rM0u2DtWxbLZVUhYsjsvx456uRDSbX\natw83h5Rf1DUPVjbY60wlAd15txGICyXkcIkJ7iFnANUGahvdnSjaPzW2WmAmfFxyfVX9MCv3UGV\nsJKjVqIe3lFBAVUSWh/6YKkKmEagqbM4bF0obySQRuaUR7Ay5FGlRRXzP4vXdYpqoElUx6p/8VeP\nKnZ6TZ+VK+m4gsoSxKuo1GgVdb7CKqvqEA6up6M/q6GhsqhKcvCceQvihlWS1TiL6pDwN0A92l9V\nuNWgTBRAywaZOobJ+BvpHv1Zx1blQA33oPm2wWgC16VH9z8tSB1FjfemnUqPWNa9K1gG/fsXFuRT\nWQ5rvBctQh59LHS8wo69Opmq0vKIVCF1KnE2WDY+UypbRZd5jXANmhSRVkudE7m0nlrOoM6cHMcI\nOSbsue/v8PQPaNF7dQ/3BxoSzQgLq99665OG0X1bHfz+ffLqLVHrNmk2igaHpLMGVJCeVy3ssyf4\nLNb+FNW3BscDMFGD14o6u0vXpfWcb3PU0yWCgvp+Cnxon/Ucy8Vg2KQy1P/TWS9JahXXGTwKSoUF\nwvzrxTVs2z00ELYqjSCJzlm7k94sVX69c6ZU62FBl0T14qjBmWHHpLB4BlATG0QKKx8q8812Hhh6\n7WayHFZFmXdrU5nS1+CkMqZZLds+lG4b696henlU2VD9NmxtZd1fwvY7qv2t8hL2Oxpklkr7VG3+\nMC32G1Zq1qWXwcO7B/vbxmpHJxrIC6SEOnNOIzUiUMnqNtus1GveVOxgKiWtPVMnMOLLa8QFKyZh\nqQ5UwY4KCoR1WP633c1Ny0MfDP23VNOIRVHFZr09L4uciaKK5bp7Dil+b3ilRI3HqFkxiSoy+req\nTmOWayrifMnsiI6CVj0eSDgrSZ8ZVrbVQAtLpzHbVp7DJKvkVsQMusqWqWOYTJsEC1w32zn8GLvZ\nrhEp/KKuZ1EjKSwI5qcy6N2vwgIWflGpDLV/ie5rLqgR8lmN2lbtjLAo6c70S1U2PlMyoaLLfJio\noGZUymMAQEm6TwfTyfnTXfk7XF2KrrVLrvHpZlkX14uC7aywZ0BUGjU9C1V/iXoWNw8JVHnKM2DP\nqwNFfba+gwZiqE6YaPBa1D6oAzlqZlxRx/Ywg3DB4GbYwFhZw9cWqYgZKjpnUZ+j19eOCDhE1Yuj\nBhyqPCVqRxUNHgrfVlSa7EyWw+pY5nW+otrG+m5N2oefz6g6+xLfWvYeb8BBlLDZgF4GpGSiZs2F\npR4N0j41tee2lrsnPmAAVG8EwoBKVrhayIyw+UUVyoUhaS0aBWYceO8JVkLDGltKixZGFZ9kAaEG\nxaNmwpS1kZYsUOXRKDnNAomquM8L6ZQWpSxI1mhoVMUzOHJJRZ2vqBFiiRrhfmuENKyiFjxXzvMw\nUZ3Vwf3JVpk8hokk257uQ7Uj1h9YMiM6EBZGow1TPSe6Xylg0OrQB5Iej6iGeKL72sLQ2WBVHwRb\nuXSByaRse6ZkQmWU+XTUXK2RAQCkJtgeUl2naFZ3ydkDeiaFrR260HX0l+6EDQ5K0ECHqDpU84jZ\nwH7RaefKPjjEP5so2baj6vf6XmGBDh3XZAOTotZiRek1wgtXW73UeypjsKZmYiWirBhR5yxsxk3U\ngMNU24th2wor75ksh9W1zCc7Z1EBwLCAl4StsZUsQ4UysoQdv1QGakYd91TbFLo2FIgjJSIAAmFA\nJQurEHgjWpb4Ro97leHgaEV1rLlGXaCyEVZZCUu5IMkqdZ6oRpq3D+laI0ll3JOs4rkkYpR9Kh3T\nDbN0Bkc2qqjzFRWcWiPFIIdmRoYJphJVgy1sdFiqM3eyuTGTqWOYTCrbq5PGugWJUlk27djbpGPT\nfp9GNtr8os5zogXIw47/GlkQOM30ws7Z9kzJhIou81Gy9fsDQC4Jux+vdOumlmw7NGjROfT9UXWB\n4JpM8yMG5Wk2Qiodq4kGh0Sl/ErE1XVTHKCzRoIBHlEDOLSvqcw2p50Vrio623XOUtlu1MyfVAcc\nprqdooFDpd8XVuYyWQ6rY5lP5ZxVRJr1VOq2ZV0PLdhH5lHaQ6XvTHYfVZuxUVsGSANgjbDcVlCD\n3KQ5IKzSUbTYZ8lOfK9DN6xjV6MVk+Wuj3r4q0KX6gK7Xodx2Lou6S7UW/R5nU15FW07vOM8lf3x\n0qZU9iK0FS2V0aV+tSqgwVUR50sWTgkf2TrPNqYWptDYjzrfiwMj0qLel05FXuVj8ZLyz+KoaJk6\nhsnUipj54heV7iVshPW8CeGBlVQb1SW2m0Y6QK1ZFb5WWOl10zRjrXQq2uZZkWY16lhXhmx8pmRC\nRZf5KFHPpFS2jzIoYOxfUrQrkIOi2lnB+oZXN9Rzxz/jXrNTgp2jYZ8ZNWsrnfW9lKUibLZ/urP1\nRd+nItIiR227bop1aS0BMOc7gyyQ+jlLbeaPrqOwuopeS3UWTtgALq8O6L/OMlkOq2OZTzVwGSaq\nbhtWF14+tyjdbNRnRbUt0hlMEHYP9dZvrF3cXtO9tr7t16is1PEA7YrcRiAshxUUFJhYzCDL6QEc\n7AjUorfBkYpeJ6vrZLQVMX8lTQ/84HoiwQpDRQQFvM8NCwxo9FS6nZYVMrIoYgZEOp3mOqa5Fgir\nirR9FXG+JGo0mNaoKtfnBspCVMU8nbKhkcFl6YCobJk6hpkWtYZSg0oOMintYnggrPTi4GGpWLMl\nxWpYah2pjMXqs/GZApSV6sxIjHYFclHtxqUHD6id5c8m4Q8aNWjZucRaX3oWBesmYQMSotZ1jJqB\nH7qvjVqEvr4kzUFKRdut3Dp7qnXpwhxM59vm6Kfzcg3p2g1TG0gTVY8LthFWRbQZdG0tmVm+tlOw\n3GWyHFbHMl8Z6ocMdtOxnfHRTaFrgenfNHMrKJ2gvgYKT3r8sMh2j1tv7Ltp8TT82sc1itO5kxIR\nFYl2RW4jjJnLCgoNckPpoNW0UjM+/LNx6jcvWTlfHJJGKthIq4iggESlfEpnpLunIkbhRDU8GTVf\n8Spq1NTyMpSVVJRqNOVYcDMdmTqGmba8gu5T6VLZDuv0CC4OrvtcWDpAzSjLBjUiZiJVRoAzG58p\n1UEmZ/1VK9SZk+MYIQeFBZc0oMVfR/QPtgmrCwTbZGHPuajBIem0R+qsvVno61XVxkq0bTqNc0+q\n9YeoshNsIyyrhEFWnlVLgtvKXDmkzFcM17ZqXvp+qoEGCnj5j7Nmgk0ecVhomUqnjaVzpEB2qvdd\nDSbXvvx01w6l9gkoF+rMOY1AWA4rqMGEvlwR1hG4aNp/ja7gSJjgKD+3nsqSxKkREa0WxyovRQV1\nWLgbYaLWq/JGDUpYug3dn7Plfhu1H24dSdacyhmJGuKkcakkNFiTol2BXBQWXPK3scQf/Cpat6hk\nJ2rw2V+bwXYp41hlj+rcN5DJckiZ/49mfoW1u9W2UvDph2Gbup9Jj/cMzQqiPpp012BWOW/X6y0b\nQOub1u9pnybb/fC3+4Ayo12R0wiE5TIuvpwR1rFVYn2wQKAsOFox2MEZltKgojr/qzp1WlDUDIh0\nUoEtZ/RPXgg28CJHNObxTLHyqs6NZG+9qqD5GjlefI+dHdI4ypbZYOKl2g2TytpxaW0rT58pqJ4I\n8qSAdgVyUNgsmGA9sHQ7q+SauJlqZ2XjgJV01wUKWrl0gUF2KO9sl0wOxAnO6MlkOSzvtipzplyu\nUbty3T2HRP677sXRa+JqdtcoUxY6h+t1vcxs0m+s2WC/oSmnbdc51swwrRENlAftitzG2cthBTVo\nsOaKsPz1fsHAlyoVGm0UVdEKq8BF5atenGYO76hGWkWtH5Wu6GBH+TtXazBzqFK4TomQsruprayW\nRzAoWhGdEplKkZBu50emjmGmRX2vTAVLFNQKrhWmczPn25GmYbvuoTPCGmTZOhKaYRy2n3qtUdvu\npqLk0jOF2XBIpkZhLYPEaFcgF4WtxexXy7WpSg4C0nM90ayAmiHPv6j1hvVMTHWQUdSaS1XVxpLC\ncqZcjnofbazsFTVAtLBUOyu8bDTt1MesVc5BYsFsLZksh4WVlGa8upb5Rrb9NHP0TWkFCL0gWHkH\naNZ2M8qKZpW5pUdsW0gDHMPS3PupLdhkiyPIwoAyo12R2wiE5bCCwtUMckPU4siesAWPNVpxWUQj\nLez9UY2o5XPT6+gP62CVmlW0MGyiVGCq8KRSgYqqmNVksdtKoY56rWsXFDMVOyMp6rPS6ahfVQEd\n6KnMTlyVZuMqU8cw06K+1zzbYGnaKb0UF2WhbSh3fbAzS9s3IWveNmzbLeuOtzrwwu7Tc759yqV/\nrKhGXbY8Uyrj+kI1VECTJxnaFchVek4vXhJe96sbkjqxfpIBLmHPP9VfwtoT6TwTF0Y8D6uyMzYq\nzdvimeNNKqIGlNHBnHnlnT0VnKUVtaad6tAVvexAJsshZb7iqD9m4oN7lbg3KiC4KmJggv5trY59\nXTC1oo9XWFBshg3QhbUjtN+aFRaVNh9IinZFTiM1Yg5zIzcLOIW5IKoiKapI1g1ZQ6xus+jfqd2w\ndAVOD/+wGTJ60Ec1vIKiRke6xVCrcFZEVIVVI36SWVTB6cKQXFTZTeV8pSOqo96tqZdCgEvvCQvK\nRClPTvh0Z9Fk6hhmWtT3UrAkE7N6ohZ2XuQaSzeXel2zxLJNMKWTx2vUpSPRMc/0MyWT11dVSxRc\nZSHvSmDrygWFNFiToV2BXBW2FrMn7Dke9XwTN8MspIO2bkSdc16SmQd+Uc/ERm27maoS9TxKtb6Z\nan0AlS/VNs28iHMbLONR10lltEUyWQ4p8xVn+tuDSwTBNICw/dk/mjZHP23W7XqZDTQNcD/6s17T\nv+nvZQ2CaaZXKnX+2sVrj23a71O77fDUjZxHlBntipxHayfHkZs0NyTq9KobESSL6uyUWo1Lf54q\nFFENQY2GScXf4+4Pfb2qO4MbRqT7SqXxOW9C6g1UVIw6a7cPfX3WuAdMRVIAOaojQ6nukkm3IRc1\n+lEd18mCOAunpFfZztQxzLQmHY6I/Dc1ptKxZOb3piyiZp4FZ4npnpruAs6ZoBlhUQMTZn1+fxpr\nHEwzk0YcFnkfzfQzJZPXVzaIunflWlAvF1BXTh3HCrko0UCKqABW2KAYCWtjufdHtMs0kCaVDtX5\nE1+PzFBRle2sqG2nMuhF71lEZ3LWSHVQWdQg0bC6ZVg90KUUT5BatCwyWQ4p8xVD9dVgOWi2c9EM\nK5UlzfzSjCv96M8VMah6+tuXpt1eVBrPsG2ns9484EddOfcRCMtxNWrWNcgNUY20qPVnEnXyR6WU\niprerQpbsgrrrHH3uZk0Yaq6MziqwqrvlWgGhDpQ1fBEZkV11Ot8pFN51cjGZJ36TdqHl00FjJI1\nBlPtzPckGkGcKPBWVA7TC8hm8hhmkoIrTSLuJ7pHpdqw1vsmPNgt7XMoOraprMeRjbPBPFHHUGX+\nt2d6Jy37+vfJjx9mg4k/mCnP9Io8jpl8pmTy+soGUUHGZB0suqYJlqWngLpyymhXIBdFDThUnaNu\nxL22QcsdI38n9P0JBqGoXpbouat/i6q76TOrMgVzoqwfv7/SP+H3SncWOipXKpkBVHcLC8iqHISt\nMxtVDyyaCZR6+yJZezyT5ZAyXzHCAqrpDMhLl1d2FxWnPCyvWuXIRIHqjXZF7iMQluMKatYxyA1R\nC7PWbxk98yuqoyyqEzdZIy2q41KvT3/7stB/q5/gMzNF3yuqsjL9nctCK6Veo3MZo32qRFRHvdZn\nStZhUPS++8zkJw6znfU9E1aoo4IV+p3fbAd/1HZmpLmoryfqmlTgLWw/9ZoCDmWRqWOYaS4lRkTA\nY5ptgCZq3HjXtd4nSmdYllGpqaQhysbZYB7tW9Q9UcGtiQ/uHXnO1XCdPOKwEuVfx/Gnu3Yo9TuZ\nfqZk8vqqalGds1rrLey7quzr2pg4fO8KH4md72rUoq6cKtoVyEWRbawE7Zeomfd1EwyUiQoK6Lk7\n7eWzI+/dwWeu3zpZsEZNVH3Tmzke9r1UlwhLKY2qlSgQoYE0098JD8hGtaei2uBFA6p6Jp1B5cqQ\nradpkFay4EUmyyFlvvxWhqwDpvqp2hMTbDvkt+KBdvpRm9Qb8KgfBUbTzezhLz9euyWV+rDeEzbI\nLJfX3EbVol2R+5jTl+OUz18/sVUrDbKbOviCubsTjVQU/VvwwR2Vu96jRlpYx6AqrOo8Vl5wjYIs\nXK2RfW2eSx2YaAR68/2Gmmyg7/V7ced3kIJhqoj7v1dRQ4AgWFVRR31UxVOBHM3gaNiumwtIKCii\n86ZZDrpGdC6931MlWw2tDY8eFVph9Trqw7aj1xQQUOBFa1NpG2rY/GUrz2VNa9HI7nPY7xZ1yPc0\nTTv1dtetl15Dx2DlkrKtfZWpY5hp2oe17fX8Z8To6KLg1ij33bz7o67pxTPGu4ZT8HgqIKPBAYnu\npUFKj6hjGHVulKavqgcAJNN8v2GRQSCVRzUQlatfnXoqH7ofqmxElf2ojpNMPlMyeX1VNXU6zQpJ\nHel1Lqn86f4WVvbn22O83p5DDJJz9eSCQoPU0K5ALopai7lBgud4VMArbB1m/+dF1TlVJ1syc3yJ\nuouXOizqOaXO+Gyoa6i+qU7msFRhCvLpmeT/XgtTmBWezSaVcwDNFhf8YbKVV4cItn0WRqyF69H7\no0TVN73BSKprNrJ1GmW/UR3fq7dom/66i7f9qIByJsthVZT5qHK3JGKWv+qIs0O2qbW2skFRutjw\nMqXvpJ9kGRvUPtESGCp/idqoYQNYVf6KBlDe7M6V7s/+PjK9f3ZEO1qyecAjshftivxAICwP1KhZ\nz6xctsAgu4WlRkyWniusoywqd71HlQAtChrVyawKSapppNTRli2jZRIFBSSd74XMUIe3Kv1hjQxV\nXhWs1E8yXkU3quKv7WiWRFhHg/e7FUVrXKnCHbWtqFkwUsNW9lel2WmfqWOYacrXrrR5UY1K77ul\nwpslls53c2lRmu8Yec9QQCbbJbvXSzr3RXVMRAWbM/VMyfT1VZW8UdZR1/ay76YlvD70w2jW5Apq\nNTBID+0K5Jqoe2HdZu0jf8dLjxZsVyRrZ7Xq8aCZ8OBeCetlqdCAm/W6Zs+AhmSDa1L9Xqh66bZ9\noup/HtVX9J6oGV3p1ANVx1MAJSpInclymOkyn+4gzMUzsjsNtpdqfkk59lP1fTdDbMLr7n4YNVMv\nUflKpz3sUfA22wc8IjvRrsgPpEbMAzVq1zfIflEdjImEjVZMNFLRo07mZuVMtaHfb9qpj8kmanyW\nJZ9zVEUnm9LF5SOVeQUnypuDW50FiWaRaDsbHvV0ZLq9RGqk+TvqONnANpzSpe8Qlnt/5ZJ5CX8v\nU8ewKmh/mnbsa8pLs23L8t00Kyzy3zpm170vSkXc66VoMesBlbqdVJ4pmb6+qtp6XS83ZbVwatlm\ntVY3pC9JH+0K5KKwAYfJOjrDZpInG2Cg51R562W1XN1uVMIMH5nmDXpJV9QxXk5WjoxSx35ZyqQC\nD4nqfx69p6Lqm4n6PzJZDinz5dfq0AcqJKDkZZmIWgO3pd1ORa3plW2DEJBbaFfkBwJh+aCghiko\nrG2Q3cJmfzVo0Tnh77jUiYHfq904tRHgqrBuYDuH06001CrueE+lUpxpXuMz2Uw6v0Sj3LK9kzQf\neIGcJmVMP6DKdZsUUvrpOlEwLJ3yrn0K6zxPRqkI02kMJurwUMU/2VpfmTqGVWG9rpeV6T7lUTCr\nzTFPl+m7eSMZg/RaLs200b16wzJ2yikQrFlaqXaCZOKZkunrqyql+13FO2ekdElOdWPSl5QB7Qrk\noOAak6l0zjYIWac5led/eeplqre06/VmVtYzNOglncCAnr9RzzDaWJnVZIvD0w7QqiymM5CsrPVA\nSae+mclySJkvn6K1vipu5tr0iOwTul9u2u/Tcgdjs7lNjOxHuyJ/kBoxTxSutrpZ8e8/BtkrrJMu\nlYCO0nf5p8anMiPMo44ydfZqvZ3Z341MOFJJFdS1OvZ1I/azaYRikCou7U560+V8jsrtLd5oH3U0\nRuX1njfxjYSzQlAxahfPRlJ5nF28SG4yqqhqAfF0RpkpGKZGoNJuzLMV86g0aSrr6+xUNDulrGkT\n1ZDTvk175ezIMhi8pqLWBNL1nWx2aKaOYVVI5z4lOq5rFAcxy/vddD8NpvTIldlgfjp+aiAmuy96\nvGOo75pOYzBTz5RMX19VSd9VnUrJzpves0aHI7L+GZ1NCmuTvqSsaFcg1xTWaVTi73VTaWMFng3J\n1mH289fL/rL372Rpz3KlTqbAgNpOReu1Rtc1FQRUOysqxaS3lmc2P3/zhX9WvNcOSnTuFDRe3567\nspRFrx5YtOZYavXNstQFM1kOKfNlo/PvX3dO57r1oQ+647NsvtYl/r5oQJqvPe5l49HMr7B2uo6p\nfieqrKjO3KRDz3jfTqrpJnW+dP4YRIbyoF2RPwpqNts7ZirQ8r9Yo6eqrPh3lomtXGaAKOrwXTBt\nTImKhxpySg2SziyrbKIK0L8zv3cVcVW06jTbzNRbuz15n7OYKrgqi/7zprSG6uhdrVELd+4qoqNX\nZWPh1DHxSrjS5mgWpsq69/kKhIU1etJJAeJdV0tmjHd/13fRNaWO+crqsM7UMawKwWtavO9Wkde2\nGmM/3bVDqdc36Tc250cKqmx4jVBvcWmVfzVSK/IYZuKZUhXXV1Xxyn7weBatJ8bo1XRoMeua9ZsZ\nlB3tCiB1qpfpHq7nrkfP3Fyuk6metGTm+HhdIp+fv/lG507BAs3W8erSldFGjqpvVmRdMJPlkDKf\nGrWdg4NJ020//T3u/tD1h9v2ejM0bW0Yrz3srZ3rtfl13nS+qEOjotCuqFq11qnY9dsJhOWR2Mql\njN4EgDRURCAMuSmsEac1FrQWIYDcVlinsalRq55B2dGuAAAAQZMeP6zEbKyilINPm3RNHL53icxH\nos9hQDOyDe2KqlXRgTDWCMsjBYWrkdMfAIBiSn8aRqMGldIjSCM+AeQ2jdqksVp+tCsAAEBQWFrI\nsghbV00zaYFsQrsi/xAIyzPK6Q8AQHWnGV+/v3x2PB+936zP74+ncPEobQa544Hcp1GbqBi0KwAA\ngF9hIFil9IRhAwwTmf724NC2WKppEYFMoV2Rf2oa5BU3erNmHRNbscQAAFBdqUGmEYqTH+/pUl1q\nzQL9/W8bBAtbXFnvAZDbNGJTdWFUDNoVAADAr44NVgXbUjNG32zmfDfKNGzXza3L5a3R5bd45g8u\nFeKscffH167zY0Aisg3tivxEICwP1bQR6+WLZhoTW2UAAKhuNBvMG2WoGWHBtcCCmA0G5D6XuoQZ\nTBWOdgUAAPA0sW2msEGFanMp64Z+0qW2WNNOfQyQLWhX5C9SI+ajghqu0QoAQHWUTnoO5aJvc/Qo\nAyC31ai9uikoKDSoYLQrAABAMQ0ebNZloKkoCoKpLaZZZEC2oF2RvwiE5SmlMSmsXd8AAFCdKP1h\n/RadU3qvC4Id9XSp1B0AckuN2g1YyLoS0a4AAAAepZSviGBY/RY7uiAYbTFkE9oV+Y3UiHlMEexV\nK5aY2KqVBgCA6kCjCZvvN9Q1rDQzbHlgIWZPEzeacQANLyDHudQltUldUtloVwAAAI/aUU069HTr\ngy2cOiayzRWkgYh1197crGMDaWqvAdmEdkX+K6jZbO+YqUDL/3rDIHuosbri37/J6w8AqJaWzPjB\nLJg2xqwqXpRZga+G7bqTfgPIA2qsFtZrSuqSDKFdAQAAwqjNtWz+72bxjO/jazV7Cm3wq1ajDUy9\ntdubOs02px2GrES7IjvVWqebqUgEwqqB2KrlttH6D41WAAAA5IWCghq2sbqmbbTWMsgc2hUAAADI\nJ7QrsldFB8JYI6wa0IXMiAsAAADkixq2bktjNfNoVwAAACCf0K6oPgiEVRNa6K+wTmMDAAAA5DLV\naVnEuurQrgAAAEA+oF1RvdQ0qDa8C3vl0vmkMwEAAEBOUdoSjdiksVr1aFcAAAAgV9GuqJ4IhFUz\nusALCmuZlYtnuwWvAQAAgGxH7v7sQ7sCAAAAuYZ2RfVFasRqyOX2r9vU/rfQAAAAANlMddbC+mvR\nWM1CtCsAAACQK2hXVG8EwqopXfg1661lCmvXNwAAAEA2qlG7gSmst7YpKCDQkq1oVwAAACDb0a4A\nqRGrM5cPtZHymphVyxaQ0gQAAABZweXt1+LVNesY5ADaFQAAAMhCtCvgIRCG4vz+q7lG66rl/xoA\nAACgqqiRWqNOE9toLTDILbQrAAAAkC1oV8CPQBgclyNV0fFadc3KJXMZxQkAAICMKiisbQpXW90F\nUpC7aFcAAACgKtGuQBgCYShBN4ia9Zu5EZykNQEAAEBlo6Gan2hXAAAAIJNoVyARAmEIpbQm+omt\nWGJWLltoYiuXGQAAAKCi0FCtHmhXAAAAoDLRrkAqCIQhoYKadUxN+6MRnGq8rlq+kNGcAAAAKBOl\nzXPrSNVqQK7+aoZ2BQAAACoK7Qqki0AYUqKbS0Ht+qaG/Yk3XlcsNvb/TCy2ygAAAABBBQU1tEq1\n/V9d20hdzf6d5kd1R7sCAAAA6aJdgfKixCBt/sarxFYttw3XlfZ/y4v+rAZsbKX9idGYBQAAyHOu\nUapRmAWFtnFa6Bqlrr5YszYNVCREuwIAAAAe2hWoTJQglFtBjVpK/m8Ka9YxAAAAAFAWtCsAAAAA\nVIYaBgAAAAAAAAAAAMhDBMIAAAAAAAAAAACQlwiEAQAAAAAAAAAAIC8RCAMAAAAAAAAAAEBeIhAG\nAAAAAAAAAACAvEQgDAAAAAAAAAAAAHmJQBgAAAAAAAAAAADyEoEwAAAAAAAAAAAA5CUCYQAAAAAA\nAAAAAMhLBMIAAAAAAAAAAACQlwiEAQAAAAAAAAAAIC8RCAMAAAAAAAAAAEBeIhAGAAAAAAAAAACA\nvEQgDAAAAAAAAAAAAHmJQBgAAAAAAAAAAADyEoEwAAAAAAAAAAAA5CUCYQAAAAAAAAAAAMhLBMIA\nAAAAAAAAAACQlwiEAQAAAAAAAAAAIC8RCAMAAAAAAAAAAEBeIhAGAAAAAAAAAACAvEQgDAAAAAAA\nAAAAAHmJQBgAAAAAAAAAAADyEoEwAAAAAAAAAAAA5CUCYQAAAAAAAAAAAMhLBMIAAAAAAAAAAACQ\nlwiEAQAAAAAAAAAAIC8RCAMAAAAAAAAAAEBeIhAGAAAAAAAAAACAvEQgDAAAAAAAAAAAAHmJQBgA\nAAAAAAAAAADyEoEwAAAAAAAAAAAA5CUCYQAAAAAAAAAAAMhLBMIAAAAAAAAAAACQlwiEAQAAAAAA\nAAAAIC8RCAMAAAAAAAAAAEBeIhAGAAAAAAAAAACAvEQgDAAAAAAAAAAAAHmJQBgAAAAAAAAAAADy\nEoEwAAAAAAAAAAAA5CUCYQAAAAAAAAAAAMhLBMIAAAAAAAAAAACQlwiEAQAAAAAAAAnEYjH3AwAA\nck9NAwAAAAAAAKAEf+DL+7P+W1BQEH/d/2cAAJCdmBEGAAAAAAAA+CjgtWrVKvPQQw+ZyZMnm5Ur\nV7ofvaYfb4YYs8QAAMh+zAhLgFE9AAAAACobnagAkB38ga3333/f9OrVy0yZMsU0btzYHHvsseaM\nM84wLVu2NDVq1HA/zAwDACA3EAhLgkYpAAAAgMpCxykAVD1/38+vv/5qevfu7QJgmg02ZMgQc8IJ\nJ5gPPvjA7L333uaiiy4yxx9/vPsdLxgW/AEAANmF1IgAAAAAAAColrxZYHPmzDGXXXaZ2XPPPc1u\nu+3mAmL6r7Rq1coMHz7cBcOefPJJs+mmm5r33nsvnirRv34Y6RIBAMg+BMIAAAAAAABQ7fjXAWvT\npo2ZN2+e+frrr11ALIwCYgqA6d/79etn+vbt6wJmCoitWLEivn6Y99kAACA7EAgDAAAAAABAteAF\nv/SjoJZmgD366KPmueeeM8OGDXPrgSVz4oknugCYgmebbLKJueKKK+KfqR8FxpgdBgBA9iAQBgAA\nAAAAgLzmD0wpDWKvXr3cWmAKaikg5qVBTIdmhikg9scff7iA2MMPPxyfGealTQxuGwAAZB6BMAAA\nAAAAAOQtLwA1e/ZsM2TIELPtttu6NIdfffWVC4SVh7d+2PPPP2+uvvpqs8MOO5jJkyfH0yV6gTH/\nOmIAACCzahoAAAAAAAAgz/iDT++//76bBda6dWv3ZwWwKtJWW23lZodpvbF99tnHdOnSxVx88cXx\n7RQUFLifGjVqxPdLfwcAAJWPGWEAAAAAAADIG/40hJqdtccee5iBAwe6IJXSIFZ0EMzPS7Wo9cO6\ndevm1g/z0iT61w/z9hMAAFQ+AmEAAAAAAADIecF1wM4++2zTsWNHc/DBB7s0iGVZB6wsFGjT+mGa\neeZfP0xBMO/H209vHTEAAFB5CIQBAAAAAAAgp/mDYLfccoubkaXUg0pXqIBYVfDWDxs2bJhbP6xn\nz57mt99+i88M8wJi3hpizBADAKByEAgDAAAAAABAzvICSJqBpTSIL774oktPqABU48aNTVXTjDQF\n5Hr06GG6d+9u+vbt61I2egExL22iP5gHAAAqDoEwAAAAAAAA5BwvaKQg0yGHHGJ69+7tZn8pCLbV\nVluZbOOtH1ZYWOjWD1O6RC8I5v8RAmIAAFQcAmEAAAAAAADIGV46wdmzZ7u1uDQLTIEvrQOm2VfZ\nzEuXqNlrTzzxhFs/TH/2B8L8M8MIhgEAUH41DQAAAAAAAJADvBlTzz//vBkwYIDZeuutXSBJAaZc\nov3V7LCHHnrInHLKKaZLly7m4osvNi1btnT/rvXNvB8vGKY/AwCA9DEjDAAAAAAAAFnLmxmlIJi3\nDthtt93mgkjPPfdczgXB/JQuUakd27RpY3bYYQdz1VVXmX/++Sc+O8xbQ4wZYgAAlB2BMAAAAAAA\nAGQdf/BHaRD79+9vevTo4dIfajbVbrvtZvKFUjwqtePvv//uAmJaP8wLgvkDYUIwDACA9BAIAwAA\nAAAAQNbwB3r051tuucVstNFGpkmTJm721Nlnn23ykX/9sKuvvtqtH6bvq4CY9+MFxbwUkQAAIDnW\nCAMAAAAAAEBW8dIg9urVy7Ru3drNlsrlFIjp0PdUAEypH7t37x5fP0yvKwhWWFjo1gvTMfLWDWP9\nMAAAojEjDAAAAAAAAFXGnwJRwZ3Jkye7dcB69+7tgkFKg1hdgmB+Wj9MAUCtH7b99tubK6+8ssS6\nYd7sMAAAkBiBMAAAAAAAAFS5OXPmmCFDhpiuXbu69b80Kyqf1gEri8aNG7v1w77++mu3fpjSJWr9\nsBUrVsSDYWHriAEAgP8QCAMAAAAAAEBGBWeBaeaXZj5NnTrVzYJS8Af/8dYPGzZsmFs/7PDDDy+x\nflgwGEZADACA/xAIAwAAAAAAQMZ4QRr9V2kP99xzT/PII4+Y5557zgV7NAsK4Q4++GAXADv00EPd\n+mF9+vRxf/fPEPMHwwiIAQBAIAwAAAAAAAAZ4A/OzJ4925x00kmmR48ebi0sBcSqexrEdHjHrGbN\nmqZbt27m0Ucfjc8O0483004IhgEAqruaBgAAAEhmyssGWaDl/gYAgFzkBcC0Dtitt97q1rlSMEez\nmZgBVjZeusTffvvN9O/f31x11VXmhhtuMAcccIA71gUFBe6/hYWF8WCYXgMAoLohEAYAAAAAAIBK\n4U+D+P7775tevXqZ1q1buz8rkIPy03FUWkmts3beeeeZF1980QwaNMgd5xo1argZYgqAeUEwgmEA\ngOqG1IgAAAAAAACoUP40iJMnTzZ77LGH6d27twvWKKUfQbCK582wa9Omjdlxxx3NFVdcYWbNmuUC\nYWHrhwEAUF0QCAMAAAAAAECF8AdZlAZRKfs6duxoDj74YBekYR2wynfZZZeZr776yvzxxx8uIPbI\nI4/Eg2H+NcQIhgEAqgsCYVlEFZF58+aZpUuXGlQ+VfgOOfRQc+VVV5uqpNFZ7777bt6c98/HjTO9\nevU2e+3dzRx+xJHmxRdfSuv3b7jxRnPyyaeauXPnmsqk8798+fL44sFhVqxY4a7LVM2fP99MmDDB\nTJv2u1myZImpCNq/v/6aYX788Sf737/cPiO/TZ061Xz2+ecJy2ZFefnlV8zBhxzq1hRA6sZ++qk7\nbu/Yezeyy4oVy81VV19t3v/gg/hrujd/++23Kd0/J078xVx73XVmnH2WAQCA9HnBFdVlhw0b5mYm\nKQ2fAmBnn322QeZ464cpBeXVtn60ySabuJl5XhCMGWIAgOqEQFgWef31181WW29rLrzworQ631E2\nquSNG/eF+eWXiSZTwiqWd955p+ndp68Nhr1nct2sf/4xxx57nOsk7tx5R9Ns7WZmjTWapPUZU6ZM\nNd99/12lXwMf2E7SDdtsZF6z112UnXbqYvbsupdJ5osvvjA9DutpNm/fwb2/8047mc3atzdHHHmU\nGT9+vCkLjZwccvnlZquttjadttvO7N2tm/3v9m4bZ571PzNjxgyD/HTFlVeaE0440cycOdNUtrlz\n57jyu2QJAzDS8e+iRe64/fH7HwbZZeXKVfa5/kuJ6+eVV18xt952mwuGJbNg4Xz3+/MXLDBlQwdS\nJtBRBwDZxx9MUVtrzz33dOtUad0qBcQaN25sUDUUEFMgUrPE9tlnH9O3b994QMybIeY/fzxnAQD5\nqKZB1tDIco1kfvudd1wHzrrrrmuQP0aMGGEee2yEee21V0u8vpMNmky2lVKNzsp1Cub++++/5vrr\nrzNHHXlkwvdef/0N5seffjTDH3zQVKkElfyYSd4IUIfpSb16m0W2Y/yww3qY9ptvbubOm2d++GG8\n+enHH02t2rVNuvSZxx1/gvn9999NixYtzEEHH2RatWxpg18zzSeffOIaMU2apBdgRO7YY/c9XEfB\n6qs3NADKb9NNN3ODBzZovoGpTHoOXHf99Wb//fcz23XazqByPP744+bJkU+ZUU+NNKuttpoBAFQd\nf1tJf1Y7ZeDAgeabb74xQ4cOdakQkT20fpjOiQKT22+/vTn99NPNJZdcYmrUKBojr5l7Hv1Z59T/\nGgAAuYxAWJb4888/zWeffW6DIRvbyuNv5s033zQnnHCCQf545933zKqQoIpGyuknH/w+7Xf33y22\n2CLh+xYvXmw++ugjs0bTNU2ue/mVV1xK0wsvvMCcesopJf5NqRULCwtNOpYtW2ZOsw0SBcGOOeZo\nc9ngwaZOnTrxf/dSOtYuQ4ANueGoo450PwAqxlZbbul+KpsGMWkdDkZRVx6NWteAMWMYrQ4A2UTZ\nLG655Ra3DpX6MR566CFmgGUpnRfNDFNQbMiQIW5A7kUXXWSOP/54FxBT4Ev/1Swx/ZdgGAAgXxAI\nyxKjR482U6ZMMY88/JC5aNAgt65Sz549Tb169Uq8T8GDEY8/Yab89ptZYSsmmjW25x57mEMPPcSs\nvvrqoZ+tTvPRH39sXn31VTdCS2tlNG/ewvQ66UTTuXPneKVmzCefmEcfedQMGnSReeqpUeaLL78w\ns/6eZTa2FaPjjj3WdOrUMf6ZmrEyzFZ0T+7b1/z444/mnXfeNdN+n2Zat2ptDjnkENO1657xz9Va\nSTfddJPZepttzGabblqcnug702bDDc2NN95o97uBq1yNGPG4+dB+P03RX2eddczWW21l+vU71R0D\nzTK60X7GwgULzeDBl5r69euX+I4vvfSyefnll02v3r3M9ttt547lU089Zb7/YbwNMk43DRs2NDvu\nsKPp3bu3rfg1Mul46OGHzcSJE815555r7r7nHvPhhx+awhqF7ju1bbuRmT59upvtFbUtdYzdfPNQ\ntw5Y3bp1zSmnnOo+t8MWHcwZNuDxig2kvPHGm+bMM8+wn9fWBYluHjrUff/11lvfbvNue7wnueOw\n5ZZbmL59+poWLZrH90+dQq+99rp59rnn3NpCDW05WNMGmApM0fHv0qWLOe64Y92aW8Ntg0Qziv62\n51X71najtmbfffc1u+22a8Jj8IH9zs8/97xb/0pBmc0228x+v14uxYLMnj3bjHr66Xiawauuusqs\n3mB1F+A7/PCeJT5L61xde+115ofx412Z9Y7H7rvvZo4snkWmsjPDHjc1pr76+msTWxUzbTZq4wJN\nm9oyFPT0M8/Y4/iqCx5pnw488ACz/377ZaTCPs8e15o1a5qN2rQp9W96PV0v2XKs9cAUTLzm6qtL\nfQf9PRgE0/X4yKOPmvG2DKr8tG3XzvQ8rIebbejRNXbxxZe4MrbLLjvb6/dW8/3335sG9lravP3m\n5qwzzywxC1UNn7ffftud16lTppm69eqatddey9QoKBot2GXnLu6+oMbuNHvcT+vXz9xjr4+PRn9s\n7znLzP333edms8nnn39uHrf3re9/+MF+xtoubabuHbVq1Ypvb8KEibZ8Djfjx/9or/MFZq211nL7\ndaJtSDdv3tyVc93/NAtA61lp/1rY13UPO+KIw0vdEzw6Lrp+FVDU9fvaa6+ZmoU1zQ03XO+OhXzx\nxZf2vjrC/Pzzz6ZxoyZm5126mBNsQ1DXq+emm282a66xprsP3nHHne699ew2d91lF3Pqqae46/z2\n2+9wx7T2arXN5ptvbvqffba7l3kWLlzoyqlSxeh+ucqW6y3tee7Vq5fZaKP/yo+O6U/28y+84AJ3\njej3Lr/8CnvednEzWu60259oz3kT24jdeputzZlnnJG0o0Hn/9VXXzMvvvSiO346pnvttZfbhzDq\nzLjn3vvMl/Y58O+if82mm21q71FnumPuUVn9dOyn5owzTjfDhz9kr9Wv3Hs3s9/9pBNPKHGt/mzv\nHRoVPKB/f3us/ja333G7mTXrH3PM0Uebk+yzyL/NTz8da5YvWx66Td1rHrbHJ3gfO8Q+A3fcYQf3\nHt0HdN/+6suvzJy5c+z9sKnZaost3YzNjTfeOP5ZP/30s1sz4Ztvv7H37UZmG3ssdR0En7vf2XOq\n9/3000+mUaPGZtttt3EzP8ti7Nix7lhdffVV5qlRo9y9e+HCBaZVy1ZuzQx1RDw16inzkq0DKNXs\neuutZw45+GD7XD24xL1gkn1OPvvss668Tf9jumlqr5ddd93VHG/v9d7+q9wMHHiOOdEeXwXlH3zg\nQfObfTaq3Oi6Ublt0KBBfJ8OKL5v+um5cdNNN5tatWuZgQMGmvoR32vOnNnmLXu/mDxpsllgt7vG\nGmu4st21a1f371oL88OPPnTP5jlz5rrnfjt7n9rL/nu9ekWfquv+ueefd+VmjTXXMK/bY6Pnq64z\nPWu77d3NPV/9Zs3627xsryk9+3Q/aWnvOfvsu0+p/dN6X19++aXZf//93TH1TP51snn3vffMH7bM\nFD1jt3TXUvC+q/uNfl8Lzv/9999mydIlZt111rXPrd3d/ur+9Pm4z92ae/qzZkeP+3yc26fDeh5m\n1miyhvsclU3VBabY/S20HUub2N/t3q1biTKn8qBAj7sX2mOpe8D6669nuuzUxWxo601hdHx1fz/6\n6KNsPeQv886779h64hTTXMeje3c3q7hm8aAM736ym33m+utkW3ToYOsqN7n36Ds8/PAj7p6rwN5G\n9l55hH2W6x7k0XuU0vnJkU/a4z/NdZRtsMH6rs7R49BD43VS1UF1/9eabfqsli1bmqOPOso98z16\nht1ww43m3HPPsdf2WHufesn8Y7/TuvZcqYxoYIBmfmnQ2LBht9g688fuOXj6GWe67+U9wwAAmeEF\nRrwUes/b5/eAAQPM1ltvbd6zz1WvjYjs5l8/7KSTTnJ9GmrP6XWdVy8YpoGd3uATAmIAgFxGICwL\naAbIs88+ZztON7MdbNu6nM0P2A4rdYRuYyuTHgU6/ve/s11ndOfOO9mOwmXm2+++sx2yP5kDDzow\n8vMVvDjDdhaoAqPPX8N25irwpoDOE7bzt2PHogDXtGnT3OyW8TawpY4evd7EdmYpwKTc3rfeeos5\n8IAD3Hv/sR10CtZ9//0PrgNKQRt9rmY9vf7GG+acgQPNaaf1c+9VJ4g6x9XRPcF2SKsjUx1HjWwH\nZq1aNV1nitbDUSdJc9vJ237z9q5jXYG292yl7NFHHradj43MksVLzDM24LGnDbJ123vv+PdTx/8D\nDz5gptr9P++8c91r199wg3nFBv623mpr19mmAIE+T53HtwwbmlYqnW++/sZV6CfZYNRntqNr43Yb\nm7WarmE7yYtm6ShAp3MTtS113Pxjv7M3msqbFeZVJtVJ/4Y9ZurAUse8C1za4/Xmm2/ZYzXHBgSa\nuk7yadNs5+5DD9uOqdHmFXtO6tcv6ji79957zbXXXe86ZtVh9Psfv5vnbNBK9Jlr2fIip51+hus8\n3m67Ti6gpg5G7XdteywSBcLutR3T1153nQs0bGODmQpKjnj8cfOCLRMP3H+fDQx0ch3rWm/NW9dL\nneurInKLK8D1t+3g8mZK/Xc8/nvPAtsheuKJJ9nPW2H3dSt7jv91wc633nrbvP/euy6Y4rnookHm\n0ccecx3IrVu3ch16b731lvnBBl0uOP98U9m0XV3Dzz3/gtl5553LnaZJgRo595yBKTU01FHZ77TT\nzdKlS23jcyvX6f+u7QR9yXYkXnrpJbZj/Lj456jDV9fULbfe6jqUdR1Os9evUnYqmK1jqw5ZnbcH\nHnjAXHHlVaZ9+/am615d7T1hpnnhhRfdZ6njdi27Hfnm229tR/qn5mcbVFDAfRMbaND16nXsKiB9\n0aBLTJMmjV2gQR2mCoSqM3iU/TddFwqSHHbY4fY4LjU7205UBT4mTZpkHnxwuCvTCtqorJ5/3vnu\n+ykYpY59lTmtwabAZ1Qg7NtvvnX3gvnz5rvPcPeetRq7Tlp9T+3fxZdc6vZX97zp0/+wgdyrXWfs\nHbff5gIFet/YTz5115aC1M2aNXOBWd3/dCx/GP+DOwZF18jWrrNbHb967Z2334oHRHWdn2MD6goQ\ndrDHVfcFpfgaPeZjM2rkSPe53jEdM+YTG3gY4P6uwQRKnfuJDVjo3rvBBhu42cMK5Oj6VCDjJXs9\neilNwjzxxBNmkO0ob9hwdfs9O5l59ngoDYr/WvIoWNG7dx93D1PKlKb2HvTMM8+6Tn6ds/bti4JA\nE36e4II5b9rrUsFPBW+XL19hRtnX9Nx42v53s82KgmHq1FYQUMf5lVdeM2vaQMc69vvqv8Ft6n6k\nchbc5vz5C8zx9lmhazt4H1PgRIEwdbQffcwxLhiwww7bm/Vtx7zK0r02MLuVvT68QNh7771vO9HP\ncOdGgyf0XFKAU9ffa6++Gi+/KqfqbNc1rs+rVau2edjehxuVcYSzysardht/2HI2ceIvZgd7fBvZ\na1FBpHFffOGuYd3jVY6UDvXTzz5zz+s111zTBrqKghB6Rlxqy+wnNmC4pQ3wtbPfSQEaDUCYOeMv\nM2jQIHd/VbnRtqZMneLKigYweOVG5XbiLxPN3XfdZYMs67trV89QXdv+AP6XNpj4mO0UObxnz6Jn\nzqzS3+mXSb+4Y6egWatWLW3Qp4l7JjRu9N+gk+dfeMGVUwVyFIhSfeN5e8/UmpBn2kBqgQ2wL7XH\nWOtDqg6ioFhD+/vrrruOO8cK4upZqWtitdWKnr36DKUhVDpC3Ye1fzpe34SsA6bj/aU9RgrkeIGw\nr7/52txnrx8NKlKgrWbNWi64qKCo6iV+0/+cbu60x0r3Nj2PG8Yauc/73AbYLr30UrOBPYZaLy5+\nDcZMqfU1vv3uW3e9rrLb0znTPVsDYbQf59qApe5JbuDQzUPd9bDFFh3cffZvG+xTedXggKhAmJ7L\nus9p4IiCYpr91swG4T+zx0MZBpSeSoOIvHKh+4lSRXp1MpUNBS9Fz/GTbHBe29T9smXLFuZjWz5e\nt2VJo8c1sMY7p/37D3CBra222tLuw2Lztd3+BFuuVY/1vo/qHhpUoaCbyrTO8fEnvG6uu/ZaV0cR\n3QtVVv+y+/Sdrdd27LitPc4bmc9sMFF1VQ3iGjLkMrfP+qlZ3CHn1amYGQYAmePdc/WsVADl8ssv\nd/U2zQDbbbfdDHKPzpuetTqHeoZrUMvFF1/sAmL+mWFCukQAQE6r2WzvWEX+5BPj6nmV78svv4xt\nvMmmsauvucb9/fPPP3d/v2jQoJitdMTfd9zxx8dab9gmNm/evPhrtgIas51ECT/fdprFvvrq65gN\nGMVfsx1SsQ3bbBQbdPHF8deeHDkytkHzFrEtt9o6ZjsT469/ZvdH2+203fYx23ET/329V/tpOzji\n77WBOfu+7WIdO20Xs5Up99r8+fNj3brv495/WM/DY3/+9VeJ/bOBM/dvNsgXs52N8deHDx8ea96i\nZeyGG26IHxe97yz7Pr9x48bF2rXbONa378mxFSuKjtekSZPtcfkz/h599wMPOji2Udt28e+mY6vP\nO+HEE2OJnH12f/e+bTt1svswrtS//24/L9m2ZLvtd4jt3a17qd8fOnSo238bpHJ/1/ntvs++bps2\noBdbWnxMbMe/KxN6/bPPPo9vq9N2O8T27LpXbM6cOfHPvPyKK9z7bCed+7vtOHJ/v+rqa0psW9uy\nnZexKDqH2u/u9vxN//O/76h93XSz9rEeh/V0ZTC+3cuLtvvLpEmxRGyHa2yHHTvHjg859rbT2X3G\nMcceX2LfbOe6K4dDhw0rsR96b+8+fVw5F9upFzvggANjm23ePvbdd99H7oMNbrrftR32ke9RWd5l\n191iiWh7u+/R1ZXVAw88KGaDyfF9KYtdd9vd7desf/5J+l7b+Rk78sijYlttvU28/IgNmsb23Xe/\n2LYdO8bLoM6Tjrk+e+A558TvB3r9wgsvcq/bgIJ7TWVp9z32jO22+x7u+vUMH/5QrFXrDWO2UzT+\n2oCBA93vdthyy9gXX3xRYv9sENjuQyf3Wd59Sts7//wL3O/YYJF7zXaiu/vRa6+9Hv9dvW/mzJnx\nY3nU0Ufbsrh9/L4iuia0DX8ZDBo48By3rXYbbxKzwfZS+6f72m677x7fP92DLr74Enc+bZAqvi82\nUOc+Z/Dgy+L3KZVPHSPv3qbz4b3/5FNOda9/PGZMfHu2w97ei7+K39f1X++aee3110scU50r26Ht\n/v7333/Httm2o3vfDTfeGD8m+v7HHX+Ce33cuHGRx0DHcYcdd7JledcSx88GjN11ot//8cefSmy/\nRctWsRdfeil+bG2Awb2vR4/D4u+78cab3Gv72+tN++h9d9tB7sqJDTS5fRSVGb1XP4MGXVzqGvFv\n0xPc5rfffpv0PvaC3bbe88ijj5Z4j861d94WLlwU22vvbu6YTpgwMf6eW2+7zf3ujfYYiw3Ixw6w\n17SeczYgFn+fjqHKtd778MOPxNKh+5h+T8d9su9c6HP0elv7LPDfk2wAw70WfO7Z4F6J54vuQ112\n3iW2s/3Rn0XnxDvmj/qOh1du2rfvEPv555/duTjzrLPcNWIDwCW287+zz3bXZvya/+2lEj8rJj0f\nu6bfTrG+e68bG/PkoPjrKye/EFv806j43//+Ynhs9lcPx/+uf7v61M6xMw9qHZvx2QPutVlfPBQ7\n94hNYyfusVbsmaG9Yst/ea54G8/Fhg3o6l6f8PbQ+GfcecG+7rWPn7gw/trC8U/GLuvVyb0+8obj\n468/f2uf2Cn7bBD78fUb3N///fGp2OV9to+dtn/L2NcvXBl/328f3B47/YBW7vffGT4g/vqqX190\nv6vv5b325XOXu/eNuOao+GsfPXZ+rFfXZrGxT11c4jgt/OHJ2OCTto31P6xdbMqHtxe9bj/zhdtO\ntu9f231fbWP8a9fHTu6+fuypG48v8fvzvhsRWzrh6f9eC7CBM3eeN91s85gNfMVfnzp1amyPPbvG\nNtl0M1vX/CpeLrz7SVidzCujl1w6OH6v0jNl5112deVe90pdSyed1MvWPbrG/vE9q1SW/vTVFZ54\n4kl3L7jssiEl7pu6/nQNePWWsZ9+Gi+rn/vuZdrWTl12dvvrbUe/v7f9/QMOPLBEvTbXZarNAQBl\npTqe96M66lm27tC4cWPXlq0ObLDItR/zneq5J9o2esuWLWP33nuve9aqD0jPcT3nVY/0lwUAACpT\nRcetahhUKY2kevrpZ9wo3d2LR1Bp1o1S1GhEvUa+elo0b1GUYuaJJ9zI61jxSBx/OrMwGt2t0bpK\naadZFBqF3Lp1azcjROm89JqfUtr4Uwd16tjRpazTzCbbWVHivUoL5l/fSrMcNKpf6e80o8FPo5mv\nu/YaNwvAb9Sop91MissvH1IiVZpyVm+33XbmKfvvmiGkEd87dd7JzYDRaGnRMdAslViBMYcfcbg9\njkVFesMNW7uR5Pp3jTIXpYLS6GSlhkyXjvOlF1/sRikHrW+PVdS2lOqrrDRzQannahcfE5URzcjT\nyPkpU35zr6l8LFmy2LRr17ZEyqiO2xbtp2bpiFI9KRWVZoRptLXKgOh3GjWKThWpUeMaja8ZBuv6\nUrztsMMOLvXZp7Y8KDVmRdPxPv+8c0rsm1JsNWnSxM1A9CjVo2hmi8qxjrnS2SmNks6zUqxVNu3T\nk08+bk7u28fYYKE57bTTjQ2umCuuuNKNtE+Xrh3NKluzeHR+Iprpopkcxx5zjDsnHqWnOvfcc13q\nOaVe89MxVbo5b90xHWuljHOf98sk91/NLtDsEM1w9Kdc1SwVHecpvnPgUVoq3bv8lLJMZbTfqae4\n46Tzo7J38sl93b9rpqVoJujKVSvdjADN8tA2tF+6Z3izU5Q6TqnwdL1rBojomlDqwVRGJJ5/3rnu\nfuWnVJ7av1NO/m//NOJRqcw0E0wzEP30nj59esfvUzqW3mxKzeDzUilqfw46sGj2rEZXejTLaKut\ntnIjKnXv1/28806d3b9pNkkymg2iVJHeMdH379HjUPdnpZSNolkhv/8+zZ6HU0ukqtljjz1cOj0/\nndt33nnP7GZf1wxHnS8dFz2TdtxxRzfjRmvieWrWLHTnt2nxDEFvxqCu108//cw9N/w0q0rpz/yz\njoLb1PbCtqn7VYMG9RPexzS7SSnnXnyhKAVkrHjUssqJd97ef/89NxtLa/Ap1aS3PaXD1H69/c67\n7n1K16aZVt267e1S4Hl0DA895BBTHkcccYRp7TsXBxaXF80CV7paj865ZotPnTolPuPWe13Paffc\nscehji1729rrT/cgfRc/pek89thj439Xudlvv33d+3R/13c+7rjjzDJbHp8cOTJ+zDSb/PPPPndp\njqLWfdQ9SLO6NDO4U8f/0ierjPvXNmy6ZlN7/azhpv4WrZ1Yw2y0UVs3g3DevLklPlPnUPWh/8p5\nTfvZnVzZmjmzqE6ke4BmiOke1XnHzvHfrV+vvkslmczUaVNdPUKz2VXOPJrdtEvgPiHatuogRTO7\ni67djTcpml2o+2wymvWq47TLzruYdWydbdnyZWbZiuWmi73+dY/9+aef3Gu6x2imvGY2q37mzUxr\nuHpDU7t28tnGmi2r69qj2bRnn/0/lw7x00D9LapOpueq7mUDB/R3MyFVTpo2XdPsv/9+bkaqZi6q\nDK273rpuhu/rr78RvxZ1zrx0sCpHSlGq7Sj9qcqvPkvPN6XP1jNaaXP9utl7h1d/EX1WZ3sP0OcH\n7yUAgMyI+Wbe6r/Dhg1zs3b1bFQ9V6mdkT/86RK1tIbqPy+88IJ7jqteoh/92V8mYszMBgDkCFIj\nVjF1AH48ZozrXPlo9GjzzTdFKX20JobS4inN4Ek2ICR9+/Z1HYtXX32NCx7tbzuyevTo4To6EnUE\nq1NbHVpKc/Or7RicO3eOSzO4YMHC0PVh/GvVeNQ59+ijjxYFoGxHpadNyLpI6rQTpYDyU9o//3o5\nooqUOtJU4Qqu/SEdbAfVRLvvM2bMdPu17777mLGDx7qKmRbhVSee0oUpXaE6tEQVMaXH0jo8Sh2p\n9WiWLF5sfv/jj/g206UO7M03b1/qdW1LnTPq0A/bVjDImA4dD6XD8lMHUp3VatvOpKJOJ/17vfr1\n3JpSSoekNGfaplKyqUx451JraZx33nnm+utvMEcedbRLP6fghwKNYcfd89tvU1yHmAKLQepcVblV\nA0hplSqS9kmdZ37qVFWH6NLi7y6//vqb++8FF1xY4r3qQJQ/pmem42xtu68KFmqBYaWJe+D++10q\nNl3bIx57tNR5TETXiK4JdRj6O5LDKFglSl8YpBRlCqapszj4+Y0C59wLdnmdmSpnSvU1yQYCVL4V\nbFdZ17WmfVo3cB3r+vCuP79pxfv34PCHzLPF6TplVXGHvlINitJv7NOtu2tsfWY7a7vutZcLNOhe\n4qWaPPmUk20g/jO3VpdS4R188EE24HlUqU7cKDv77lseL3j0yKOPuFSfHh0HdQD//c8s918vgKLU\nhQqQ+dUvXt9IHeh+DYqPqT8ooc/9zHb86n7xpy2b822Af/78oqCSP8gRZT3b8RxMAdmweDtKSxZF\naVV1rarTwk+vtSteJ83zlwukLHb3s379Tivxb1oXTRRs8QJPderUdc8gP52zze094YMP3neDNpTK\n0aNyEgy+p7pNrSt5qg3m3XPPvZH3MT0zTrBBenXA77f/AWbPPXa3QZ7jXRDXS8f6h31urLBBCKX3\n/fzzcSW2p+eDAmjufcX3cX+gxNM2cNzS1SaQ4s47r61btyrxPFdgQakA9Vzx1mjQPur5qhS6Squn\n+52eCb/a8ryquJPCL+yZXs/e11fa9y1dWjR4QylNFcjy1oTSOVNaumk2QNvbBn+D5d6jYL+uET3D\nE62JqECm1pDTPXu+/bN+R2lyYy61XWDf7P0kuOapypTK6/JlRc9UBVEURAted7Le+uuZZJQaVMez\nVWt7vAMpRddZp/Q9RYEvBSOVDlHBIK2Ft9yWIYmlUKfQ81kUjPLfk/X9dY+Y577PcvcM33vvvV0a\n0SGXX+5SZe5i712tW29YYqBQlA3W3yBezj0btdnIHU//wCoJq5NpfyZP/tWVoVMD1+I0GzxU/ULl\nTedCaXdVJ73woovMw/Z6O+yww9xadl5QXGvFqXzo3A8YONClFfV49UPvWvNs2LpkXUPXwuoNV3fl\nujz1KQBA2fgDHKq/al1bDajVQCHWActvOr/P2TaX0iWqH0FLZShdoupe3pIP+m+i1OwAAGQbAmFV\nTCPb1RGgTjCt/+SnDgCt9XTUkUe6zmet0zBy5BNuDQvNkrr9jjvdWmIXDbrIHHnEEaGVEAXB7r7n\nHnP//Q+4NXoUsFCnSGHNQtuh83XoPoWNOvbWo5rvmwlQ9N7apX/fdtZorY0FixaWeH1125EW7MhR\nR5T2UWuKhKlXr67tbNIstqLOZC2uvsYta7h1Y4455hi3FohG7Z95xhnxYIPWwrjgwotcJ7zWt9Bs\nKa1fptlawU6XVNWuXcvNRAjSti69dLCZZDsgK2pbnjq24y9Zx5c6J0+0wRetEXac/a9mBU23HewK\nFGrE9ba+kdWaNdR2o7Zm1NNPuyDhG2++6d5/sS0/CmqF0Yw2lb2wDk4FyNSxVZYZdsmo0y6VTj91\nsnkzh/z0d32nLSNmMUiN4s5CdT5GUSexF+hIRvuhtZ/69O5lehx6iDm7/wC3vpDWoOrXr59JlRod\nCoRp5ptmOyTizczxZiL5qTNUs0T+tR3o/kasruVEHdaiWQlHHHG4ufnmoaZPn76uHM2ynb/6PipX\nW/vWLvS2HxZQnTe3aKaHZnh4ay55DrGBrvWKZ7NqezfeeINby2bU08+4RteTTz7pZjtdYTuDdZ/R\n2jLPPjPKraeoWbHDht1iHnvsMXPB+Re4YEiyWWFNAvcYdfR6x0+zLYJlSIGA9YoDgB7dj6KOXbKg\npWZkaI3Ht995x5UTzd7pYL+T1kP8+utvTCpUFpOduzD6nrqe6gbOgTRsVPK8aaaNghTqIA8eE2/2\n2Oq+oIjKme73QQrQK1Dhzd7zrLFm01LvTXWbKgenn3aa6bhtx1L3Mc0obmsDfXrPJbaRvucee5pH\nHnnEvPbGG+aVV18zBx90kFsjSeXUO+8KbAa3d5B9n+73osEiErb+nDrny6Nx4/CZuHVCruUgrZk0\n+LIhZo69vja2zxyN1G3SuIlb21M/QY0aNkr6mbrnHnjA/m69PNVL9t9/f7em3fo2qLRT586Rv7fE\nBnd1LdVNsN8zZvxlbh46zD1PdH/TjNXV7TWnK0vXRVAtV4dIXM5VXlR/qFOndH2lXt16JhmtLSph\n120dG3j016cUgHn5lZddvUP1KM1k00zC1ezv/lQ86zqZhQsXuP9qjddgedJM2gYNVjc1Coo6kw6w\nx36TjTdxA6G+svW0jz8e496jZ3iTiLqSJ/xZUDQ7z/vOnrA6mZ6Huh4brN4g9Lm6zTbbuutMNGtd\nAz2eemqUGWmfc1dceaVbR23QRRe6oJjqdsuWLXf3/mbN1ikRoNNn6TkSXPNM2wUAVD1//VeDHhUA\n04BY1gGrfpSlRz9aJ7R79+6uD0aZBloXD17xshR5P8L6YQCAbEUgrAqpA0gLpSu9kTp7lV7P7/ob\nbnQBje9/+CGeKkaLmffp08elMVLaOs3w0QwxjeYOpiWTn376yQXL2nfoYK675up4hUUzrDSrLMxf\ngVHDohkF0iIw+nrm3zNLvfeff2a70fbrr5t8VLY6YdQxqW3GQhZd1QwrdWx6QS51lO6yy862Q/49\n893335vXX3/ddQwpQCb6jPsfeMBV1G8ZNtSlbfQ6Xy63gblgGp7Ula7MedtSyqPbbr0ltW2lkTag\noDC10VWHH364ecl20P0za5b54YfxrhxdeuklLsWlvzNRf95pp86mc+cdXaBFQYTHRjxuOz4vMU+P\nGlVqFLmo007Bz2BntihFlToj/bM9Mk0BhX/+mWWuv+7apIGIIM2WUqehZr2FWbhwkQu0tW+/uUmX\nyuQZp59uO6w/Mj/aazAdmqHzjg2WPGEDQYMvvTThe5sWXxdeujC/uXOLztu6xakD/2vQFqh1kvBz\n1RmrAPwLL7xkAzXTTH3bYaprUKmyevbsmTCdpp83M0NpNHfaaaeE71XnsIJjBxxwgPnyyy9dAP/J\nJ0eaLTps4VLYiVJ89up1km18HePujRdeNMgMskEPzRxLd1aivqPSmur+0qdvH9PVl+I1KJ1jF0Uz\nzt586y13XIcMuSzeYa3O7hd9s9Eqg86DOrgXhAStNbvFTzNSNPtGQeRh9h6arCGrzw1+hvxunxk6\nX8GyEvZx6Wwz6j421AZa7rj9Nve7eo+eEzvv3MUNlLju+uvNU/Ye13StpubCCy6IpxNWwFr3zyjN\nimcG/R2S+m7O7LKnvS0PBTPuuvtuM2/+PHPVFVeYffbdx9Qsvnf/+NOPblZYWaljS+fiw49Gu+Da\neFv32GHHHUNnfnsa2/OrQMs/CdLAakCPZgaefvppbnad0vvKYyNGhKb0LEhhZLECJjrPYQMxFi5a\nmPT3vUDkvLnzSv3bIhvA8c+q06AEBbB1n+l3ar/4tatAz/O+ma6JePfqjh07uZmMiej4aBCEfjRz\n6pVXX3UzyTTI6JRTTkn4u3Pnzg19TfXNZs3WNsnofqgglf57SwrXv4LJZ555husgfe3111x9VPfl\njW0gb+ON29nA7mo24La6udbWP4Oz/MIwqhwAqp6X6k4DWG699VY361eBEKVAVN0O1ZMCYSoHQ4YM\ncQExZUNRn5Se3aoveP+VsH4dAACyAS3OKvSD7WTSjCKtraF1ZtSR6/85znb2qkPkaRuwCuZeVqfh\nvvvsYy63FRF1BPnXofH788+/3L/vtOMO8SCYTJw4wXX0h/nkkzEltqXR0Ao4qXLTNpBaa9zn49z6\nXR6l/nrLdvbWql3LBs1amFSog1wdTV9/XXKGmjpu3rafpU4ZL9WOAmcasa/v9Pzzz7uZFEqFpdlY\n3van2MCGpuxrbRkvuKOAwFcRM+DKytvWGmuukdK21Gm36N9FFZ5DW+dGZemmm26yZeUpG5S71a0t\nFpyB4223KGXiRub8889364koyOk/h37b2bKp9FnqrPdT57c6BmvWKixTijB13Go/Fi/615SHOiZX\nrFjpUpylS0HVZms3M6++9mqpzkMdq7fefsv9eastS6b8U9nzH6+oVJtz5801NQpM/DzoMxUw8NIP\nRlHKTwWFRtjOfaXRS1Re1FHauHET8+JLL5fYD/1ZszrUgO3Qob0pC820mTzpF3PrLbeYp0Y+ae66\n8w6XnjWdBvCmtjNd9zClRUyU+s//HXWdKNXdlbaTX2sKeWvQ+d+jTlqlDzvrrDNdWrHJZez8V0pJ\nBXPfeP2NSk+7pSC1Znlq/SevI13X0bhAar7KoHRjut7ef/+DEq+rHGutLT8FthXc+GTsJy71bDIK\nzHz2+Wclzo+up9GjR5u1bcd74yQzWNLdZtR9TIMfFgdmP+o9uj9poIkCuVoXzK3t1G5jl27wpZdf\nLrWelp9mBOpZ++GHH5S6bsd9Ufq8KXCuGVllSb+bKp2zv/6a4e5dqjd4QbCZdrupzk6KonuiAsIa\nxKHBFZpxpnTEiWZn6RxrZpTqMkuWhh9LpaJUQFTXmxcE0/H89bdfTVlpllvdenXdsy84q/fH8cnX\nrWzatCjYo3Sc/mtf638pJayfzqlSU26/3fYlZlz99FPp7Wi2vcrgsuL1Qj0q4zXsA2Hs2LER95qY\ntwOlfq9v795ucMW0QLrpMN98+40L5Hm0rfc/+NAd7w0CKUyjbLnlFi4AN+aTTxK+LzjT+LAePczA\nAQPcNaU6qY6vngEKWGtwQ0UptOWxwB5LfadUUsoCAFLj9TfoR8Ev1bO8NrqCIATB4F8/7M4773QD\np5Qm01s3zFtHzF+WAADIJgTCqsiq4uCC1jvSWl9hs3EUXGllg0lvv/22W1/iQVvp0EyRv/76y3Vw\na+0epRJTcEipx8JodlChDWC98+57bqF2re2gjphbbr0tnm4w6JMxn7jZKFpPQttSSqPPx41zo/BV\n2fGbbDs7brzpZldJ1nsff/wJ14G+ZYctXBAlFUcecbgLnA0ceI7tLPnKfdffbKfmOeec6zriTjut\nX4mOOM0aUADgxRdedEEcHT9vNpA6Lde0QTOlJdQIagUeNOPn+uuvdzPrKpK3rZm2UzKVbSk4p/3V\nLCF1mOocVgStDaNKp1ITPfzII26GxKhRo8wXX3zhRqyLgjcKlP388wR3fLX+3Be2Y0prx6mDrV69\n8FRSClIqxeDdd9/tAo8qP7///oe54447zQe2c+3wnj1LrTGSCs0C1M9PP/9sAzZji9Zc+Tf9oNgp\nJ5/s0jtdfc01bn2pP/6Y7srtt99+a/f5Hlcuo6hj/MQTT3Drq512+ulmzJgxrhNeHXhKqXbttde5\nmSN6j0f7eFjPw906Rup8VSfjPffea4Y/9JDrkNXaOrouX3vtdZdWUB21e+y+u/tdpeo886yzTH/b\nUZgoGKZUZFoHSe85/vgTzC02EKUGqLdvuuZff70oMKn922P33czHNuhw/Q03uMC31lJ66aWX3GxF\npTRMNhMrigLRCoIqyKjGsMrVyJFPuWs01aBR165d7T5s7RZYvv32213nqsrQL7ZjVMdY9yLRukSa\n/aV7lMrC37aMatan1s9qWRxQV8qtt+y9UOdX147O7adjP3WdomunuE5YkNYm22GH7d2MLJ2vKcX3\nsQkTJ7prSeWoouhevsyWmfdsw1HfQZ3rzzzzrHnm2WdNZVMAolPHTm7dLKWd1LZVHlVug2tkqZPj\npJNOcsGW/53d34yz936dM5VtPX9UrvzUwH3iiSfMy6+84r6XPveKK68yE20wQeu+pbKGW3CbCn6G\nbVPXwG233RZ6H2tQnOZNZeoB+349A/Tv+pz3P/jABsmWuOtFAzq23mZrs8ceu5mP7L34mmuudUE0\nvU+/o5nSr73+utue7tlKBaoBF7rn6drW+3QvfOedd0sdh2uuvdbsu9/+rjxXFs2q0b1zit3Xjz/+\n2F0vWnPq8iGXu3tzeeg5e+ihh7jP1PWu5+y2ITPN/dZdZ1237puOncqBypYCoVqPVOuXSdOma7p7\np66nBQvmu/eMfGqk+a14jcey7qv2bdasf1yq1KK1qOaaH8b/4AKcyahcapCAgjTP2/vTnDlz3X1F\n51XrgPnpGan1Kb+y92G9R8/T73/43taTRpYa7byGDd7rpW9smdFx9AZNtGzZyt2Pf/7pJ3tvedgG\nB/9wx0mz4Ufb8/hN8b1mmi3zqhuqrOtY6Uez33U/TuVaUrD3yiuudPda3ct0/1aaWXVm+lMlJ6JU\n0wpiqQ6m9Jgq9/os3Qt0H9d+q84xYsQI1xGm86lrTSmiP/vsMzeQo3GTos7SfvZZpuvy/AsutM/F\n19xn6UeBMT1jyzIAQevbaQCI1pvTta1zHzWYBwCQnD9ooXXA9thjD1dPV51RQQ8CYAhSQEwBMAVI\njzzySJexSAMTg8EwISAGAMgmpEasIuqwVyfcJptuGprSUBSc0Oynm26+2Y3QVifE5ZdfYRrYTgYF\nYNT4V2e51vLZJqKDQ0GMAw48wHZEv2j22Xdf14mmGUuahaa1GcJmrGuqu7ajDkKNjtbMMXWkavZZ\n0I477mA75t9y6yCtZjtOtOC71sk6u//Z8VlccRGz4xVcG3zJpS6gdtDBB7vAir6b1p3paytV+9n9\n9lOn1F57dTW32mCeUjZp9kh8E/YL9Tv1FBcEOvmUU91sMnUgqQKvNSvUUed/r/+/kSL+OZ1tyTFH\nH+3e26t3bxeg3LD1hraR8XBorjC9UiN8o/7/uFHnDRs1MvUb1HcBEnUaq6KpII1GZe9lAxF33nmH\nKycPPDjcBhPudvupfVfHlv58wQXnh671JiovV191pTnjzLPMWf8rSofhBYAUQDgtuPZVQYn/RFJH\n2ZFHHmEG28qz1jZTeiWli7r22mtKfD+T4BiIRsvfeustbr2cfjaYVbdO0Wh9lXGlHN2tOGVmFKXc\nmzR5klt36ogjj3LBTX0/jepv22Yjc9VVV5VYJ0Udm0o3OnvObLcNzQ5Q5+5bb73tjrF+X9QAUEDr\nNBsw2704EKaO4C+++MqtMaOO1OD6K35nnH6aa0CoETp02C0uGK1zpG2oI19rAnbv3s29pvM3/c/p\n5i57bocPf8jt03zbedpuo7ZmQP/+SdeUKTqkJU+ctq3AwqpVK81Lr7zsgttqvqxcsdKWq8WugXzn\nHbe7bSW6fvTv1193nbnwoovMsFtuNbfedrs79+pM1v3tant8RYENpa/TZyk121JbdhUM04y/ffbZ\nx71HsyzVcarfc9ea7fjU+oFHH3Wkab/55km/W9h+apaK1pPS2jb33nefS8eo/VMKQaVeu+SSS8wW\nNvCeSmqP4Hvi2y0+qLqvvqCgor3mX375JXcsFWjU6wps+n+/KMd+yGcXhG44dPvB73nOuQPNmWee\n6QJNRWnhClxARcdXgXP/ryv15N+z/rbBkBHmkEN7uJS86mjWvWW3XXc1few9zKNOaa0bdN7559tn\nwGpuVpbK6c477+yu8VK7G7GP/m3ubQNoYdtUubnLBrhVloL3sZNP7us63PW8UiDuqquvib9ntr1u\n2228sQ0sHxcfdHLZ4MHuHDxqAz6PPPqIPRaNXAe/1j0866wzzD72vGiAhdIAKcB32x13uACb0vbp\nHrH//vu51KHeF9K9X+XYK8OR4ge6IOKfC8JfK35Z19TJffvYgPo5pt9pp7tt6ThtsP765iD7rH/x\npRdLf1ZY2Qg8Szxa90mzYMd+Otadw2QDHbSNHraM6LiP+XiMGTPmE3cf1P1xu+06uc/q3q2bC9Ao\nmNjEPkO0fqjW8dprr71cICW4dxFHptQr3W05UfB8tA08agastqvy17lzZ/esLXENmZLXicrBEYcf\n4VI5axDFOzbIXtv+vsrbDttvbz4eMyb+u6orbWODp6qHKeha0z4f9H31Wt26dUo9kzbddDMbBPzG\nBYO1T0qTqzS+R9s6gMrOmE/GunW/NItKzwWVOc3w33KLLc1Su/8v2fuDrkmtnar77hz7vFlzjTVt\nffBAk4zqk0rB+vQzT7vn95w58+y2N3Br621YnBUg4f3E0tpd11x9lbsn97V1Gw02Wb5iuVn872Jb\n59rQHG6fP3rGjR37qXnl1cHunqzrVfU2HVcFU716reqaWr/v+utvNKec2s+9VzPjFi78192HBgzo\nX2JXwu9jJc+dnoFKt6vzccYZZ7qZm7q+H7j/PlIrAkAa/IEK1bEGDhzoBq8NHTrUpcADkvGvH6YM\nPUqXeLFtW3nBL3/KRH9WBwAAqkpBzWZ7V+jwjOV/vWHyRcl1dSqWOs1+GD/erVO0USDdoJ9G2mr2\nRIvmzV0H7c8//+xmFSkFUdM1m5qWrVq69cESVSgULPnuu+/diG0tLK91vrQOkUaRq7NbI3pEM4o0\nAvjee+8xG7dr50b3qsO+pe3AUcXGv8C7ZkBpZsygQReZ/ffbz81U0Qh9BTT0Xn/nuzpM9F21TkTr\n1q0i91OdjUrTNfPvWW4tC43G3yhibZIZM2e6UUfqyN3Mbi/4/fVvmunz7+J/XQeU0vOoc1/rNXXq\n2DE+w+yTsWNdZ5M6/6Jo39V5tflmm5VaWF40clud9Mm2JTrm4+1+LbadX+02bme2sR1O2tfZtvGh\nz1cnp86XtlnXdsIGZ+B55UbnXJ3b9957n5sNpRHcBx98UFFHnt22OtcefVQdvI+6NXcOPeQQdz4n\n/TLJBXNqr1bbrL/e+m79q1TW7VAH1/fff2/+tJ3O7jxu2NqVkWCnk2ZWaEaSZggkW7NL5UIzwibY\nzmMF1hRs3XTTTdyaawqEKADhp2P66WefuQBrMEXnvHnzzHh7XLR/q1aucum6dIy8jvBEdI1rHSHN\npvrzrz/d8VCnso59MECo92r2gK7bXXbZxf1d507Xlka5q0O6tu3U1AxNBYTVOejRedXsTu2/P3ib\niM6VOl6VWmzZsuWmod03BdgUAFbZ9yjwoLRoLkWg/brNbWesZnP43yNR5X2xPd6adaY1s1SGtQaR\nZjaeZQOgB9rOda9cKeWWArwPPfSwGWoD9D16HFqq/IZRedR51WwhBWgVUFWq1tb23qPrQ8dN50D3\ntvn2zw0bru7uSzqH3jlQA13fcfr0P9z31bFVmUm2Rp32T/eL4LXot9B22v9ir01dy/qz2z+7fd2D\nvO3rulMauuCx+8VeUwrgaAasf2avK5M//ug+xwsmzCpex68oeNPU3fs1S0llVwENb+0q7bOude8a\nUNnRzKd1mq1T6h6q4I3uNerkbpZkxoieJzoPf07/0+5TM7d9lXd9Nx0f//VcdF1McrOy/prxl6lf\nr77bP637490zbrrpZhesHTnySXc96/wtXbbU3bdV/vz3Sz1LtJ1W9ph63zPI26bKidafDG5Tx0Ez\neKZOnRZ5H9N79Bl6Jik9qQJ1KktKoRs8/3qvytTvfxSlh21krxeVf11fXlDbHWN7LidOmGim2v1q\nZMtmu3Ybu/OnmWu61nXcFehRgEBpGu+0QbOosqYyoACJ7p/++4O++1j7XPWXF9G9UeWjhi1busa8\neokCQOPH/+CuLX0/DXpRmdNMSe/+kqjcuBlw9n6tz/Q/2+XMs/5nPvjgA/PE4yPc55YwJXy2lZ6R\nmoWkAPYyWwZ0Plq1bBVfI87N9Lb3SdVdmtmyvv76G7h7uspWi+Yt3HWmtUV1bvXn4HVdNHvqL9Nc\ndaF69UscH5UXzayqVaumPRfruPu3yonutd4odl1zuqb0+/5zq/uRzv/fM/929y/VqfT5k3+dbO+j\nzePHZvlylb3J7hrSwJO1mq7lzr0+V+fDPytf29GxnT37H/dZKp9KxSkrV65wzxrdMxbZ99W1gSHN\nqlMZ0v1D15Fmi2k7KpPaV5WTli1alnymtty/xPHRed+py86uLnDCCce78jhj5gx3rNvastbMF5xN\nVC78dM50HJWSUfcGlUvdk1W/Uzl09xP7/NZ9U99Lx1vXjspjsG6g56POv+oHouO3ySYbx4PG+q6a\nSa/6pgax+KnetMAeK5VV79zpmKtOo3XsFPxMZ8ZbtqrMNgcA+PkDYHq+KvsE64Alp8GNgwcPdmuq\nojQ957V+mGYVeuuHeW2j4BpiBMMAAKmqtU43U5EIhCVQ3RqlXiDs7rvuNPvZ4FYiXiDsogsvNP36\nnWpQNbrutbfrOHvh+edKBT2UnuvoY441l1w8yJx88skGSNWhPQ5znctjPh5dKvirxs3xJ5xoLht8\nqentmxmE6keBsIdd6pxnTZsNNzTVmWbhnHba6W6mpNavy1UKbnTfZ18XOLz3nrtLzxaekjztIDIg\nIhB2+mn9zAUXXGCQewiEAcgE7z6jwSga9NKrVy83OE0pEL3BsQhHICw1mu2vlOcafHTvvfe68uUN\nkPGCYd4PAADJVHQgjBwiQA7T2isaSa3Zb95aGwqMaUaJZvUUFNSITL0JRNEsDjWUlY5V5cmjUf0P\nDn/IjcrXrBgARQprFJrjjz/ebLf99ibXeOl0NZPphhtvcjPLlMo3KmUuAADIPV66Os2a33PPPd2A\ntoceesgNciMIhoqiQKHKmIKsSsHuXz9MAVjvx782HQAAmcIaYUAOO+7YY916OGf9739uHZPVV2/g\nUoYpbZZSPvXrdwqBMKTt8MN7mm+//c707z/AtFa5atCgKAWkbdQssx3mp55yilv/B0CRPffcw/3k\nIi12rufInNmzza+//WYOPPBAtz4YAADIXcEAg1Ld33rrre5HM5uUBhGoLEq1qaCYUm9269bNnH76\n6W69Yi9NosqnP5UyM8QAAJlAIAxxTRo3MZ077+imsSdTp25ds+OOO7j1IFB19t13X7N2s2Zm9OjR\n5sfxP5qlS5eZtm3b2Q7ZrmbXXXdx63mweDzStVfXrqbZ2s3MBx9+4NZB0poyrVu3MrvYzvE9u+7p\n1jeKWgMJ1UerVi3tc2BHt3YdcpvWZVp77bXcrDYFwrWeKHKHZn/vtNNOZqON2hoAAPwUcFAw4vLL\nLzcnnHCCm63DOmDIBM00HDp0qPnf//7n1g/TGtze+mH+PgoCYgCATGGNsATI1w8AAFCMNcKyQ2CN\nMOQ+2hwAKpKXck7rgCkAoXsM61uVD2uElZ9Scao8dunSxVx88cWmZcuWJdYN8/8ZAABhjTAAAAAA\nAAA4XvBL6y9p1tehhx7q1mlSCkStA0YAB1VN6RJVNrfddlvTvXt3c+6557r1w7w1w4L/ZYAIAKCi\nkdsKAAAAyTETCQCArOIFC/TfOXPmuDXAHn74YRd00Awc0iAi2yg4e/DBB7vZYQqIXXTRRS49tzc7\n2j87zPs7AAAVgRlhAAAAAAAAOcSbNaOf559/3s20+fbbb837779vLrvsMoJgyFpaP2z48OGurN51\n111u/bCvv/7arFy50pVn/Vczw4SZYQCAisKMMAAAAAAAgBzhBQe++eYb079/fzdrRjPASIGIXKKA\n2FdffeXK7pFHHhlfP6x169bxFIneumH+mWHMEgMAlAUzwgAAAAAAALKct4bS7NmzXYq5PfbYw6WZ\nYx0w5DJv/bA2bdq42WFKm+jNCguuGUYQDABQVgTCAAAAAAAAspgXELjlllvMRhtt5AICCh4oIAbk\nA6X0VJmePn26C4hpvTsFxPxBsbDgGAAAqSA1IgAAAAAAQJbxOvr1X62nNGDAANOkSROXTk5p5YB8\n460fpjXDDjnkEHP77bebkSNHutdr1KjhfhQE1jWhP4uXQhEAgESYEZalFi9ebD4ZO9b8/PMEk88m\nTZ5sRo/+2KB6WrFihfnss8/M999/n3OjuX799TczZswYs2DBAvd3jUr79rvvzOeff87INJQSLC8A\nKsaff/5pPvzwQzNnzhyD/LV06VLz8ccfm6lTpxoAqC68NoVmyCgFYu/evc2wYcNcGkSCYMh3W221\nlSv7WgNvn332MX379nV/Vx+Cf0aY/gwAQCoIhGWpqdOmmTPOONM8+tijJp89+MCD5uRTTjbIfaqU\nHnXU0ebtt99O+XcU8L3iyqvM5VdcYZYtW2aylSrbvXr1Nrfddnv8tZdffsmc2u808+NPP7m/L1++\n3Nxyy62m/4CBZsmSJe613//4w/SxFfZRo542qN6C5aUihJVLVC41th98cLgZNOhiM39+9Qhqzpgx\nw93bRox43JW5ME8//Yy54YYbzaJFi0ymvfvue6ZX777m22+/jb9289ChZoC9F+sZU13oPJ3Uq5eb\nLZAr0qk3zJ8/35x11v/Mww8/YgAg33kd/FoHTKniFATT+l+aBcY6YKhutH6Ygr9NmzY13bp1s22f\n20qtH+YPjDEoFQAQhUBYFVOn0SOPPOpGNPvpQb506ZLITqd8oeDHksVLDHKfRmmP/vhj8+lnn6X1\newogKXCUzRVW7d+7tvL9zrvvxF9T5XupfX2V/a9n+bLl7jXvu/zzzz/mo49G247ad01VeObZZ83k\nyZNNdTXxl1/MYyNGmEyK2mZYeSmvsHKZK9SYfe+9902u0bNZnVDquJ8zZ7apDlZv2NCM+WSMG7Dw\n5Zdflvr3H374wQy2nXQffPihqV+/vknHF/bz3nrrLVMeqiepvrTSNxr4s08/N+/ZgNDcuXNNdTHH\nflcFBdN9BlelsHqDgpePPvqomR6oF8vSZUvdDwDkK39H/kMPPeTWAdO9UiniFBBr3LixAaojzYAc\nOnSoG/Azfvz4UuuH+YNhQjAMABCGNcKq2M8//2yuu/46s9lmm5p1113XALmqS5cuZtRTT5kOHdqb\nfNOgQQPz0ksvmqZrrpnW77XffHN7TEaa9dZbz2SagnB33HGnOf+8c82GG25oqqMnn3jCdrKOMcce\nc4zJlExus6zlsqqpYXrDjTeZbbbZ2uy++24mlxQWFprBgy81s2bNMi1atDDVQb26dc1p/fqZPn1P\nNqOeftpsu+227jiIzuUdd95VPFvnzHQ+1gWwHnjgAVO/Xn2z1157mYp00003uCBYdapXtbWdpZp5\n2rJlS5MrwuoNk3/91Vxz7XWug2s96sUAqongOmCXX365W+/oueeeYwYY4OOtH6ZA8ZAhQ1x67EGD\nBrn2rq4Zb50w/ddbP8z7OwAABMKqkEa9vvjiS2bhwkXmt99+c52atWvXLtWJoZEtGnGtdInN1m5m\nNt10k9BR16o4z5w504z/8UdTWKPQvW+ttdYq8Z6//vrLrbOgDrwpU6a499aqVcts0WEL06zZ2u49\nWmdj3LhxZpX9vHZt25rWrVuX2pY62X/88Sf33jXXXMO0te8Lbuu/9/1oli9f4To61rQdtlGVEO27\n0j9o3+rVq1fi39Rhps6ROqutVqLz0f/5m2yysVlnnXVKfb466MaP/9F2XP5tGjZs5N639tprm2R0\nfn6ZNMlM/2O6qVOnjtlyyy1CR+FpNp8+XyPSmzVr5jpvEo2K1/5Mnz7dHbN58+a52QVLly5zI/7a\ntt3I7b/Okdaamr9ggWlpv2+7du3ceQrS8deMnxkzZtrj39QGVDeLb/sPu98LFsw3bdq0KfW7+nyl\nJGrUqFG8o1DlR6mVlLqtpu3k1PcIntNptgyqQqnAjo69RidqBNaee+7pZnY1btzIfXbw+//7779u\nP6dMnWoarr662XjjxOfg338Xm99/n2ZWs+e7efPmbpvajs61yq3Oxwb2dZXPVCu1+m463io/+n2P\nV+70nRo2bBh/feHChXYffo+/Xtsew3Tzj6vc1rWdyCtX/vd7Om7aD13nOi46/yoTG2ywgdliiy1K\nVNg92g8FzXUM1l13PXs+i27dNWvWdNen1ynt0fs0G2KKva9Mm/a7+ak4HZ/eq2PqUdn96aef7Z9i\n7nyn02msbfzxxx9uBtRK+z1bFJdT//5rxqfOu9bHWm+9dd159x970bHXMdHv+/dN5VHfW8dc/+Zd\nFxoVq+tc94ivv/7GXUte2fefP73+2utvuGPkff/Vbdlbf/314+9ZsmSp3f+J5ndbrtWo0jXov1a8\n7em61v1Zqdd0XbVo0dy0b9++VNkL26b/GvOobH3zzbf2/C9y29V50e+EHePfbHn/ZeJElwpEx0/7\n4RcslypLKusqX9o/la+ZM/+2v9vO3XOCVEb1HXWt65jqWTTRbk/7rPOp8huk7U2y90bdD9Rts4nd\nL/9xFT1rdE/Q9avz+5W9V2g23A477ODWhtR2dG/zjlM9GwxZvPhfs8Yaa4Q+S7SP+jyvkRtF90Tt\nv4IguvfpOASPrf8+pjKmNQr1nnb2e7RMIbilY6ayqvPjfbZ3TPS99Gddz8H7drJ7mK4nPXeC17Q+\nT/dr/U7wOOuY6BgqDWsr+12DZdgzYcIEu29T7D6scOdW14vqG6nq3Lmz2W3XXV2d5aSTTjKbbbqp\ne11rPL7zzrtmV/tvu+y8c4nf0fUzYcJEd+70bNP58AfQNJr3008/M9tsvXW8HOi5oDIQRcdQx8+V\nUXv+NrX3rTD6fJ0jHTvvnlR0jibbn19MgX1tA3ssdU0Fy0ei56qfrncdVz2vVM6D92VtT5+j+5eO\ntcqZzrHO4ZZbbhn/nKI6ynj7vF7orlN9VlgZV7lTneQ3WxZahpxrbU/3g5W+TAL//DPbPm/mun3Q\ndvTM1n1P95127dqG3nf830v7utpqtUt8r2DZ1PnV8dY2/P+m76p7nc67fzt///23uydo/4P1Bp3f\nkSOfcq/rWtI9W58ZrBfrfXomTp06zf2+zmOTJk0MAOQafwBMz58BAwbYZ+2LbuaL0sEBCKfrQz9a\nM0/rh+2///7mzDPPjLeBVP9TPcUfHAMAwNRstnesIn/yiXF10sphK7qx/Q84ILZB8xYlfnbYsXNs\n1qxZMRugim3evn2s32mnxY486qgS7+mwxZaxt99+u8TnLViwIHbBhReWeF+bjdrGHhsxImY7T+Lv\nGzBwYGy33feI3XrbbbHWG7aJv3fDNhvFHn7kkdgjjzwa22STTUt8zsUXXxL/fduxHbvppptjbdtt\nXOI9LVu1jt19993x99nOvNh1118fa2M/17+NW265NWY7POLvO+ecc2OtW2/o/jx8+EPufbfffkep\n4/Xxx2Pcv/XvP8D93XaSxG6/444Sn9/Kfs7Fl1wSW7BwYfz39JmbbrZ5qeN8881DY1F0vO666+7Y\nZpu3L/E7+vsLL74Yf9+iRYtiF154kfte/ve123iT2Pvvvx/5+aNGjXLve/qZZ+w57hD/vRYtW8XO\n7t8/9sknn8R2tOXA/5lHHXV0zAZsShzfs876n/3ObUq8b+ttton98ssk954rrrjSvfb88y+U2oen\nnirahxtvvMn93XaQxc47//xYS7sP3mdt1LZdbNgtt8SW+M7X4UccETv6mGNjI596Kn5cVY50zMZ+\n+qn7+2233x5/v+2sir340kuxLbfapsR+7th5p5jtjHbb7dZ9n9gBBx7ovpN3XI8/4UT3vnvvvdd9\nhu0kjO21d7dS57HLzju7spCKm26+2f3OK6++WuL1I4440r1+5ZVXxWxlOf76Aw886F4fPXq02wf9\n+YQTT4z/u22gxtrZ60DnS5YsWRI77rgTYh07dnLfQWwA213Hgy6++L/fGzbMlRHb2WePy9Ylvs/+\nBxwYs4Gh+Hu1P5dccmmp7+39bLNtR3e/COo/YEDo+7/88sui823vF2f973+l/v2UU0+N2SBdLBkb\nyIgdceRRpX5fZdvz4Ycfxnbq0qXEv2+x5VaxN954IxY8L7oObICgxOsqD0cffUzswAMPcsfWfzxv\nuPHG2PHHn1Dqs1999TX3vu/t+3RPCu7f8SecED+uH3/8cazTdtuX+Pceh/V05dLjbU9lQffi5i1a\nuvcNtPctf1mRMbYchG3ztNNPLzrvKi/2vOv7Bq8H3eNtULLE59nO5dghh/YIXN/bxl63x8/bdli5\n1H1F9yod5/32/+8Zo3tvGBsIinW216PK/7777V9ie506befKv997773nnlP+9+keoPuN/5icfXb/\n2KE9Dos9++yz8Xtp+w4dYpcNGeLu1cHjdMYZZ9p7SvvYMcceV2ofdf71Gd26dS/xPAuWF5WLtva+\n5f/c/fbfP2aDLCXeq/uY9m3o0GHuOel//zkh5zZI323nXXeN2WCf+7vKTM/Djyj1nTra42eDCu49\nqdzDTjzxJHdN/x24pm1QL7b9DjvGTurVu8TrNjAb67rXXiU+r9s++8R+9H1fPTcOPuTQUtvdsXPn\nEmU9FZ+PG+fu+2eceaarC6j8HWvPl87/Z599XuK9Y8eOjW1r74Xe9nTtqJyrvInuFS18zxvv5y5f\nPSJIxztYH9KzZMjll7s/v/Puu/H3evdiHTuxgcJYz56Hl9rezrvsGrMBF/cefaeo5+onn4yNf3aq\n92UbsHN/f+6559016v37ueeeF/+c4cOHu2et//dPt9eC/zkgKsO72DLnf98+++5X4r7pbe/ue+6J\nv2Y7h9x5eOihh0s9bw46+JB4GU7ne/mp7OoZuvXW28RscDL+uvds1+8F60P9+p3myoyek8F6Q/D8\n6qdDhy1sveYXV5Z1P9bxOfa440q8R+XyzTffiuWyymxzAMhOuu/qR8/TSy+91LbDWsYGDx7s+gmQ\nfXbbbTdXD0b2+fXXX209+kR3Dan/QO0C9TmpnqK2g3686w0AkFsqOm7FGmFVRKNcbxk2zBx99NFu\ntMrNN91k3nzjdfPYo4+UmHX00ksvm7lz55kHH3jAvPP2W+aqK69wI2xtR4pbH0Y0Mvbqa64xTz45\n0hxxxOHmlVdeNqNGPWW23WYbYzuIzJgxn5TYtu1QMHfeeZe5wv6btqlta7TypYMHu5+ePQ8zr7/2\nqhn55BNuJO9DDz/sRn2LRi3bjnzTqVMn8+ILz5uPPvzAjHjsUdPrpJPMNttuG9/Gffffb2677Xaz\nx557mOeefca88PzzZhu7P7aj0u7fK6HH5JBDDnb78exzz5V4XSN5nre/r9HdBxywv3vt5ZdfNtde\ne12Jz9fCqbazxzz44IPuPRMmTjS209m0atXSPDXySTP6ow9dmrrevXslTMel0cdNmjQ2e3Xtaobb\nz3r/vXfNfffe416/eehQN5pZbIe0efSxx8z+++3nzs2777xj7rzjdtOjx6FutkgytjPVHHPM0eYV\n+10eH/GY2bB1a/PMM8+ao44+xrRs1co8+8zT5qUXXzD77rOP+Wj0aPP4E0/Ef1czAxo2amj62O/y\n9KhRbh8vveRiN6L8mmuvce858sgj3H+fs8fGTyOvbXDKzZ7ZZ5/ubgTiXXff40ZhH3744S610lP2\nOCn9lQ0YmrfefLPE72tWzAUXXGh27tLFPOTSEgwvNSPJY4MDxnZw23+vYa644nLz3HPPmrvuutPu\nd283sylII961Do3WDzpn4EA380DXxxVXXeVmcdx0043m49EfuWM2aNBF7voJG9EeZvvtt3fvtR20\n8deU3uzH4pkIn372qVuzz6M1S3ScO3bsaCqaZoKde955Zt9993HHRNfb8ccd50brq4x5Ro162gx/\n6CFz5BFHmJ9+HG+vvx/MySf3df/Wr18/V6bXDEmLN3DAAHPNNVe7P196ySXuOtfPpsWzOIZcNsQ8\n++xz5rjjjrXXznPmebsPRx55pL02XzX9Tjs94b5rps3p9j26Jxxjj/8Tjz9unnjicTNgQH+zyy67\nuvfoPnFqv9PcbNdr7b3pjddfM3fYa0PXd+8+fc0XX3xhysMGdcysf2aZRx952Lz91lvmSlu2NMvh\nCnt/1EwDXUuvvfqKm1mimQ/e97/qyivd7+se2KfvKbY8FLr9euvNN8wl9vrRjI1LLx3srhE/G3Q3\ntiPcHcvHHx9hTrHnIDiysIO95sO2Oeiii+Lv0Xm/3d4X996rqzvmL734ojn4oIPM6NEfmzvvuiv+\nPs2ku2jQIHccL7roQrd/d999ly2Pq9njPNDNDkqkqHydb+bOmWOuu+5ae45GmIPt/TUR23nurrXh\nwx80r9pnyIUXXuDWHLKdzm5/PM3WWce02XBDM3TozeZte9/TZzdv3sLdC22gpMRnaibzhRcNMp13\n3NE+w+4399j7TJ/efcwD9vmg2R/77btv/DhdNuQys9VWW7jrU884v7ftvVWzWXbfY/fIe83jjz/h\nysW2Hbd1z1HdI84771w3A2jAwHPsvXFBifer/Oo5dcEF57vjq+edro8nR440r772mkmHFuzWzLtz\nzz3H3rvedd/nSlsWjz76qPjspoq4h/lp1o4NzrrZfnfdeYfd5htm8KWXmsn2+w60ZcT7vtffcKOb\n4X3hBReYDz94310vN9t92H//A0rNLktGM7c088sGnM13333nZoJ9Ys/XAfvvZ8/dfzOc9D31HFN5\nuufuu1050bEZO/Yzc77dD28WseoOq6/e0HTbe+94OTi8Z8/Qbes5dd75F7hr5Qh7P3z5pRfds79N\nmw3Nfffdn3C/VYe44/Y7zJfuHJ1rPrT1Ft2TdI4OOuhAN7NMNLsq6rl6/Q03xD/Puy/r2v3h++/M\npF8mJrwvX2nvO5q9etngS+2zfkT8vVoba8jlV9pjt5V9/j5pj+sr5uijjnJ1pBttXcmjc3n4EUe6\n2V033HB9/H6l2Wb97bnW9Z6IZoiqLnjQgQe646b7jp49X375lX0e3xWfURr2vS4edFHk9xKV3S5d\ndjI2eGt+njAh/rpma2mGpLxh6xCx4hkPesaOs/d/PY+DM//l6quuds87PXtvtMdcZeLpp0e5WXKe\nF154wcy2x+Jee8966603zTD7zFS2AN1DNMMYALJdzLcOmNo8mu2u9G5Kicg6YED6vHSJuoYet21T\nZTrRn9W3oHqn6jreOmLeDwCgeiI1YhVRZ54qvc3WXsv9uXXrVvFOaj8FZO65527TorgTQKmWfvhh\nvAuKKG2MHvLqbFAARYGJ6669Nt5ReIPtRNjbBocUGFJHhb/jVsEgBWFE21Vaonvvu88Fky6++OJ4\nyiR1Evbte7LruNhuu+1cygZ9jjpRtradYqKKxy677BL/bKVoeuKJJ+2/b+U6Mrx0ZeoAPNB2xDzy\n6GNmb9vxFUw1pBRi3bt3c6mX1IG6+eabu9fVsa00b0q7o/RM6hC9+577zFZbblni89UZrnQ+zz77\nrOtIUZBDHdq777a7S8el/dZUef05GXW06cejgOB7771vA5MvFadLWsvM+GuG6+g79NBD3HkRpX86\n4IADTCq2266T65z0qFP0pF69XRq222+7Nd7hpA5EdTAHgwcKZPqpPL3/wQfmu2+/c39X2iEFH1UJ\n1LFQajX5w3agfvrpp67zTedeqQFHPvmk6Wo7JhWs8tLTNVt7bdf59vwLL9rz0j3eWatAyGGH9TDX\nX3ddaAoujwK1t9vOR6VWu+vOO933TUSVU61p9aQtO6fbDt7TTz/NbVMV1d+n/e7S0XW35VPnW9nL\nttiig0nHRvYcqjNNnX/qOFQn3A820DB3zlyz0047mbGfjnVp0nRNqSP+yy+/tOVtx3h6rYq2nw2g\nDrGNXe8Yat0hBYG//OLL+Hs+HvOx+6869L3r5dRTTrHBs+fdNRuWtk7Uwe2leNNx899bFMhUR7+C\nylfbznmPAp8LbYfry7YT9jsbEOoQEcxVsOx7e3326dPbBYa8+0oXeww9CqzqOn3EBqp2L17XQOnF\nlEJvz6572cD9teYZ27lZVkqfduv/2TsL8KiuJgxPi7u7OxR3a3FrcXd397a4U8HdW7TFHYp7kZ/i\nUlxKcXdn//kmOdu7m91kExIIMG+fbcjm7pXjO9+ZmVGjpF8ChBODoDlnzm9i9MW18MwwpqKerc+P\ndgYB5NWrlywS/STjJkAfRjubw1+eDrORP6dFAMWzQAwvXLiw23tCyEJ317RSlAV2iFOm3CB0IWwg\nQiVivEJ7g+iGV8cOHaS+cSzaJeIQtmvXjv5Ys0b6iDvwpQ8iHwRKqwHZNyDYQFBBSD+QMWNGevP6\njQgAItDXrCHvIxTdbBYwDGm43Dp1bE9t2raT8TdXzv/6OYze2OCAzRZWseeN7Y3MUzFjxXQop6os\nguC5ly5dRnXq/JdjDe0dVK5UyeW9I9QovvSiHYwbO9YuPmGMiMLjRY+evaTdms0BBgjGjRo1tP/+\nw+BBLBhWEuEIIp2nXOJxI2bMGPysFSmRd/lZnyuwxjAr8+cv4PHqspQtQsF4XTOthKScNHky/cki\nC8Zt9AeMMQ0bNrCPFyingID5rm6dOrRp0ybZZHL3zl05dytui9a5YCT3TYS2mzhhvMxBAOI0wrBu\n2LCByxdCSC7pc1hrIKSdu/5iQJ3s3r1HckphrjchVrFZJW++/PLc7kCfv3b9mpR79WrV7GGgMU44\n425exbrLYMbl3r172dcfvo3LT3kunDH9V4dNFRCXJ02aTHHjes33mPcBxDmMZQsWLuL5eICU+dRp\n00TgGcPHQaQCKDusRZBjDWWKtZVvYM0F8cz0wx8G/8Blup/H8uMyV2PMcvVczfm5Jk2e4ut8g41R\nqMfd3HdNv9m+fbsYciNFiijhL9FH8TvE/fv3H4g47opkyZJKmYTg506ePJnLdiHj/+j/xn/MK1ev\nXeVx9WduB9d9Da2pKIryPrFZwiDie3yjRo0k3C9yHWkeMEV5e2CXgriMPoU1DNaNsG2ZVB9YE2Jt\nZbWLadhERVGUTwv1CAvmQHyK620gMaRksQVAwAAwbMOwj/wvf+7cSdvYAIHX338fF4MAhA/rDvvQ\nYUL7yOWBRQOA0dqaN8QYGiCkyLVZXIEgNWjQYNlhfPToMclpYuX8uXNioINh5+ChQ/b7wYIfxhZ4\nMzh/xtDQOxb6jJkz7e/BGwBGLhgxYSSGMAZjSnQWiqznR76zaFGjiECFY9KzkQueCxMnTqSObPCE\nt42zp4dvwIgLUQ+fg1Hn8xCf05OnTySvj5RV4UIiTsCDBt4UyIfhn91FxVkQsJI0qdcCDcYy667r\n6NFjiKHwARuPrJ4ZEGdQLyhX5BPDTsIwocOIp4yhfr26suCzepMtXLhQzoO/YeGHXeU3bt4UTw94\nQdnri7+Y4T6Q/8NaXyiHVi1b+iqCAeyiRz6cDCxo5szpu1fVM66XUaNH0zgWzNq0bUMdO3awG+xw\nj+XZ+Ic8bA0bNqKN3B5gVPMvMJ5B3DG5jVB+q9k4njRZUqpfvx6FChmKVq1eLcdCBIP4UYxFi6AC\nBkNrGaLfYZGO/mowucWsQtybN15tDIbmgHCE+yzGgwoVKvr4G4zl4DCLMu5AW4NoDYOsqy8OuK/9\nLNrCKzKbt1hugPEWoiOM2sajNSB88UU6MVBbSZXSK/+V8dh0B8ZKiE6RI0cSwci0d3hnhAodSvqG\ns8cVRP/8FqEvoKC8Spf+xqHc0McwTj9+/Mju2YH2h7EK/R7eoOYeH/Pfw7Ix+syZs35eC54lnopg\nAEJ1HKe5ply5slzXUbnNHHF4H3WHMRkedDv4/pA3DTh7ciF3D8Z0Tz2e4BmEuWjmrFn2Nn+Vr7Nx\n4wYpf8w/rsB4f+r0GfHOdTaCFy9eQoRhzI3W8RnzYIkSjmOwyaEGLyv/UKFCBZnzanKZz5kzR+7H\nSmCNYQa02127doln+fMXz+3tA68wYcPw9T63CzfwKMZzlyz1tYi8WDe8zS5YbA7As2zbtl0Ec3g3\nOeee+/PPnTJGPOI51NwXPMfChQsrc8m5c363X2cgDmHurcRiqDXPINoW6t03MM4WLlxExvQ6deuI\n0Ip/u8LdvPrAUl/+HZexySS7xWMeQLBBri+0TYhM1nJCDjeUE9YUAOIwgDhlHa9C83iF+d2T8aAM\njzvWfhg9ejTJ74rNTWZd4eq5cH53z2WAWIV1Ie4dY9gdPufGTZtlLQPxGgI51mzyLHLMY8rjRgjz\nBFfjf+pUZvy/QYqiKMER44WCcbdfv34yL2D9gDWnimCKErggdxj6FmxZ2EzYn+1WVs8w/LQK04qi\nKMqng3qEBXMQNshZcDDGDDNpX2ShAkA8+n3uXB/ngPEERhUYzUDE8BEokvduX4PxIosR0zHsTQjv\nJPPkvT6AtwDC0CBsz7x5C8QD46uvvqQG9etTXjZs4N5guLTZ3oihDAYxZ0KGCulWkMLucRg4EHqp\nP39JwH0hYTB2EsNICq5e9To/drzDUOXz/KEklBAMcePHj6MBAwfRH3+soWXLlotBu02b1lSoYEHZ\nDeQKGHzwXAiRBZEI5Q+RwtlwiUUVQnwNHDRQdiLDmwn3CE8ms+vIN7Dr2QrCBwLnOoDN/PPPHQWH\na9ev07Rpv9C6devE8I9yD8XlevfuPbJqE/AIiBKlr3jZtWndWoxU69dv5GvH5XrzEkNhwAVLliyR\nlzOo8xcv/jOCxYkdx6OQHTDsYxd7Av68XzutzrAR+8L5C2LghSeaVYwFKFOUD+oFXnPwQqlarSrV\nqV3bZXglV+AeChQsIGEhIR5HjhyFDhw4KF9E8+fLJx5z27nNwtMG76PPoJ0EFRDmnEF7ty7G0bfQ\n/n/+eQi1a9cWT0HTfvlFDLXtWDAMCNeuXpFrQKRwBgZYOea6a+8K8Wz591/xfoJI4wrUOTwgYBg1\n3oVW4seLK18+YJBP7O215h7XX0zQfp3bVIiQIez36BsQceBJcZsF49atfZYhxsmHDxzD6CVjcca5\nTQYEnCOGk1BjkjkDc+//eI/pAy0ee1ZevPBd0Mc5EydJQv4hYoSIPgSrqFzHYVgwwuYCc3/wMJ08\neYp4zeF2YYx3B0Q0V+3cHejL8CAbMmSohN7LnDmzhMV99eq1eKG6w8wJrq4VIUJ48QpDu4TB37TJ\n6NGi+2if9rCL/vxCXKliRXrx/AUL+RMkFOToMWOpGo9PjRs1so+VgTGGGbBJ4z4LORAeBwwY6OPv\nESNGYKHHa75CuGS0+cmTJ1PPnr1oxPARVKZsGfFgQj8KCM2bNaOVK1fxGBpRwula51LMn1evXpV/\nt2jR0sW9RXTY0OEpN703/sT3HqOsGG9n36hWtQq94nvDDuG27dpRgvjx5d6bNm1iXxthLp08ZarL\nedWKGZcRxrdrly7cB8LIZhh34zIEXOfxCkIcvKsxl7sKR4t7euA9DpnxAGGGXR333IPxwJWXFNZi\nmHN9ey70P7/mG6wx4d24du06uVe0zXNnz3K/qEA5c+bi/jCOy3S9rBEh4MIjz3hOBgSX438Iz8Z/\nRVGUd43V2D5q1CgxyNfn780w0msIREUJWhBqFKIYxGfYbnr06EF169a1C9PO3mFAPcQURVE+blQI\nC+bACOnXZIzd0TgGhjbsPHYGQo51of0ZT/gh3eRZcScOWcmRIzvNmjVTwhstRn4jNn4gD9nQoUPE\ny8UYF+vWqS07x53B9d0ZrnB95Aj58aefJPwSdhrv4+sgL0kSb8NuGO/d4BUrlKd69er5PL93CEQA\nQWrqlMnimYRQQwib2KxZcwkhiVxeroCg2L//QBZIskket+QpklNUFtUmTJhI02dMdzg2b948tJTF\nI7jgz5g5ixbx+Tfxv5HzS0KZ+YI7j6rP/ahviAjIY4RwSAjLiFCMCeInEA+XXr17y/sGGFgRNgte\nCghn9/TJU8nd0bhxQ3voI7O7HjmecufK5fM+2XgfJcp/wikMTp60ExyHZ3zugecPjsOufnhtwDMM\n3h/WHd/I/9GhfXtpG8gP8vvceTSQBU6EXJo8aaLbvEHOZM2SRYzEuA7CW8IzoXOXTlIW8PCbP2++\nCD3IbYad+v7xqPEvMLD6BQzs27Zuo/kLFkg4PLRtiCktWjSXnF4BIaR3u3vpwhj99KlXXVk9LpyB\nJw0+687gaNr1CzY6uzrGfg03YbYM8E549Nh17htXApvHcBmGCxeG4rMhfLLkxfLZ39A2rOCZAwNs\nLPDLkxIgBBmEvbFjx1AsF2NlZKeNDM7gifybdwrGdNSXdb6BgIL3wnkLNYcOHRJxAyIoQjqiP+Hf\nyI/V3IXoAe9R/95HWR6vhg4dRnO5L2bKlEnyZEo+Qxb13WH60nMXbRqiC8ZM5zaD+/JkHPMEnKuO\nzHflZPz95dfpkq8MG0EQEg9ixduMYdi5ahWPMAagniAIYC5DCGVnjFCN4xo0qC9zBe4N89SMGTx/\n7/2Lf053mWPQLxIkiE+RWNCC8BjFxaYatHHcG0Jtuv68/3KTgTBhvMYkVyIwQm36/fkw4vGKOoLn\n70ye55HvdNv2bTSL/w3v7gkTJ0qeUVfz6noWcgxmXMYGE+RJQ33gud2Ny67Gj7DiufeZrNmwdnMF\nQgOCcDweo0yRj9GT8coZfMaTfujquYAn802hgoUk7+Shw0foqrdXM7yC06ZNIyFBMafC6Hv69BkR\nuF21WU95q/FfURTlHWEVwLZu3SqGeIz72HSoHmCK8u4w+cMQ5QdhzMeOHUvz58+324uAEcTwcv4+\npCiKonxcqBD2vuFJ9m3zDyH3ESbsly9fieHhXUzcMMpABEKej4oVKlLrNm1kYQ8hDF4eMLrcvHlL\n8sz4Fxihhg4bJp472BENgzreM8BjKHz4COJ14sn5sbBBvjG8ateqSbVq15bFkCshDJ5qCFsF4xeE\nvRQWMebO3TtuywL5N4qyQWsmGxmxm3oeL676sPEsKMAucoSWy8xGYuRoMkZxGEtdhfSqXq2q5M+B\nQfnxo0cirpb1zikDkiZNIm0G+V4CUl/ugDEfHkanz5yWkG4RfPF6QG61fv36iicWvCW6d+9BU6dO\nFdHKCsSLli1bSgiylq1ayc79M2fPineFJ6BtJkuWXEJ6og1F5HpGOYIihYtIbjsY8xBqKmeO7PS+\nQT968PCB5MPr0KE9RWSDeqKEibgc4nl8DhOyy4DcYQiddvrMGR/h/kwIPHe79dFOkidPIaG64Ima\nxIXXEdojjPAXL1wQrwdrXhl4HyCEKQRaI/Ag7BjGQBMW0PD06RPx9Inn5DnpHz5zMb7CqAwDtwn9\nmTCh/43y/r2mf0EYj9evXlMorv/A7JO+ceXyFRFbrCLoWW4j8IxM6C1crFm7lp7w78j3WMYyhmza\nvIUCgnPbBNi8gHCqa1j4rVe3jniGIcyjc05JK7Fiec0JJj+iFYRtvH3njoQZDgyvPt+A4IUv2MjN\n2bNHD1q4aDH9b+9eKlqkiP0Y38Yw9He0nafoCxaBCv3IGsrPjK0QFhDiLoObfH5W0C8RVhACz/Dh\nIySP2O49e/yVC80TMN9iTXKO7w3jLTyzfcPT5QrGPPQtbORwztWHzQueAs8o5DmrUrkydeveXfLf\n7d69WzyDd7Jw6cm8asblVClT8jm6yXiWLGkyf43L0aJFp2jRvUITpkmTxte2ifEAbQT3lCxZUgoq\nXD0X2msy79DZvpE5cyap682bN9Ht23coRcoUEjIT6yO0f3jMIU8fPOuRp9VXMcu7UZiwjIqiKB8S\n1k1gCLMLAQxC2IgRIyQUoqIo7wfkR8faGdEBEDUH0XG681rQpAgxQpixpakYpiiK8nGiOcLeM9hN\njS/7JrxhQIDAgwl80aJFsjPfajxArpK3ycXjDIQihAwyhl4YvdKkSS0eZyY/DIwoMOysZQPfxk2b\nHHbEwZjnV24UGPiQw2wzG1f/WPMHG8LjSqJTA4zs+fPnow0bNvp6foSPQjgs6xcS7ESPHTuOl8uE\nC2Cof/P6jRilrMbs8+cv0P/+5xiGEeVgNd6jLJC7AgZb/+Qi8y9YlL1+7RXOyOzyxn1jB/fJk6d8\nHI9FH4QmeAMgrwg81TJ5iz8AZQJDKvLHwOPDWp4Q3VCOAQFG4VwslP7zzyVauGCB3aMB533mVD4o\nOzwL6rVJ44bisTVy5Ej7vVy5csUhRwkMgmlSp5F/G88m7GIfPWaMhLN0B4z8yIWExNQrWGhNmSKl\n3SMiR84c4qk4e84cbkP3JBfO++b69eu0ZctWEUMQ1hPG8vDhw0m78ysEVISIXqHuzpw94/A+wlMh\nNNXvv/8uYrUB4a+mTpkqBspcLjwDDfCcs3HfmDhhooQgBbgX5IRDO8Q1y5YpTddv3KDZs2fbQ29h\nXILHJOoH3n/my0Wy5MnkefayuGvGLvS9ZcuXsxB2hd4GGGavXLns0IZh3MVOXDzvlKlTHMYj9FuT\nDzEwr+lfChT4SvrP8BEjpQ0YUC6BPaYbDh0+LOODAWMpcgviOVDnwPRBq1cbxsG5lhyEngAx8vPP\nQ0gYNWtoNkOtWjWlHgYN/kF+r1q1iq/nQ3vOwULGug3rad++ffb3ITLACxjPgnxgQfWF1nl8wvOl\nT++1KcWMe56MYbH5OTCP7t37l71/4zMzZ832Macg1xzqZjgb1qzzEI5HmzGfd56n0D8h+qDcX3uX\nPcKUQhhDzrfAoDT3bwioQ4cNd7g2rolrmTqHFxVCJf57+V8/xzOETcY6Y8HChZKfzoB8jwil7BcQ\nZ6w57NCGMaZiUwA8CVFXpoz9mlfNuJwzZ07KzveFfKSejssGeETl47EYQinCNlvXbTiPdRz65huv\nvIKDfxjsMF6Z8SCw1huunisal7knz4UQyslZxN60aTOdOHGS8rLYZbwSCxUqKGWK3H8o07x+5AdD\nSFXUycWLAV8XK4qivGtMqDWA9QdCshUpUkS+o+P7uYpgihI8QKhERPNB9BkIYgMHDpR1mMkdZvKH\nWfu0oiiK8vGgHmHvGYSICRkyFP3ww48iGCBcTn0X4f58A0JGyxbNaeCgH6hxk6YiIsWLH49usZEb\nSdiLFitKHTt0oMAA4W369e1HOdlQjrA9MIgjFOCZM2fsC3wYtnr26E5NmzWXMFoIa5giRXL5UnD6\n1GnZKTzk5599NUrC8InzwqiCXCYmhwdAzhfkqzBhusz5HyIvBQtWodnA9csv0+RLBzyLMrMQBAEB\nhi/sgMeOcnflgZ32OVkQQUL377//Xr7AQExbvWq1j93JCxYsFLd6GHWwY/vu3TuSBwOGyKIuQlQG\nFjC0p0mTVnaxd+rUWXZiX7hwkTZs3Chl8/z5U4fjUc5VqlShwd5GZXheWcMkYYd8s6ZNqHOXrmyA\nrk2F2OidOFEiusmGuPPnzlPu3Lnp22+7kn+BoNK0cWPas3uPGLR37tot3mcwzMIg+cPgwT52wUMQ\na9GiBe3Y8afs1oKhEgbf2nXqSqitLPyssWLHplNch/DcQu6V1N7eYONZmPnnn4u+hlADEFWRXw1i\nQpHChe1GfYS/zMPPunTZMikf38SgdwUMiTAwwsMQIoUJ5xaTxbv8/BzwmHHncQHPL4wNU6dOEw8T\neMyUK1dWvDQ6cPvv06cP1ahZk9u4l3cF+tr5C+cl/49vuYO+4uuWYaFrGQuPFStVlvxqaGNnz56l\nJk2acH8sQPXq12eRejONGTtOckkhhN75CxfEKxH31LlzJ/v5UOZRo0aTHHv/sOETufOOsEEeYeUC\nErbNSs4cOej48eOSWycfi6wQKOrUqSN5k7Zs3UKzWGCAdyCEYORvguH1xo3rNG7sWA/yl3l2TbSr\nqlWr+uscaNcNG9SnsVwmVfizGGMgAkAAOHbsGH3b9VsqWbIEBSbhwoWn9u078HlLUqKECST0LcZ7\nXBtjAEDd//LLr2zc6SfhZuGtC8+tx4+feByeFHi16wSSL+g7HmdTp0pF6djoXsA7b2G5cuVkzMAO\nanxJhQjiGxA3mzZrSs15rmjQsBELB1+zqB2Ljhw5zOPkHgnRa54hKOjCYye8XnNkz8Zzb3y6/O9l\nCX8Ij0mICcCTMQw5JufPXyChgeEJFyVqFAkN/BeLe87lC0+utWvXSv5L9GOUEcYGXPvAwYP0229z\nxDOrK7eVx08eU+ZMmSWk4ZWrV0V4wYaTHNxWAQTPYSxawXNn+vRf6W1p3LiRbISZMWOGtFfMUZjt\n4WkL7605c2bL9bFpBOWzfsMGKcNUqVOJ9ys8hpyBIbFmjRoSvrA292HMsfCaXP3HavFy9g2Ikd26\ndaP7D+5TxgwZ+dpxZfPR6tWruexTSfljHMV6bPGSJS7n1WdP/xP0zLiMPKI7d+6U8MGejssGHI+8\njzj/93xv2JiRNl1aevzosdwbPGIXsegHEM5x6bKlsr6ofqmm1Bty82G8wtprzJjRlCkQPEddPReI\nHSuWn8+FuRz1hrYn+TgLFLD/DRtvEL4RdY/NQsjP5huZMmaQ9j5+/HgZ80J7e7FrSERFUYIrVmM5\nDOyNGjWS7zD4d1IPvGoVRXm3oF+6yh+G74lmzW0NlRhY4dQVRVGU948KYe8ZeOv06tmDpk6bJjkr\nYCyoXKmS5BNJmDCRS6MDdpLDWGFCjmGCrl69ulfOmylTROyB4QeTOAw8VgMJjoERyNklCgY3nDOM\nkzAB4wbeNzt7ESIrLhuwYKCEhxEWBcgf1bt3Lwk3ZIDYsGjhAtmtfvToEdq3f5+E+cK5vrSEY8MO\n+IQu8jAVLVZMvMpstjdivHdVbrNmzvBxfpRfhfIV5L4QYguGpT1cHtu37xBDNwQ1GJ+aN29GrsDn\nGjZsSPfu36d16zeIiAAja/HixWXHUI+ePe0LIQgl69av59c6er3GJoYpPB9CKha0GIGcgVCI43yE\n+uJ6xPuxYjrm+4BQg1xVVi+8H38YLCEY4UWDF3aXN2valBKwcXnYsGE+roncHwjbiOMQxtEZGIph\npB3DAsDevXtpN4tWIbg8EyVK6OA9Fj9efAnB6cqlLlzYcHL/US1t9gs2ck6bOkXOe/DAIdn9jvvP\nlTOntM+Q3tcwO/IBDP4//PADdezUUdpznrx5xINoydKlIuwCtMuybCxv07q13Xvv/PlzklMOoqRv\nIOwaPCKwsx6hPa1AdNvPAioWx1Yx6DNTN7Fi29+DxxXabnjvkI84BqJiQn4e8yxedZ3Yoa5j4Bg+\nl6ucLbimzbueIbwizxD6MvpwEoSw5P8esogI4+fw4cPFONu1q2uREiISBOnBXJa/zZ1Hofl62dhQ\nD4GnVs0a4sEwadJk8ZiBVwS8an76wX3uPAPKe8iQISJcLF60mJavXCl1Go3HkMjeueSi83iB3Hzj\nJ0xg4+0GOnz4iIxXCMv2bdcuMg4ZUGY/DB4oos8aNp5zZXI7Tii5jxCq0dS5u/I0oN2gXENZxrD2\n7duLJw7EuIMsnMPTAV9wME5MYCMr+vd67sMrV66SsQYhUYvx2IPr+HU9dzhfE+eDEObcXgwoO4S7\nvHHzhkMoDpwnQYKEEtZ048bNcn/YNJGRjcTWEB7O7TIs+iFfJ4ofecScqVixvNTLwkWLaOuWLRSW\n2wc2JFg3DcCTrifPVxCSkWsqbLiwklewEYtPEMeiR4tuPzYyjwMYy1xteEDfhxAOMRYCLLxQkL/J\nCGGY4yD0IWwdRHxPvnwWLPCVzAmjRo+RuQltGvNnExbjmzRp7BDy0d04hvtCecaMFdPXazk/G8aN\nKdyWFi9ZKr+jj+Ri4Q0bDEyeQb/GMAAhYcCA/lK+CA2MsyNH5YQJ42nu3LkyxhrwPKNHjaIZ2WeK\ncAEhBc+DOoEIYcbhIkVZ3Pp1Ol97CY8pXvNUypQpeB5sZ++H8LrGeAEhyhPgzZcocULx3HEF2vic\n2bO4T48TkQveugBjAMrKrGvwDBDlEXYYG1+2bttG9evVdSmEAQjoMWLGoHlcFtiIgtC5xYsVl3CU\nrbgcw4f7r2+ZsThEiJBSrxClZ86cLXUAgwbmVQhKjXi+hxALevbqyXP/PV/nVeu4DNEOHq1oa/CO\ndR6XTf9E+FdXoPwXzJ9HI0eO4rnxL9kAgHvFWFahwn/5VfHeJBYA0S4gsEL8xHiA8kOYSCMsubpe\n7DhxZC3pqg8l5PHlkXj1fub2ueDZhzbr13wDMNat4PkAOcGwfrO2B+R0XbJ0mYwX1hyHrtYNECS7\ndulM02fM4tcMqQfkUkN+WP+M/4qiKEGNVQDDBsxOnTrJ9wts5tM8YIoS/DH5w5by+rBjx46ynsb3\nXGxmw9rJ5A6z9nUNmagoivJh81nIOCUC1d/35bW19LHgPOkFJS9evJQdwPiC70lSc9+ApwtCz0FM\nww7awJ6sUSYIlQODSWg2uIQLF9ZXQyU8pGBMgbHPaowMLMz5UW5hw/q8F/wNZQLDFwwynu7owWfw\njDCGu/uMKQsIOeHZyBcUz+cOXNuEXzOG+8AAYZbw7GECuf2gLFEXAT0vQiqZ0FboJ9bwbDDUlShZ\nikYMH8ZCTmX6GIC3QvMWLakXG2ebNmniUF5Xr15lQacefR7iM1oP8cgX0D9QbuFctE8IiPgbRE/f\ncri5A20Qn8e94fyuvIIwFj3jeocI7ZvXkNe9POZ+HMKHWPS2oJ+gHJBjLaTTPeC6Xv3oMxEH/ePZ\nFNBrBuRcr169lvuztvvA4PLly1StWnX6ioWkH1k0hUEc10Mfc1cWpi8690P/8vr1GxEQUOfWMQzt\nqgKLG8eP/027dv4pIUs9xYzJr7leI/L9vasdnKYdoWxQLq5yPvk2hjmfC6FG4enkyZxi+jGe1VU/\n9Apd+pBecd26mqdwX/g7BKrALi9Pxoj/+qDXBoPP/ZgbcPwDvt9IfKx/+iueE5572GyAMcZVHfk1\nrwbWuOwMxgp4VkKoRDn5Nj/i/pBfLzDHq6B6rrdB1rL8Qnl8Ct5g7/I7h6Iob481DCI8SrChFRt8\nOgRSFBYl+IHNJ6hjFTk/XiBioz8jfxg8xCCUGTHMrJGtecQURVGUoCdU3JIUmKhHWDABxo/QoaNQ\nYAAjV1AKMpj4YcTz1EsCxr7ANt765/wwohjvOf/gSTn6tywCE1w7MAUwgxGqAhsYHUO/xW5tCJ3Y\n9e0K5DdCCDXsSP9YQKhUgJx7zottiEu379yi1KlS+3ke9A3j0ekMFvSR/ek5ZAX3ZQ1b6goI8mE9\naE9e9xKJggLf+ieu69czBPY13+e5/AKGdb/ahG990X/X+pzP43Pe27FjBx04cFC8E/0jggEzJr9r\nPGlHnpab8bT2z7V9qzOUiW9/x325GyPeFk/GCP/2QRwfNYr/10t4Tr88Jf2aVwNrXHYG47SrvuCK\noGjfQfVcb0NQr2UVRVECgjWX8qhRo6h///5Uv359On/+fKCsjRRFeX8gVCKETohhCBcPMaxu3boO\nG8WcN42pKKYoivJhoUKYoigfPIV5wZovb14/87J8SOTOk5sFybA0ZOhQ8aRDGC0YJE+eOEHTZ8yk\ne/fuU+06tUlRPgbgNYSwQsgh+NPPP4sw0rJFC1KU4ISrcRke4Sf+/vuDHpfdPdc/Fy9K/k2dbxRF\n+ZSxil9gy5YtEgYRm0iQBwwh+xVF+Tgw4RIvXLggKTMGDRpEkydPltDjEMFMzjBrDjGggpiiKMqH\ngYZG9AUNU6IoyvsCY8/cufNo2q+/0PVr1+nlyxeSswXeAMmTJ5PcR8ilF0KT9ypvAfKZITRiwYIF\n5Ive+2Lfvn3UrHkLNrjfk5xGXbt2lrxaihKcsI7LV69clVCiMIYg1OKHPC5/rM/1IaHfORQleGIV\nweD11ZjHw4sXL4qhXEPkfVpoaMRPExMu8csvv3QIl2gVw6x5nhVFUZTAJbBDI6oQ5gv6pVRRlPcN\ncg8gjxN26cMoiRBnceLEeaswk4piQO6+Y8ePU9y4cSkev94X8Ag7e/YcvXnzmhIkSECxY8cmRQmu\nYFy+woLR48ePJHwfvAI+hnHZ+bmQ4zAh90edb4Ie/c6hKMET5KXE2Dh69GjJA4YwiMgDpmEQPz1U\nCPu06du3r4RDbd26NbVp04aiR49uF8GMKAZUDFMURQlcNEeYoijKJwQMrEGVv0dRYODOGgxC+iAv\nU+bMmUhRPgQ+1nFZ5xtFURQv7y8jTM+YMUO8QSCCIISzCmCK8mkCIQw5xDAe5MmTx2X+MORa1lCJ\niqIowRsVwhRFURRFURRFURRF+WSxhkFEHrD+/fuLMRuh0dQLSFEUa/4wiOMIK79mzRpKliyZ3bMb\nP1UQUxRFCb5osH9FURRFURRFURRFUT5JjNEaYRA7duxIlStXFu+PzZs3qwimKIoDEMSQMxBeYl9/\n/TU1adJEfkeOVYRTNT8NGvpYURQl+KBCmKIoiqIoiqIoiqIonwRW7y/zglE7RYoUEiIWRm0IYYqi\nKO7AGIGQqRg3cufOTQMHDrQLYRhTrIKYNeSqoiiK8v5QIUxRFEVRFEVRFEVRlE8GY6CG11fy5Mlp\n27ZtYtSGIKa5wBRF8QSMFRgzDh48SJcvX6a0adPSzJkz6dWrVw7eYVbxXVEURXl/aI4wRVEURVEU\nRVEURVE+eoxnBvL8NGrUiC5evKh5wBRFeStM/rClS5dKeNUVK1bQzz//LO8Dkyvs88//80XQ/GGK\noijvHvUIUxRFURRFURRFURTlo8PqiQHPDOQB69evH2XPnl3EL4RBVBFMUZTAoEKFCjKmVKpUSfKH\nNWvWjM6dO2cPl+jsHaYeYoqiKO8WFcIURVEURVEURVEURfmocDY4jxo1SvL53L9/X4zVCGmmKIoS\n2CB/GMKuhggRgkqWLEkzZsywh0k0Lw2XqCiK8u5RIewTxyTx1Mk3eHH02DGqUbOWxJr+ULl9+zYd\nOXLEHn/fExCXH8+9Z88eepfcuXOHWrZqRcNHjPDX/XrKgwcPaN/+/fT8xQt/fe7I0aN05coV+hRY\nt24d1albj/bvP0AfC7e5XaE9//HHGnpfYNfzwYOH6OXLl6S8Ox48fEitWrehn34eIjkCwLFjx6le\n/Qb0v//9j94FGHf287gTEHr27Eldv/1WnsMvli1fIe381KlTFFj8+++/NHDQYCpbrjxVqVqNxk+Y\nQC/8OX4GBaZP//LrdPt727fvoAYNGwXq83sKymTQ4B+oTdt29OTJE3nv6dOntG/fPnr8+LFH5zj+\n99907fp18g8II3by5En6kNC1rqJ8uqDvb9myhYoUKULLly+nJUuW0MiRIzUPmKIoQYoJl4jx548/\n/pD8YQidiO8GRhTDT6DeYYqiKO8GFcI+ccaNG09JkyWnVatW0YfIx7pYePzoEf35559iDPxQGTt2\nHFWrXoMOHz7s8WdgwMNz37t3j94luO6uXXvozJkzQdKm8IW7QoWKNH/+fI8/AyP2N9+UphYtW9Gn\nwM2bN6Xur9/wn0E2uOCq3Tzzbs/IQfEurueKMWPGUMVKlWjDho0UXPkYv/i9eP5cBP3TLI6YZ7t1\n6ybt3LlL2vq7YPSYsVSexx2Ma/4B93vy5Gnaw4LdU29xxTfOnz8n7fyJB8d6whPuN506dxHDQfJk\nydiIkITChglDoUKFoveN6dNnLWV6/fo12rVzp2yoeNdIXZ04SXt277aL3du3b6cKFSvR6NFjfBzr\nzCVeY9SqVZv69x9AnoJ67tL1W6peo6Ykhf8QgHCHtW73Hj1IUZSPG7OmMC94fSEPGF7GQ0PDICqK\n8i6BIAZ7ADxQv/vuO2ratKmES4QgZsQw4yGmgpiiKErQokLYJ07kyJEdfn5IQGApWKgwneVFhBL8\nyJUrJxUo8BUlSpSIPnUyZcpEBb4qQJkyZvT4MxEjRqRSpUrKSwnenGMjS+IkSSXMTnC7Xv78+alg\nwQKyAzG48vOQodS8RUu755QSOOTJnZsKFihA8ePHpw8JCHeY38uWKUMjR46goUOGiAFTE4p7RsqU\nKalw4UKUO09u+3t3796jEiVL0dGjxxyOjRkjBs/TBeirr74kTwnDomShQgWpUMGCFDNmTPqQUMOS\nonwaoK9jcwKMzvACgxEaUScghCmKorwvMAZBnEd41rx589LAgQNlrHIVMlEFMUVRlKAhJCmfNJEj\nR2Lj0ucfZGgIhA989OgR2d58zAuED9fwh+SweClEWbNmpTlzZvnrM59//jlNmTyZlODPhvUb5Oe7\n+rLin+sVLVpUXsEVfPHbtHEjJUmahJTApVixovIKOO9n/rnLBgGE9cuYMaOKXwEgefLkNHPGDIf3\nzpw5LYYXHjUc3g8XLhyNHjWS/ANyXbRu9Wl4KiuK8mFhDMcIQ4YNFMmSJZN/QwhTFEUJLkCkhyjW\nr18/ypMnD/Xo0YPq1q0r617YAPAC+B1jmq6HFUVRAg8VwoIBCDMzZ84c+vPPnZIPKCkv2osULkxV\nqlSmkCH/q6KZs2ZJCJyePXvQsOHDadeu3fTs2TNKmzYN1a9Xj3LlyuVwXhgYZ/N5t27ZSv9evkxJ\nkiSh8uXL0TcsTpjJFQJY6NChWBCLYv8ccopMnjKVLl64QK/4HPHixZOd5TVr1qBo0aK5fAaEVkQe\nmlq1atK8+fPlHE+ePKV06dJRg/r1KX36L+zHYjJHrpTFSxbTyZOn6Mb16xSXr1GyRAn5vLk35Lbp\n3bsPtWrVUv49ecoUuvTPJSrMZQOj6fjx48UjonefPhQpYkSKEycOxYgZg06cOEHt27Xz4QGBfBYI\n14fPV6pU0eVz4N527NhBixYvEcPRq1evKXHiRFSzRg35HMp03779tGz5ctm1fufObYoXNx6XTU0q\nUaK4GIjA8ePH+f4mUPv27aRcEBLv5q1blCB+fCpStIjUl7Vu3cFf52jGzJmSg+Q6lxNCRFWsWJEK\nFyrkY0F0gtvGTD52/4H9Up/ZsmWldm3bUvjw4X29BnYhLVq0iHbv3kOXuf2FDRuWsmfLRk2aNJa6\ndwdESIRTQjuF99LIUaO4TM5SlsyZafjwYbRi5UrasnkzffvddxQndmwpW+Q8mzFjJp3msn358hXF\nix+PcuXISdWrV3O7sxzhnkaOHCXljfbx22+/Uxpu8506dnQ4Dt4kk1k4OnXqNHXs1JGSJE7s8nzX\nrl2jqVOncTkdkPrMmTMnlS9XllytL7EjC/eLUFP//PMPJWMDYzk+Fp4Kzhw6dIj72290+vRp6Zdo\nN7W4XSD8yu49e+jXX36l5s2bcb1kk+Nx3K/Tp0tfePjwIcWKFVPuBW0tQYIEUl4tW7YSY3Dr1q0c\nymMh19eWzVvoPPfRuHHjUoGvvqTatWuLUdOAay5etJi6du0ifRKh8RBuMVHChFShQgUqW7aMr20Q\n10c7XrR4sYw7N27eoBgxYlKF8uWl/4QOHVqOQ/jO4cNHULVqVenmzVs0b948Gcdi8vN8+eWX1Khh\nQ2kfVhBabO7ceXSC+yTa2Ndfl+Lreb7AR1vAeIi+hV6SNk1aqlevLmXIkMHh/lF+pUt/I4aQMdz3\nUeaRI0WiXLlzUfNmzfh5YjicF3ntfuF6+uuvv+ght++0aVJTPR6/0KZdIWPs7Dk0ddo0+b0Dt8kw\nob1CuI0dO8bhXtAf5s9fIGHUYsWMJZ5aDRrUd+ifaAeIH7912za6ePEfCs3nwTjWtGkTeQZPr2cF\nY/Pateuobds2lCpVKnnv5KlTMlbAOwT9OBb3Pcwf1apVo4QJE7g8z+7du+nXX6fTDz8M5nOulhwb\nyJeUOFEiKsNtqSK3KTP+GbZt2y7j/JnTZyh0mDCUkeunfv16Yqg39Yi8fKf47yj7Vq1ay7hWkdtX\nqZLuPSHRviZPnkKHjxyhly9eSL03a9ZUysgKxswpU6fSX3v/olA8z0GQRr1P5ffQlhs39vIyMs/T\ntWtXSpkyhf3z6GsYx69evcpfVPuKJwzA75hbjx49yv++Jh7VeflLbCM+XzQPN5Vg3O3Wrbu/xzKM\nQ8OGDeexKJnMc87zwNChQ8VLekD//pKLbNmy5Xz8UHsfxHpjxYoVtInHj0uXLvF8+xmXX0ZqyuM9\ndqdaCclzMZ4VZXj40GGZjzB+tWje3O1awLn80e+OHTvKbfeNzCstWraQ+cAVCFH7x5o1tGDBQvl9\n/oIF8gzwcGrXrq2UP8ZWjMkIO4mxB+sleCZhfWIti+ksBKG/9+rZU9rtau5XqM++vF7IY/GUsoJy\nw1rMrEtixopFBfnc9erW8XMe9QszTlatWpXu3btLq1av5vs7I/2nRMkS0n+cx2OE85s0aTL315P0\n5PETGQuqVK1C+fPl8/Va6N/DeY1YpUoVKlqkiNT3OG7Hz58/pwEDB1LUKFH5WiFowIABMo5jHkff\nQBkaMPfN+e03Xg/9SWfPnqFIkSJTBl7HtW7dWubqCRMn0r+X/mVDTh/7vIN+ibA/yPOItUSECOEp\nX9583M8a81rTa42JsbBnz16Um9eUyZP/Ny5HjBCB0mdIL2sW67oD/QRroF27dsn8EiNGdFlXlud5\nKEf27PQ2YF3Zq1dvat6iuYSvncdz0pWrPHfx2JD/y/zUmI3oznOXoijBEyOA4XtGp06d5PvhdF5j\nawhERQlaIDSbEPAQnLNkyaK59zzE5A9D+cHONGjQIFrD62C8b8QvI4wZVBBTFEV5ezQ04nsGuUJg\naO0/YKAYDhKx8fwIG/eQpL59h44OOTdgiILxtwobUubNmy+G88RsIFu9eg2fowHtZWOfAQnUYeSA\nweHyFS8RDEa71q3b0M9Dhtg9CSKxAQ8GijBhvIzaMFwiEfzevWx8YqNpCjZYwliJz7zwzj/hChgy\nfvv9d0lqDwM3DCMh2SgKgaU6G1dg+DbAGNOWDXizZs2m12zwS50mjdxbt+7dadq0X+zHicGOjccw\neNar35AOHz5CUdn4FoENJidPnBKjKwxzeJY33i8Y2P5Y/YcYfp2BQXDpsmUUJUoUt8+BnBp16tYT\nY3RoNjDDOAMR6saNG/J3iCgwPuO5YKROmTIVHWUjXzM2DGLhYq3XNXwPOBY5KT7ne03Lz/n333+z\n4agfDR78A3nCkCFDeVE0WAQMLCo3s/GyadNmYtiygvcrVa7Mz7eUhY5EUq7I//b1N9/4mbcFBsOB\nfI2r166KIRTGQoiObdggBcO8O2CQ3LhpE/3++1w2XFcWITd69OjyAqfYmLiexRcY2gGEW+QM28Ti\nGNptsmRJ2UB+Woys7nKrwPDfjw26EDAhmiGEwMV/Lko93WJh0QrKfOLEyeIpGJdFUVdgRzzuAddE\nH4kTJzYb7hazoa4JP+sjh2NhCGzAIg6EVgjJKVOlFLELxnpr7hW0PxjFK1epRgsXLpTPoY1uYQEa\nhjtwmY2gMMTCUAgg1qKvLFmyVIyKEIofPHhIo0aNFkHAnBfG0r1/7bVfC14SrbgPf/vtd3SE+wzE\ntivcv/uxIbMRP4O1THDN3+fOpfoNGogxH0ZJCAV/7dtH7dq35za0knwDdd+5y7c0Y/oMes3PlDp1\nGjHMYmyCYdmAtrlu/TrqxaJ1RzY+PHr8iFKlTs2G38vSfr/7vpuUtQHGbYwx6zdsEFEOzwnBe+LE\nCeQJG/hzyH+DdgdRK2LESLSc+0PlKlVpwcJF9rHNlN8oriv87RQbh1PzfaHdTpgwkRo3aSpjkQFt\nsGHDRmLgxfOiDaEP16hRk9auW+fyXtBXjrFYaAQgeKe+cRHGAsJlBx7PUVaoAwiYP/z4o4TDsB6L\nMaRzl650hMe6hFw2n/EXH4yrqEPUrafXs4Kxee3atfZ2dYz7R7Vq1XkMW8xtL4YYle8/uM8G6bG+\n5mf717sNN2Kjdq/evWVMg6C1j9tTF75nfJEz4H5QPw25/2ziMQKCI77EzWERuwIL+Vu3bpXj0J7Q\n7yDG4AneeD8P+fI8aPflylegWbNnUwQWJ6JGjSZibS0Wgs9ZwuTiS2VVfs4pU6bKuSFWLeT2gf7/\nK7dpbBhAXwUQGvBs2NhgBeMPhJhNmzfZwzbivWEsaKCdoM9CXIRBHRsBIGxZ27pvYJwMyFiGz6FO\nUb4Qxaxc5N9nsVB6/foNEW5O8XF4LrR5w0oWRpHfCSK35N4KG07Enwbc9k0bMVznea9ho8YyVkSI\nGIHP81zmY+ScwzV84zjPdV9//Q0Lt7Ol7CPy5zHXVOK+e/78BZefQW7IP3fslHEOmLndtG/cX81a\ntXm+GiTPnojnEayXvvv+e+7PTez1CQ6xSL5q5SrJNfbTzz9LGUTlud9dGGj0rd4siljXJWifMEpA\nXDSJzAOKGSeRF6Jtu/bcPi+y4BNX8rB16tSZx4OfHEKDHjhwkEqW+prmzptHoUKGko0+GDMxHv1i\n6WuuuM3taTWvg9AfcN+oC2NEMWOGcaQ38zjWYAZ8pnadutS9ew8RoHBtzAer+JwYe/D3vf/7S/q2\ntb0PHTZMwpyatcSD+w+kX3zfrZvDWIs1wOgxjuOyEfmR084ci/6FtS36CAw/mTNnkjKaPfs3GXfe\nFqyNsKnpW57TMD5j8wP6M+b7oUOHybpcQxIpSvDFiF8Y+zEPd+TvXPCAx2YvhEFUEUxRgg6s2SDe\n4IX1Pl749wwnj/TgBLyvjLhkXs6b6N4HEL5go4CXGKLpIH8YfreGStRwiYqiKIFIyDglbIH5+pgg\nWWMHLT/+9JMtYaLENjbU2J6/eCHv8ZdzGwtF8j6LSvZjO3fuIu8VK17cxoYz+/ss7sj73373nf29\nHTv+tCVOktTWr19/GxsV5D029NrYgGj7In0G28GDB13eT7fuPWxJkiWz3b9/3/4eT7y2S5cu2Xxj\nxIgRcg84P4tG9vfZ2GpjA7qNjY82NjTZ32cDn42NWvbfWWCypeLj2PBjf48Nr3LOJEmT2br36Glj\ng43DNdlAZcuaLbvt9Okz9vdwzqJFi9nYmGJjAcb+/tOnT20FChay5cqdx8ZGRpfPgM+mTpPWVrxE\nCRsb6uzv47rWa6Ps2Khl/50NOba06b6wNW3W3P6MW7ZssaVImdqWPEVK2/bt2+3H8hc1W7bsOWzJ\nkqewsUHH5o7du3fLs2fJms3Ghlj7+2zYsuX/8itbkSJF5Vzg0aPHfM8l5bzHjh23H8uGJjkHG/Fs\nvoHnPnnypP13NmzZWrRoKffI4qrbz6EccU1cg0UFGxsvHf7OhiRbxkyZbWfOnpXfWUCxpfsivY2/\nnNqPYeOX7erVq9LGAAumcj4WBOS9QYN/kPrv+u139jqYPn26HDNx4iSH67E4LO+zmOTyfnE+FiVt\niRInsY0aPdpe/uhL5cqXl8+2bNXK/v7mzZvlPRZ45D4ByrrU19/Ic7OoJe+hnaId5siZy3b48GH7\n9dDmTN9jgUzOxQKm/D523Dj5Hdew8s8/lxzKBsewCGJ/jwU3ea9Dhw5yfoBrsLDqVdfDhtmPNdfM\nlz+/tFEDi3C2DBkz21g4sPkFG0cd+ukNrvMcOXLaypYrb68PFlZs6TNksCVNlty2bt06e12y4dRW\nunQZGU/YoCzvoY1kzpJVxqC/+T4MW7Zulf6Pc7Dh3u394F7Q1tEv2EBreaaTtjx589my58hhu3z5\nskP54YVx1twXyq0Jt9eUqVLbtnn3Tfxt5MiR8t7ixYvtx7L4LnVdsmQpHj/vur0vNsTLdUyfNJgx\nDOMKCxD29/nLo5Qh+rJpRwDj7tGjx+xtEPfBX9q8+sTatX5ezxUYmzEGm/IaP368zA3r1693OA79\n0DpGO7NgwQK5JsqIxQf7+6Y9ffVVAXs/wXyBPlG6TFl7fYAd3L9R/yhP034x9mfNlo3Hz2a+Xh/g\nM3Xr1ZPxdseOHf+dl+e7FClTcb/oKPeAcuvRs6ePvo4xq0zZcj76+rDhw+W9PXv2+LherVq1bTlz\n5XKYT1Cv1ufC3ypVrmLLmj277cyZM/Zroe2wyC5jKjDzwsqVK+X3gI5l47zHDxbDHN6fNu0Xfuak\ntqlTp8nvI7hN4zjrnIf1xV9/7bO3cZRB//4DZJxlUUDew9+qVKkmn23QoKF9PYD3x0+YIMcO/uEH\n+znMdaxjO4uQchwL7/bPLl6yRI5r376DzTfQNnEcxjsrP/74o9QpC+z2MsX416at13qJRWP7sWgL\neA9txbmtu+Msz1XW8Q5rpi+5XaNt49/A9GkWiezHoW9Y+5grzDiZLEUKrrff7WWH82HNYu1XeLbK\nVarIvVvXatevX5djrfMPxuG6devLuIxxBZh5dOKk/9rV3Llz5T1r3wWmnVqfh0VmORZrGtNPcb9m\n3ePqmvIs3CewRjHgs1gT4tlMf8F5MFY7j8v4yUKyvG/GZRa75HesA6zcunXbx3rDL1gYl3Nh7LTf\nr2V8XuVyfP7SYXwOat7Fdw5F+RjAeIEX5nvMYcN5Do8aNSrPLe09WhcpSkBhcdXHd7dPlQb8/RTz\nFvod1n8s3EjZ4GdwZQmvQ3Hf5oVxg0UoW3ACY1ifPn1sUaJEsfVguwXWUlh3YW2I70nme455KYqi\nfAoEtm6lHmHvEez6Xrt2PaVJk0ZCsMDDCMCb6tuuXSlG9OjiPeHs0dOubTuHkF758uWTUDIXvHdZ\nY2ftrNmzJFwgQslhBwl2/eK8NWtUl53JCB3hivjx49HrV6/FkwI7fWzebtnwTvALHIfwSrFixbK/\nh/Brefn+cD2r10/6L76Qne04P3b/Ro4SRcJbGdd6K+nTp6ce3bvZw1L5Bs5Zrnw52S3MooT9fXik\nXb58hUqVKmn3WHJmydKlsisc4aaSWvLV4LrWa2fOnJkiRYok5Yp7R9lHiRKZbt++5cMbALsREQLI\nAK8uhCrCda5eu0Z+gXCLCJdnwK4lxJPGTn94C4Dt27dJiCWENUO4LNQ1XvXq1pPd2/AW86vMsCNb\n6oLvH+0HYYFwj7du3/LzHlHfw4cN9TN0FNoQ7mvr1m2ycxNglzpC+zm7+aMcETINYU0Qcq9f3//C\nklWuXFnKETvlrTvo2cgq4brKlCnt8vrw6oPXGp61Vq1adq8a9KWmTZpQyJChHI6fN3+BhIns2KG9\n3A/uPUSIz6k29ym0ZYRWBOvXbxCPDoQ9RBhDAz5rwgc6E0+e+XNat369hB6zee/sSpTIfT978vSp\nhJ3CuMCiuJwf4Bq4dqpUKWnFylU+vDrq1KlrD4kHMN5kzJjBrVeGFfQ901/QHuCBA28+eAdgt76V\nDHxsIUvIToSUKlGihIwnV/gZAbzkcH8IGQkPSUO+vHmpSJHCft7P3r/+Eq9KhBdDPPX/nik1NW/W\nlOv4lg/vLXiAWkPIody+KV1a+q7x0EMInSVLl1Emrr9ixYrJ31DfKNMvuS+wmOudXydgILTsN5Z8\nebgnXAf94O7de/b34a0C70C0TZQ37gMhC1HHbEimwCB+/Pgydq1dt148fkzbQz/0JFxr1apVHEJQ\nYkzKni0rPX7yWEIlAniuoJ7btG4t1zMgpBs+D6+2s2fPkX+BFxDGM4TSzJ49u32sQ5nl4nHy4KFD\nMm9JX9/xp4++Du9LhJn05Dl9A6FL8Vxm/oJ3XO7cueTaeHmKq7EM5/NrLGMhUfolPOFeentqP3/+\ngpbyHBYjejT+ewm318Q6IHv2bNIfcE288ubLK+P+DScvL/QVhMg1XlT4DPou5rxNmza79RiGxxo8\niRBGFXM96gjPhfpHeL9du3f56ansDLzEELIYoSsR0jKU93oJfaOfd3i+2bNmO3wG94vQyuhrngAP\nR+u6JCyfM2uWLDJXW73q3ob0X6SncuXK2ccjtKWWLVtIPa7mdReA5zFC5tapU1vWG4bYsWNTN14L\noX2v8j42KIC3YViebwcNHGCfZ3C/WPf4BkI/YzwwawmQN28eKTsz5xucx2X8rFS5kvzbjMs4Jnz4\nCOLZgdDWxlMM4RHfNlSlFYTK/Nrl+HzPYXxWFOX9YnPyhEBINqwFENqYDfA0cuRIDcmmKO8IfEeH\nJxP6HcIh4t/4Hhic8/HBWxQRLMzLtyhB7wuMYfAMg+0M3/2wbkY4e6zT8f0NP/GyWbzDbOohpiiK\n4i80R9h7BMb0+/fvUaZMmXzkqoFoEDtOHDEIwIhg/dJvzbcFQrFRD6HYHnmHE4Kx4Pq162KI6Na9\nh4PR75G34eqiU0glQ3UWU7Zv20Hfffe95FEqU/obMdYlSpTIz5jECJ2UMGEix3tjYxUMSRs3bhRj\nMww5mMQRcgiGtGPHj0k54BlhPHv50mdYKQh9/jF6wPg2Zco0MS5ChMJ9I/zNmzevqVKlSg5xlq1A\nSITx3mrkdQZlC4P4Rr535M24e+cuPX32lJ/hLhuS4/lYiCC0pDHYGYxR8RkLG34Bo5kzX6RLJz+R\nL43ys3H40iU2Zr6UcI7OAifu5+w53w3OMDDiC+TOXbvFwAYDpQnV5Uk4KJSxu3BTVlD2ECRHjRkt\nht4KFcpLDpNELkTW39gQt3fvXmnrvXv1YiNnWPvfUEfIUYVcTrt276avvvxS2tZffHyxYkXt+Yec\ngSHuwYP70h5jOvU3hHEKb8mvhXJDSFD8RChCKxA8YTy+5i1knjp1UoywWTJnIU+BQITcVcjBgjCe\nJYoXpxosUqPtOedZMqCPXL58VYRH5zxOMN7CAInwqHhO63iS/ot0Ps6FcKgm/JhvIETUOhaWEE7v\nzu070tbPsigUhRfpNtsbh2MR1tVHW4/i2NbPnjsrP3PlyulwHD6H0IuuQppaQTgxkN07z5qVTJky\nSz0gn5kV5BcyxlxDVL4v1O2zp17GbeQmwpcNjEXNmrdwOPbSpX+k39+56zp8pyek4zpwHj+jcR3A\n+P3CMuah7iDmIC/Pv/9ekrCBeA/90Cr6vg0w8JYpU0ZyuW3YsJ5Fk5Is7taStudJ3Pl0TrkX0V5h\nrH7z+g298DZUn2KjNcrcmm/LkDNHTppIk2TTg/Nc5hfXrnmFbkSeRoTsM6AuTyD8G9/LPR4LcB/3\nHzzgvp7ZR19Pxe0hXLi3M6JD7ELouYOHDtLtW7dFpL569QqXwWt/hdBzNZZhfvFrLEuWLCl9mT8/\nC47r6e8TJ0TARV5OCLalv/lGRE13YHzHOAED4qV//3UY71+9dmxj0VlUc84TCaMBjBwISYgxydXY\njzECQLi21hPaMEJshmHxChuBELLZUzDeoh8i96WzICObOVjsR85BrC/MHI91w5f5v/To/Pgc7g0b\nG/5bl/B8j/CCfN/WsItvQxIeJ53XM1/wPI81HIRetOVLl7zqxboJxpDL+70LHmxkCAi4/ulTpygF\n9xPrpiZPPodNHcg1ivC7WEtgjkGZAufxy9W4HMW+NvIal7HubNWqheRJq1S5ivQP5FVEubibJwMC\n1lSejM+Korw/bJaw15gnkXsQ3yVhzNYQiIrybjEblyGAKUGDyR+G9TrCTs6aNYvtW1Nk7WzWufhp\nNq2bn4qiKIrfqBD2HoGXCfInIQ+VK+BldOPGdR8GBL9EB3x5f8xGFBhu4HlClkkRho1kbFyD4d8V\n+Pu0aVNo7ty5NH/BQho7brzk7WrdpjU1b9bMrYgEPuP/woT16bUVLryXwPDUe0c1du4NGDiIXvJz\nZWTjKxKmx4geQ4zcT574NM5HjxaN/ANExPz584n3CYwxKIedO3eJ8T2FG8MigOEUoqGzccaAeoC4\nNmzYcDnmCzZuJ0mSVOrp4MFDLj8TLbr/7t0ZV/eCJPeoh4ePvERNiEAAeTycDVdIKB86dCi350f5\nNGfDP4yp8J6AkRveNYcOHRbPG0/wtH4SJkhAkyZOpFWrVrPQ9RuNHDlKFnTt2rWjZk2bOrQt5OWB\nBxh2xe/YsYNKlSrlcC4Y7qdPn0FzWTCDcQwCymsWOitWrOT2+jBQP378RPLiOQPDZMhQ/w2HqGt4\nO4QOE9pHmeL3tGnTiUEdbQsCNMRoq1jnFzCAjxg+TIzWyM+zcPEi8f5sxAvdLl06u/R+fMnjxePH\njySvmStgRIQh+8kTR4E1UiS/RUpXoEy7dO3K/fQli3yZ+XlTiZcKvA9d4Uk7MOKbK8+CqB7synvg\n3dbDWURLA8osFNchRAmrIA3Rzy9QZsa701V9Z8uWnQ2jAd9lHCWy3/cAIzJyH23cuEm8jZAPJ3my\n5Cx0/0PHuR8EFjC4jxo5gsqWKS35pBbwOD9/Pre9Rg2pa5cufnreRosW3de/S5949FjGUlfnCh/B\nSwQwuQP9g5kf0F+d6wmbLPA+PKuf8vyHtuaqr4fjY0KF8nzp4zz/nmaBvBnPhbfv3KU0qVOJt2V0\nnr+2bfNbWHaF81gGgc2vsQxjZeXKlcQDdM0ff4gQtn79ehFPylco79bjDX9HntDN/KUaawAYMDCO\n3b5z2+V4//lnn7usQ4x1OJe7fGjYGAIwzjnXE/pYJMntF5H8A66HtQ1yd7oSQbARB/eD+jKeuJj7\njBjvF9u2baM+ffvRXRY5zbokWtRoItjhFViEcTGnI0crcqo+f/FS7h95FtGPwrsQbI2IhrkgKBDv\nZx4L/fL+cgZebMj1iI03aFtea4k0Mq668vT3ZFxGPbZu1YpyZM9BCxYulNyCa9aupcJs9P7ppx+l\nzwcGkSMHvx3hiqJ4YRXAsDFo9OjRkoMI0TE6dOigHmCK8g6BIANM9ANswDXvAawr27dv7+NzEHPQ\nb7EeQJ+FZ1b9+vUdjoGHGeb5Pn36SL4/XAP9vGDBgpLbC5/F786fw3E4N66Bf7s7/9uAcy9btsy+\n4djVfQQVEPoh/qN8YA/5kr8r9OzZU4QyI3452+dUEFMURfEdFcLeIzA0wNCBnc7Ouzhg8IFXV6xY\nsd2GV3MHjo8VM6aEpho8eJC/DU44vkmTJlS3bl1Jov7zz0P4PD9IiKMCBQq4/RwMj/fv3Xd4D891\n5cpVMczBkIxjhg0fwRP2ZzR18iTZ2Wuee+26tWxwukH+woUrOBYDxYsVFYPiFl5Qfc7nv337DrVl\nMc+3soBo6BUO8LaISs5g5yF2Jsflvw0dOkQ8+QC8SebOne/ynBAH3wazU98KhC8YyeJ779Q3O/Yr\nV6oo4RH9A0ROhPjrwIvW1q1b2dsaPBSwGA1ssDitXbuWhEfDohLJ6H/66WcR4YoU/i80XqNGjSS8\nV6PGjalnr17yd6t3BH5H29mwYYOE+lzKi1N45EEAdYeX8TWS3avECkRQq8EbHkqoZ7RNiAa+LSjj\nxolLL7jd+NdYCpEToc8QkunQ4UM0nPvFxEmTKHHiRNL3nME9QYi6zW0C7dTqfSUeatdviOASKbKj\nATMga2GU6U8//0xvbG/odxbqsmbNKu9DTNy2fbuPMFeeXiiet6fK9es+68BVW3cGoe0ANgj4/PxN\n8SiN5x1q0z9hIiKwOIOyRRiy0aNG0vtgw4aNtHz5CmrAX6wghppwHctXrJCxLDBBP/+GRVh8oTpy\n9Cj9+ONPMrYlS5pM+qdv+FXNGH+jRovqtSHDhdfhde/we86eRp4Q01tUKVq0KHXp3MntcRgfI0lf\n9xl+Fm335UtHccv0b2evnxcsTNyxhEbD30eNGs1zwT88Loykr7/5WgQMgGc9fNj1hgjfsI5l2Jiw\nbv0GP8cykCNHDhYckrMwsE52xm/YuFE87BCi1B0IpYjjatasaQ8nCBCiFeHwnHnIYqVzCEOUAeow\nTtw4bjeNYAwDxbieunbtQoEB5g6sI+7w/Izxzjr+mXVGzJgxnNZLng1+mMMnTJzI88B9H+uSv0/8\nLV5hgcWVy1d8vHfz5i2ZQ+CBJ2slHosQOvfqtas+jkU4UxA3XnwKCiB8IvSgCdnriTEFx02dNo1O\nnjpFPXp0pxrVq9vroX///uLdHVBQHugL+fLlFU9DbKCBh3/ffv1p3NgxauxRlE8AjDEwdMMYXpi/\nK+D7Q3AOv6YoHyvoe1YgPFnfwxrbWQhDv0WoP6zjIJRBTEIob4RUREQaI2bD7gCxB3/HezgvXvg3\n+rsRwuARZbxA8R7GBPzEuXGsu/MHFOf7N/eB9xC6+V2J8bgmnhv3g2gePXr0EHuB1RtMBTFFURTP\n0Bxh7xEYApETCOF8TCghw549/2NB5g4lT5bMpfeDb8CQkZwNZFic/PXXX/76rNV4jPMgr01/nnDB\nAe+cSO6AgWzXrp0O7yE3EIwgCNWEncww9EHISZc2nRidzQSNHBzuPE3c8RlP9s+eP5OwgM5goRA7\ndiwxICPvBnYfFy7sew6itOnSihfQ1i1bXRrRscsdxiHkgTIiGDjHRrKg2p0N0cEaagvGZYh7oUKH\nosTeYaXSpE7DdRWWVqxc6a88JjjXufPnRCBC7jRjuILX1P4D+ymwsZYproXwgP369eXneyP5P6zk\nyJ6NX9mpZ/ceImJ255/OHiS1atYQ7x94s6DdQVTyTehE+KyYbOA7xca6f/91zLd0kNu2s8EXHjkI\n67Rz1y7yDXgGotzhyeNpWDRrWSDvWDYWmob8/JP8ftyNJx6eDSGckIdpl9M9wZsD7RBjin89KF0B\nAziE3wxfpLeLYABjiisRy1Ng9AfIIWUtA3ghILSbX2TJklk8fpavWOkgWuDfEO0Rygz5z/wLxibk\nA0O5Xr161d+fNx44/s17ZAWhYTEeoi8aEQzPtX/ffh9eSW9zPWu54wtTZh7LfvrxRxkHDhw8QIFB\n/nz5pU9s4i+gViAWrV+/jttyBHt4z5AiaHzGYsQzP8VLbPCAh+MmFnOsOSedQV+PwaLISenr/zr8\nDX396VPHcjMC6z8IN2sBYTEvXPgvN5xXCM1/RagoVKigXQRDnzzunbMxIJixbO68+XTi7+N+jmUA\nnuHYLIAv5NgIANGveLHivuY7wNgHsGnCrCtQ5ghZ6woI4gecwu0eP35cyiBJ4sRuhTB4yWGMX/3H\nH1JmgYGslxImlI0b/ziFdkY+UJQDwqMGBMz72CARJ3Ych3XJjZs36YRTqNW35fTZMw5jKMp/E49d\n6BsmRB/WGKjHlStX+RBnYdzBMdYci54Q0ls4xPzuF8gNifHfXS5ZZ+D1dfHCRYrO8ytyoP63lnjM\n60bPzuEOMybgmRFOceDAAbzmSS3399Tb+xd5vN5m7FUUJXhhct5g/IMhuwiPK8iRAyM5QoWpCKYo\n7wd4JuG12Xt9D88r8x5eWKNYQZ+FYGSOw+fwE15fWGOMGjXKxzXQx3EcPgfg+QkbFPJkA3hmGYyn\n2IgRI+QYc358BueHgP42+Hb/uK6r+w9KrOESYd9C/jBEWjL5w8zLoPnDFEVRXKNC2HsEQlP9+vXE\nuPztd99LHh54lUA4+omN4vBuwN/9ClXlDIybdevUEWPgd993o5WrVomRDPnGEL5m8pQpIki5AuFn\n4IGA47GrB0Zh5AgCnnzxmDxlquzWhXcHFgoTxk8Qwxnc2nE/eMEABy8EhN+D1xoMwO3atRdhxj8g\nDxJCcMEojvNYvVTwt6/ZoLxnzx4Wk3bIjmLf8qYAeEcgJNkvv/xCCxctostcXnh+iFEwvsFYijCW\n/+P6OXHihDwj8vkgVCJy+QQFEDKxown1gXtZvHgJrWLjWOGChSild3jLrNmy8pfEQrR923bq1bu3\nGIhQv1igIezZH2vWuDw3jOnwZkIYsR1sCEUZwsCI59+0aQsFNsgLhsUaDNPmWrt27qIQIUOwAdJ1\niCOE/6pWtSr9uXOn7AS3LubgSYX2NGr0aBYKXlOZ0mV8vT4My1WqVpE+1qNnTxGOUE5Y1P7y63Qf\nYgNCHsCg16VLV1q7dq2UP+oBuXEmTpxoDwuBEAUwXMLb4ldeMOP5ILRt3bqNTnHbdgX6FMKPXrp0\nSQRW3Afy6IGECRK6/AzupXqN6nKfPw8ZIuEj8SwYN0aMGCllihx/gZH4N3So0Gx4jk8XuC1hPMK5\nkTOtR4+ebAS/EtDTUq5cuVg4/IL++GMNzZ49RzxLYBQeM2as9Cu/gIEWXql/7tghZYDPQmyHgWTR\nwkWSND1//vzkXyAq1K9XT8aQ1m3aSg4l1Anqcjtfawaf3zeROVZML0+lefPnS1nhs/794pEwUUL5\nDATtGzduyuYAxIPHWBSY10NbRtvDs+F50ab//HOHGLOTBZJxCWFoURfjxo2nRYsWSztFW4cHKjYa\nFChQUPL/AIT0RLhGzE34EguB66F3LktnMD7XqlVDQrl257Z4lOeR6971hHEOZQfQ16txX79185a0\nWdPXITigjzr3dXhRYd6EVwvEIpQpPtOzV2/JtWmAF1JsFksgyv/pPWbiODznvv0BFxHNWIZQsaF5\nvvdrLDOULVNWxnFcH+ECv/nma193fyaI7yU+Yk0ALyTUPYwECxYscvOJz2R+wy5dzHdnz/Kz8px+\n//4DqlK5sluxDh7V8CzEmNG+fQcR6lH+GPNXch0hxLB/wXM2bNSQBcMnsq7BuId7Qpvp2KmTCD0I\noxcQIAJjDLjIc6Z1XdK/X38fmybeFnj6Y2OHaZOYF1EeiVlYLFqsmByTmPtG6dJfi6EDHohYu+FY\nCGOTJk4Sz7/ixYv567oJEnjV/SIeT9AffRszEKoY7alT5848z+yVcRbriRW8Nrx7756P48WLjNdH\nN/jZsFHHzO+496NvIRBjzBgzZgydPHlK6hpzJdYCd3jcwpoB/RFjWLdu3ahylapuxw1FUT4cjOEW\nawGER0OeahihsVbXXGCK8mEBoQoeUxCqrJ5TxsMKNg5nzHEmj6yxP5mf9yzrEHxXhzAE4cuK8Urz\ndEOPO4zQ5er+cX+u7v9dgLKAMIj7+Pbbb6kpr9uwrjSCmPlpDS2rKIqi/IeGRnzPlCtXjv7hL/sw\nLpUtV56iRYvKi/97EpqmR/fuEv7IYAxcrgxdeMv6PnbOIvRRr959qFWr1rJzG4Yk7NDFzuo8uXO7\nzK8AI+AUFrMg+MCwgS8iMJAWK1qESpQsSb4B8Skn3y+MUhHCR+BJ+JXkAfvqq6+oaZPGcn8w0jdg\ncQ/hEWvVri2fgfECBtjSpb+xi24Oz+nGsFecjUZT+V7HjRtHCxcsoDgsdI3nf8PLDlSqVEl22L/i\nxUClihX9DDEZjsuoV88eLEIOoa5dv5XfERru6dPnbBDrS3Xr1qEaNWqIkFiuPNcVGy4fPXhEadKm\n4efO7rhz2zdX9M+cns/VIfw3eB1U4OtApIHACAER3nSpU6eiTp062nOFwCuhb58+9JrFIBidF7KY\niZwXWCiGYkGjXbs2LAqWcnmNatWq0tZtW2nQoME0ZfIUCc+E5y5fvqx4WvnmUO9X/dif0/vXA/sP\n0pzffpO8Lcgb84jrHe2jVMkSbkNuwhjXrZuXSAwDNsIjYWcoQHlU5C/H01i4Q5vOkMF9SDBDrZo1\nJe8YdqwVL7FD2iN2lZfnfujsYYJQjD8MHiQhAps2b0Hh+Xp4ZhjBEZKsEn85BxBIe/boTgMGDORy\n/EFCieK+0W8QJip1qlQ+CgWGzX79B4ghD2UBERgGPQgINWvVdChfazvJny8fff/995IjoVr1GjJO\nwCiNPDgwXqIPeYpv7Q8humrzfcAIWZtFdbT1O7fviBBRuFBBEcicz+NJGFCUC3K7dGDjOEJeQswC\nKId6deuK4OTbfaEPI9xrO/6CM2HCRBHTAIzjmTJk5P7bU/qNw325Ot9nTo2TKV68OLVs0UL6d+Uq\nVcQ4jvxor16+oqxZs8hY7c4DplKlijSdBQWEt1zAYxG8m3ayuORrH+H3rPeGNriA+9ycOb+JUAhh\nBgJvZR7HsEHBk+u59B52ujaM2r379BXPOoQaxJel+zxWZM+ejSrwOOkW+3lcPYs5xOsfEHUwJkFU\n7MCGLCPOIiRhnjy5JBSrCW2HealBg/o0aPBgqlO3nnh9Yezu7CL0IT6DXJXoKyijNSx+RY4cSTYi\nhAgRko1l5Vgc8hKRakpfP8ZCw1Iq9fU3Mqc9e/6CChcuKEKjFXg9VqxYgQ39K6k0i0uYl2DMh6dm\nfu+QbHg2tD94b/31115qyfMq5lAIpGhzFSuWl7H3v+Ly2cbclaF1LIMnrCdjGcBcAM/V3bv3UAlu\nv0ZcdMbcS5UqlWn+gvksfs0Ub2mMO6/4Vb16dWljzn0G7R4bSBo0bGQfK/E3zIWlXMwpVjrzOuAB\nj00QKPGCAQFzPT5fh+d+qu7bpz+z/P8/0EcgyCB0b5my5aTcIZDg3vr27k05c+ZwPoVHwRFR/s2a\nNuG1SxeHdQnyWpYvV5aWr1j+32ld9Wl/hJ4pyHPdyVOnef7x8vzEvINx9fvvvmOhMr79Gt+xYQNC\n4pixYyVkLu4RczqMH314XWfmf+vlncc662/II5eP54/fWQTftGWzjNdzf//9v1xdls9iPu7apTON\n5zG2StWqcp+Y99CvFy9a6D0X/ndNvFq2aE779u0T4XnUyFGyloDAXYXH0t/5Os64Xsc6VhrqdgIL\nfyNZUMM8ib8jNGYSLgPkNMR4AC9geC2iv6Is3eU2czUf+Gd8VhQl6LAaafFdCiFVsc6FMRubKjUP\nmKJ8eGDNYkIW4qdzvlC8jw0/eN+TzdauMOK4CdFoRLJ7Ljbt+BecA0Kau/tPlizZW9//24JwiSZM\nIzbV1apVi+rVqyf3g++RZo1mXp6GvFYURfnY+SxknBKBukXg5bW19LHg3zwzAQWLfuw+hucRQhHB\nmIXwPDCgWycreAed58m2XNmyDl5iMMQh+X0ENow4CwrwYoHnCHKa8FcNEbfgvYIQPCa8lhUYGGFU\nQ6g6hB2MGSMmpUmTWgworhLUG7AjZsbMWfT7b3PoEYtth3jh8Ew8DJKJeGH9EoPnxbPs3btPwhom\nTpJYwulghzK8bSp6G2NhdMPO9WxZs4nw4Ap4AiC/ye1bt9mYFI/KctlgZzdAuKpSpb4WI868ub+L\nccsTLvE59/5vL/17+TLZ+F6TJE0ixisY3eBJsHv3btp/4CCF4AVGUv5bbhYVce/wTMFxMM7AgLOd\n6xMu6+m4rK0cPnyEDWEnRZxyt6Mexmp4yBQqWJCu8b/3eu/KTpAwgVwPYamcQXg5eLIcO36MHj54\nyM8dWUJUId+J1WjmDDzIsNMS5YVd4xkyZKAULAJhZ3cap9xcztdDvpl4ceOJwdQZGKHP8RfYIoWL\nSA4mlBHK7sKFi/T02VMxquH+IMoagQHtfy2LoXjPatTFInMvtxmECoWniWEJC1rwJmzZsgV179aN\nPAHGX5TtkcOH6TXXLwyE8FRCWDzUHdq6td9hZ/tff+2T3ek29CFuR3nz5OE2mcLhuJtc53g+lOeb\n128obry4VIBFYBiSUXfo36Ytw6iI8KfwLHz46CFFZuMdPAIgxlj7NozT8ePFd8gXZMYLXAuhu3B+\n5O/DQt0aG9xcE18SYnmHfjOg/129eo37i3vPE6+2vkfCjr14+ULEddQLxhsYHtFn0a4QkgphCWOz\noRJt04qpt3x589o9EgDaAjxq0D7gPZI3T17ZBIBx7Mv8+V3m6LOCe9i1a7d4EcGDJhn3wzxcJ9Gc\nwkK6Kj+Avo36zsV9w+w4BBjvUSfw9LzG/Tl06DB8L7FlQwKO8+3LA54V5QAvpFixY4mHGfqIuzEM\nmw7gGfvVl1/aNyVg/EWuMLS1mLFictvMJN4f6GdJkyTlsSStr9dzNUbjGhBy0BbR5xAa7X//20N/\n/32CHjxkETVSZEqYMCEVK1bU13EC/WAPzyXOdYky27lzF927f0/ahFUshGEa3kTnz18Qo3jy5Mmk\njZgx2gAxDvUBrypsoMB5MAe6A31437794nGJvJK4b3zpw0aMmJa2bvr64UOHxWPoCy6/+PETUMVK\nlbmf56ExbGgzZYZ7QPvD3PecBTOITBjP0dfgdQahCcfieXHM1m3b6AmXJcoCIiLaLLw6c/JYgvyN\nZnxErjK0P/RNMy9gvLGWIcBYBu8phH6r5yJHoDvQjg5xH8VYbQ3ZC3DvaMvWNQPqZM2atZJ/CmMH\nytnVeI/6wPInR47s4hWKeQuroQzcHvNyG7Dm6DLXcR5rUFbwKEJ53bx1k8XIiDKO4Jy+ea7C82fj\npo2UkecizKFWcM7jx/8Wb++79+6K9xSETJzXCu4f+T7N/OMXpl43btxsX5dgnAcYB4sWLSIii1mX\npEyR0j7voW/Aa9z0MVfAM74aC46Vue21aduGhes/Za6IHSeuhAJ2nk8AruXlWXxK6gLzX968eRza\nONrtjh07eBx+Kl5iWNeZeTQdlx3mcwM8wfA+NmJEjRqNqrIwin7pbh5HmN7DXK/wjsfmJrQvbNbA\nfTpfE2BMQjhUjGPSL7JlEwELfQWbOMx94x7QFpzHZYTkhbhtxmX0Icy9KLvbd25TGBaiEyZMJF7Y\ncePGsT//0qXLuI9ep4YNGrJg6HqzAuapVatXS1vPxvdlytc/43NQ866+cyhKcMHa3vFvGJWRIxgG\nZg2BqARHkGYBYfE+de9EzPfopxBh0Fddgf7sV1oKALEbfb1hw4YSitD8jn+b9+D55eqaEKvgdWY8\ns6xjhsnl5e7+zPGYe3FNd8/oF8HFWxX3i7LA/Vjzh1kFMWMnUDFMUZQPjVBxS1JgokKYL+iXUs/B\nAmT6jJm0YP48ETeCAwgbBs+ub7t2pTZtWpPycYG+Wb1GTdmFvnnzJjGIKoqi+MZlFkFLlynnQwh7\nn5ixDGFN1q1dKx6ZyseFEcIQ4mvggAGkKM7odw7lU8O0d8x9jRs3ls0BMFprCEQluKJCmBeeCGHw\npsJGJZQVyswdpiwDIoQhfCpsUPAeNeEWPb0/4IkQ5tf9YyNqcPJaxX1jUzk2Jc2bN082vEEAMyIY\nvveod5iiKB8agS2EaWhE5aPC5H7xSpw6UnZnV61WlZSPB+wSh1fUsmXLxSsKIcVUBFMU5UPDeSxr\n26aNimCKoijKR40RwOChjBCIJgwiDNmKonwcGO8s2GSCSjiESIbrBEWuLpwXAhcEvQ9J+MR9I38u\nygYpPeBF37NnT7t3G8Zf4yVmUEFMUZRPjc9JUT4ikEeqarXqVL16DQkDhLwbcd5RWBsl6EHelmpc\nv9hZjxxTiRMnoq5du5CiKMqHhKuxrGnTJqQoiqIoHyMwwJoXDNcIaYvcx/DGUBFMUT4uICJBQIIQ\nNmrUKB9/nzFjhoRPfFsQHtE5JxjOHRjAi9+EX3QGAhlyjgdX4A2HsRWhtxFmHLkXEU4aG/CsL6De\n6IqifGqoR5gSKMSLF0/yniDfxPskTuw4ksMpWbKkVL5cOSpYsCApHw9w50+WPLm4+yOPQM0a1SW/\nkaIoiieEDh2asmbJRFm8Q4W8L1yNZcEptIoSuCAfaO5cuX3kMlMURflYMaG3rEZWGL5hVMb7S5Ys\n0TCIivIRg7CECCfZoUMHEY7Kly8v7y9btkw8ltD/32YMgNgDUR0hGHENAHEK1wLOAhn+hmsbIMQD\nhGA0IAyjuacRI0bImAWhHoKeuX/kP8Z1ERYRYllwBveOcsK4i7z1yB9Wr149+Q5kxmbrv9U7TFGU\nTwEVwpRAoXr16vJ635QrV1ZeysdJ+PDhacTwYaQoihIQYsWK5Wu+gHeFjmWfFokTJ6Zp06aSoijK\np4TxAINnAjwStm3bJvl2YJhVFOXjBmH6Nm/eLCIMhC+8ADZ+YRx4W09QnANiF85rhDCIWBDZIcA5\ne5wdOnTIfg9WrO9ZhTncp2/3b64Z3EE94LsPygOi36xZs2jKlCnyvhmjIYCZjQvvc6OgoijKu+Cz\nkHFKBKov7Mtra+ljQRNXK4qiKIqiKIoSlOh3DuVjwhhXYaRGWDSEKoP4BcOxej8rHyoQVyCAqCej\n/8FYAK8q9H+TPywwzw0vMJw3sM9tvYa5f/P6UIGgB3EP+cPgIZY8eXK7EGZewPpvRVGU90mouCUp\nMFGPMEVRFEVRFEVRFEVR3gojgsH7AKF/kyVLJv8OKgO1oijBHwhHCCXoX6wbRFyFWwWRI0e2p8MI\nqhB/Ab3/4Ag2JUDMxSaFUqVKUevWralt27biCeYsiJkyVxRF+ZhQv1dFURRFURRFURRFUfyNEb/e\nvHlDBw4coCJFilDnzp3F8wChxVQEUxTFvxhRC+PK69ev5fXy5Ut69eqV/DQv8zt+4li8zJikuAZj\nssmBdvz4cUqbNq147ppyNmVuylHLUlGUjwn1CFMURVEURVEURVEUxSOcDaN3796VcFszZ878oPLn\nKIoSfDDjihFfnj9/LiLXixcv7EKXIUSIEOKtFCpUKAoZMqT8Dq8m/MRxVg8noJ5NPjH5w0y4RORx\n7Nmzp7xv9Qiz5g3TclQU5UNHPcIURVEURVEURVEURfEYY6weOXIkpUiRQgyk58+fVxFMURR/Y/UA\ne/bsGd25c0cE9kePHokQZhXBADyWII49ffqUHj58SA8ePKAnT56IeGYVzqzimuIahEvE2J09e3YJ\nl9ilSxc6d+6cvfysXnZajoqifOioR5iifKxcXElKMCBJGVIURVEURVGUDx2rURlhtTp16kTRokWT\nEIgfSw4dRVHeLWZcgffX/fv3RcjyL0ZAgxAWNmxYEcqMp5jxFgPq0eQebGKoUKGCeIdBEOvevTvV\nr1/fh3eY+beWpaIoHyIqhCmKoiiKoiiKoiiK4hKrFwA8ByCAHTp0SMJqFSpUiBRFUQKC8TKCNxc8\nu5w9vwJyPniJQQQLHTq0hE40qBjmNyZc4oULF6hixYo0ePBgmjt3LmXNmtXhOA2XqCjKh4qGRlTe\nKceOHaf//e9/slPnfYFr4x6WL1/OP/fKrqPgyNlz52jHjj95UfiUPkawY+vEiRN09epVCgiox6NH\nj9L169foYwa72f766y9auXKV/ETYh+AC6nDfvn1yb3v2/I/u3LlLHzr37z+gP//8k/755x8K7mzb\nvp2OHjtGwRl8Ed21ezedPHmKgiN/8xi0g+v7bQkOc9v7xNTzv/9eJuU/ENIH+RaC6zpDURTFE4yh\nGmNa3759qWjRouL9deDAARXBFEUJMGZsgQCGtdLbimBWEBrReIiZUIn4Xq3h/TwDghjGeIz5NWvW\npCZNmog4hjJEPTmHS9QyVRTlQ0GFMMXORTb8tm7dlrZs2UpBxY8//UTffve9xHp+H8BY1659e6pb\nrz61bef1c/eePRQcWbVqtSw4Tpz4mz5GIOj8On06rVixwv7eqdOnaOKkiXTz1k0/P3/33l0aPWYM\nbd++gz5WsGBv1bo1t9N61LpNG6pfv4GIo8EBGEO6detODRo24r7UjmrXqcNCQPDsS/7h8uV/qR2P\nDTNmzKTgxPYdO6hFy5Z06dIl+R1fNho3bkKjRo2i4Azi+6Od/DxkiP29v//+m5q3aEFHjhzx8/OX\nL1+mxjwO/rlzJwUF48aNo+bNm9PbMmPmDJ5bOsj9Anzx7tGzJ0375Rf5wvix8w+3yzZt2tLKVR9+\nSF58sf/hhx9oxIiR/hI2Mad1796Tpk+fYX/v9Okz1KhxU9q1axcpiqJ8iBiD59KlSylbtmyyUQhh\nEGEcjRo1KimKogQUfJ+BXSiobEMYu7CWw7rcOW+YCjeeYfKHIQ9k2rRpacCAAVJ2+H5jFcWAimKK\nonwIqBD2CQLD5KzZs+kpLwisnDxxgv5Y84d4QwQVL148f6875hctWkxr1qyl9u3b0d/Hj/GXusVU\nqGBBCo7Y3rymZ8+fyYLtY+XVy5f0wvJ8Vy5fEc+i69ev+/lZ2xubxBEPmJHZRrt275IksMGZefPn\n0+rVf1Dt2rXp2NEjtGz5MipUqKCUz+TJU+T53xd//LGGFi5aRJUqVqSDB/bTWh47PpZdwc8xTr14\nP+PUqdOn6bfff/fR7zEuQxw3bRZfMPCl7n22AU95yV88MZYZrly9Ku3n8OHD9vcgrE6dOlV2hFo5\nc+YMrVu3XvKQBAX4UvzMaS4MCBiHcB4zHmGeXbXqD9qwfsN7q6O//toX6OWG+XvS5Ml086bjZgUv\nQ0Pgz1fu2kVQgmdcvmKliHrYPOMpOHb5iuUyLhpstqApF0VRlKAG6wyM7ZhH4AE2ZswYFvqnS8gs\neAooiqIEFCOWYI38+PFjCkpwHatXmIphAQObHyCIYdNfmjRpaObMmXYxzAhjVrRsFUUJrmiOsE8Q\nhFcbNXIUlf7mGwoXNqz9/cKFC9P8efN4YktNHysnTp6QhU/TJk0kXnS6tGlJCT7kzZuXEidJTEkS\nJ6GgBEZVhPMryCJo8uTJKbiCcGugfr36FDFiRErJL7BgwQKawsbhWrVqOsQ9f5ccP36cIkeOTNWq\nVaUoUaLIS3l75rP4iRB7EBgR297QqmVLKl6sGGXOnJk+dL768ktatGghZcyQwf7erl27adiw4fRN\n6dIUKVIk+/tf8rELuEwyZsxAHxLx48en2bNmUIwYMSRh9/tg6rSpFDt27EAVqBGKE55S+fPlo1ix\nYlFQs3u363YRlIQLF46/3M+Q/uefcQ3lsWDBfIr8ju5TURQlqIAB8969e2L4hLGzT58+1KFDB1IU\nRQksTLjVwAyH6Btm4xtyW+GFvFaa28p/mPxhBw8elPxhY8eOle+uSZIksecMs+ZhM2KYlrOiKMEJ\nFcLeM9euXZMdKokTJ5aFwJGjRwnTRLp06ShmzJguJ40bN2/S+XPn6NatW2Jsy5gxo4PBFLuSET4r\nYcKEYiQ/wBPVzRs3KHXq1BQnThxatHgJPX/xgk6fPi1GnvDhw8ux2JETOXIklzuX4a5++swZunL5\nMht7YlPatGnECP7y5Ss6f/4c/zsKxY0bx+EziPOM/E84d0RvA747sDDB+bHDBEYk7DKBAdGABdI/\n/1xiA1VYeYYrV65IWK0IESJSrlw5JRGqX6BcENc4QoQIdPbsWXkP54oWLZr9mEv//it5qyLyedOl\nS+sj5AfKFXWCZ8K5EOILZZw9e3b7eeCtc/gwQn7ZKFWqVLIwcFWPeNazZ8/Ri5cvWPhJTClTpvR4\nkXD79m06xkLE61evpS7ixo3r8Wex6wrld+/+PYoaJSolSJiAwocLb/872iPaJTwa8Gy4f2cDJJ4R\nZY5nxnPgfDD2olys5WkF4hPK7zXXJZ7XFW/evKbQoULTm9evKUSIEJa/8EKZv5BfvHCRwkcIT4kT\nJXb7fGZRff36DX7WR2IIxn2ZRRna0pEjR+kG9wkc9y/XOYjDx4WytKMHDx9w275AIfk+EiVKJO3d\n3TM94jKNxG08QYL40hf8AveA6546dVrKDXWI9m6tQ/QJtDFw69ZNeRa015fcP5ctX8H99CWdPHWK\nInD/Rf/CMxrQl+E5dOHiRS6rRNK2rIIZ6hihbfBceH///gPcV69IWX3xxRcun9UKkhnj/Pgs2grq\nKnr06PJ5gB13586d5/50icKGCSPXd9dGMbYc536EMco6tljL6vLlK3SSRWw8J0IyeBqKx69xxS+w\ns+3kyZMy9kSPEZ2+4HHZ3Vh27959ORb9JnXqVPJFwbENe4G++/ffJ6TtwXCO5zXPg/reuHEjfy6k\nnCsMl50pV9Qpxi7ck3W8d4Wp/3Pnz1MCniMw9vslxiCsG+oSwjDmgFPctq5cuUopUiR3Ozahr2GM\nhxcbPDQ9HYvwDOgvZq5BP0LOxqfPn9EZPtcDnjtwvyhDtKWoUaNIm8XzWzHtEGF9UYZp06Tl+o1u\n/zvOjz5wkV+hua361g49AefDuZC/EeNU8uTJpA+5Oh+eEc9gdpziGNwv+j1Ci6Bt7t27lx5y+0+a\nJCllyJBejsFzHjhwUNpJ/PjxpD+iHTiDdob6vX3rtsy9WDNY50HMDxAXITpiTgNoR2hPBszR+Nt9\nrvs03EawDvGtbNCu1q5dK3MIro12iHHVeTMBnv3QoUN0ldtTnNhxZC51rjtTnhhjL136h/A1GRtT\nsKYxYM7ewP3B2i7wjJiT3PUtvNDe8WyYnx8/fiLtEue1PhvaO+YA1B+ewayTIDRjLA3B74XwnjMw\nfqCNYvxwLh/UF3bHYr2GuS+0PzYm4B4PHT7s5zyOcf6Cd3nHixfPPpe5GvcRivGffy5KGTmP+wB1\ngzrHvIUyjO89PryvDRWKogQ/MGchDGKjRo2offv2MsZpCERFUQITjDNYT76r8OFYX2GdhO8VWP/g\nd6ynzBpd8R/IEYm5AV7CpUqVko2LPXr0oGTJktnL1IiNiqIowQ0Vwt4zQ4YOpQNshC5arKjkpDFh\neDBxtG7VSkL4GSMYFgtNmzaTXDFWsmTJTJMmThKjGUC4qVq169DPP/8ku/hg5Aa1ataUPCsw5IEq\nVavJz2xZs9KcObNp37591LhJM+rSuRO1aOGVMwUT2Qw+x6BBgx3CRyVNmoQ2rF8v4ZGKFitO1atX\np6FDfna4rz/++IO6fvsdTZ0ymUqWLOm2DBYuXES9+/RxCH0EY1fv3r2ofr168juM5S25PFKxYSdr\n1iw0aPAPYoDKkCEDLZg/z08hDF/ovu/W3e56X7yE1/306NGdWjRvLs/Wu3cf+n3uXPtnIkaKSD27\nd6datWrZd7R06tSFnjx9QgULFqAJEyaJGAFgZB86dAj9zQamcePGyyLL1GOHDu2po2UXJUSjFi1b\nSfJRA46Dd9K4sWN83fUOw+Hs2bNpwMBBDtdoUL8+fff9dyxohXP72ZcsuK1ctZpW/7GaXr38T+yE\ncXTQgAEUkg1hK1etojVr1jiEKIBQWr9+PcqVM5f8jnIYOmyoiFERIkZwyNGFeylXriyVL1fe/h4W\nuDCeLlm21H5d1Beel5zWRiiTKVOnUe9ePXkh5WVchVCINrJp0yb7Yhmfr1C+nI9nRG6xSZMm24VO\nA4ybTRo3FsMhdjHt8A7/iWfFC/TiayZP5iUCLGOjPN43hno8V4UK5alM6TLSFvA+wmYhvJupB3fP\n7wwM899/9x3tZCO12SWFzzVs0EDuAYvzJUuWcH12s48H5cpXkJ/wAFu6dJkY1EGFChXlZwFuj3Nm\nzZJ/QyDu1LkzGztP2q+Zno3sI0eMYKEgjfwOI3bVqlWpG1/j1+m/suhyyn4sjB1TJk+iPHnyuLx/\n9KXvvvue+4HXvSFHGGjUsCH169dX6uqHH38UI7MBRlY8c7NmTe3v+TW2YNxDv+/UqTP94V1HACJZ\n9+7dqAaPOa6M4YZJkybRqNFjfIwrA/r3l3L0CwhbDfiZrDkTIaIN+flnKl68mP09tMnJkyfTTz8P\ncfgyB2Fi/LixYowG+PI1ZsxYmsj3ZQ23hnsaNHCgiKgNGzW2h44tU9arfdeuXYt+/OEHCWcLz5gV\ny5fJlw93HDt2TPIfYqODAUbxYTw+5c6d2+3nUMZdunSlXj170ASeT7DRwgCPorFjRjt4x+AZevXq\nLeE7DWjH33zztTyPVXBxBv28eo2aNHHCeMk3UrFSZXturdp16srP1KlSsSi4gQ5ze65SpSq3uW+p\nTevW8jeIS6tWr+br92Hh47/7hKgxf95cEQcQyqkn35+Z7wDaYcsWLahjxw5+ionOoF917fqtCEyG\nECE+pxn8BbCgi/C6EDrxjFm5ribwc+LaEL4wx/700w80kMdwaxnnz5+fOvB8j/Z+yVucB+nTp+dy\nmiD9AqA99+vXX/rhc8vYAzFqCs+1KLf58xfQt9zf0B4xluEFrGUIr1KUjxlLUHdff12Kfhg82OVm\nBrTfRo2b2EMttm7dxqtMuRy3b99mPw7PVILne4j8Bpxv5IjhVKRIEft7m1E/PXuJIG8IFToUNWrQ\niOfq7+gRPydyIx48eEj+ZtoF6nbliuUuBW3k5ho5ahT3l8HUp28/e1/COFG5ciXq36+fXZBbz2MM\nnn/4sGGSl9Ksk8aMHsV9MYFcD3Mj1kYYpyZMmEjLeQ7LyuslKxiPu3TtKuutYkWLUrXqNWRdMoPH\nVXeYefynn36WTRSm/J3ncXhjNGvewm1+MRgdfv9tjvzbVb/PlCmTrMswFgGI6zgGAqEVCHAYV/BT\nUZRPGxMqDLv94QEGTzBFUZTAxIRd9U/46cAAay2sDbEuNC9j41HBJmAgfxi+JyJnNQSx1vw9o23b\ntlLWqGPzXd3qJaYoivK+USEsGCCeVlevUts2bST/D3ZR/8xG1TFjx8ru37p168hxMOBEihyJDWUd\nqVDBQuK9tWTJUjb2jqbJbADra/myAqPVoEGDWMSIQD/++IN4hcC406RJE0lwid3PMHYbjzC8XLFo\n0SIxdmKneOdOndigmlh2J8OI6GqXekCIEiWyhPwqX768eABghz+MeDD2IXwjdlobtm7dSmtYVKnA\nx37Df4No5GqnuTMFChSgJYsXUf/+A2QH9qKFC+R9Y/iBEAcRrHWrllS2bFkx5kFs68fHw7iKzxsg\nNGJX/8AB/dmIm5WOHj1KPdig15In/lAhQ4mIiIXA3Tt3qP+AgbwwGE1VKleW8wB4gaC8e/XsKYas\n169f0Wg22K9dt07uoVnTpm6fY+myZdSXDXw4f5MmjaUeILz9ygbAmLFiipHT3QID4g+8LpJxGX/9\n9dcULXo0uvzvZVmghPTeDY72kDlzJsqZI6fd8272nDmSWy1d2nQOIt1+NmajbiAkJkyUUETROXN+\nE8Ng5kyZ7fkD9u3fRwsWLhShthqLrzFixhBvgZUrV7IA8pyS+RGZEAbLDRs2iKG3apUqFCZsWNqz\nZzfNX7DQx7HwbIsWLSoLs9XEOyREyBAsoG0W4+1ONiaWKF6cxaMK4pEB42apUiUpX9588lk8L4CA\nu4oFwRw5snP7K00vWeyEy//ixUvkefPmySu76ZctWy5eHAgLEIH7GUQ4GMvTpfvC7bM848V3czZs\nwlgJgzxEAxiiJ02eQr/8Ol3aRuvWrcSwvmzpEm4/A2jHDq43rvewYcOISFWTjet9+vSVXf9Tpkzh\n9g+PMK96QX1BMH748BH9xGIUBJOdLH7/PGQI99/ONHfu7w51+H23biKO/MZ1HCdObAlD1pf7Hdrt\n0iWLXQrMuLelfG99+vYV74MhbGiF15ERPtCfc+XKxaJhafE0uH79mhilf/zpJ6pUqaK9P1vHlm7f\nf89jXVyHsQVG/MEsAMFg3pL7FMYHiGsQnPqxmAUh9quvvnRb1nhOV+PK6DFjqHTpb/wMebaMyzxT\nxow0mYWrZMmT0V8sYgwYOJjLpy9lz57N/rwQ/n4eMkwM5J15bIbRf9u2bTRk6DDZbLB921a5FxiV\nRowcKWMJNhvgOOS/2rptu7Q1jEW/sdG9C4stoVkQGMp1ZjzCPAVl1pjFCoiUP3N5Z8mahY7weDX4\nhx+pXfsOtG7tGj+fGyI7xquaNWvI2DDnt99YNFkobWXC+PH243r17k2LFi/m9lhD+tubNzbu5wvo\n99/nioA5nQVn34RKA9rDrJkzeLwdTFt4fJ/Bn4MAEcYXDzb05TZt2spnB/A4DOEBfRLeUfHieXkU\neXmIpWFxqT0LAhml7aAdjmNRqkSJ4v4KMQmvt8ZNmrK4dUfGWGyEeMBCzSkWkOGR7V86dOgoAmcN\nFk3wJRGGRuSA27NnjwjQQ1i0jMKCL3LFzZo1m8aOG2ffaIL5DhsQINIWL1aUx9OYtGC+V6jU4cOH\ns5Azmopxu589ayaPBW24vX1pF7/MGIfwyJ06d6Hc3E+xnkD7nDtvHs2cOYsiR4osoo4z6JcD+vej\nX375ReabsdyP4Pn42Wefy3kfeAvO06b94nJMgeiD+c6MKXH5M/A2RP1gzoGXMepnBreFUqVKSH8a\nxf0FYRhXrFppbxf4vF+eCdj0gr6IcM8Qk9DnIQ6iL/Xo3t1+HDZ8dO/RQ8rUrJPggefMNzxfoh7m\ns3joLIQtYUESFLWIfH5h5vHcXNddu3R2O48PYEEZIlgf7mvYjIK5ohs/2zqeE0eOHEElS5SQ86Ft\nm34/bOhQCSOKDSoQBbt++y3NYdEN/X4891/0kx9YKERoyydPntJf+/4S70J3ntyKoiiKoiiBCYQn\nbAp61zl08b0E35VwXay9TGQDDZH4duB79ogRI8SDuF+/fhK9pTuvt+t5b2hHGaPcjRgGtLwVRXmf\nqBAWTIDnU9u2XjusYVhLljQZVWJjJESI8uXL2UOFTZo40eFzndmgCuPMEQnF9x9YYEBkWMQCBFyU\nrcAYhN3pMFL7ZmSFge7nIUPFGAsRyYQ9QxjAwKQ4ixN4GRBuCkafoWxIRsgtqxCG8HgQXrp1+95f\nEyieEy8Y0PA8Zoc0QFgtGMlg4P+eDfKGaHw8PG6wy9wqhIHv2KBeiw3FAOdav2GjCCj16tYVwdBM\n9KhTGD0hlhkhDGU/9/ffHM4Hz7RNmzf72KltBWGUYGTEeSA+GEEDnmjHS5dhkWMe1a5Vy2Wdoi5X\nrlgpQksnbjMI/QhSpkjpcBzCaOFlgBB75uxZLy+xJ499eKvBi8kYDhPETyBtDp44EHqwKMKuK4S2\nQs6VpmxINuJYwgQJ6enTZyI4+QYMf/DIQftHjiTzbEmTJBGPiz17/udwPAyarVu1dnivYoXyYvi9\n6B1mEJ4EJrdNtGjR7fUC7t27K/WA+2zYoKHcN2jDIjW8ZVav/kOEMBj60f5yZM8hXmQAxuAM6X3P\nY7Rjxw4JSwWxFB5Spg3nyJGDqlarJgbvOnVq29trlCheBl+EFjOh7WCwhLcixEuE07KG6kM7/pfF\nTXg5QHQCX3yRTkLeTZo8WYztEFEN4vEwe5Zd1MaYgLxkEJvxmcQuQlji+nhFiRxF2jK8NOFxZHDu\nz6lSpZTnRfmZ/uzJ2AKvPgiwVVj8RL9En4J3DNpgnbr1xCD/5Zf53Y4D8OTEy2DGlcksOkLI9ksQ\nwj2NHj1KRFMAUQX5kSD2Xrt2XeoH7WDChAncnmKKJ5IJL4b7hNgNj5Op06aJRygM/bhXiJ/GmI52\nBtHCgNBryNsYhkVPfInwb24piHIInQuvNXjAAISbQz/q1buPeBNDoPQN5OkbPHiQve3DYwsiHnLq\nff+dV8g11M28efOpCAsNP/30o70O4J2Mfo2xEAImPGT8QtpQqlTSF+FdlIrbYPx48dweD+/BsWPH\nyf1BmENoXJDDaV6CCDx16hT772jbph3CM8ZTIQxz6cxZs6T+ME5bNyqUsLRz/4B7hpefAeM5vJQx\nhsDzzng7dencmUXV7eKtbUA/6McitJWuXbvIRgqEGcTu2ujRo0mZhgoVQs5lne/kejy3IiTeeBYF\nY3uPhWjnEPbQ91u2bOFj3YA6RnuN7S2mQcRyPi+IHTuWyzFlrdOYgs/OnDHD/jkc147nS3gsIfQk\nxkRsfsDGCU/ahZUyZco45LLBHFWOBXGI7/AMNoIg6hbCGoRY6/M6J/eGZxXubxX3AXiVmX4OgRRj\naj4WlTBeYDOIX1jncXjJxfN+Jlfz+Nat2yhlyhSy6QVgzOrObXDFypXiSWfuAyKdj37P5XudBTJ4\nq5p+j2MSJ05E5cqWta8p06f/ghRFURRFUd4FxuvUeO2/j+tDCMMaCmKc8QxT3h6TPwzhEiGIbd++\nnXr27CnvG887a7hEFcMURXlfqBAWDMBulCJFCju8B+MxvARgBEMuC2O0gAEZu3eRV+QeCwEveCKH\nQfCWJTyUATuUnY1Z/gFeajD0wIPGGKqDCoR7wnNi9zaMti+8F0f43QqMQw0bNgzUiRPhqrBLBbvb\n/8f/NuDaEM7gpWIWSgBGb9SNFZMjpXDhIg67XWD0gzEbXn5WcD7UI4xikquEDVQRI0bw8bxWYLzH\nC6HW/vbO+WJAjpi//ton53IlhN25e4dfd9lAWNougrkCCxQY97E4hUH12fNn9t1az54+czgWBtZE\niRI6vJfAO7+LeQ4Yra9eviLeiFaxBCDE5dp1a8k3sNMd7QFGa3h6WcmdK7cPIQygj+AZsNv/MX/2\nCf+EsfO+JUSeOy6xiITPoS1Yw5MBtAV4XL16/Uq8d1DOCAuHa2RmQykEHr+8JOExBuDZZm3DWIwj\nVOH333ej48f/ZjEiD/kXtOFdu3eL1+jnn3/m0JbhQQLPDbQbqxAGjwLne4ZBHHWOOkycODEFBPRn\n06dRF/f5XHhG0y48GVuQxw11j5CBf1mEgPv37kvZ4xwY/8L4EhbV1biCvofx0y8gRDnnPjJhDm/e\nRNjHdBJ279bt21S3Th0fOXYQLrZ3n74iggN4LUF8QCjI+/cfUNGiRUTQDSzPWoCxDMIo6tta/+Ya\nZ8+c8fMchQsXsotgAO20SuUqEu4SQiD6sakPeJY6t+MaNapL2L5DBw95JIT5F3g7QsiCwJczZw4/\njn3o8LK3Qx53PQVtDHUIcaksCyyBQREn7yGzQQBCsDXkH+oBnrTIjYgQrMabyswfT3l8Rd4seAJF\nYnEc7710kePTCj4LzzMIhchJZ/IQAgjsGPfRrgO6dijBgp6rMeWFizEF4wxyeqGPwqMM/QKgj78N\nEJutYGwuwnPzQhbCEBbWCGEAGwb8elbM6TW5XSPUMzyU4Y0OTFjQ2hbB3S+s8zjmGOs84zyPI5wx\n4gdjTjPrCiPSvXjx0vvnCzp46JDLfo+1CjD9HuE34ZnXqnUbqle3DvefnOoJpiiKA8ZI7bwhQFEU\nJbB4n0KYSXGA781YX5lcvhoeMfBAuES8Ro4cKXYHbFBDyER8r0Z5O+dn03JXFOVdo0JYMADGCyN0\nWUmYMJEYOeD5grwYl9kIjxB6CPMGgxKMTaFCheS/3/MhSIBUbMx/GxBCR+6DRYyA4MlXKCxEEN4R\nu0fOeSeDh6HS3eIIxh4YiwKTC+cvyE/k4MFubGeiRokixkHjeROBhaSITuEYQ3qLZDFjOIpQIbx3\nvVi/UJ5iYW30mLGykxznRci7ECG4Hv0w/nkJZw/YGH2UFxcNffwd3lAP3Ig9t256CaUxYsR0e/6n\nT5/Qnzt30e7du+j69RtSf3guk0PGGeRFCxnS0fhvxELzvHg+5ECB2OG8yEEYw3Bh3ec0AxAKkSMM\nxmEIOVaiuRD8IFQtX7FCPOvQhkJzW/qc7wnniect0vkGwlmiTSIvzdEjR338PSz3OYh78CiDZ+Li\nJUvEqw1h9OAFBPEZnkMh3OQfusAGbfR1V3ngjLcDdvoHRAgTwYmf8xELBd179PTxdxFaeSyxAm8L\nZ5CnhwJoBDH9GQZiiBU4h+nP1j7tydhy4eIF+Tl+/AR5OYNyfOVGCMN9wEsCeZA8GVdcAQHCuc2a\nvFKmbOAZhvYALxhnIIDD2+PGDS8vEYgdCCc3dOhQ8WjClwN4VCGOemB5Zfxz6R+ZL5Bnyhm0OU8E\noHgu8gQlS5ZUfhqvyvPeYyZESmfie/ezy1cuU1Dw6NFDCV0LL113X5xQ//DSnTd3roTCNTs/nduh\nJzzn+oUgHyZ0GLsn6duSwGksMuNmzFiO47PXF8UQDnMpRJRZs+fQ+nXr6CaXA/KUYf7AvxMl9Huu\nhgCNL/8IT+tqHoHY5m7M94SYHo4pWMcgJOzBQwfpcx7bsZ55m+taiRfX0XMM5QgBF331utOmlFQp\nPVsnlShRgrp170Fz580XIQxf5OGBCZGtZMkS5Cn+mcfhLQov34kTJ8qmAYhfPw/5mSKED08FvMPC\nPpP2ed2jfo/Q2Ogb8Gpt0rSZeKVBCGzcqJGf4SYVRfk0UIOkoijvgvcltuO73HPvjZFGDFMhLGhA\ndAasX+EdBkGsR48eVLduXR8imNVLTFEU5V2gQlgwAIYMVzGSn7GIgEkBBlVM0s2aNaPjx09Qg/r1\nqNTXpURciMTiTNVq1fnvr318PpSTSOFfwnrv6oYYFxAePvDbA2f16tXUs1cv8ZYYPmyo7BxH+B8I\nCwMHDfZxPIx+gT1Rhg7jZUjv2L6Dy5xDMAxa85B99vlnbl3oncUaZ+CV0KBhIwmh1LJlS/EKicGC\nDryQKlWu4utnzS77UiVLus0j5uzBYhBDJPPKl1jc27ZvlzxYCKlVp3Ztis9Gbgh+CG2IkIDOfO6d\nYNY3JP8YLzhfufBSwOLTr8+j7HmJ5PK+bdwnrDx6/Ejy5cFDogSXEfI7QSx5Y3tDP/30E3mC8eop\nXKgQ5XEjRkHAA9jRjzCYCAOJPC77DhwQAa5WzZrcjr5y+VkIcy+5P7la/GMcAFZvHP8gZcXlCW81\n5Adz9qADzrv/A9MbCZj+jLLp3bsXfZEunVwT5QNvCoMnYwvGPTxP3759xPvHGdSVu9CBuA/k/UOu\nMudxZfiIkeQJnpRNaO9+5e450K8TJfxvkwI8SWfNmileH4uXLGYRdTVt3baNpk6ZLN4abwvKA+MJ\nDOfIHeeMJ8ZueFw5g+cAEb0F3JAhvca/5899Prfx5g0bxn9hHT0FY4qIWs+euT0GeamQSwkbE9q3\na0vZc+SQcnFuh56ANhiGn8VG96WeQ4Z8+2WTs/eg4XM/xkNsLEBYQ7TvcuXKSa475LVC265fvwHd\nf+C30GlyryEEZrfvfZaFEY0Ciif9Zv/+/eKVhHm1J38pziIev9HE07B16zb0tkAsdebJk8fyRTu8\n0yYW04f9Ah5ayHGG8LYQRrFhAZ5zjRo29Nc46p95/Ltvv2XB8jD98ONPNH7CRKkbzCHdunWTkKXA\ntE9P+j3GXeRkw/yO8KWzWRBDDtM//9xJM6b/6nKDhqIonxZmfapGSUVRggqTI+x9YPJVOXuDKUGD\nCZeICBSI6jRo0CCaN2+eRPtxDpNonXd0DlIUJShRISwY8PzZc9nljTwU9vfYmAijetSoUcQTCUaX\nw4ePSAjFPn1624/DRH7r1m020ni+mxfzyhsnEcEVCGGESejY8WO+7JLxMsw8eexoPMX5rSGX3LFh\n4yYx7k0YP84hRNrt23foXZEmdWr5CZEK+dncERiLJOzChzcMQql16vhfDhN4ibkyQFtB+aCe4fUE\n4dA/C4RYMWPJ8WhHruoSQhO8oJDXqFrVqvbwVZJr7ukzCigQGdGGkRvGeGUYEP7pyVPfPQBgwIOI\nd/XaVYfwUOD6jesOx8IoCQMlwo5VrFDB/j52yj93Fiq8H99mc+wH8MiQMIp8b0kSJ/FI6EMIPeR2\nysOGZRgiN27a5FYIgyCDUIrwUorr5Hlz4uRJ+Zksud8hyT6z3/9/bRICGjyQzvO5EcYNbeRdY/rz\ngP797IZa8OjRY4cvPJ6MLSm5rOSL0stXvvZLd/eBcwb1uIKQnzBsnzx5ysffkKsNnrvxnbym0Afg\n8Zc7dy4qXLgwtWcBHrHUIYSZcrC9CdhYg9ySBw4clHvyb5kZTrsInwhjvJzfO4Rc6lReY+bhw4ep\nWDHH8IcInwiSJPW/mPLGg+fGGIV2fvrMaelL8I5xBiFC79y5Tf369aHyLBgZnNuhJ6As48SJLfPZ\nuXPn3ku/MmAc3fu/vSIw9+ndm4V+L+ECfQ7eoGTpRu7aUqyYMXlNEUk8SDFuhfYltKhrvM7ryRrC\nHfDWg/fX4EEDZaeo4eGWLS6u9plH7cLKqdNnqFChQvbfsU46cvSoCMWe5hlzRdWqVcSTDV7AZ86c\nlY0v1apX89c5rPM4cpf5lpfiDY9/EKEhmiF3JEQ8hFO1eiaaZ8K472m/hxcbduQiDy2EyIWLFkv5\n5OM5TFGUTxvMHcY4rCiKEtgEB+EJ11ch7N0CQWzz5s3ynbdGjRqyuQz5w7D5zuQOM3YeFcEURQlq\nPiclWPDr9Bl2jxAYbVauXCkGyZw5c8lub+NxEDp0GLsBCgY9hGa7d++uv64VhcUFiBB37/r+OeyA\nzpo1q+wW3rJ1q/26+AmhACCsH0LOHf/7hD1RPP4Oo8qOP/8kv3j5wst74HOLMejfy5dpydIl5B+2\nbdsmocYOHDxI/gVeIzAszZ4zR7x7zGJI8mWxEcqvcvIPxoMC4o65zjMWPadOneZDlHEGIceyZM4i\nhm4Y4/xznzCYJk+RXHKJeD3jG+/PvpGd8vT5Z5KP5A23vTDeHnL426V/L8nxAQXiTFI2nl+/fp32\n7dtnvy4Mt3v+9z8ROXwDBrt4ceLQiRMn2fD4n4EefWXr1m0Ox5pzIZyjuQ760rbt21iodRTcYDyE\nARJhwqwkSpiI4vL1Dh44IHmB7HUCQZCv+cg7txREPRiezd+xYEO4M3jQ+eblBCEb4SQnTJggwqvX\nqW1SxggpCE+q1Kl8D9WF+44Q3us6EDatwEMEhtPhI0bYz2/uF3UQ1At9V/0ZZQzvJ+u1PRlbEGoS\ni+YJLC5eYJHTgGOQV+iZLx5BuA8JtfCW44pf4P4ysjCykg3jx44d+69P872NHjNG/l2wQEH5ic0N\nGCPNs2KxD0EJhnEj1KJdhmJh4uatmzJG+5eSbDBHG50ydaqED7SOEXd9yT9oZd26dSL4GCAwL1m6\nVOoss/dmjUKFCsq8tGbtWrp8+b8QiBCip06ZJmFTC7gRg90RJUpkadMmbKY74LWSi0XEf/65RAsX\nLLD3N8yHpn++8B5nrd5brtqhJ0AogrCN8HIzZ86yh62zttV3BdqzydsYPryX5yhyby1evJiue4fg\nNEAwRFjF8yzgWUUr9AuMEwhdivWDNVSkJ+NERG+Po7OWNuJf4M2HuoGQZAwQ5y9cpBUrVvo4NoL3\nmOpXu7Ayf/58h3ybyIm2Y8ef4j3nzmvaE4oXKyaea3/8sYb+WLOG+356Sv+F/8KaWufx+QsW+jqP\n79q5UzZJIRdfpkyZKRXPD2iP1rEPwjo2f5h+b31u1C36pAF9wBp9IByPN+nTe22qwVypKIpiUEOk\noigfK0YIs4pgKoa9G5A7DJu3sDkYm4kHDhwodYF1qHOoSq0TRVGCCvUICwZgF+9BFnCqVa8hBkbs\n+kYoOoSxadiwgRi0sFsiSZLEYqTs0bMnG3QS098nTkjidv/mLcmRIydNm/YLdenSVQynOH91F7ua\n8SWoe/dufA+NqEWLlpKvArnIkCcGxvaZM2dK6Dnc8+zZcyTUEfJW3GIjNQzcxijpGzAwrlq9hho1\nakTfsLEHeU5Wr1rNxh3/7VJfvnwFLVi4UHJeZM2SxV+fhWHr+++/o169elO9evXpS36GmDFiSP4f\neDcg/0eXzp0pMMicOZMYkJGLDEZAeEv9ycauY0ePiRePb8AA9t1334nI2KJlKypYsCAb9ZKJIHP2\n7DkJkzlu3Fg34eI+o7JlytDkSZNFhPmCRYZoLIheZyMZjGWdOnakL9J9QSvOrqSJfEyO7NnpIdcf\njPsmLFpACM31WKJ4cTrFRtfZv80Rrydc9/yF82zY/NfBw8sVMPJ9801pmjJlCo0dN068aJBXDN6S\nd5yEPxgYY8SITtt37JCcOmibEM/gbecczix2zFiSd2zXrt1sWI8s4l/uXLmlL1WpWlU8u8aNH0/Z\nsmejmNFjiMEbBn/kp2vSuAn3vb/p99/nUurUqSgOC2dYp8E75gobGsuXL+/2eSB0Va5cSUIC1KhZ\ni0WSAuIVhx1SN27eoDGjRvkZZgtlkiVrFjHE9unbV/plzBgx5bylv/mG1rI4AUNtufIVpD8iX9nl\nfy+LSPwb1wE8rYIK0587duxEFSqUp6dP+NlYtEVOHGtdO48tMPSibK1jC7ytWrZoLnl5KlasRIW4\nvaOsISbBiF+0WFHq2KGD2/tYyePI244rfoFnQp9syNepXaeulD+8Cvfu3SuG93z58lG5cmXl2LU8\ndg8fNpxysvCOfovQnpu43iFYNWvmFSINfRxh4mbOmiUh/PLz55GHCzmJPCFfvrzS39AG4MGUjcVG\nCCYXWTRCnxk3doyfHiMIK1enbj0Z99AW0TbhvfM9P6fJZYmfPbp3p169e/OzNxbRC2WBMKoQ0Vq2\naEHp0qUj/5A9Wzb69dfpEtKwRo3qImy1atnSx3G4p6aNG9Oe3Xto0OAfaCf34aRJk0i7wJzzw+DB\n9OWX+WXM6NOnL/19/Lh8sUJZO7dDTylTugytWvUHLWLBCbnrMrB4ADH/zNkz4pn1rrzEINLDgxke\nb82atZBQm6jndbwOiBw5osOx8CRH7rktW7ZKmFCsGVKkSE5Fixalb7t2kVyQmPM2bNgg4hDqGF5O\nt1iEXc3CrjtPMXgxoQ5+/PFH+ufiPzzW2qh+vXrkH/LnzydtfPjw4Tx3nRExDyEHkZvS2UPqiy/S\nSZ2hXSCfFf6O64V34QlouHbtKjVu0lTmC9Q5Nhbhi3WbNm18/ZxfYGNH2bJlRBAF7dr6P4yjdR5H\nrgT0L3fzOAwEmLu+79ZNchZC2ERZ4N+YZ+DtiL9//c3XtJH7nun3OXPmkOOuXLkq5TuCyxn9/rvv\nv2ch7JWEDcZYimNRNlhfJmNRX1EUxaAGSEVRghKsU94mukBAcY4MYXK5q/j/bunLNgyIYsgfhvVu\nd/5eWb9+fYd6cM4lpiiKElioEBYMiMrCyKBBA0VM+u2333nQ/0yMTW3ZaANDKIDhacyYMTRgwEAW\nw9bLe0hK35cNXBAVjnmHowIwlCdMmJCisyjgiuJsQG7Xti3NX7CAJk2eLPl3ypcvJ4azRIkSOOTD\nys1G29/mzKFhbEiBcXcnizYQ6JCjDMCoA+MSFjIwqE0/e5YiRY5EhQsVlpBZ37PxymrYih8vvhhi\nTHilSpUq0TU2fs2dO5fvZQobgSJQocKFqVnTJlSrdh37vWDyix07Fl8nho/ngeH8DF8XhvNMbET2\nDYSjS8jHOYNwgAgvNGz4CPE0wq5pCAgp2EBlcvfgHiAEIueU82QMUQVlbnLnGMKy4QyfMQZkeDiN\nGztWclatWLFcdvinSpmKpk2dIvm5QlnylcRmQ1XChIkcDLfp0qWlxYsWUv8BA0R4QZ3gPiHclSlT\n2tf8NRkzZKRmzZvTWhZQIKK+5oUg2kr27F4h7L5hYxq8DZC/CHUZNlxYaYfpv0gvBuD/3NX5eVlI\nigCPBKc1SchQIeUZI0T8rw2lTJGSxY4WtILFStwzvKgSxE9ADXnxg7xkVuEOohQ+D4OfAcb85iyI\nwFtg796/5D7gidO0aVMaNXqU/Vr4XO3ateU6KBfzXlNuS0eOHPXyfDPX4fqoW7cOC1LzxZsQbRT3\nCSEsA4uEnTt3kuud+PuEGNE/D/E5RY8WnYXMLPb6hnCJ8yKkJNoD2mrNGjUcQnI5g3sfOKA/pUqV\nkuaxGPo7t3vUAQTcbmykLM4ihhWEMUO7cjbeV69WjQ2cZ/net9MU7jcZM2US4QllOZrFtBnZZ9Ki\nRYvEUwmVhLoswKIbxhqAPoy2ZX63graakO/Hr1xluK9r16//F6eR/uvPC1mUnj59huSryc6iapMm\nTag3CwbuxhaMK+hz1rEFZVq9enUp68n8jNu275C2A4+6lClTiDHXHbiPo8eOSzt2HleaNmvmcB/O\nYBxMmDCxy2MQqhPPHcoiEmRlUXLChPE0issdYhfGQpRrm9atZGw0fRKG5rg8xmzdulXuC3UKb7Ce\nPbpTVR5/DB06tBePsL+4rcMrEWHRIBQiB5DXGBPSXj74PVas2A73OGTIzzRr9mzJhwaPLQhuuN9c\nOXOy6B+d/ALCzl/79tOaNWvFEwfC/YD+/alWrZoOx9WsWYPbSFgWzqeIxxhAyMJhQ4c4iMGYu9Ce\nrG0tcuQocu9hLH2/RIkSPE40p6XLlnN5ThRhG0IYhG8ca/08xiWMmWN4LD144BD9j/t7KC4XhJxE\nX8aYPYDHSHjIzOE51bkdWsUQ1IEJBesO9PUxo0fKfLlhwybue8slX2XSpMns4V5xv/HiIdypV39A\nPeG+sdHCzBeu5lhgr8uYPje1YAyAt64py59++pG/PPajQ4cP0uEjh6V/INcXvI2X85xiHZJ79+ol\n4UD/QI5Hvkajhg1ECMMzz4YQNWIE7d9/gA4cOCD3jY0ZCFXo2zySI0cO2RiCNvbrjBkSGrlMmTL+\nGlMQDqV7t+9pxoyZfJ45ItbmzJFT7hc5q6ybAXC/pl1gAw/G6Mrcv30TtEbzOabzvS1cuEjGb9Rv\n61atRNz9r0695uwQIVw/K/4GL0Xnr90Yezdt2iz/LmcJuylwGUOksoZfNOsx63XMPD6c1xvwjHY1\nj2PzxejRY+Q5MQfGxIYnNgZggwo2Tv3vf3vF8xJzBsQz0++XLlnK7WCFzKEIG4o+Yfo91mXTfvmF\nTvD8D7B+y5U7t4yLCVysixRF+XRRo6OiKEEFxA2s19+HEIZ1oVX4sor+Koi9W0z+MKxrK1asSOPH\njxebIN43IpirDYxaR4qivC2fhYxTIlC3fL28tpY+FswOkaCkc5cutHHjJlowfx4bx1NJ2CUYLmE4\ncjXIS4grb08YhKp6GxA6DSISQiWGc+lF5Ah2wMMIg/BvroxQJk8J7su/eUewGx2hwGDk8i1nhivg\ngVCjZm366sv8YiT0zYjnFzbvnBy4nwjezxkUk61XeLc7YqAN6A51eHKhvFHWCBfmo9wurnT7WYRW\nwuchkIQJ7eiB9PzFc3r65ClFjBSRQoYIXK0cYhS6lG9ChG88fPRQvMx885pCeEe0U4iK4cP5XrY4\nFn0OxkpXdY0yglcTDPYw+jsqfzZ+nqdSlqiD8FyXn3/mwtskSRmX18aONPRlPAvqz7/tDG0VfRht\nFcZ25zLB39E+cB2c3y9Ps8AEZYJrQzjy5Lrw5MFzQChw1x/wd+TRQ59B+/GkvN5mXAkICEsG7xaI\nF+7Gb9QZclWhPWGcd3VfOA73jbCpEMACMqZhjMH94GdErv+wftTDvPnzxUt44sQJ4tkGEQz3GiVK\nVB8CvxW0L1wHfSiKCxHEvyDv1wPvecSTtoO2hrIKy4JZJB6zrOUOcfXu3Xvyvl/CrqeY58Umhihu\n6i+oMe0IdYRy8s3LzYQSRblANHNulzgHnsftPOIGlDs+h7xVEGICMk9CvLt//560G7/q+rF3X0aZ\nuxsjhg0bTiNZkF65coWE8cS4gvrC+YPrl2Z38zgMA7379BUv3q9YOLSCDSWly5Sl5s2bSY4vK371\nezPvvOK5D2WJfqEGheDBu/jOoSh+YcJSYZc+xqM+ffqQoiheILcv+oRvmx4V38EYY8KZw3b0rsFa\nEtfHd058n8Q6CGtQfNcKSNQIJfBA/jDMPdb8YZiHJN2BJX+YrlsV5dMjVNySFJioR1gwAzt8fQMD\n/9sKYAYYXSL5cT0rWCj4Zkz06+++AcNWQAUh5NB49fqlJLJ/GxEMoHyxMMIrKMFkHitWTHobsGjD\nzv6AAM+hsG7ETwhjzuJYYBE+fMAEMEOkiH63VzFQe2iQx7EQa9yBMnZvoP3srdot2qp/w5o6XJ3b\nKoQU423o6u++PVtQ4lv7coUnfS4gZf029RMQ/Cpvv+rMehza8NvIShhjAjRXeBtiYZiHcOIXaMfw\nvAws4MUSwR915ltbgzgHT+LAJLCfNyCYduQJXnON+zJAPQdkHkGZw8P6bUBIWk+v7d92AYJ6Hg8M\n3M3jyIEHXIV6Fk9cwprLZ3n41e/fdt5RFOXjRsOEKYoSlBgh431sJAPYJOeVp/YzB4FFef8gVCJE\nZghiSN9St25dCSNuFcGs6DylKEpA0ZFf+eDJlCmThFjLli0bKYqiKIqifMikz5Befnb99lvaum2b\nhI1BbrhJkyZTz569RKQuV7YMKYqiBAXqnagoSlABAQOb1d61GAYRTFIesLCCa5vrq5dR8AFhEZE/\nbMuWLbLZHfnDZsyYIV58eMGj0IS3NB7MiqIo/kU9wt4zmIi9pl2dfAMKvDDel+eLoijKx8Bn5PUl\n8DPdGal8oHz2udc66mPY3VumdGn6+/jftHbdetq8uYXkjg3xeQgJRYm8hG1at5Fw2oqiKIqiKB8a\n+M6BqATvMjwi0l9YRTD8W2xxKoQFO0z+sKVLl1LHjh0lpzu8w3zLH6Z1qCiKp6gQ9p5p1bIl1ahR\ngxIlSkiKoiiK8j7Inz8fzZs3V3IrKcqHSPVq1Shv3ryUInly+tBB6MlevXpSkyaN6caNG5J7EDkv\nke8ufvz4bx0GWlEURVEU5X1gxCiTlwuePUENvIgguiFkPq5rrm2EMA0JGzypUKGCvBAu8euvv5b8\nYRDEkiVLZhfDtA4VRfEv+k36PYNBHC9FURRFeV8kSJBAXoryofIxtuF48eLJS1EU5V2gRkRFUYIS\nM8YYMQwhEp8/f05BCYS2W7duybWMCGYVw9QjLPhj8of169ePSpUqJWJYnTp15G9GADM537QuFUXx\nC42BpCiKoiiKoiiKoiiKoihKkAKxAkJUmDBhgtzL/cGDB/ITQhheCMloDY+owsmHgQmXiPxhv/32\nG6VLl07+DaHTvOD5Z/6t+cMURXGHCmGKoiiKoiiKoiiKoiiKogQpxnvHeIUFVX5XiGDPnj0T8Qsv\nCG/GMwzXVhHswwOC2ObNm6lv377UvHlzatKkCZ07d84ufllFMBXDFEVxhYZGVJSPlSRlSFEURVEU\nRVEUxS9gQFTDsKIoQYk1FCHGHAhT+PnixYtAEy5wvvv370vYRSOA4WUVwzQs4ocNwiXiBUEMOYJ/\n/vlnqlu3rl3gNCETNXeYoijOqBCmKIqiKIryrrm4kpRggG4aURRFEWAsVDFMUZSgxghexiMMv+Nl\n8oW9zRiEc9y7d0/+DdErbNiwDkKYNSSijnUfPhDCUI8XLlywz19oS8bjUOtYURRnVAhTFEVRFEVR\nFEVRlE8Y6w56RVGUoMIqQlnFMIBQhsj1BCHDPyETIYA9fPiQXr586ZAPzCqE4T2TH0wFko8PtCG0\nHdSv+R1oXSuKYkWFMEVRFEVRFEVRFEX5hFGPMEVR3iUYa4xoYX7HC6IWBC38xO/I6QXMTwDBA8cg\npOKrV6/k3zhXuHDh7CIYfhpPMBXBPk00NKKiKM6oEKYoiqIoiqIoiqIonzhqMFQU5V1h9Qozv5uQ\ndhC4IG4ZQQzCF14mjKLBhDmEAAahDC/jEWYEMbxnRDD/eJkpHw7Oc5fZ1KH1rSiKMzoqvGcwsT96\n9Ej+jZ0s9+8/oE+Bab/8QnXq1qMbN27Y3zty9ChduXKFghIsoh48fChl/fTZM/k36uB9cebMGTp/\n/jwpXqAvjB03nqpUqUJlypalbt2622N8vyuO//03/XPpEgUEtKWDhw7R48eP6WPjQ3u29h06Utdv\nv/Xo2Lt379LBg4f8NRZcvnyZmjRrRpMnT6FPkQcPHtAhbg/4khFYXOJ+17NXLypZqhTVrFWb5s6d\nS8GRq1evUo2atWj9hg30MfKGjQwzZs6U1/Pnz+Q9zJnnzp21r1f8Ytz48TR7zhxS3HP9+vUgGUMw\nNh0//neg9s3gDp7VGMcURXk7nI3MiqIoQYlV/DIilsntBXErfPjwFCFCBHlFjBjR/m/zPn46v48X\nPotz4HxGCFNR5NNAw/wqiuIbOhO8R+7fv0+9evUWgxGMS506daZJkyfRp8CJv0/Qzj//tBueYVyv\nXr0mffd9NwpKfh4ylIoWLUpr166lnj16yr/nzptH74tOnbtQi5at7IlhP3V++eVXGjVqFL1ig1b8\n+PGlXLCAfVdcY8Nk06ZNacCAAfT06VPyL+fOnaNateqIAflj40N7tr1799L+/Qc8OnbatGlUu04d\n2rVrN3kKRPTdu3bRufPn6FNkypSp1LhJUzp16hQFBk+ePKHWbdrQ77/PpWTJkssX1ZcsvgRHMG/9\nyfMX+sTHCJtA6d9//6XTXLcvXnjN0f/88w+NGTeOVq1a5dE5Tp48+Rbl82l8aYW4GBRjyJChQ1lI\nrkVnz56lT4Vp036h/F9+RUeOHCFFUd4Oa+4eRVGUd4UrMcwIWq7EMFc/jQhm8oIZrzDjNaZ8vJi5\ny9SzhkRUFMUdKoS9R7Zu3Up/7fuLmjRuzD/30b+X/6WWLVrSpwgWOPnz56W8efNQUHLnzh26du26\niBzwAsG/ffNw+f3336lY8RIUVOTKlZNy5cwpLvsAO5rbte9A/fr1p08NeH6tWLmSyyQXzZs7lyZP\nmkTDhw97p0JYlMiRKXv2HJQ9W3ZZPPuXWLFiUZ48uSht2rT0PmjTth316z+AggJXz3b37j0qXqIk\nrWFh+UMma9aslDNnDkqUKBEpjsyaNZvF4WY+3s+SJbO80C4Cgz937qSjR49RixbNaeKE8TRn9iyq\ny+KkEjyIHj06pUqZipInT05BzaLFS2jk6FH0rjl8+DDP98VlbRCYQET8qkAB2sfrvHdB7ly56cv8\n+SlKlCj0IXHu/HlKlDhJgLyOw4ULK55wMH4pihJwdPe8oijvE+MdZsQw/DTeYcZDzPzECwKY+bc5\nzghgVi8wFcI+PYxHmM5riqI4oznC3iMwjnz22ed07NgxunjhAj1/9pyOHD1C+fLmpU8NLE6mTJ5M\nQU3/fn3p7NkzYiAaMWI4VatenaJHi+7yWOz637hxM0+eQRdeqGePHg6/w0sQxrLixYrRpwY8bB7y\nK3v2gIlQgQEW0aNHjaSAAmPxL9Om0fsAYUaPHDlKhQsXpKDA1bOdOXNaQnt+6AtMeIbipfhk8+bN\nLsOIBHaZIUwcxtxMGTOSEvyIGjUqtWoZ9Bt1Xjx/LmuiSJEj0btmz57/yTossMczeCldvnzlnY2T\nNWvWkNeHxvp16+VnQMopWrRoYvQKF06FMEV5G2A4RKhRNRwqivK+MAKGEbDMmGQVNcxPI26Zn1bB\nS4UvRT2cFUVxhQph7xEkAD1x4gQtW76c0qZJQ4fZWLJ69WoRwvBzy5at1KlzJ5o5YyZt3rJFvIXS\np09PnTp2pDhxYktoKuQowe7ZlClTUuNGDSlHjhz28+P4bdu3y7lgrEZOl0SJElPlShWpZMmS9qSk\nCD+3ePESWrPmDzHWhAkbhlIkT0ElSpSgMmVKO9wvrrl7zx7J5RWDDeOZs2Smtm3ayAQzaPBgSv/F\nF1S3bl2H50TOpVEjR1Hr1q0oU6ZMLssCi5mWLVtRRjaC4jiwe/duua+uXbvQggULaf369XSfnyFx\nokRUpmwZqlihgv0ZDP/bu5fm/j6XTpw8wYaR6PTVV19Sg/r17V5FBw8epIsX/6Fs2bLRX3/tkzwa\nuXPn8nE/165doxEjR9KWrVt5QfUZNW/eQt4vXLgQ1ahRg1Zxme7auYvatWtLGzZupHnz5tGjR49p\nyM8/ybnhebZ02TJ+hj10iQVPuOpnyJiBWrdqRTFjxrRfB2WGcu3Xty/tP3CARnI5QSBFvSIPDWjW\nrKmIQwhVNX3GDDqw/wDdvXePYsWKyUbjTFSlSmVKw+3HN7Zv30ELFi6UMGZRokTmeshMTZs0ptix\nY0vZI6zQ338fp06dOlGCBAkcPrvjzz9p9qzZVK58Ofrm66/lvRMnTtLMmTPp0OFDFCFCRH7mrNSu\nbVuH3dgov1gxY3FbK0GjRo0Wr8dIkSLR+HHj5N4NWNwizNiiRYvp1s2btH3bNilveMn1799PDFy4\nxyVLltLqP1bThfMXKFny5FSuXFkqW6aM/Ty3bt2inj17UZ06tblPPJEQfte4DGPGikUNGtSnktye\nt+/YIc9ynoXn6HzeAgW+ombNm1MYb488hCjt338AJUuWTMod7Qvt8Ndfp9MPPwymVatW03Lur7e5\nfl21Q3MPlblOjJiJtrLzz53UqlVLWrp0KfeztfTs2TNKmjQp1apVkwoWLOhDaFi4aJG09zNnzoqX\n0jfffE1Vq1Rxu5BD2xkxYoT081evXtLVK15tp3bt2vKM+FsofsbatWrRpEmTuBz+lLBcy5ctFdHx\n+PHj3McW0KnTZ1iQuCZhKUuVKkXVqlaV3XTOz1a0SBFasWIFjRs/QcaP8RMm0FKun5AhQ0hYSYhm\n+/fvp1mz59Dp06fo2dPnFC9eXMrLYxsMtKhTvzjAzzRx4iRq3LiReAkadu7cSTN4TMyaNQu1aNHC\n/v6p06dp7Jix4mVZx9uTCOV18eJF6VcnTp6kUPwsmTJnkn4YL148+2cR7m3t2nXUtm0bSpUqlf19\njHPTp8+QDQq3bt2WcbdE8eJcb7Uc7nX16j/Ee/TqtasUJ3Ycypcvn9y3b96MUp69enO/aSNj/8KF\ni2TcSJAgPpdRTbkO2s5CHvtwH7G4r5YqVVL+ZtorgIA0n+sO5YXxG+06F49pjRo2FMHftN+y3F/K\nlC7tcA/wwhw2bDi3jVDU7fvvxZBsf3buO2NGj5E5JHLkyPYxsFChgnIP8N7cwiLZt999x88c26HM\nkPMIz4R+C2+7Zk2bUNy4cV2Ww4MHD7lPLeMxdL78PpHbJ8b9LFmy8JzgdU2MkWgLmHvgrZMuXVqq\nx/MMjjFgA8Fsbm9t2rSmjRs3ybz3kPsz+lkL7uNoL3PnzuP7XkE3b96SNo6xE2Vi2jiw9oUbN65L\nO3HuC+7Aff4+dy5t4utjDknB83Itbu/58+f380sYymrturU8Rp8WUTt8+HA8xiSm0nx/6C/wYsYz\nIpcm2g7OFi9+PO6LReUZDRAub/I4WoLH3XUsLEBUsvEYG5efA2NgihQpfNzzpk2b6Bg/90OeXxMk\nTED58/m831u3b8n4lZnnjpw5c9rff/L0Cf3xxx8Shu/p02c8dibl8eobH2Mang854Hbu2slz2WW6\nf/+etCvM+YULFZZxCG1nGbcFHAcPn3E8VwD0J7QjgPFm/Yb1dPLkKdk4kYDrEc+aJHES69VoK88j\n+/btlz6Fdh2L512sP3Lnzu3QzgHWUNOnT6epLPRj7ujcuYvMP8lTJKcO7dvLveH+58z5TfoDQj6i\nPWf1bqPuvJCwBkM7/PGnn0Xk/Yl/YmzEPNiZ13ZWsNbA3HSR53/0YazlMB45jyHo7yN5Pj127CiF\n+DyE9IEWfA/WPoi5Gf2vM8/naL+Yb4YNG0YZMmSgzJkz0+gxY+jw4SO8zktOQ4cO5fuJ6OPeMX+j\nDVSqWJHrYby0j7C8NsyWNZt4beI5rM+JssZaFnlP79y5TfHixqPKlSvLGtLMj+hb43nO6NixA53l\nMpw6dZq05Vo8nqAOfvn1VzmuHZd5qJChZPyKzOuVBxJGvJeUmxV4Ii/hsaJu3TpyLMTa0KFD2dvb\n1q3beGycT+fPnZdwn/Hjc9vOn0+uh00viqK4Ro2GiqK8b6zjENYRRgSz5n1yDn1nFcA0LN6ni9a9\noih+oULYeyQJG68KFCjAIlhaSpgwofw7TerU8jcYdWFQg3CDvEUI24UwfgtZzIAhOHHiRGJ4gGgG\ng9maNWtY7NhOC+bPFyMhgAGoTZu2sniAkBI9egzawUIADGUjR46gcmXLynG9+/SRvCzp0qWj9Gwo\nefDgvhgY4KFjhLCHDx9RlapVWCw5IddOmiQp/XPpH7q54RZ16dxZDFKbNm1m4/prquv0nBA3VrOh\nDEZHd2DCgtH32fNn9vcg/CxZukQMOjA8wfgG48v//vc/MRo9YcNJvXr17Mcj11efPn3FaAVj+KVL\n/9LgwT9KeU1g40uECOFF/Bo6ZAjFiOFVFj/++AMlSZLEx/1cZ0Pk9es32GAWUow8b+wLLq+/n+H6\nwf3C4Lh23ToRImEMMwZ+CFYjRoyUMHKpuU4vsPACow9yEK1iQ6wxDO1gQeLJE68wQKfYUP/K5MTh\nC1mviZA/tVjUuHr1GuXJk5vis7EcIsnkKVMoCxt4fRPCYPQaMmQoxeRnhjERIs7UqVNFyED4wUyZ\nMorxaD4b3LNxO6ntZORfsXwF/cHtq6W3N8DmzVsklw+MjQjBBIEVhjIYQ//gMjFGwT1stH758hXN\nnDVL6g/tC8anyE47/fHMEOpg/JXn5dcby44vCGXduncXQznKOWWqlJL7CW3+JAtyXbp0luOQYwh1\nAgPbP/9cFNEYgtYebi9t27YTERP3jtBeKdjACe8p5IzDtSDiYcEEg+FGNgrDwPnmTWOpJ7RDtN/r\nbBQ/ePCQGFJxjj0sMKAd3mPDfJMmTRzuIWu2rPbnQ1uBUAEhEKKMCK/8aBC30c+mTJ4khnZD9+49\nWECaLe0yQ4b00ue+/fY7KcPvWXRwBYyP8GRgzVbK7Y19J6/XTwgI6MPYcQ9DOoR3GA2N5x1yPcHA\nintLl+4L2sH1sW3bdqlbiAjOz1aIxTsI3HZj9xuva77xviw+26RpUzGc5mOj+udctujHECIr+zIO\nWIFhE4IwDPhGCMOzYVxEfWCMRP837Q1taAkb6r/66iv7OTAGVqhYSe4jI4vG+B0i2p8sTC5ZvEjK\nAJzmcyFvIIRJI4ShjTVt1kwMtRAP4sSJw8bn42JYthr5d3iLuBl57EToOIiSMJZDPJvIAqE7pDxZ\ngDuP9sqG/8xspE/IIgS8UnayyI6Qqbu4jcF4j+vv/esvEYzhNWraK4BxHSJ3FjZwp+Z7h8F6+PAR\nIoCgf0PYxj3iGl9zO7NuHsAzzp4zR0QeZ3HgCo85t2/f9rqOw3jk9fMUCxHrN2ykVq1b243waFsN\nGzYSsQpz03MWWWbwWIi+OnvWTJdh9SC87uZnfuadJ/GNd1sy14GBvErVanSUz52DxycIEBAtV6xY\nSePGjqUSJYp73S+LKBCQ8dx4VswXGG+2cj+DgJQ+/RdSrpgLkydPJqEYEZ44Aref4sWL2+/H2hdS\ncn3u5jHbuS+4AiJ6167f0kqu04wZM1CixIl5vN8l4v2Afv1EnHX3pezNm9c0jOsMQgHmEIh0ECkx\nZpT1nqf3sbA87ZdfpB0mSpRQRCdstMA4Bk/nyJG9wuBB5P+L28qhw4elrWD+efnyheTMw6tv3z52\n0Qii0qTJk0VEjR07Fs/tSURMHe/dbqNaQus95fZ6gNcj2Nzw3zM/ZFFmFItg50Swh1CMfo61icn/\naf88C3m//PqLnB99LEGChCKeYVzHJpIqLJqgrz158lTGCwxdzh4JKOMxXOfY0IG5IHr0aNLfvMb4\nNiLSAYxTi7gtQPhIkiSxiFvH/j4uc0ye3Hlc1t35Cxe5b4S0j5/Oc9D333eTsQdlnyF9BrrE8wKe\nHeLPgvnzpF6cwdyGTSNGQHU+r8GMISgXtE2IfJi3z5476zCGYMytU7sOPeI+AUEHZYq1xjpeg8zm\nOSNZsqRyHOoeYnDzZl4hTVEX2PyAuQSiHMZBzMdRokaRNY4rMH/j3pG3E4Ilxhb0qwkTJ/LctZlm\nTJ/B5eu1mQCib4eOHeW8OVnAQ7/Zs2e3zHHYHFHaW4DHemkN990wLO6t4HKLzmsSCP/heA2LOjTz\nkc17DMDvr3lNuWDhIvqSx3WzZgUQcH/le/v7xN/UoUN7mbuxPjTjGOr/2+++l/fy8JyNto7+hL7h\nvMZRFMURNSIqihLccPbssf7b1ZilY5iiKIrilpBxStgC8/UxQTKvvh9GjBxpS5gosa1wkaK2S5cu\nyXtsjLG1btNW3k+WPIWNDYP292fNmiXvDxk61H4OFnBsBw4ctLGxxP7e7t27bWnTfWGr36CB/M6G\nC1v27Dlt1apXt7Fh1n4c/s1GC/vvbGyV8//www9yXnNdNg7Kv3Fszly5bZ27dPXxLGxslM+yscb+\nXhc+Llmy5DYWGez3imPMfYEFCxbIe7nz5LWxwcz+/okTJ2wZMma2Va9RU+4BoIzy5M3P5VXEXl5s\nhLKx8UrOMXfuXJt/YSOirUTJkrYiRYv6+NtI7/pJkzad7ffff7ffh4ENbjY21tnfx08WBuQzbKi1\nH1fq629sBQoWtP/OYoccw4Kew/mWLVsm77Oo5PD+1atXbWwQsrkD95AkaTJbseIl7PWJe1m1arUt\nZarUtqrVqtvYSCZlmimTV5mywcj++Zs3b0kbrFS5so0N0jY2WNqKlyhpy5Y9Bz/HcftxbLST+xtq\naX/Va9SQ93Bta/25A8+eI0dOW79+/R3eZ+FW7rVlq9b2Nor7QNnh2cy5WWSS66VImYrbzkL75w8f\nPizv4W8//fSTPK/Xs92UZytRspTUtXkPz9a4cRN7uZp2iHs4cuSI/bymHX71VQF7nzD3MHHSJPtx\npq3kzZ/fdvLkSfv7W7dts6VOk85Wv34De5mz4VyObdzkv+vjZ9269WxfpM/A1z/qtvzwt3RfpLf1\n6dvXx9/Qv3HeXLnz2FgU8PF3Nl7bWLyw/37+/HlbpsxZuO0Xs7/n6tnQr/AeC1MO5+vWvYctSbJk\nNjbs299DuzN90xNYXLeVKVvWVrpMWXu9o71/yeWdIWMmW1IeP1gAtB/fpGkzqSMWneX3vPnyy721\na9/BoY+MGDHClihxEhuLkw7vpU6dRsof4Ho1a9WS/j1//gJ7P8aYgn4A2ChtS58hg1xj8ZKl9nOx\nQVb6CN7H/brDlCfqdcuWrfb3WeSxt9dZs2Y7tK3MWbI6tFfAxmmurwv239moL/0V9YeyQHtv264d\nt7W0Mh5Yad+hgy15ipQ2Fthc3iOeF+Mv+oMzQ4cOs2XkMeOMd//DPFO3Xj2ZX3bs2GE/DuWcNFkK\nW4cOHe3P4opff/1VnnnLli0O748Y4dV/JkyYaH8P7cq0T7QTsHz5cjkuR85cDv0EY2aixEmlPWIO\nMnWJfoD+gjKwEtC+MG/ePLkOxi/Tn1mck3aYLXt22+XLl30+9IUV8to8o7OtQZFYttmDa9penl5i\nf//J3/Ps/358fJ7t4rZxttfnlnm9d365bd2UdvK5/Uv724+b1qeSvNenYQ7b7QMz7O/vmtdD3v+l\nb2X7e3sW9JL3RnUubnt2coG89+rsUtvC4Q3l/R51MtseHPlN3v9n+zhbq7JJbEtHNbF/fuX4FraG\nRWPbZg6sbr/vF6cX24a1LyKf79c4l/1YvC7yOR4e/d3++/3Dc2zdameyDWiSWz6H927+9autS7W0\ntuEdizp8Fq8lfG1cb83kNvZyuLZnqq1ZqQT8mXRy73ivW+2MtkHN89p/N/d179BsH+eUlzfteaz4\n8suvbCwAO1TTmrVrpU+2dxpLTJvF+74xbNgwWbOxEOnwPtY/ZgxhQVr6G0D7qd+goY8xBPM15jwW\nReV3tOXFS5b4uIdOnTvLWGH6O9ZpJUt9LcexqGy7eu2azS/M/F27Tl17e8bP/v0HyPsDBw1yOP7g\nwYP29SDAtTGfN23W3D7nom+nSJnaa606ZKiPdRP6Iv5m+jTAegll14DLwwrm4nRfZLDVq1fffn4r\ndXjORBlY5xyMPy77YTDhfX7nUBQD+iX6Su/evW19XawnFeVTplChQvK9VFGU4AXmq549e8r3YHxX\nx/dSrNmxtnZebyqK8uER2LrV56QEaxBWCd5iADtbECINlClTRjxezPu8MKOQIUNJyCEDvBayZMns\nEFoHHkrYuX3nzl3ZrYwEo2HDhaULFy6Kh5EBO+mtIfzgoQIvqg4dOti9IXBd51A1QQF20ls9CeDl\nky1rFtkxj53cAGEk//33kngtmfKC5wPC5GE3M8IkwbMrsClfvhxVq1bNx66jWLFiye5uq4t+kSJF\n5N//Xr5M/iVq1GgUgssd3iLwvjPAO8LZk8MKdrDjub/77lt7feJeihcvJl4QyF0iIZJSpJCQjvgd\nobkM+w/sp3Nnz0r4MHje7NixnU6fPkO1a9eyex6CZk29wggiFJEVtKOePbq79ATxFHh5YEd+504d\n7eGM4N3XoH49eTbna8JToEKF8vbfcW14xSCEFsJamt35KI+8eXKLRwp2k/sFwjwhtJTBtMPHTx7L\nTni/qFO7tnhnGL7Mn5/bSQzxPnzu7Q2DUIKgb58+9nrFT5Q3PFKwm/1t+J7bAerZGXgzGe8ogHYF\nr4eHDx+IR45/iRkzhuzkh2eU8XJEuzN90xMwNmXJnIX+vXRJvPIA2idCm1avXl3+vm2bV90jBB68\nZ1E/1nELdO/ezaGPFCpUWHYOWsdKZ1iwpL17/5LQqhUrVrD3Y7Rx5zBoGGOLFfsvVxa8GBDCECDM\nqV/Aw/PLL/M7nA/tNR2P1WXLlrGPt4kTJxbvMOf2mojLNGnSJA7llidPHmlT8MBAe6/OYxQ80ODt\naICX6d7/7aU0aVK7DVnrH+DtCI9LzFEIBWhAOL7UqVNJ3WHM9i/TZ0yXOQuhSg3wgIWHJ7zAMB5Z\nQVg+eFIaUBYxYkSnfHnzibegqUt4x8bmcdq5HQSkL8Dj5rff54pHX6NGDSWsHoD3IDydbty4KV4+\n7oA3I9pWhfLlKaTFQ8ea7wjtDm3A7o3Iz4HxBGPi7Vu3fZwT9WDNf5krZy757K1bN+V3jJ3wrsb6\nAGUWJozXOgH3kTdvHpk3/QIedrg+PA3NfaOvVa5UyeXxCPWIMMEGrB/gsfXk6VMJsegb8ACC1zva\nwldffmUvB3hiwWMe3mTw2gXwJkXbN+OGua8oFg83/4CQkJiDevXq6TCW1K9fX0I7Llq8WPpXQEGf\nL1eunN1bE+3HrPXMGALvOXgYVuKyzeYdJhJtGWFqv/jiC9q1e5ef8xjKe9DAARTXhfeaOxCa2rRn\n/GzWvJmUOTwy7R7sDEIuWteDmHfRXm/fviV1ZwVl1pzP48lubZwnb568tG//PikDw8aNG6VPVqhQ\nwWXIUng4Ys7EOI66A2gz8LZUFMV3bC48VxVFURQluGPWljqPKYriGxoaMZiTKlVqh9+NISd5sqQO\n78M4A3EAoXIMGPxPnjolYY8Qmg95UR6zwRjGw6Ten4dhAwJD/wEDqULFimLQLVO6DBUsWMBuCLt3\n774YMJEzzLecN0EBDBypUqV0eA/GIuSlevXqsj38EkIIAeSWMcZxgJBLMA7BEAnDsLtcHgHBGKGc\nc6EAhAZDiK6j/Pr30r9ikLlw8YL8zWo88hTk4KrBoiiErT2791CtWjVEyEJ4I+c8aVYgGoCcltxx\nAO0lR47sEpoNhjacv1q1qpLvbM3aNWJIRtkuW7aMokWPLnUPEG4SOagQUgz5qJxBWEIrMChb88n4\nF7RhGLpR1gjphBB3hiveebAQotMKQidaDWMoH4gTESyhKw3oT8+ePfdIJE2X1jH8pGmHb16/sQtZ\nvpHWKXwl2k1kXP/pM/v1z3kb+n76+WeHY9F+wSUWewMK2j7COjqDMoYoAqM4wqohzBX6DXJqIT+e\nMSL6Bxj//9zxJw0aNFiMxJUqVBTxFUZNT0NVeInHhSX0F0LuQaxFziOEXytbpjTf715at36D5Os6\ndOiQ9DG0c2sfR1gsa+4cECFiBPn5zDJWOoMwtBg3cufK5WdeKORdDO+Ub8a0s6e+XMOAkGPWPoy2\nihdEFOc8Nq7aK8YaCKQQWq5cvUIPHzyU3JOo11fex0HoQkhA5CGDIAsxAuHYLrEIVI8FZas4EVAu\neI81R48eo7bt2tnfR6jD69ymQvKYc+/+fYfcQn6B0H63b9/htvA5te/QweFvqHPU4VV+ZuT/MqR2\nmi/CclniFT9eXHvoNYD2hf7nPGda+wLyNCKsnl99ATkbEVIYmxSQ99HaZsw4efGfiy4/i2tiToaB\nHiKmO7Dp4xqLoMh3BNHn0eNHkl8N47Sr8StBfMdcjxhv0DeeP/cSJfA5zO1oY4mcBOqoUaJKW3vj\ny7gI4ecpi1cQt51zTEEQdNXPEWoTaxLkXsO1nz17KuIGNvHY3vj+ZRVljHtGGc+YNdMrfKI3Riy6\nyeNk/HjxqVzZcjR56hQaOGiQtA2EQ8TYI6Ee/RkqB3WO0KkQp7EZyAqeEWMERF6MGQhrGBBcjSFG\nVDLtE+EnAa5l7V9YT2DMxlPdYPEPuSvdAcHMP5sRQGpLzkQQJXIU2QSDMLFohxCKMf9hgw82I6B9\nIgQlRGPUbdJkyXwYIjBOe7qJCmvO6jWq0/a2O2jpsuWyXsWYh/Co2GwEodsVyA176NBhyTeGsJGY\nJxBOEiKehktSFEVRFEX5+MCa0zfbmKIoClCPsGBOlCiud2WH9SPRNyaBWbNmU6VKlWns2LGSXwhG\noMRJEvswAlRkAWzRwgXUpHFjFs0OSf6nqtWq0/79++Xv9+7dlZ+RA+j9FRDhxwDBJnIkv3em37rl\nlcsGRhMYTc0Lxhbkp0C+GleC1dsAw6jVc8Bw6dIlata8BTVq0kQSuSPvGXZGx7TkVvEvMFQPHDCA\nZs2YSZkzZ6LxEydSeRYXkDsKAoA77np7KrkysKJcYeQzOcqQyykliw0rV64UoysMb/v37aeiRYva\n85/c9W4LYcOGcyhnvLCj/euvSzlcI1y4sG8lPqLtwBiOdgDjsvV6MEyi7ab/Ir3DZ6K62fUPQ7zZ\n2R4QYsSISQEFbcU3I7fhJhsWvWKgO5Ytyh/PmiljwD13IEBYhQADDIpff/0N9erdR3L7hA0TVozG\nESP6fb/uQHufMWM6Dfn5JzbwhqchQ4dS+fIVaOKkSf4S1mC49fL82k6XWSxAniR4wkIAhkcQBCCI\nFdj1j5xJRYsWcRjfYjoZrj3FtHNPjLUop7dZcEeJGs3l+6grv8YsjOvIgdaydRvJwwVBJGnSpJJ7\nxwqeo0rlSpJLDgIijOsrV66S/DzI9xYY3LvrNdbgnq1tF2VTgK9RrFgxCu2L96or7np7kDn3fbyy\nZMlK5cqXl3HASmQ3/R9zpl8GcOe+gLbnSV94wUIABDOMd/9n70zgbaq+OL7NUxQZSmROQuYhQlQI\n/TPPFTKWMiWUMUWZJZIhs8g8FyFDxsiQDIWkUJQ5Mt3//q739u3c8+59776Jh/3rc/Pefefss4e1\n195n/fZaK5EmdZz1zJ49h8xddz0Nrl2/FuEhDQggjPmDBw+RvIR4QOIlDOHq77QjY+A8NOAPyMq/\nV/4VT2O3XkwUhK7Ey4cyyC+ZIL4vWUyuLbeuIcdb7z599L5kihBL5I564IEHgyZEID1ZD6hbiIzF\n837Ip4gXmzkohH7o1KGjkO8cBiHn2cCBA9V3Wn9E9nQobSS/YqBDQMlThIzbpUtR9wgLRodAOgH3\n/EqUKLEqp+dX1WrV5LBHeGBtTBTJOeiWA8YtSeKkMhboXP4lP2sNrYfIV/jDnh9UMl2PHDlzqAQB\nDhFA8kcGpUs9IflzFy9aJM8jVx05IiuUL6/LesDvPXidfTFzhurVs6fMlzc7d1bPVamqZs2abU8I\nW1hYWFhYWFjcofCE5oxz55WzsLCwMLAeYXcoOJGL4SefNgZ82L+fhHEDf/zxp1q1anWY6zH2devW\nVbVu3UrNmzdP9ev/gWrVuo3atHGDSp8+vSwix08cj+Cp8bTRKCzp9efJUyqqYOkKZv16+OGQU9BN\nm7ysypYtq24lpk6dpjZt2qRJqs5CLhqvjjFjx6oVK1aoqAJjcNmyZSRcG4agIUOGqi9mzVJp06VV\n3bp29XsPfwOcGHefBP/92O9SZvpQjxlI10qVKqlPx4wRL8LDh3/RY35CldXPMx4OxoBVq2YNCQkZ\n28BoRxgnyMQ+vXtLuKNbhejso4LdiJlQUgM+/CDq3peRsPGxUezevbu6of+dPm2akKwAooQwXNEJ\n9wV5SwhDQnlt2rxZvMP69euvicvHgp6jEM1Zs2ZTP+zerb7XRmzC7zVr2kSMs+WfKqeGDx+uvv32\nW5lv6IAwITijOGgmdBheHhEhugR7dORq0ODBQoYNGjRQ1ald21uXnprIwTvDCcLnQk4sWLhQpdN6\n4cc9e1TJJ54QT7uYQMZQDySI8zc7dVQxAfHe0G3KqomOj4YPC+qeqHZndOYC3tMptbwz9fr1ez9S\nHnYQZ5BBf2si0eMn2TfAw2/zli3qGd23kGqGNINQ2rx5U5jrQ8oIvyfQ6dQZL3EOPqR0HDiBmLt6\n9Uq490MS4smF9+i1G9f0ZvK/7STEnTtMH3JH+wi1lz1byDyFFCd84e9BhAu+V0ichCK7rzRp5hNC\n0h9Y7+rWqasqVqwkfbR02TI1/fPpKovWsYQuDhZyGEePL+Fv/Y2P8da9P4qkOwhGh5g9DjJAH94s\n4MWX3uFVy9iyRtEvHK5AJ3/66RjRmeghE2aVecMBhpgAz6lcubJ+zqcyF1YsXyH7qmcrPhvhfc2b\nvyIhshdpEu3DAQNVl65dxEswl8vTzcLCIgSB1iELCwsLi9sfRIniHZH3Qn8Hum93uEMjBrOm+fv7\nxIkTJQS6hYXFnQnrEXaHAsKLMFSlnyjpJcHATz8d0H/zNe46T8dywrxZs2aS4wbyBOMPRje8DPAO\ncubccAKjGkTKr78e9SmPMExbtBE8toGXCM+dP39BjJ72xdDHyffIeLWRYwvD1vPVqnlJMAx+5PeK\nCPHjJxDD78V/fHPRONvEYk2OELxtML4ROtCEiHSDvDCAkEJOYNT9+uuVYrB1kgfkJGIs582fr5Zr\n0o7cQ878QbkfyS25ZBYtXhxUXq2YAAZpcuCsXr1K3enIm/cxLWvX1cKFi1RkwUl9ZIOQacHi9Okz\nkqOM3FrG8A+Y+xjZI3xmqHfBPxcDyysG0zJPPqneebub/A7JCkwOK2fOOzcgbsj/gzfYrNmzxdPJ\n5DjDkImhkxP+Bw4cEA+AmNrQZ9bGcgz9y1csDyq84a0Ccx9PEnIyGWM6c3vHzl1hriWEWfHixbUe\n2qzn7xLxtiIPUXihH5Gn+H70kT9kypxJyJRVK1cGlTMvGCTTZDCh2Xbs3BmUPEYH0ZkL6FFyV/Fy\nGZU8fhDghPULRAgROpGxKKRl35BgHs8NdfiXw3p9uqqiAubl/WnuF082Z15IwLw8c/pMhPdDKFG3\nP/V+w4kDP4XNh0b4Qvooe9b/9iMQcO5wryFyHE+87JxIlSql3mPcp4nfw+r4iWMqLBzrvkP/4AVV\n8dmKqmyZspr0u6j+Ckc20WfkKrvhCtNIzjsOF7nJZer/tV4nIcrcuQl9ytX7CPYQ/14Jn1wMD+g7\nDgBA6N1MnUQYZCd+PnhQQj4/qPUJY0K+Wbxy0b/OvQIEvXuvGRHoJ+BuH7LPfoq/k4uPOfboo7nD\neIM74VyDOFRSp04d1b59O1lfWS8sLCz8w5nb2MLCwsLizkKfPn3kUN2kSZNUTIP3ID63Es79H4e1\n+ERkG2zSpIn3A0FoYWFx58MSYXco7rvvXnWPNuSuXLVaQgNhxMFrYvhHIyTUnAF5HAYPGSJhoDB+\nYdQg5Az5VzDumJPtr77aRl3WhqmuXbvJiVzKwwhLTi4M2hA+mR7KpHbt2iVhcjhFjFFv2rRpug4r\nVWyD8F5FihSWU+fv9+svizBGGOo4adJktX3795EtUoxO6dOllz75+uuvpU3BeMhkfjiTEF+QRYRs\nxKtqxMcfSxkRgdBaD2R4QEK9YTgkHBIGNMZu/Pjx0i7qQ/+TLJ7QRHhpBTpRXqNGdW0Az6DGjBmj\nlixdKvexIejbt6/kz/jf88/7EGEY2woWKCBEDIRF8WLFJOyUQaHChVSFCk+pdWvXqR49e0qoNcqk\nXhASy778UsU0OI1DWML+H3yoic75YnTDOE2ulKFDh3pDRt0JaNWypXhp9OvfX7z9fv/9mMgxeZdG\nj/7UmwvHHyCx8SxZv/5btXfvXpHXiHKXQV6T34fr6U/uwdDMPA8v5KaBCfc2b9588Z5CFthsQlot\nXLRIjOTkc2G8Vq0O8USFVAcLNDlb+bnn1McjR4b7DDwgMTjjXZArZ06vBxNEFXN+u5ZT6v1k6VKR\nDvsVCNl0HatWrSJ5cN555x3pE9qAIXzN2rVxJrQWuZ0I3UZf0wfoGvIi7dy5I8y1EF716taV+UOY\nvUceeUQVCSUVAwG9kiXLw7rdO0W3Q3A51w8nMmlZIHfhXr0+vP1OdwmFZ3QD4VbRh1FBB2285jBC\nm1dfE88s5Ay5whNw+PCPgsrvFwz8zQXmXTBzgX5q2/Y1+beLvv7Lr76SeUs9t27dqkaOHCVrbSBU\nqlRR7p02fbo6dPiQ5OTkfrzAILbvT3u/yNxW/Tv9z5zatHlLtDyMeV6ZsmWkXMbmp59/kjxneH4v\n+3KZOhcOQW1AKFLWp6l6nSckMPdDgEybNj2METW9Js1Osm/Qa8b58+ckt9sULYenTp70uQ6ij89v\nv/0uew2IcvQYh0QgQ5CFMWPHqT0/7hGyjnHau2+vXvv/OzywULfn558PSj+iO5D5/bosiPU0qVMH\nbE+WhzNLLtXly5eLrNPPoH69uuo+fV+nTm/KXoI15xe9jr75Zmd1Sj//tddeDZdQhiSmn+fMmSv3\nRmXNwjuyUaOGsuZ26dJVyBzmF2sC84t9V2wAz/Nt27ZJncl7+o6e24xBkyYvyxhDALLX3KLlnPHi\nOohrwniyfkUGhGoFzB/G1awnAI+4Mk+W1n04RxPARyTkdXghS8eP/0z2SOhtxhH5hNSLnyC+z57G\nwsLCF+YEvYWFhYXFnQfsKhA+L7zwgoppQCI5D+DfCjjfP5o3by52g4gOdkyYMMH7sV5gFhZ3B2xo\nxNsMRo37U+hyej/0e4wm9RvUF2PAc1WqiIEcQ1wxTWwUKlTI+5KDJ9GiRUvUR5ogw7uC6zDAcYK2\ne/d3vB5NeBzs27tPjC2Vnwsp77w2DuI5QR4Ofn/xpcZiuMNwOHDgICGDMEw/+8yzav6CBYEbowKc\nQAxv0XLFTMRwNmTwYPVm57fU2HFj1WeffSbfnTt3Xowl777bRxXWJE5kQB9Ur/6CNvBsUW1ff0P6\nFM+WDz7oL88OtKg2bNBAGyi/VgMGDFSTJ0/xek693ratJiI/8glYFc/VZsiM//3veXHHrlKlqpCR\nHTt2kJPwfd97X0g+TuHTtxh3Hn30UfXSSy8GzC+Cx9iIESPUm9qA17bt61I+Rt0bnhvaqFhVynYC\n8q9WrZBQdhj2qmjZcdYvoX5O71691PVr18WoN1sTHqlS3SsGR3KVvPFGW/Vc5cqhbYtcXGbvta5b\nIOoGDfxQ8su80b6DSh6a6wcDJ8brWrVr+9wfqVOsjGNEdfCW56fceMrvs+O5nxGwTvF8xJxwXh99\nNFz16t1HdX7rLZVY9ynGW4zfGTNmVE+Vf0oFAnJBnrbRo0erGjVrqfv1fG7VqqWWj5fCPMcAuUEu\nhw4brmrWqi1GTQzA5GNh7J3eLf7a9nj+/Kq0JqAghyC1mO8zPv9cjLRjtbEaj560ul7oHj7PaMN5\nxUqV5F7IdsKKFSxYUIUHQinSNgys3O/MPUSYMPI6IbfoNp+ejee/zfH+u8B5sXL3S9cuXYTInqtJ\nPj4Qb7ShmjbAli5VSoWHYGTRr6z4/D3A946fW7RorrbqMWrXrr3IDnObPEGEZIWccBfxpDYk430E\nOVWmTBnxEosIjRs3FmK+Tp26Kl36dKqUbvuADz/8T/ZDr2PsIXLRS8uWfSk5y/AYIb8S44O3KURG\nZIEcEgqO8Gv1GzSUtQadijEeD0pIiMA9FNG3yrtm+psLkCKP5Xk0qLnAutq/fz/9+UC1bNlKDpFA\n0lFX+rx27VoB8wTmy5tP1axRXS3V/UYIUdZd7oOY66bX00dyPSLjS34w8uRRV8IQF3i8gPrxxl4V\nLNyhhrNlzaaq6xfhJcuWSX4n1sp//rkknsDoXV8i3avsvN8ULFBQ5uDqb75Rfd59V9qMN0++fHlF\nHpzyX7FiRTV9xudq0JDBQvYjF6nTpJYwqfv37fdex7oLQff59M/lkA6Heso8WUZ0G96ghFpdpusL\n0ZI8eTJ15d8r6rpeD5HlF/Q1AMJ6gd5zUJ+kWl/g/ch6VlWPY3hhEatp+Rw7brx6p3t3WTczZc6s\nxuv9BOvsh/37C8n5QvXq8iz0JB5KjRo2VE21QSE8lNVzjTJYL1evXi1hHkd+PELW44Bj5UeHdOrY\nUZ07e04OnEB+sz9gznNN40aNlKqnwtzjW6iKFBin/I/nVw0aNgoJ3/n3aS178WXPUS10LkNQ1a9f\nX0I/k7MvtV53Lpy7oHI/mluVLFlcXXV6LEawNteuVUv2TIR2Hf3JaHWPfubCBfNF5yMX7E3wiGM+\nkfc1PGzb9p16t29fmXPsgwz52Fi3hQgCFhYW/oH+sESYhUVw+Ebvf4wHDAf9eKe5E8PNGdxt7b0T\nAVl1N3g92XXMwsIiPMRLmKFijGqJqye+UncKbuXLAKGYOFXLQpXOEXIHry2MYWw88I4wwEBLqLuH\nMj2kihYpIt9hKMRAtW/vXglnlz17NlWiRAkhug4eOqQqacMUbeRZ3323TR07fkzaixdUuXJlZYPj\nxhZNdBEWB4MIIYfwyKAuxvDC5mitNor/oQ3chM7BIIbnAYbyfNr4QGgkgIfBwYMHtXHsWTGwALxI\nMj6YUQzrgJPOeHtgRIKkM6COGzZsVGfOnlFPV6jgk0sJ4yFkHCeTyV2CEe0xbUjHy8mQepEBhkwM\noN9t2yZhHimnQoXy6vDhw2KQxCic0U/idzwByMUWkpvrId1PReWEzLz588SAYzxpCD+YIH58yavj\nbMOqVavEsyJJ4iTyvJx6rBmjXbt3qbNnzoqBFGMQxmyMahGB09UrV65Svx79VfoyjzbKQRz4O8Uu\n4Z5WrhSPgfJa/sz4OIFsYRznJD71gZDCm4wyTegu5ACi1dm28EC7kVfykfjzVEH28Qghd5lH/4dx\nq1jRoip37twifxgEv1q+XNpGeDMDPBbwkrp0+ZKq+OyzPqQh3gl4rjz7zDNiNKVdtD3lPSlFDukD\n5BCZco4b8CeH/uoQnqwwLzAclw/N32QQ4sG5WcYLQ2/6DOklzGXOnDnCzSdDf6Mf9vywR4yOFTRx\nRriqbzds0ON0RpUvX97vPNig/86cvHL1isgpHpZGT9A3yEmg/uX75ctX6Ll/WKXShG0dbfAH1B/v\nBcLqpb4vtXpUEwpPli7t7f9qzz8v5X+3dauQN4HAHFy/fr36U4//EyVL+uS6g3RZu26dELTly1cQ\nw7gBxuIE8ROIjnEC0nbF119LG2gL2K1lAH3k1jUhcr5V/fjjXpkX5NwrWaKkjAO/I6/oOTcJR1lG\nd2UIzTfmRkTySp8jg06j9nbypGl5NPIK6OM1a9ep09owj1GaMG7JkiXX/bI2THuQj2bNXlE7d+1S\n47SBv7ir3v6AnPPiu2v3D1K3J0qWEFnGO+SQlu0Kut9TpEju8ww8jPEsPnXyT5VC1xMPDNal8MLH\nsXZA6kEyQvq6AbmKl+pvvx/TcyWxeMMV03MiY8aQOYW8IguFCxVWOXL85+UKmYMnyP362W69gpfh\nNU0oVdDzwsA5F/LkyaPHu0TQcwHgfYSeYpxCcjBm0M8tJMRSmLl7xNdL7uDBn/WcPyrEN/oga5as\nsn4yZ/AM26kJHsi5lJpgpI9YF1i/CUmZOXReoG+oA8Sce66zfifV30FgG3CoghCL9D+hAx/U5T6q\ndSptZE8A2QaRST/iRUyOLudpTw5VIIO/aL1M6D9k8DHdb3hRco8Jl8c83n9gv1x3Tf/MvEF3Iy94\nkT2uCRf2KaZOjDdeaoQpzK/72Om5TPsOHj6k/tLkRoIECYX0pywj639qufvxxx9lnwJSp75P75dy\nideiXzImy38ELfet0/OPgz7ZtRxBnhndzLxep2WMvKcZtE5GPoKZQwAiBpnBSyqtXruqVasqxiO8\nn/zpECPPbh3CfNy4cZPsccgrx1qFHBQtWsS7F3DrM6ND8aoz61pEqN+ggczjH/f8IHtLxiixnnfI\nTlG97jrXUeO1vv37HbKfgUhlr4l+Zh6U02QnxCh9QP9BCtJ3/oAc0k/MgZw5cqjqmng09eVv5Ss8\no/uuiho2dGjAA0Cm/1iDDut7kEM8EiH10AFxNeSbJSAs4gKQQXQw4bOYY7169VIWFrcD2N/HNinD\nexRzAhtJ06ZNZX/sxLBhw1S7du3UnQb6lnB67vb27t37rtER9AG5qTlsxc/Yvxhrf/YywJ7FXA8C\nXc87Cgeg+Rvy67wHz61AHkru+lAu1/ojuZBVNwJdG175eJGxL3OCupsw2kTu4domrgNieFr5K5/w\njMiUKd/MLSd4PvWgvvQhPxs5dPYPaxb7UWyN2KDYU7HnJBIS1zj3fv7q42wP/eUvRxhjynNMXf3B\n9BnjGdFhXwsLi+CR6IFKKiZhibBwYF9KLSwsLGIehDsrULCQevmll/RGsqeyuDkg5F9TTYThEfHJ\nqJFe0triFuFI1MJFWsQwskTeU/FOB0QYhwAOapIzroAQo8M+Gq7GjB4txsg7DfadwyIuwIRGxNgH\nCW2JMIvbAaQu+Cb0MCUHYGNrf2uIMAz4hrxo3769/A0jOQZytyEfI78h6W5X7ylDDNBeyAfaQXv5\n924w9kNsMPaGAKPdhozxR34iH8iF+3pkY968eT59ZogXrudnruU6Uz7fkwoi2Pr4Iyf9HQDyR/SE\nV74hxNzlU78FoZGfnN6CTnBIzwk52KTL5193/d314nuudfePqQ/yCLFliDAOYS0ODccPCRZMfdz9\nEogIA9SFOhHhwU0k0h4OC/K88J5hYWERecQ0EWZzhFlYWFhY3FScPn1Gcrw0iSCkmEX0gUELrxs8\n2MjHxksDYdQsCWZhYRHXge7CsIFnPuEXixUpqkqULKksLCxiDzZPmMXtBva0zz77rPyLkdoYwGMD\n7KMxkmPshgQx5BdGcX/eQXjJYBzHU+R2BW0w7YW4MO29Wzxe8IYDkB9Ep+BfiA76AWIImTCADIG0\ngbDhGnM9/xrPOuf1BsgUJBn3OMunz93XQ9TwnbN8fmY8qI/bc8/odD78PSKY8inbWX9/5VM/ns3H\n5GA1v5uPG4YE89efhkB0g+dACJr+4T6up9+MBx0YMGCA5HsmcgLh1wFRDcKrT2RgSM8FftK+mH6x\nB0gsLOI+LBFmYWFhYXFTQfi0ER8N1xvmh5VF7IIXhbr16qtq1Z6X3IV169aRkKoWFhYWcRmEpiX3\nHDn7Xn65iYRPJq9p8iiEubawsAgOlgCzuF1BCF68wSBoCN/NAQo8xWIaxkh/t5BAEBYmdN3dCIgW\n+oDDm04PIBMej75xkiIQnnznDvOHvEDyUBYeY27wN3f5Jgyhm9jy533IzxBFEFXR9Tw05TtlnN/x\nvIpu+fRVRP3pr3+43nmA1pBmgLzj4GYc4mBMaD9y4Sbs8Erjb3dDDjYLi9sdCZWFhYWFhYXFHQvy\nSaVPn061at1KPV+tmkqaNImysLCwCIT8+fJLjtJbCXKbkVeQD3niateuZfMtWFjEMuJqDj0Li2CB\nV1iVKlUk5+eKFSuEHCOPdSBg0MY4b8IXYuh2h0Tjbx06dPDmfQJ4oThzL5kcUM7rgQkXh1eV+Rn4\ny7cEID0gAkzoQX/1AZAAqVOnFvLA2YZAuZYiC9M2Y+wPr70G7rxP4dXfX3tBeHmxzPW0NZg8WjEB\nQ7IwXm4YMsdJDJl6+Rtb6gmR5PRgCg+mXPKmOkFd6DPGw+TOMgRMTJAwtAsPLHf5/BvdfZgh9SjH\nTfAZ+Osff/JscuMasH6ZMNPOtSym1zXmHuOILjDeX7TFEHx3K2lsYXE7wRJhFhYWFhYWdygKFy4s\nHwsLC4tg8c47b6tbjWTJkqn2LiObhYVF7MN6hVncCYAAwyC9YcMG9dNPPwlB4AwLbsLUYcA2Rn4M\n8BBW/OvMy8S1xtBtjNzmOwNyEzmJMPM3QyQZzyqDAgUKhKkzHiXG48ZZH0gJwsE5CRe+x8DvDNVo\nnsvfTOi4qMIfSRGovaZ99Cd1duaVoi60ifq4PYnc7TU5n/iO9rrr777eEA+Byo8JmDEL1JeB8k+F\nVxcnIRoVMN6QoPzLByDfMUUKIvuQTBA9pnzj0QYJF51+Nv1pvLliGqxf5Ld0fxeTZBhyz5zkY4gw\n48VmwyJaWNwesKERLSwsLCwsLCwsLCwsLCzuYsS0wdDC4lYC4uuZZ54RjzBIHLzEDCBV+A7DNaSO\nyVMEkYCB25nTC7KDv0E2GEM3Hj/OvEMQPu7r+RhCDcO/83o3EQDhAKFjyjX14XkQSv5yjEGoUHeT\nK8pcD9lA+6IDU0/qASBCArXX9KchEJ15n0w4QHf9TXtNuSbvE/dzvdP7LND1pr3+yr/TQT8ZuaVf\nDClIPjp/ObYiC8p0lm9IykKFCsVI+YRZpGx/n+iQScYjDLj/jSlABJpcZoYgRz6tN5iFxe0D6xFm\nYWFhYWFhYXGzkaWasrCwsLCwiCvAiHjjxg1LhlncUYAIe+ihh4QIW7p0qZApkF0YrTHyO8H3hN7j\n+3Y30SvZ5BeC4HB63JgQbE7vE3d93dcbku9mAgKxXLlyYUICGu8ZtxeU8aCZN2+eT/0hGJyhDyO6\nnvauWbMmYP9EFyYUIM9wkxy0iX6GIDV/K1++vJAi5nsnTJjF6IQXhHyhb0yOMBMOkbYTjpN+oK+i\nKruxXb7pJ8I9xlYuLbN+xeY6RvvNXDNeeLEZotPCwiJmYT3CLCwsLCwsLCwsLCwsLCzucjhP1FtY\n3CnAO6xo0aISMhFDP94bjRo1CnOdyWsFIRDdEHbBwjwLksCQK86PCRvorz7+wtRlyZJF3WyY0HwA\nbzETts/tOWZg2uXPgwayC+8wA+N5Y8IhuvvHXBMb4wW5B0yIQCcgKPFccz7XkCGGuHPCkK7RIVh5\nFmSb22MOxIQ3Unjlm3CegTzC8EYL7+/A9I8/cpT76NPoepyZ9cvkEDMEZEyCeYe8I3+QYYY0tLCw\nuD1gPcIsLCwsLCwsLCwsLCwsLO5y4BFmYXGnAoM1nmEpUqRQpUqVUkeOHAlIHDlzgsUmjPcT/0JC\n3K4wHkMgvH4zREegXFN87/ybuT6i/omN8YJ8wxsKsoNnGxILrzXIMUhTJwHCz5A9hjjjZ0PwUH/K\nik4dqQ/PgICBrCJnF4DsMd6B5jsDJ6llZM14rZkyTbuCKT+Q55O5j/CJxjuP+yjbtJl/nf2JByAE\nG9dRJ+rHfHR7FgYDc4iDHGH8TLmLFi1SNWvWlDpQd3d93P1jyDln/xhPTTfMOHMPoR4tLCxuH1gi\nzMLCwsLCwsLCwsLCwsLiLgcGRBsa0eJOxp9//qlGjhypMmbMKL+fPHlSPMXwGrsVMKSPMweZP8Tl\n/EOGBDMh40ybIAmMp5AbkfX8gaTxR0g4/x4bMJ5ceHnVqFFDfqZ9jJU71xuAHEmdOrX0hyHEDJni\n7/rIAo85iCTjdWeA/PAMt5z482Zzhs7kPqeXGnm6GM9gyzcw+elotyGXDDHnvIf+5Hfa4OwPyufZ\nUfWscua45OeePXuqc+fOqY8++kjaE6g+EfUP1/qTO+ppvDWNN6SFhcXtgXgJM1SM0dgHV098pe4U\n2NAQFhYWFhYWFhYWFhaxCfvOYREXYLzBMFQmSJAgVnLuWFjcahhyBkP28uXL1U8//STf5c2bV7xR\n8GjBM+X06dM+nkl4sOAFgpEfw3cwXiAY2bmeORVoPmFIhzjB4H748GEVDLgWbzZ/6wZ/Y00Jtqzw\n4OwrSIpAoP6APvN3v7u/qCN5otzXA8IpusmFQOXfbCAXxmMtkEebv+tji8Q0Hl6UH0x9bkb5Jkxl\nMO3mOq6Pbh9Bql27dk117drV6xHGGsbPkGHMlZgeB8gydEJMEZwWFhaBkeiBSiomYXOEWVhYWFhY\nWFhYWFhYWFjc5XCeqrewuBNh8vlgyP7999/FG4zf9+zZo2bPni3fQcLEBLFgCJzwvJ94Ds+HFCCE\nnht4Ijk9VOIy3O30lysLQA6akIHu+/HegdhwAqKBv7m/B5A1gXKRxTRMXrNgZSNQHrSYrA+f2CDB\nolo+1wbbbq6JyT5yr12sZ+QKi41xMF5vUQnjaGFhcWthQyPeRvj1119lg1S4cGF1zz33qJjE1atX\n1Y9796rfjh7Vi1dqlS9fXm+CSQuLOwUHDx1Sx48dlzmUPHkyFVfBidz1679V6dKnU3kefVRZRB9b\ntmyVk2FFihRWFnEXvLCsW7feyv4dBk5p7tu3X+9jjqhUqe5VOXPmUA888ICKyzh9+ow2iv0gJ0kf\neughlT9/fjlZGpfAWvGDNtz9e/myrGvoOAsLC4uowngmWu9EizsdeHHgzcEHby08wbZu3Sr5wwYO\nHCjeYTGBcuXKCTFgcmeRtwhPKHeuJbylTM4kiB2Tm8nkooIoi2rIuJsB6k0/4k1nvGMgp4xHkcm9\nZEAoPtrFtfyN9hoi0F/OJXM9zzDXgzVr1kjfQnRYQsLCCZMvLCaB7EFKMy/5Obo53ywsLG4NrEfY\nbYR5ejPR7JUW6rBrIxFdXLp0Sb35ZmdVt2499eprbfUzmqtNmzer2x0sTuPGjZPTXRb+QciEVq1a\nycb/bsCSJUtV8+bNtUF2r4rL+Pfff9Ureh5+8slodacCAy4vPxMmTFQ3A126dVU9evZUMYl169er\n1m3aqGPHjqmbiZvddzcTV65cCSP7nMx9Rc/bDRs3KovbE6NGfaIaNGyoXmv7umrStKn6LI7L7g8/\n/KBq1qqp69pM6oz8Xb9+XcU1cIhp+PCPVIeOndQ///yjLCwsLKIDS4BZ3C2AODGh/vD+MoQY+cOK\nFSsm3kdLly6N9toK4QWpg7Hc5E5iD+/2YOLv1Ie6QPiQi4oP12FsDy8soRu3Is8fRJUhtfjXkGHU\nmz4whJgB35n20i/0v/GwMd8Hut7ZP/wc2f6xuHsQ03MBEgw5ZV6afHgWFha3H6xH2G2Ea1evaQP5\nZW/89sjg4sWLau7cueqZZ55RDz74oM/flixZouYvWKDq168nm4vz58+rx/LkUbc7Ro4apWbMmKn+\n97/n1bChQ1WiRImUhS9+++03tXTZl3LSnU1/XMc336zR//dEPYnqjevqsp5DeCdEB8zBxYuXqEyZ\nHpJT+DENDBHU8+rVK+pOxeXLl7XeWah+0yRH06ZNVGzj38v/qvjxonb248BPP6n9+/apatWq+Wym\nN27YKORqC20kNwm3bwZudt/dTPiT/UOHDqnly1eoRx99VJV64gllcesRYnCIpw0XT0V47S9Hjkii\n6goVKqiOHTvIfiRt2rQqrgIZfO+999WJE3+ogQMHSMikC3pfFFf3EFevXBWPsKjsDS0sLCycsLnq\nLO4mQIZxKNTkNHKGvGPtJ3cYhm++53fAz5GdI3gq8YkovxRlQ5rhrRZRjqVfAhyMpm7sm83P/urq\nfJeJiCQItr3UlXpDStFO7jN1D5TXy9le9z0RXW/6J9hcXRZ3J2I61K/JlReRrFpYWMRtWCLsLsH+\n/fvVBx9+qPJogstNhO3YuVMMKK1btZJkpncC8NBYsWKlGK6+/nqlOnr0qMqePbuy8EXJkiXVvLlz\nVO7cudXtgHHjx8k43urQEIS0GDxkqGrUqEGsEGF3A5InT64WLVqo0t5/v4rr+OKLLyQ07XPPPacS\nJvxv2WzdupV6+ukKEubkZuJ26ruYQKlSpdQsPQb58+dTFrcevFQOHDRY675CQRFheFfpt1DVsGED\nITPjOgiF+PPBg6pokSKqip7zSZIkURYWFhYWFhZ3JkxOIzdy5coloZEJl4h3WHQPxPh7RmTqEwhO\nooqfzcEY868hA8x1hIsznjJOj5mYIAxMvrPYvCey/WNx98AfyRuTZJglwCws7gxYIuwW48SJExIG\n7eGHH5bTMru1wQg1DWHFielglDbeLYcP/6KO/nZUvMYeeSSXxLk29xL6cOHCRerChYtyeob8Yhhz\nIb0IQ8V3SZMmlfBT1CVNmjQqffr03vJPnjyp9h84oP65+I967LE8siF01otN1q+/HlUpUiRX6dKl\nk5NVEG/33JNSFS9eTLwXCDPA886cOau+3/G9uvLvFalnjhw5pCzqSHi+c+fOq4ezPKzy5c0brZi+\nkF9///23euONtmrs2HFqwYKFqkOH9mH67eeff5b20Ce7d+9WR7SxO+39aaWdweZIo/2Eq/z5p59k\nzCCVnDncjhw5Iu175JFHfNrEfQd0v2LUZvy5BsIuU6ZMstHeu3evOn78uBA/9J3TAG/Awo5XF7lX\nUqZMKUbG++7zrffRo79hg5RyIQgxSpJHpHTp0nI/dXWGfHLKJD/v3LVLrn88/+MqQ4YQuUBWd+zY\nKV4bvCQEIlAhjPbt26fOasNibt1+ynTKDgZHZCOz/v6GrsNOTcoybnjXcPIuceLE3mv36JeQ3bt/\nUPfde5+UCZBT5NX0J/135Miv6oquVxZdZs6cOaO88WFeHDjwk+6ba0IeO+uzZcsWdejQQfXHiT+k\nLjyDOjOW3JciRYow+W8IrQGZkjlzZvm7E3/pNhPCM4GWj7z58qnErhct5BSZYF67wVj88ccfMr7+\ncgf+9ddfMg7c65x/efM+5i3PPf/y6zr46zfGhtOR1Dej7hPkDd3hbCPyyDgjM7t27RaZS5curcqn\ny3TXj3Y6vRiQB9pCvcz8wCsjd+5HpH3O/DdGdzHnjAwY0F7mDnIZkREbD9iD2uh9Qj8XYgnd6xwf\nnrFy5Uot+xlkrJmHRkcSloxrmT9mfqL70INcw88//3xQpUqVSnTK/X6Iq8t6ru3X8/f333+T3En3\n35/G2/dO+XbD3XeA+cwcOnbsuEqcJLF6WMsac8Cpd+jjH3/cq06dOqlSaR2XQ+sXdCAQXab1N33m\n1vNGfukHk/jbAA8f2vrnnycl9xP9HmyuIiP7Hv3sx7TeT+lHhhlr9Bp6yTk2yPbevftkDtDnjz6a\nO8ypUPT8Id0m9HBS3S76g7nplm+egaED+SVPZtq0/40V40CbWSOB0aW79JpBX5UoXlzmPkAWOInL\nuD/0UEbR+8454gQyR9sTJUwk8uH0kmIszfMYC+Ydnom0v6AmXs0YMF++37FDdBNrD/PS39w1487c\noJ/cusQ59+hnyjyvv8uUKbNcb+YR9Vqzdq3MC3Ss0cX+5AIgU/Qr8nD6zBm5nrXKyBygTsgPJ7LZ\nE1AH93qHbkeO0bOMO3J+7dp1IaL9rY0GrC/INHImelzP74h0Ah5s7Fs8+j90A8916hLZO+jvD2q9\njD6n351lIgP0D/3BPuL773eo4yeOq/Tp0mvS/HGRB/qRsmn3ffq6vHp98XeiGR3Ds8jfGi9efNHb\n7sNMgUA9kPufdD3Rbehr99rjxO+/H9P68JyMgdvYh0zQj7TH+Xz2h+QoS6jHl/KZh074G7cruk1l\ny5SRutAPzAH2KfETxFcPha79Rmchk8gma4qzj0P2nb+KrDv3FbQZGeO5yBzPZQ7aiAAWFhYWFlEB\n+7uiRYvKuk7kHNYb1ua4tK4Y8ou9LHXjX/YqzvcE1kTqzp6JuvMvv7Pemo+bGLO4vcG+2oTgNN6F\ndzqBaMheQ/xaWbawsPCLhBkqemLycydBiS6NXXTs1MlTvnwFz3vvv+/J9UhuT6bMD8vn4SxZPR9+\nOMCjjTHeawcNGix/27Fzp/c7TQx4SpV+0nsfnyxZs3lea/u6R2+CPNpA6Kn2/PM+f+dToEBBz7hx\n4z25H80T5m/vdO8uZWvDp+ftt9/x+Rv1at2mjUcbNLx10EYsT+Xnqni6dXvb069/f0/WbDnkWr7T\nRmbP7NmzPdlz5PRMmjzZk+exvD7ldena1bNu3TpPvvyP+3z/wgvV5d6oQG/8PE2aNvU8WaaMRxsr\npX8rVqos9XRCGzzlWYMHD/HUqVvX5/n5Hy/gWbbsywifpY1snhYtWvrcW6hwEc+XX32l7bo35Jo+\nfd6V70eP/tTnXvqfsRoxYoT8vmnTJk+27DlknEs/6TumNWvV8mgjlM/9p06d8jRt1syT+eGs3uvo\n3+XLl/tcV69+fU/t2nU8s2bN8uTImUuuK1ykqNzPM/l97Lhx3uuRyad0n32k6/VI7ke9ZZsxnDx5\niudRl9x0794jTN988cUXPvcjO61at/ZoMsV7jZGNCRMnyng5y6xQ4WmPJoDkupkzv5C+csvqiI8/\nlr9rg7HnmWcrhpHVF1962aONaN7nDRs2TJeT1bN582ZPIDBnmusxdT+PvtVGS13G8DD1ePjhLJ65\n8+Z5tFHQU6x4CU+nNzuHKXfNmjVyrXN8kNWRI0d5x8V8xowZK/8y10Ct2rVFrrRR0KdMbfTzdOnS\nVfp527ZtftszVLeZv/ubfwMHDfKsWLEizPxr2bKVzH+DCxcueDp07Cjy6byuTNlyHm3k9l73zTff\n6LY84vnsswmeqlWr+VxbtFhxz3ffbfOpO9+/3KSJ97vZc+Z4Hs3zmGf48I+kvc77X2neQuabgSaK\nPTlzPSLtc2PqtGlyj7NuT5Qq7anw9DPe39Gt7/fr5yOjfBi/jRs3yjVr164NMzZGb5m+5XdNLvu0\nCb3ZVutg5z3oWuaOEzt27PCUe6p8mPLNZ/hHH3n8wV/faWO3zBl3Gc9WrCRzAH00YeKkMDKQWcsu\nY8vf0euFixTT8+Yln7UHrF+/3iubznosWrRY9KWzvPoNGoh+DQ+BZP+99/v5yD7YpOerc76ztqG3\nnWum0VGffz7De9/q1au1LvXVK8jwgAEDPdpQ4DMOyEegcRg2fLj0x4svvuypXqOmZ+GiRd5ns/5q\nAkHK0UYST+06vmsJz9+0yVffaOLZ07nzWz7XoW+mTp3qXTfM88rrMUUOnHr+sbz5PAsXLvQMGTpU\n5oCz/fQpfevERK1f3XO3Y8dOHk1geq+RuRcqo+6+ePqZZz2aXJDrPvlktNZ3WcP0Ed+7oQlBT4GC\nhcJc27TZK/J3xmDChAlhZLJqtWoeTY74lFW3Xj1Pw0aNPTP1umKup03uthqgxxvp61kHnGWXLfdU\nuLLZpEnTMPfw2bVrl/ydfihbrpzP30o+UUr0kQF6ijX2rS5dPK1atQ7z/C1btnjatHnVZ0zpp1Wr\nVvvUZfbsOX77jzXIwMhJ0aLFPNrg4f3evyw+GUYWnejb9z25bv78BWH+9sUXs+Rv7E+AJsY8AwcO\n1Pu97N7ykUWZK/pv4Y1blmzZPJrEilBnAXRT3nz5ffoX0Fau+9//XvDqKvQ937nLY+1xzve4ipvx\nzmFhERFYg9CrPXr08PTu3dtjYWHxH+rUCXmfXrJkiayztxrsw5mv7Od4R2R/E+wHGwm2AOwjvOex\nlrK/pjz0gNmPWtyeYO+vyS/ZW5gPv9+pYL3qrm2YzAVsGLxrIc/s/6wsW1jc/ohp3irqLjcWMQZO\n606ZMlW93ratWrpksRo/fpx42Wijn9LGh3DvzZjxQZUjR3Y1ZPBg9fWKFWrevLmqUKFCkvfrq6+W\ny8nr4cOGqYYNG8pJH65b/tWXatasLyR3FmHxnixdWk47TZ8+Tf72xuuvS9k9evZUk6dMUZUrV1az\nZ81SixctUk2avCy5kdq1bx8mcbw2DqrJkyarZk2bqKn6vnf79PGePuZkUu/efdSLLzaWNk6fNlVO\nD0+bNl299HITVebJJ9X8efPUsqVL1LPPPKO2bd+u++EzFRVwypoT2E8//bSc/H9et5MT6e4krQba\nmC0nZj77bLxasWK56qPrfe3qVfXuu++KB0wg0CZt6FKrv/lGvf12N7Vi+Vdq9OhPVNKkSZQ2MooX\nD+jc+U3x6howcKDav/+At479P/hAPfHEE6pFixbeMiXx/Ucfyelz+ny+Hs86dWqrrVu3KW18F88d\nwAkvktCSM+vVNq3VsmVLdZ9PltPprVq3kZPSTuzbv1+9072Hqv7CC3qMJqlhw4YG9DQB1H3UqE9U\nuzfeUF/qspEbPA569uolH+q0aOEC9cXMGXJ6fKIuEy8pg++++0517PSmeBbNnPG5jHnjxo0kn1L/\n/h+E6ceePXupfHn1tbo8nvfSiy+KF4c2WMvfyW1H+/DUQG6RUz4NGzSQMjiFzin1fu+/r7768kt5\nXsVnn5W47p/PmKEiA2T+S11Gs2bN1No138i8GjJ4kKpatap4k9SvX18NHTJErm3RornU4yv9eUbL\nW2ShjdkSYixzpkxqgpY/yurS5S2RDSdq1qwpp+nxdHTi9Okzau26dZLjzcSu9we8edzzD5nUhJNq\n2ap1mPn31fLlShMc3vsZezwBmP8L5s9Xq1Z+rV59tY2cuh8yZFgYzyRkJGWqlGrK5EnSf+/1fVe8\nzbp07aIign4ZU9rAL2E758yerWZ9MVNVqlRR9/FXem6+G0bvRBW0Ce+jWrpvp0+bpr5ZvVp01tmz\n59SHHw6QPkOX0lfMx9KlS0nfMUYd2rcPt2xk6Ltt29THH48QvTBs6BDRsZp49Mbtx+NksJajs1r3\nTJ40Uf1y+JBavWqleIbgQTZn9izV9rXXVLAgWS+eqSP1M9evWyv6Gr1Us2YNWQeQn8F6HuOxxbzl\nGv5to/VHtarVonRiDu+O17WOeFDr2YkTJsg8aNv2NbVp0xbRV+HlLHLLPv3UV+vcz7W+iAjocvQ2\neQ0XLpiv1q1dI2WwzhUtWsR7HacfH82dW434aLiW2ZXqc73GMZYjPxklXihA76tU6zaviq7/YuZM\ndeSXw1IeazAeWt98s9q7JgI8ajXRqZ5/vpqMG7oBj0e8Vl5r+7r8vbeWf9ozaNBA+b5d+3bi2WLA\n/EAvNWrUUMvUEtHzyFqfd/uqdXo+O4En2Lhx49VHw4eK7GnjpPRr29ffUJqUFB1Ev48d86l4HLJ+\n4LljME/P6+49eqrHH39czZkzW/QremCWnlt4Sztx4eJFfW0PVaRIEdkboA9e1LoYb2dNgMjp4tq1\na6kRIz6Stb1qlSpeXVy3bp0w44ROps9btWop8v/R8GFy7bt9esvfNeGi9xm9ZIzQ70sWL1ZvvdVZ\nr4+HRC/h1emEJqNU167dRF99Nn68rGWBPA+Z3xm0XL7xxutqwYIQncUei/k3xtVuJ3r27CGyhL4j\nTM+Xy5ZJnfEqwnu0br36ei79LbnDVn69Qg3Vcxsvqg56zUdnODF9+ucyFtOmTpW+bNigvjy/Xv0G\nasvWLXp9+0DkhGdyL3sEnmGQJk1qLeNF1aejR2v9tErmK3r7Mz3X8FoLBKcsvt2tm8gHe5Pr12+E\nkUUnyBML5oWeHjbAG4z9HXrpuecqy5z5dMwYvUcdqdfFKnpPuEjvVWeK3AwZMlTvDRaq8MZtyuTJ\n4mVpdNaADz8QfcTa3VevFUZnRRZ99frPmtS/fz9Zuxm7997rKyE5w/MatLCwsLCwCAZ4QbM3xKuG\nfSTvu+61/2bAE+oBht2A/T2REfg5MuB+3kV472Kd50MZvGeZdy2PzRd4W8J4L/IexHsAe9Hvv/9e\nfr4b4HGEArV5Ly0sLPzBvhnGEbz80kvq9dfbys8YtbNlzaZq1qqlpmoD7Qsv/E8MEP4AmYExyIl3\ntPGzRs1amvzYp6pVqyqGkwzp04nBKFu2rBL6ywACgUUSF/lHtOGP8EYAombmzC9UkcKF1ZhPR3uN\npIRv+vvv05p4WSYEkNP4j/EFg/dLui3+UKN6ddX5zTe9Bon27d7Qxrx28kwMxiYUzmBtWHy8QEEx\nskYFy5evkA1hzRo1pd6VK1XWpNp49YUmlsg14zaIEG4HQ5UJ6UM/HDiwX4x0hJwMRBht3LhJGy3X\na1KojuRX41mS/0SvtW9o4/AkbezBsJssWTIxTv/vherqDd1mCIc32rWXDWi/fu+HCdOE2/qokSO9\nhiAMmBB1kF6QTeXKlZOfN27arBppwy9EmzEGEnquum43BlIMQAbcX79eXW14GxC0wfuVV5oJ2QHy\n5s0r4YbGjB2rSYlKqnv37t4wgV01udGiRUsx/BcvXly+w8BNSKJR2uCcPrRfIcwOaCLwS01oYHx3\nhlMsVrSojLsJL9arV0+1afNmCRt18eI/YhDEMJ0oUQIx9jplGCC/GKWdeOedt9UqTW4QYjIywEiY\nIGECMVqaOhKaj3EGhIfMmi2r/AzR6qwLLxHBgpeMcZrsTaif9YnuJ5M7h/LOn7+gichR3msNWY0M\nN9D1MmO4bdt3Yvhr07p1wPBrBu751+Tll7RBvre00d/8w4hqjNv0by9NjDuBURmj/ZGjR8R46wwl\nmh2yQRP5Zu7Qf8grBD3XRmTk5AUTo7mpK/LXQMv6ylWrJLxbTOSKog9fdxAcIGvWLOprTZgQ9pJQ\napA0hD1LpvsWHczYBGtQ/Wz8OK9sMLaEGR00eIjMI3Qy4UIJLwrBWr58ebkOorV581fEqI6ejUx4\nWMLoYVx+/vnnpW1EviMMmwEvu4S6Q39AwANC0Jmfo4IpWm+ic5Af5ifIpdtAeNKvv/5ajP60yQ10\nnz/Z5994us3ol/DAHKWNVao8JwQSQG9CmDuBHI0bN9b7e65cOSWv25tvdhbdQm43Dg0QDhGi/okn\nSnrLaqOv4/DAn/pZORz5JenH5ypXVoM0aeHUpZAHhALt0qWz6E7THuZyX01wQfxx6IHwuxxwYRw+\n6N/fe//YsWO0/iyhJk6cpMqWLev9Ht3eVZPjJFkHyCPzfunSZUIYMKepByH/ftW6oG/f94Q8o995\n8Rs4cJAYbSClzbx7/7339Pq6S+8vpqqmTZv47C8K6PUGcs+E/IFIgXg8qOcE6whlZc+RXeqVVhOA\nbl3sBDrJ5CXl+ux6DTDXEw5xtCZ40OcQayZU4uOP51f36vrQ9xyUefPNTt7yeD5E3IAPP4wwJBH6\ncrAmIp1g3Vmzdp3a/cNu0b/+SDT0oQkZdO+9zPlHvfNw1CefCGFKfTlUAiDI2Pu8q8cYmf/f//7n\nLSuV7u9Bui85EAI6d+6stm79TvflIdVDy/gLoWUgJ5v1erd69TdSlhkn9ILRDYA1tL0mspDfQ5os\nzOonVC5gjTWySJsB8oGxrEf3nl5ZdAOZIeclB0hOnTrlDdX5+7FjUj/mE+NHuMmJEyaKXmYszLqd\nQesfiMKJkyaLXmPvo8IZN6Oz6tWr5+1j9phRxW9HCcubWf1P60Aj04SStLCwsLCwiEnwjovdgP0W\naybrYZYAa3JMg70dHwg43qnCO3QWbHkctGVPxL6N8sy7jlmbbXi52wuTQm2DvXr18r4/3E1wh0WM\nTroVCwuLOxNWK8QBoJwrVCjv8x0GO0goPHM4qRMMuA6jnjmZdO7sORVV4FEF6mhDuHPzgxEDQgWD\n/25taHGCnF/VqlULWCZtdBqRM2XOrA0lSVUhbVxxLlDk1YCc+/PkSRVZYERatHixeArg+QDIb5L3\nsbzqG21kwhjtBsZPZ14L6oJxC08kDEeBwCln+gFjM6ea8WDigxErqTYAQVBcCT2dRX6kLm+9JUb8\nas//T+7l92x+km0++WRpH6KAPq9Zo4ac0iJHDICk4NmP62djWDXPNmSI8TpxolUoWRcM2AyXKVPG\n5zuTGLSs/t6Zuyt7qJH4r1MhfYWBEaMZeTuQSVM38uFAIplcaE7gvWeMaYDyKfeU7v8rV4InlwD5\nipgHnNrDGIYRLjIoVrSYiqdV4yvNW6i1a9dG+wUjEDA0Hj9+TE78u5Ou/u9533mEIfmpp8pJzqxd\nofMO74wF2qAJGVemzJMRPS7M/MMoDZ7SBnn3/IPcCDT/kMPjeh4xl+LFS6D+vfxvGAKwRIkSYfIF\nZcoUYugOZl7jleasK/Ph+WrPizy5ZScmgMxi3MXLgrZf1m2C8IgqIE7cBAE6hTE7FTpPblwPieXv\nNuibufXvv5F7fulSpcWw/Nprbb15m5xApzIn8QKCEA/kFRIZkFdOSA49VmaeH9WkEmPNPA/0DF7c\nA8l+ubJlInyuyTf3/vv9hPSPaI7zMsThCE5IXr92Xfr8jCZigJFd94EEfkcuLl3yHQee27RZ0zC6\n9DtNcCRJkliIFNMXfMj5Rr62vXpMqMe2bdukXAgH53WsXRAP5ON0ej2iw0qUKOn9nbmaPVuIzi3/\nVHmfemTOlFnmjZljkDaMB2ThSa1vzLNYr1ivaRv55JyoWKmij0zec08K0dvoVT4xBfKF4Q1frlxZ\nn3xh0i5N/vAd8uXWv61atox0Xg7GGDLnNz0/kuu1mXnHJ7KAxAIQV86xy/hgRhkz+tWJtHpfQb5T\nA+bgvfqTPn06TfgV8Lk2mx5T6uT0CHOCsUR+4+n/8Fg/e+6sCoRAsogedcqiP9SqVVPasmDBAu93\nyzTpSt34G/LG+oqMQYyxrpvyuQZik7nGxwl/42Z0VqPGjeWkcnTxpF4H2WOhA7dv3x5ra7eFxd0A\na/i2sAgfrGlE48B7/GZ5h5m1mz0jB4picp1j7efdx3iG8c7Cd4Z4s7h98EvofvROzwcWLKz8WlhY\nuGE9wuIACCHmz+MrszZaGjKGk0f+wMs+3jc7du4QAwlG1EChgiIDkrODhzVZ5UbGUKPV0d98DdIY\nQNzGbyfSh3qbGSQQ43s8dV/qsAniMeZFZdGCuIAsoB+eebai93uMSBjxZs2arTp08A1r5i/xfKJQ\nI3x4dTBkEyfB/eHqlatisEoSathu2bKFnNRmo4wBmN/9IUOGB/x8l0HGlYTy4Jcjv8i/vXr1DnMt\nxq6Lro04/Znd4dUQETiR75ZJI1fptVHUp+zQ701fHdMGRzbOtLOaJi/cYGzc5C5kjhuJEiUM3Xyr\nCMGY9//gQ3kmm3fCUyZIkFC8eiILPDDpryFDh6iXmzRV96dJo8nLauL156+ewcItSxBh//57RaXT\nxm+3Ed4tk7xsvfTiS+rLL78SrzDIV/r5669XqbKaOAjmFKJ7/hmiCa8ONxhrZ30JFzhixAiRX0gH\n7uUayCN/cgUR4jaiGLLNE8RLm/FE8C0zk/yLQTtCBCEzEDWESCPUIwZy5JIP5Ov94YQNDQZuwz5I\n6NIpqbTe57DD7NmzVdEihbVOKC7k0ISJE8XTI1euR1RkgBdlGk26TJs2TT1X5UvxwquhCfR6deuK\nAR4CZ+rUKap3n3d1u8erT0aPVoUKFhKCvGLFZyM0ernll3n2668ha4C/ec7zzp71b6xHngLJPutI\nRIA8wxN60KBBatjwj9SgwYNVBU2e4OFnPEB4gV/x9Uo1c8YMvT7ulN+ZRyb8iwFkAQcSZn0xSzwv\nIdmQ6xEjPtbE0kOasCrk82wI+yx6bXYCfYdOZr3GW8cNnntFt5frzLrxyehP1LhxYUP0PaDnKYYU\nQ4hyb2rXGoknHfJ03333+nxvEqF7boSMlTn4sWbNGrVp06Ywz6ItFy/66mLnoRCDxIkSq5h+h/z9\nt9/FgONvb4N3KWsQZBlrhVmL0IvByAeg7UOHDhPP9bNnz2gCKKluR0JNIJ2XwzFRgRm7mjVrhfkb\n667bAJbpIV89aJLRp0hxj/4k97mWMQVmntE3eKXjdQmxzX3IBHIcHiIji/68W2vXqiUhiT+fMVM1\nbRpC+M5fEHLgAk9I8MsvIWEZZ86c6U3C7gSewE7SNNC4OXUWnuyEdsajrmWL5qKzwoO/vVnPHj3E\nAx1PQlMeXpOvNGsWYXkWFhYhcJ6it7CwiBjspapUqSJpGFasWCHkmImSEJMwhBT7opg8mOQEewP2\nH+ZZ7DvQB+xBrF6I22A/Zg4x4aUISPfh3P/gIeY+gMi13GdSiECetWvXLsx1BtgBhg8fLtfzM9f5\nK9d5PR5qPIefo1I+ERSC8Wxzy6iVWQsLi0CwRFgcAKdv/MV1vqwNtSjwQCHPCOfU7JXmYtjo/s47\nqmCBAkJEcQqfMHzRgTHKYKx040qoETFpEt96JYifINwFJ1GAkGIx5a5MP+Ihg9EMrypnv93QhkFC\nSS1eskRCj/l4XCWM3OlyA8L+UPfevXupPKGhvdx/d9aBDfLevT/qTWUiObXM73kdp8UN3IZJgOGW\nNhjjmSm3f7/3/RIRSUNDEhnEjx8vUv1MeLKEAQjViMpJElo3Qq5185MTKiRsmy9xQ59EFZygb9K0\nmfzbtm1bVbJkCSEyeEmoWau2iiyoHyFFK1SooImnZWrS5Cl6AzdZwl7NnTNHQjlFCD9G4wsXfF9a\nzMvFVW3YdBse/J3ww8CPZ8fqVas0idZOrVy5Ssv8JVWpYsWgNnqB5l9E96KbevbsKaHfatSormrX\nri0GXuSbPD7+yI7EiZOo6ODS5Uthv7sUYmROnjxZhPefj8CLlv4dMmSIGv3pGPFG7N79HfGWQnd0\ne/sdOWAQHSQKQp7JsUSo1FdeeUW1a99BdBJjAelNCLXIhghjHejYoYPkkyMX39w5cyXXGeTwR/qF\ngvGijePGjpFchTNmzlBztDy3adNGdezUSbV97VVvWf5ID0I5OgHpwjMhjvq+28dvnfwRggBvlUCy\nH2wOOHKBTZkyWbdvm5o7b660ec3atdK+0prQgvjp1u1tlVYb2t/q/KaEQWR93Lhxo+r8VheffiOX\nFzoEL1CugURgHJARtwE9vq6r+7AJOpF1BPkZOGCAbndYcueee1LKfeZgRId27f16cqIXkA2zJ/D3\nPBDMnDfrROXKlYTId4NyszpC1PIsp7dvbIKDDuCKvz2G7n/maJKkSXzaSX2DXcdef/0N9d32berF\nxi9KHivC9iXUY92hfUd16d9LKiogRCry8vn06bKmuuEmERMG8FyjTfEiaAde1R06dhRPUnJf5tbk\nXWoti3hOtWnzasD7IiOL/oBBD89+yKkf9uyRtZQwoq+80tRLSBq5erFxY/ESc4OyHwo9uGB+9zdu\nRmeRE3SJ3p/RryNHjlQ//XTAq7MCQfbNWk6SOfZYSTWp3l4bVxo3aiThu6dqQow8mN9+u0FyTcbE\nITELi7sB1gPEwiLygADDaL9hwwYJmYinmDPaSXRg5iN7w9giwZzPYo3lXzcBZkPMxV3gBWYIMBMp\nw5BbBi+//LIPAQVRRr5W3nWM99iwYcPkM3HiRLne/QyiNvAv13Mf1/HhHgiuiK6PqHxsHYYw43oI\nPq6lnhBu4cHMEyOzdi2zsLAIBEuExQEQWgxSi1xQ3u808UFuI058c7LeH9auWyfeYiM+Gu5zSuKn\nn34Oe7FeECLjPv9IqDcCebqeeeZpn79hHAFZst6cWNjBgk3n9u07xEA6ZPDgMJ4GeAlNnTpN7d69\nW3KFRRfk66BPr129JnndwgN5rjq92VmS1Q/Qxulub3eT3+fOmR1mk3zo0OEwxmGIM4/nhpxwBtlD\njZf/aLI0omffbODlgaGNE2vks4kpw6p3U3PDd0ODjBIur1vXrqqVw8sOLzHy80QVEC6QCuRcGjJk\nqPpYG+gIu8npcu/YuDZX8cSQnEidO+9LDjGev7jCZmE0RUZ/PfKrvHA45YAcS25ghKxWtap6v18/\n9c2aNWqpNvRx+r18+adUbILN6KrV32iyN48YVs14EnoyKuHFgsFhPQecYJ7t2fOjvIBlDPWWw4hK\nf59zETT++toNZJM2QWoOHzbUm98ML7HzrvICyV1MAN2RKtW96kVtCC5ZooRKpeuBd1J0vBfwJnvt\n1TaSk6drl65iBEZ/FClSWP5OH5L3qI9+oeC59es3EK+0V5o1De1T1qTLYV4cDoV6CRtQTk6tAyFC\neamKKO+bE1wbSPaPHz8RdDnUl9C2JUoUlxetdppc4mUJImyjJsL+/vsv/ZLXS73gyNsEIe32qqEO\nEHC8wBUuVFA8WjhgEGjtdQMZyaUJi2+18YPQc+HpZIgNAHEf27obMo+6/fHHn3LoIqYMGGZO3IjG\nnEiXLr0e9xSyz2E8nN5Jv/9+TLx5H8+fL+gxcOKffy5JWEVkonevnt52oysoN3mKiMl0f2DNx1se\nXZwtW1YVm1i/fr3oPXRuwYL/hVHkAER4iIwsBkK9unXUdE1KLViwUKXRxDDE9fOOsNfkUuQ5zP2Y\nkCs8gF9+6UVVp05t9bYmr5evWOHVWUkSJ5F+cHvb4VHNePqLpkB56Dby7HJIbPacuTJuuR+JnJet\nhcXdCJNbxcLCIvJgP0u+WpM7jP0xBFlMgLWQsMM3K+wvtiiz35MDPNa7Jk6jffv28gF49PM+tHr1\n6oCeV7wrQy7xdw5ZmXdPQ0ZRlpuoMqQW5UL0muv5nuvx3HI+L5jrne+81Bu7A/UxxBzXE+GEupJf\n2ZQTCG7yy8qthYWFP9hjHXEEEyZO8uakwSC3WBvcyZ9BuCxjpHXjcmjuknjx4nsVPsY1kyDTCcIM\nUS75pIIB+Yh47uczZkg+CAOM3+PGjpck8GXLRJzLJaZAqKpPx4yR3Fj+QPtXrlql/j79txhs3CQY\ngCzk+xVff61iAoSkw6BLiDFnLhw2qBCUZjyp28CBA8UD7K3OneUEdVdN2vD7pMmTw7xwYsDDy8Hc\nS564BQsXqAcffMDrefbkk09qo3kqNXr0pxKuyZTBv2wgYvu0WHhgw8EJfE6Rz503zycMGSfZ6Kuo\nvGTzchE/fgLJw+J8CTBeiwkT/RdO87J+5rhx44U8jCyQcafRDQNtkSJFQp4VOqZ4bAB3XZCv9Okz\nCFls8stRJ8jNL7/80uc5zC/Ib2R6tSZlDJAbf3MY8HLFhnEG4d527FDlK1QIOlRYVMGYXb9+TSVN\nlsTrrUMdV+n55iZHYgrM0Z9C8+HRf7T1669XakN0du8Gm/6jv/HeMqE2uXbv3n3iNRceMLwTolHy\nQDnGD++pvfv2+lyL90MiTf79fux3IcpiEuu/XS9z9ekKT4vHEiQYXgvXrgXnFeXEiRN/+Mw1SNJs\n2bOpG3rMEiQIWerRDc65B2mdPVtW8W5hbCEd7tV6hRxCkBEGGJ2/mDU7zDMrV66sSdsjavLkKT5z\nhv5FZwcCnh6BZH/hwoUqItBO5qmZe5LXMdcjQmz+G0rOGk8jJ8Fy/Phx8R5z658lS5ZI/WtUf0Fe\nvPCco2x/ntqBQHhJ6jFs2HBvHjhg+sKQb8WLFxcSfOq0abIGOHX3BS0L7txK0QHjWbpUKfEuol+d\n7aEP/whnjMItV+s/dDF7g4hC9QUCecdKlXpCwlZC1hrQ/rlz5wrJ8cyzz0bpBRZ9dUP3J97JRmcx\nnniFHzr4s4oqCH1Effr17+fjCWvWfHeuxOjgypWQsTLe+YAQz1OnTY3w3mBlMRCYA+Sp/eqrr9Qy\nvW6RE815UAtPT67BS3rTps1R3n+4dRbeXYT9deosdBhzc6vWzWYs2ecSJtidb5JwwU4Zp7y8efOF\neJ/G0qENCwsLCwsLNwiNiMGe9Wvp0qUxkjuMMoKNmhBdsG6yV2BNDXkPDAmZaMImWtz+wJ4wYcIE\nNU/bapxkFO/ZyC77OefBUsIn8nuTJk18yCiux8PLXBPM9Xh2mZCJThw+fNjHO81cTz2N51pEcJK3\nFhYWFoFgPcLiADDGYuitW6++EFDktsBgQ5iXpk2bBHSrL126lNxL+KaD2rjD5gSjIrm7jKHeACNr\nwoSJVP/+H4jhMkXyFOrFFxsHLJtTtu+8/bbq0bOn1IvwaylT3qNWf7NGDMVtWrdWefJELnRXdDD9\n88/V4MFDtMG4gpo4cUKYv5/Uhtrly1eonNpQXqxYMb9lFC5USAw6nHLu2qWLii5y5sypXnv1VTVA\nk1y169SRUIAs0IwfSXNbtmwlJ6tXrlwpeX8I18h4gpdfekm+//TTT1UhvdiXLFnSWy4bTzwTKuo+\nxwi/bt06dUCTAvXr1VP5Q41RtKNlixYS9ofxIcQWuWVIXL9jx071yivNJDzQrQKhyDZt2qh69Ogp\nxjK8K9jA//zzQW2YO6mWasNzZD3FMOpinKM/euoN1MOZHxZiBNmGFBkzZqwY/fDk4jT8nh/2qDRp\nUqvIAuMh87FI0SJCTBzTxnNkxpzyA5ySZ2O2cOEiPZeSazIqreQSQvYqlH9KfThgoGr84ksyby5c\nvKA2btwkRngn2KARjg7ypfNbb6lVq1cL2bl923b14969fvO3PJjxQU1+lVczZ8yU/iOfWWwDXVC0\nSFHdp9+qNzWRy7w/sP+A2rxlixBEsYEzZ86qFnr+4O2GwR3S7aSWm1dfbSM5nQBeO8xp+q1Fy5aq\n1BOl5Jo1WkddjcDQiywVLkJ+rjmqfbv26gltkMerEP2Jl5HzHY9+Juzs5ClTVBdNYBcsUFDCjWEU\njy7w3jp9+ox6Wb8kpE+fTg418HzKb6Hn9xMOvRAROLWXThNBJkQuOgivQbxDeCHH6/iF6jVE1zya\nO7c8Z/v329XOnbvE6xH5RibJ0TNo0GDp06q6jVevXtEG8eV+jfyQ+jxjyNChaqOe7+gl8iJC/PK8\nuXPn+H1p8Sf7GbVs4wWya/cuv7LvxFfLl6shej0opkml7NpQDqlJGRB2Jvci+nbs2LGSR3Hvj3gd\nXQ3NF3UujAdL/vxar34+Q0IK400inp26f3JoHf/SSy+qEvo5EYFrCBWHrq+j1wMOK+CFfOzYcbVz\n1071Qf/+8h1j07VrF9GN9bTufvqZpyVP1qmTp9T3Wu9UqlRRvdmpk4op8LLZoGFDCbO3aPESlStn\nDvGU5YCF0u+I5FCLLMgXRR5AwkwyJx7R8pXnsccidTgGeXtNywCenm1ff13Pp+d036dTu/X4Q66U\n0WVVrVJVRQUcUOEENnqjR48emtjMonZr0pUcov5yoAUL9O38BfNlr1HvaAM5IMF68/vvv0s7Roz4\nSD0eQ15+eDpy+OcNvRfAM/nSP5fkMMWl0MMY4cEpi8ztcnpfiR4/rmXx+x3fe2UxEJB/QuD269df\n9ot9+vT2mZPo3jf0mL3Z+S3RU09pPU0+WfZhePNmy5ZV8vdFBKOz8uV9TLwXDx/+RffvAq/OAnjv\n33dfajVy5CjxICWn5Y+6r/doEtmtJxo1flFkkzGgPAwwHCojFPMj1hvMwiIomIgU1ohoYRE9sM8p\nWrSoN2Qdh0jYmyRKFLl0AMbDJaYP40UE9srs/TmgZ0Ic21xhdw54P4OkAtg9nGEUTWhFJ8zf3V5i\nAM8uQ2IZmDCNkFrm50BlGuARBuHFvzzHhEfkXyc5FiysrFpYWASCJcLiAO7TRvz3339PwvZNn/65\nnM5no/R627ZymtsAD6BMmTIJQQYIOzd40EAJ2zZF3wspli9vXvXuu33UJ598qg0M/xl8WDx6dH9H\njRs/Xk2ZMlWIA/L9sEnDcCC5XFyLRYMG9cU7gDw65NYCnLjnmSx4BiwyGHHd5JtBmjT3S73dRouk\nSclZk8mvxxs5iB7QpIDBg7qOeL7kesR/8tk/NQFE+EHCOAbKS8PGs2GDBmrExx+rXbt2iXGEeqXW\nRh03kul+yZw5k5B/gUC7W7dupQmxHNoA9rEmtlaLBxKEY/78+bSx+REhtWbMnCnG+w8/+MDbB2wo\nMUZhuGHs2CgbQGJxonrp0i8l9FyqVPeotm1fk5B8zrxdbV97TYxF48eNV+vXfxtyilqXny9fXjGG\nGzBmeDgE6hP64N5U/40BRtkHpe995eHe++6Va5O4yA+IAunH1Kl9njlVEwcYyLdv/15c3CmPUJ94\n5pl+MLKRIEFYVZQhwwMiB06x7KKN5t21AXmZJor5QzNNLJLjaaQe0/fef1/NmTNbxdd9lCsn/TJW\nG+Ln+eRrSq+NY5kyZQ43lBMGQryM8BK5ft0joQ4Z41c16WmMaRhT33nnbTV06DA1b958qUvPjN2l\nXEIyHddk6IoVK8XjD6Ns8eLFZP69934/H29FDKkTPhuvBmij4Zo1a0SmIFinTJ6kBg4cJIZhn/HS\n/VZDG+shwiAAioZ6qoUHcrz4m3/J9Pzj+/vuDUtU0O8QEwDS6J13uqn+H3yotmzZqrZu/U7GF/lD\nfgirZ8C1mTM/5FcXkN+G5xkClLbyOyHSnKCenTp2UPv275Ok05cv/yueS126vCXz14C+7tfvfV2v\nD6Re+/btF/mCWHiqXDltoO/mk6sMcilJ4pB8MtQBAgyvC3JJYSSnfoTmQocO1WSoU/rbt2+nCdFj\narM20G/evEVVrlRJPffcc96+NblnArXJPFP6O3VIf0MUQaRmzfqwyFXKlKlkDuPlsHbteiGolixe\nJPrZDX/PgUAhj5vxMoKEqVq1qjZYt5Xx4GU2f758atPmzerbb7+Vfr5H67fmzZvrl42XvHOCnGXo\nnfnzF6gp06aJVwVGecYbfcU6ZECoVubZqE8+EfIZbzyAxxdeoYmTBM4V50/20VPoxUkTJ/nI/n+y\nGqKnIKgfePBBuQ+inbojk931nISEAoRH7Nu3rxo7bpyaNn265FfkmbSXnHfmEAh1njVrltzP3+mr\nGzeuC6lOKA9e0qZPm6p14oNCAGTK7F9fIQPkmntMG/Un6vpDEAL6Gf3uXJfq6joS4nPExyPVhg0b\n5bQtujuHntPU24xxoOdh5M+s+8OdZyplqpQyJs5wgo8+mltC8A4eMkR0MeQn5DJzqnHj/w5LsB5n\n0vfe6yfUHPmejjmIfHRY/379hGRbtWq1fsFdI4c8AhFhrC+sp8ldOZ+KFC6sRn8yUvqBcYQIZj/Q\nXMsg62Dq1P/ppowPZtT9BMEd3EsteesGDBiovl65SuYDB0UIk3hRE0qrVq4MP5+p1mv0Ly/f7hxl\nn44ercaP/0xOuuKVZNb8Z599Rj2UMTQfl74H/WnCuDqBHLPHcz+dwxROXUL4F9Z9wvrxPPQH3oRd\n3uqsmuq9gBknf3LilEW8NVesCPGC9yeLgVCzRg25F3Aox42nn66g6zVWfaz3Pnixb9q4SWSYcS5e\n4j8CP7xxc+ss+h2i/p23u3nXELzg+/d7T32sibAvNQGeQMs887+3lj3mJ3rZgNDBlLdvX4gekj4r\nUUK1bNH8puW+s7C43REvNJS+9fqwsIgZcHCSPSZrHe81hBR258oOBDMP2ZdHJkpBTCAkQsU1eTbr\n83Xx1k4QJn2Dxe0L8m+ZcITseQ2R5Y8IiyjtgDsEoynDhGsMBrxXIF94ihHaEWDD9BdGMRjYHGEW\nFhaBEC9hhooxqh2unvhK3Sm4GXHSO735puR8IJE3pMa58+fldDund4PdZBAa7uzZM95QYeGBkHFn\nTp+RU8z+civ4Ay9EJqRWbIdhCwQT0oeNZETeArcKhOvhtBZGSAzBkd0kEr6qdp266u1u3VSbNq3V\nFb3hJTwUBq+ITo8RGo5nQ+DdE4CQvFVgA438YIiCFIpuwnoThor+RR5NP/OCgHfNPfekiHZyYhPi\niRxsGN8Dkbw8k3BVtM1tNIV4IMzXvfp7yISIgPyAiHItEW6SXEh4leCReLMQ0idnhSTA8BobL0Fz\n5s5VHTt0VMOGD1M1NGFKqDxIYfo2PLnB25C5gjxE5qQlbaLfkVHaFB5ByrWMJ95mEGDR0UO8THbs\n2EkI+Y8/HiEvxU5A4LbTm/4JEz5Tzzz9dNDloifxioIguS/AeoCeYBwJucaaEchAjGyTT4kwuMHM\nJ57NnKEPWVsi0z+MAX1CfYKVKzN25PxKliypPNOfjNAO6sXf/fVHY01cY5xYuGCheDk5MXLkSDVo\n8BAZo6qR8ACkboTO49lmPQgExoNrk2sdk1JfG5vGBae+CtRfkQE5LwlHTI0jmj/hgf5i74POZG5F\nt14GZu9CvaKTdy8QRB9Inr+U4r0dG0AHsq7df3+aKJE59C06FB3J2hKeLEanjuhf+gB5j4wcoDeQ\nyWt6/nMYIVD9GMu//z4tIROdh278lce4UB57p6jsxW4VbG4mi7gAZJD59u6778pcxjBpYWERAnIb\nMSciylMUCITw5YAV9gwOPUe0vzaG/JD9btTzXkcVrO/oAd6DWU/Zh7C/j6l9mkXswOQIw0srvBxh\nHNQ2oQedMu3vfmfesWDk31xP2YHqwPeB/oYXGQceIeuYM+5cZm706dNH9oDdtB2N/ZTxYLSejBYW\ndwYSPVBJxSSsR1gcQ6oIjOD+QCJzNlTBAG+yBx7IoCIDFo80frymbibYdGU0p63jKDAypYzC+AUC\nobnSBkk8YnxyegHEJbBpDlY+gwHy6C+8FQRI+vRRD3vlBJsljG3hGdzMM/HO8IckMtceUMEiGNnh\nJQjjPN4cdUM9X24WQvok5o3J4QHDajAGZl4ko0J+0qZgDwQYz4uYwKVLl+VlGJLUhAAzEIOvJhdA\nZNuEnoxI5niRDcYYjmw/kCH4tYJnE1YwKoiK3jRjF9H40Y7wwuEREjNzpsziMegGpCJIlTI4GXHW\nLVjiJdjxiAmEp6+iAkiJdFEccyfor3tTRa6Pg0Fs710iWh9iAui/Bx8Mfh1xg76N7f1BsHraH9Ab\nwewPGMu0aSPeD1FedMJfWlhYWFhYxBawZbBGkQcZQ38w3mG8F8RkDtLIgLUXcoGPyRNmD2zcGTD5\nvAhFGAyxZUIT7ty5M8z1JvynM4ShIbg47BdM+RxcM4SXyVPGB+K5Q4cOkocMTzHSh1hYWFhEF1E7\nvmthYWFhcdNA+L6vvvpKtXn1VXXgwE+qSdMm1th3G4Owhfny5xdPJHIfMr6E4+Ql4t2+70nITV4k\nCkUhHrpF5PD444+rH374QcLoEfaS04bkkur73nsStpYwt0WKFFYWFhYWFhZ3OsypeWvstrCIHXAo\nCW8wjPzk8yVfLl7bgXArw7txuAQCzE2CWf1w58Ad8tCQWm6Qs4tDfhBS7tCJEFR4gDnLMrnEuN79\nDO4fPny4Tzlcg8cl5bhhiDR/IRv9wYZEtLCwiAjWI+wWQ1x15Sfrrnu3w7x8WtdtCzfIF7b9+x0q\nZap7JBdPq5Yt1Z2I+KGynyD+nR1ygxfLFs1fUefOnVXz5i+QXHKsBeSAw0uMXDeER71ZnkJ3M955\n+2317+V/1Zw5c9T4zz6TsUmYKKHktXqxcWPJAxndUKsWFhYWFha3AzB2W1hYxD7YW1apUsWbOwxy\nzB0lwgCPrFsB3k2cRJj52FBztz/IuUXuLUNUkZsWby+Tmws4iSdIMOOdVahQITV06FD5Hs8y7uEA\nJ3ngDfDq4npCFkJw8awCBQp4n4H3F96Q5h7uhzwzpJrJCcb11JGfDbkWLCwZZmFhEQiWCLvFeLVN\nG1W/fn1JMG5xdyN79uzqiy9mqtyPPKIsLJz48MMPJQ9g2rTpRFdENRdPXEeJEiXUF7O+kJfBOx2E\nR/mgf38JkUguLjbrKZKn0Bv9eyVU2J06xnENhJIcNWqk+u233yT3IK9M5OoiXxlhBO2LvoWFhYXF\n3QKbq87C4uaCdx5Igw0bNkjIRLxfzAGsuODZYvIGGo8w621zZwCZmzdvnhBbEFN8IJsIPUg4Q8gn\ncnQVdEQngcziGsitGjVqyHeGIONvTrlgLSHsIs/hev5ugIz7yzVGHbgeMsxJyHEdxFugfGLhwb7H\nWVhY+EO8hBkqxuhKdvXEV+pOgX0ZsLCwsLCwsLCwsLCITdh3Dou4AGP0xnCZIEECMXBaWFiEAM8W\n5kQwOY+iAogwPhj8IciYi3iDnTx5Ut0qcEgsRYoU8oGgIwc20RPQDxZ3BvDOAshdMDmOWSfw1OJf\ncw+y6iSdzJ7GfHfkyBHxMOPaYAityNaJNYu50q1bN3kmH2SUg6XWg9HC4vZHogcqqZiE9QizsLCw\nsLCwsLCwsLCwsLjLYYyIFhYWNxeERnzooYckXOLSpUtVmTJlVOLEicWQfyvCll69elX+tbnB7mwU\nDDIntdMbMF++fPIvcnnlyhXv352pPkx0E/4lDCKfYNeWgjZPtoWFRSzCEmEWFhYWFhYWFhYWFhYW\nFnc5bOgzC4tbB7yuihYtKnmb1q5dK+HSCad+K2DIN0uM390w6wG54iC9IEj5Fw8sJ0GLBxaykihR\nIq/XICSY+d54Z4HYkinqajzAzDOcBJ2FhYUFsESYhYWFhYWFhYWFhYWFhcVdDEuAWVjEDRASLm3a\ntGrXrl0SLhFvsZuNf//914fAiG0SwyJuwawHkF3IwsWLF73eX/4AUQYgyADygkejmxiLTVlyhpk2\nBJiVVwsLCzcsEWYRPI4sVhaxiCzVlIWFhYUXVufGLqzOtbCwsLCw8MKd18XCwuLWAe+wYsWKqVOn\nTt2y0IgQGMAQYpZYuDtgPIMhtc6ePRsuARYIyOzly5eFRCO3nCHE+BjPLWDlycLC4mYjvrKwsLCw\nsLCwsLCwsLCwsLirYY2SFhZxA4Z0SpUqlZc0uFmABIME4bkQF5YEu3tgSLB//vlH/fXXX1Eiwdzl\nQYhRHqQYH2QLD7LYDsVrvZwtLCz8wXqEWVhYWFhYWFhYWFhYWFjc5bA5wiws4g4gnggph0fNpUuX\n1M3ChQsXvOHszMcSYXc+jP4/f/68yEBMAuILQgzPMJ7Bv8DkEYsJOD2arbxaWFgEgvUIu4vw22+/\nS9JV3JvvRLCw7tu3Tx0/flxFBZxO+eGHH9SZs2dUXMfpM2fU+vXr1W+//64s7nwcP35CbdiwQTal\ncQ03W68wz7dt26YWL16iNm/eov7++7SKi/jzzz+lX0799Ze6U7F//3517FjUdFB09bXF7QX0A/Ph\nWAyO92+//aaWr1ihVujPgQM/qdsJe/b8qLZs2SL7jrgC6sIY/XzwoLKwsLi7YY2HFhZxBxAFkAY3\nyyvMEBaQEyaUnSHDjGeYxZ0HQ4JBgMU0CWZg8o3xMV6HfMcnugcwnMSXM1eYhYWFhRuWCLuLgNGl\n2Sst1MaNG9WdiHPnzqkJEyeqRYsWeb/75cgvauSokerIkSMR3n/6zGn10YgRasf3O1Rcx7bvtqkW\nLVupNWvWKIs7H2vWfKNat3lV7dXEQVzDzdQrp0+fVt26va2aNG2mXn/jDf1vU/38zSou4ttvv5V+\n2bp1q7pTMWbsWLV4yVLv74cOHdL6dpQ6+tvRCO/9448/1CejR6v1up8sIgaHHjp06KSWLftS3Y44\n/MsvMh+WLl2qYgLr1q9XtWrXUa1bt1Gt9OfNzp3V7YRJkyepN9q1jzVDQ1Tw199/yxhNnTJVWVhY\n3N2wBkQLi1sPY9g3HjN4hcU2ICTISQbxZj6GCLME2J0Lo/Mhpi5evKhiG4Rb5GNCJMZEDjznumXX\nMAsLi/BgibC7CB4PJzAuy4Jzp+La1avqiqN9B38+qLZt265+0Ua4iOC54ZGTKSzGUcG+/fvkhPrN\nwPXr19Tly/9Gua63O9av/zZWPQAOHjwohtabDYzdK1Z8HeZ7xvnfy5fVjRge733794unWTDAG22J\nNmIzR5y4mXpl1apVQnRXqlhRLV60UI0Y8ZEqU6aMiouQMfs35scsLsGc5DM48usRrW+/03PzQIT3\n8sLD/VHpnxta5vbs2aNOnDih7hYQo3/J0sVqwcKFkbqPE5dffDErzLyNLQR6Hi+kzIerV6JfD57R\nr19/mWPTp01Vc2bPVj16dFe3E8xp67gEz40QXX6zZMXCwiLuwhq8LSziBowHlsnVxSc2wcFiAAGW\nOHFiLxHG86032J0N3s3+/vvvGCGlgnkW+2AnGWZyhkUXhkB2hkm0sLCwcMLmCLO4o1GseDGVNm1a\n9cgjj6jYBAv5hAkT1TNPP60yZcqkLGIPbJzatW+vWrZsocc1l4oNDBk6TIyBZZ58Ut1MTJkyRa1Z\ns1Y9++wz6mbg4xEfq8vaqFyqVKkIryUc4Ttvv6OKFyum0qVLp24Fdu7cpZIkTaoaNW6k8ubNKx+L\nuIMSxUuoNGnSqOzZsqnYxD8X/1Gfz5ghJOgDDzyg7gbk07I+ftw4lTHjQ5G6b9OmTarTm2+qihWf\nVffdd5+KbdyM5x07dkxCstarV0eVLFlSWVhYWFhYWFjcqTAeYRBSkFMmlFxMg0OP5CFLqt+18D7j\nWXycHmGWWLjzYMgnxv5mHbJGprG1cLjNkKx8YoK8cpZhyTALCwt/sETYLQYn2lkAHn74YfEm2v3D\nD3Ly5vH8j6sMGdLLNYQD+/7779XVa9fUI7lyqWx+jIwoeXJv4Pl07uxZKS937txBnxritPmeH39U\n169dV48+mls9+OCDKliwaB4/cVz9/dff6t57U6mHNBGUPFly79+vXbuq2/mH5MxJnCSxypw5s7o3\n1b0+Zfzxxwm94UoqhjOuO3r0qGy4IJUgsvyBnCO//vqrtJEy/SFhgoTq/vvv9/MXjzp16i95Top7\nUqiHMz+swsMZ/azj2vj2zz+XNAmQVmV8KKOULSXpvt/63VYZp79P/+31CuO5yZIl85ZB6MVffz2q\n70sg9U2VKpUKBmx0f9fPJh8P9zyWJ0+413OS68cf90r/MJZZsmQJ83fCkvE9p3AgOC5qwzKkUo4c\nOWSzALG3c+dO6aNMmTOpvI895leW2Cz98ssR9dNPB1Tq1Kn18x7VMuA7tsgH/cxYItu7du3S8nJC\nPZAhg3pMl5s8eXKf6+nPn376Scq9ceO6GLrz6DazIedvCxctEhk5fuy45BgCDz2USaVIkVz6N1my\npHruZBBjKTnfkCMM5mzkASedDh0+rP7SbWMs8+XL5/0bYB6Qfy1Pnke95adPn14M/Aa8KPyorzur\n+zK3JlmZb+5N1j///CPX0NfJk6fQ8zar9HmgzRhhKBYtWiz9bJ6bMmVK3TZfwzehtCCEzp8/J8/N\npXWCSTbrBHX86eef1YnjJ6Sd9HWKFCm8f6cPvl65Uuua/N7n0Uba6q8siAd0EGODvkC2eX7Yuu1U\n5/T1D2sZh4D2VzfGkXny4969ItP59Rjcc889KjzQnz/r9lDe3/r51JlxRu4MnHosf/58YXQHf0f+\n0aHoXurK3v+xx/J428I83rFjp+jl7NmzyZxwJ/Cl/r///rs6ovUP8yxb1qwi+8FutLmH+l+4cFGe\njYwHey/ziWcjx+hLdIlTz1y58q/klCPMWWLdV5kf9tW31P3kyZMi8/fpuXry1EmZn4n075m0rKVO\nncbvc89fOC/6ljmfVctxKpcOBzQBvRdGV+hnknvx6NHfwtXXBowTc/zS5Usq7f1p5XrTP+hDvMHo\ng9NG38YLkV3vukOSZ11fnndN1/dh3Qf33Rs8KYMcM3eO6WekS5de9KhTX9OHyA+eb/zMWuseQ/rp\nsJ5j1AsZZd7wYU5D4Ppbl8iXhqcr8w2yOXfuR7xkEqcleYZ7nqDD0amssffck0Jk2+gj9PiUqdPk\nuv26rvfqNvCS6TwYQj0JHXxA14358qhui/MZ9Dfjjowx3/CWRXbRafSLs93BPM/UmTCa9GnGjBn9\n9gN9QDswxjhBf5PDCs8lfqYuzE/0oAFzmLFhDrCXeSx0/XCDtiNHjPV13b88j7o6c3DQJsYNb91c\nOXNqnZDdb44OZBJ5ix8/nujsyOy/kKW9WhfeuOFROXPm8LuegD/1vD2s+42572+PZ3QD84U6fr9j\nhzqp5xFtMv0TImMHpH/TahljvP0RlvQtbfpV64b0XKf1WyAdzXyl/levXgsjE6Z96FPqRbidbdu3\nq0tan5ctW9ZnTbKwsIgbsLlVLCziFpweYexd2MPHpFc58/3MmTOyVrNfMh9DghmPMEso3Llgv8+7\n9s0EMoXMGaI1psgwk+vM7NctGWZhYeGGJcJuMQYOGqS2b/9e1axZQ3388UjvAsTGo1evntq+F0/1\n69dPXXDE6m3y8suqb993vb9jxHz99TfEuOBEwYIF1ORJk3wMxW5gkBo+fLga/ekY+RmwaHTq2FGX\n2TbcRYON2OpvVqu5c+Zqg+V/m7HM2kDT9a23hOBY/+16NUf/nc2VAW2rVauWevaZp3X5IQvUoCFD\nVBZ9H0Z4Zw4UFsbnKldWNWrU8NaF53711Vdq3oL56trVa94yy5UrJwZRJyB5PpswQb326quqaNGi\n8h0LLt+R28hZp+ov/C9MGzHajP70U01o7BEjlUGOHNlVm9ZtxJhJqLb5CxbIIvvll1/JB7yqn1lM\nP5PTLlOnTZMk9Ab0cfXqL6hqVauF28f0W89evdS8efO932E8bFC/vhjc3Fi4cKFq36GjT2ijqlWq\nqIEDB4gBFqz4+mvV/Z3uqnPnzmr06NFCSgHqQblVq1VVXbt2E7kyeOKJkmr0J5/4kEG/aONpu3bt\nRH4N2MR06tRRvdqmjZc8wEhbr34D1aXLW7p+i4ScMoAcGz58mHgZAQx8nTq9qVauWi0h9wyo+5zZ\ns9T0zz9XEydOku/Gf/aZfMAno0Zpo1oZ1Ub3OcbKQoUKqvf79ZexRqbWaDnl5z593lXz589X/4bK\nOsCwOXbsGCGZCen1VpcuImPffrtBPVuxklxD3du+9pr8vGTJEtX5rS5iSDRj+dxzlVV/PU/NXFus\nr+nZs5cQDk5UKF9ejR8/LoyBFPKmQYOGYsAF5rkVKpRXkyZOVKEDpDZs3Khat3lNGx5Pee9FxkaN\nGun1jGHsP/jwQ8nz8o82jBpAho0aOUqVLFlCffPNN6p5i5bSJxs3bfI+78XGjbW+ed+nbrShUuXn\nvG1hLMHjjz+uZn0x03sdpFb3Hj103f72fgeBOXr0Jz4eQpBA7dq112O8yvsdBvh+778v/egPjFmX\nLl297SFHGOjVs4dq3ry5Xz2G/HXs0MFHjyE7EHrog/f1eNF+kEiPR8tWLYXUfEfPjfOheXu473//\ne17G1swfyI03O7+lvtv6nYToMyhRooSaNnVKuPH7ITOmTp2q+n/woVfXIwuNGzfS7eui7gnHKMwL\nyurVq9WsWbN85BcdNGjgQPmZMJfTpk/3eZGBOKxTu7Z69tln5ffLmlwapedLSq1HMmuS+6uvlntP\nlVIXdFI1rQPM/A3Ra1+qL/RznahS5bkwcvz99zvUuPHjVYsWLdQToZ46V3Qfz547V8JamlOG6Ntn\nngnr9XhOk7sTPpugdmiC0gmM/m926iRG88lTJovXJKDufBgn88yrV6+oRYsXq2W6zmZ9YHyf1+P4\nXOXnwiUnaOukyZPV++/38zEwZM2aRX29YoWMLfN+wIAB+rqpXh3F81/Q60dvrasNwcVcZq4w5y9r\n0mbBgkXe6ynn3T59VMOGDbzPGDRosORXc4aapK7MiwYN6gsBVbdePb1uVFfv9e0rf0cfMC/coX8r\n6rFG59etV18OUIDateuE9n0idVATPwCCq4NeL7Y48tgxF7kX72bAGkh+wrRp71eP6vk8buw4n3Fs\n27ater3ta1Lvas//L9znGdA3DRs1lkMTy5Yu8SG7eN4rzVuIvkG/ZNUkswFy3fjFF9V3322Xvhwz\nZqx8kidPpvaHkvnkDPtS7w+cJ1rR8axfHG4w4CDA22+/I7n8nBg6ZLCue235mQMR5B77/fdj3r+X\nKFFcjfz4YyEFAfVs2aq1rtN3PuVQ78+nTwvXQxy5Ic/e+PGfeXUReL5aNS1jH3qJJ/qkhdbX7nC9\n7PE+Hf2pJhNDDi6x1qIbhwwerHXhaO/a/NZbnaU+AwYM1PPzMzmcZMAYvv/+e6q+li1vP2s9i6xt\n2vRf/kXkgjo965i3jPmnY8boPhvq1Un+9NngwUPUrt27Vfv27VT37j2E5AZbNm+yRJiFhYWFhUUQ\nMEZ91m32qzcknHHI3iE6Rn7KMHYa9qfGG8wQYbxH2LCIdzaQJ96fb3ZobN41eSbPNmSYIcSiA7ec\nWrm1sLBwwxJhcQB4OYwa9YkY+p58srQmCvYI+cEHIuxFbVTAMMMp9be1kXaiJreef76aKl68uNyP\ngRajTPfu72jC4gnxApg0abKQL3PnzlOvvNIs4LM/0UTIiI9HqSraAN28+SuyCI3UxnIIOoykEFCB\nsHHTRjVt2nR5dqNGjcSDDc+lBPETeL18OBGOR0UJXVc8iziNjIEew3aRwoV9TsWTy4u2vKyJvpz6\nHk70f66Jj+XaAMkJek4/y3Xbt6lZs2eLcatWrZpiLMJjDmMtebOyZVfhYq42ykKC5c+fX4yXCRIk\nVJu1QeaLWbPDXEt/cFr6+WrPa6NTQbl2xdcr1Lp169RXy5erhg0aqLLlykp7Z8ycKUYiE2bu/rQh\nbfviiy+EBHvqqXLqqXJPqavaCMV3jA0EQd68+fzWk00J4wAJRqi8NppcSqI3pNyHsdntuk6dMNBD\nULz9djeVQtcJo/gU3d+QZxixDCBW+773nqpTp7aQXxja3n23r5AEn8+YKaTSgA8/kLYjmxiWIRE6\nduwg93N9K238Q3a7v/OOerLMk3IqHGMuxrb4muB87bVXvc+jrv37fyCE2lRtyIacWrp0mZCM5Hrh\nO8aR8V695htN0nXSMvmcGNrwzjnw0wE5TQ75mOfRPKpL166qWdOmqn79EOMdxkZzenXNmjViCK3+\nwguqatWqKmGihGJs4+94/zXR90HC3q8Neyu/Xqk+1EbtIZqIHfHRR2Kcpy5tXm2rxyWPJlp6SpnG\n6ImxE6MwXlTvvPO2yCvjPnnyFJUqZUgfnz9/QX2giQ76f4Am6nLlyineXtQrc+aH/RrikQOMvhiu\nGasx2ogJDPkCMAITyhBdUK9eXfGgnDNnthg2R2kjL4Z1wAsL3i+1atcSEhSCDBJiwMBB+jNQ2ldE\nk2fz581Vz1WpKsSYuddJdBpA7k3XuuSDDz5QW3X7qRvX4SHi9ESCyG+s9UBNPSeT6Zeo6dM/F+Jy\noJYHyE7jddfm1ddEVt94/XUZH8jPzpo455MtW4hnlRuQ3PPnz1O9evdWP/30sxjqH8qY0Uv++dNj\nfbQ8+9NjeOj1121B35bRcnv0t99U7959RM556aN/69atIwTOIG3Ahbzl+XVCjePorNSp71Ndu3VR\nT5YuLZ5UQ4cOFXlmrvH8QFis51EPTZCiD5lLyZIlF0MycwsPIPokENZrgz3zE4P0C//7n0qv9S3e\nUM6XhXu0vBQsUEAV0+Wjj/GaRAfgRVmgwON63mXwXgshDdndWJOf6Fs8w2bO/ELP9UUqb77H9Hc5\n5br9+/cJCcacZXwZezxK+C6Y06gQniu0DscjBfLf6OvFi5eEySuXInkKCX1ZTxvhkQPWMvQs+pN6\nNdRkMbo4W9Zssg5WqlRRlS5VWs4/pAldSyDG8KwsUqSIqlyxooqn+2fhooWiN9OmTecl6Pxhzpw5\nqkePnkK8cRgkS5aHxbMJeUI2qC8EO3qKsHzUE++z6Z/PUHP1vYRsHPXJKNHTBugHPEGHDx8qxPCB\n/Qf0Wt1dy0FPIbqRYQ6xDNf6h3FFz+PV+vPPB+UgSbFiRf3Wlf1A377viS6eOOEzlTNnTvHgpa8e\n1MQIunu0rst7770vYzBLrzl4bMePH0JwQugxF/F26q51WZkyZcUz7F1NsvXq1Vu8qJzeWpCPeP30\n799PFSpUSB3R5BtljxgxQtaLwvq78J7nBDIMWTdb9xlE1NOhpBv4Yc8eqRO62O3NjHFmgCb58eTs\npkmslzQpxh7A6bGJXmfPg25JqWWN9XOEJq4GDR4koSUBBp/XdNsZ20YNG2rit5ocotmqCcGyZcvJ\nNRB66Hrk9ZNRI/U+JqcmV5fpuT5MyMPp00M839CrrAsQlugTvKvJk/ebJs/c3rxusC6wH+rQob0q\nV7aseJwP07qS9bZgoYKqpSZ3AetXylQpRWewh4D4Q2ewxxszdowQsAbIw9t6TeaeDz7oL565eAnS\ntgkTJsiep4XWUcn0+gRBuWr1N6qU3jc6MVvvr5h/n302XsaAnJyQ7ejJonpeeQ986Hqy1nGAgboy\n1hB7/vQZpGv79h3kkMq77/aRsbxbwppaWNxOMHtpazi0sIhbMGEJ2fMYMgxAZLE/NWRVsOA+9oIQ\nEbw7mpxgbiIsJogJi7gL4z11xXHI8mYDGeTD+5YJ+xkTxKv1BLOwsAgES4TFEWC4adGiufyMsYxw\nPxgUKlWqJEYzY0Tu2rWLnAz+bts2LxGGwevTUMO5AQYTjFGcwg0EDMJ4Jzz+eH4fj6FBgwaq1d98\now16owMSYRhb8MrCSNRRG3GMgTVnTt+cTfnzPy4fgwcfeFAd0waiOZqM+vPkn2HCQzVt2kQVKljI\n+zueY8OGDVe/Hv1ViDA2bYRzwwD/4ouNVdYsWeU6QhsSlgdvnfAAmYDREUNcuzfe8BrQCPXFKfXN\nm7f4XM8m8JVmvkQixlyMZBgCWaghHTASx4sfT4zEzrBfZ86c1mP1nYTfe/mll73fc4r+zTc767as\nCkiEHTx4SLzjMEhxwtuEL6IsDIHIgAEL/QhNkiAnUyZP8o7l+5rsIoweBnS8mpz9jeHyg/79vZvb\njtrw26JlS21kzqKNXgO8RipOk2OsxOOHjTabFMYPGe3Ro7tq/sp/hv+SJUqo0k+WUR+PHCmnwp1h\nEumXTzVhYdqBYRzPD4yrnBBHliBSU9+XWkgH83xDgAKuyZotq/yMsTePI0ykSe57Whs5W7dqpbp1\n6+qz+eHnPppIcYKQdvTN4cO/SFipNGlSh4YaTCCEVB5XGMqBmuijjzltnzn0pD9EL8ZtyLc2bVrL\nfbxYlH/qKW3grSDPxZiIYT4QkGfaycsHpGqeAOEvn9bG4Q81QWnahaF+y9ZtMsYmnAXAC8oJSONv\nNBG3Z8+PYkBHXk2/EjYvTzjhNhlvQrQxlgkTJpAwW/5yhOGZ1qdPb28oRDxaN23eLOOLcZh+43dI\nsEaNGmqy803vvXi4Nm3aTBMMM6QMNzC88qGulI/XnzGSB9JjePmVLPmEXz2GzLZu3Up+hmSHMOLg\nQWlNYvfVRlpDVnZ+s5N4ruzWetQQYYzvOK2bnUCuIMJ+2PODCgTkc/SnY8U4DlmSPrQP39Nth1iC\noMcrw19oSginZcuWiXzg5WauyZE9h891ELR8DNC3zKlFCxdK6DwnEZZAz3vmaNEiIUQL8/OSNsTj\nLXvklyNeImzFiq/lX55rCGFj4J88ZYoKD4TpxYvl/vvTCEGYPl1IvdHXHIpw61v0MXPXCbwUyTtF\n2FOADksX2n5kwqlvT2kyfo0mgpB3iHJzIAOyD9JotV4TC2tDPCSyG+hySA3m0Ly5c7x97Jy3jNPs\n2XNU4cKFRXea9QNi6F89RuiAbzVpAMFlgNyP/HiEJiILyO+EovvlyC9aVgfJoRf0HOHsQI0a1bU8\nPiY/0wbybAUC8/ii/hBKr3z58qLHQ/RMYe81kGP3pQ7Rt4Ssc4bAwxMUMvRNLeOtQvucMJ2JEieS\nubhk6VJNmDT/b2z03O+rSTIOKJh2QPrjMbV71y452BLe85yg3+poshndu0ATzU4iDDnnZRgveffL\nK23kGefOnZcyIOrcuuv99/r6/I5OXrN2neg+s34tWbJUCDdksmePHt7nQGwbjB07TvYL48aNlXUN\n4FHG2i9zXfcdazH6B50EeW70rxnDYNBJE/LNmjX1/g6pVat2HbXd5eHP2umE2ePt3uW7x2MvYPYB\nzjDalIfXVp3atby5FTmAYTxFnaAd06dN9ep5iPIDB/arBfMXqEOHDmsZS+3VZxDvkGQmdGggfYa8\nol8hI60XmIVF3AX6MDZyD1lYWEQfzhCJJvQbH94TIDI4eMo15j3GefgS2w1rN2sw+yH2WtzLXpnr\nnESY+dl46NjcYHc2kCVnZIKbCZMrDNnlE9PrjzNEooWFhYWB1QpxACaHkRMmHFBZR24jgHEMkN/I\nHyQf02+/Sb4wDBOnHCHU3OA09JkzZyV30MlTpyRUkORO+vtvMTBxKtt9Yt/g4j8XJQcTBhWncTUg\n9CJ04cJ59ceffyiPCjnBxOl5J+iHggUK+nxHfhhw9mwIycFG74/jJ7QhNqPK8rDvaXEMMnj/hAdO\nYNNHhOJz5/0pXqx4uPeyweT+c7ouEALkS3KGGPIHQipBAkCWnPjjhPeDgQ3SDANooAX/2LHfJewS\nJ+edBkUW8ypVq/hci1fNwUOHhMRxjuVhTdaR+wtgwHKCE/fOjcGDDz4gm2HCXzlPavNzkqTJJKSd\nOS20e/cPUm/CfjmBrNbUpANGL5N3ygCvAWc72HTn0kZcSKMLoaHoShQvIaf1IeTwbAgkf+GBfn35\n5ZfC3bBTLnlLCO943333imxejeBZbM42ayKHPmbDZvr4hDaE4n1jcqFB1mGAXLh4kXpHk9jusGVR\nBe2pXKmiT7sg0DJlekjmo7+43rQTXUA98ViDmIitsAcYs535wJAF9BXkBHmrAKH7AMSB6T8+vJQh\nD+ikyCKQHuNlz58eo8/KlPXVt9lzhOhVyArnSyOEC2TLidDwoW7w0sAcNmEyjZ7yBwjavXt/FGIb\neffWU9+Lhxn9hFelP4jeOX9O9C0hLiMCm/5z586KkZ72kCfroks+8JxxE2l4mRHK7u/QEJ2SP+rX\nX0XmDQlmULx4sQjrQZuZzxyQMCSYQeFChcN9MblyFX17UnQg5ObFixdURCAfEn1ITjD6y+hb2pE0\naRJZD//91/+JR8YYcq5ypUp+yUiwT5Mg5KZCxznXDyF26tQOyde1e5fPPZBL6H8njNcjzwN42UA+\ndOnaTTzILjpCIQcChzlyaVKa8HWQuHhzRSanC+Quc4G6+ZuLB1xzMXOmzD6HVECWrFnEYGLaERnk\n0X1QtGgRIcaPHQu5n7Fbq0kryD2ItehA5qbeo5DbK7luJzJwKTS06o4d30s78Rr2t06wtm3avEl0\nK33k7B9zAML0D95U6NSmzV4Rz7DIjAHyj7e3E5DMPPOs1mn+gIzRpvD2eC/odrlzyebW/c3aSOjk\nGZqADC8PBF6TzsMOJs8bRJrRUUafZcueTXRXMPqMwweWBLOwsLCwsIgaDBFmyDBDWPH+zoc9mcm7\nxJ6HPTg2Aj78jHc4h2n5O9ezJrPnMPfzceYGsyTY3QHjFXYrYPLe8a5uQn7GVF2M3NqclxYWFm5Y\nj7A4gJQp7/GepjUwRrb06X09LxI68rYY4E0zdtw4CTVFqCwnMjwQmKTCeMVGiDBPfPwBY7K/cGmn\n9YaKnFn+PEOc4PQ0oQR//HGv1wgVCDwnTEzf+L4L2KXLl8TQkjdfvjDXYuxKljRZuM9gE4iB1Z+h\n018uNepMTq1NmzaKR4Wz392GJn/AoMzCvmDBAvmEfeZ9Qu4ZzwUnjPGdkJJu3J/mfm9+NYAM4JGA\nIa5cuaeUP7jzVaVO49teOfWlN88PusIVhbim+8oceZLwEPJn1DL9cuTIr5I3ySBDhrBhkBLqDbxs\nekLLJjcRZNKw4cNVo8YvSll4DxECyxmGLzyQl+TBBx8M8z1jOWPmF2qmNjQjl05yBMN5RCCXGhu1\nPXv2+O3j+LqTIJF5gSDPDLl7CJWHlxOeBq1atVSl9b9RfZngpSSta75JiAxCjzk2sBhlCYXHs/HU\nuOIgvhIljD2V70/XJEqUMHRzHfK78XzBG9Ifjh8/piKLyOox+tE9141edXowAmfSXgPm0Titbxcu\nWixEtzOXXUT1ZHO/cuVK+biRIEF8L6HmBkbnq1euir51zns3MM4vWLhQQpY6Q1z4kznCVzpzM4EQ\nYiqet02Ep4Xsh3Rxg7nvPkzgBoQf886fvk11byof4hRgnMfLhTCibiM6pERE+Pv03zJW33yzRj5u\nmFj0/mByIj4UznPQe9TZTQoC+gjC7let95xInTpNmHaaeWgOQUDYTpwwQXJ9du78luQowxu6tdYZ\ngcLH8eLYv9/70qbJk6fKfC9Xrqxq07q1KqmJjIj0DAdZTIhbv393kVvo1XvuSRGmHTzn+o3Iv2Cy\n5tWoXkMOC6xatVK89nbs2KEOHTokhIm/fUdEQKeT4+0LrechLZ2HTEw/Ih94ADPXA+VPRY8jt3/+\neVKvSc/7vcb0T8uWLWRfQYjTmuvXi9cY3oiMX8II9C17P/ccDJlT8Xx0DuNEOGTCe9I/TmTPHnYf\nQq5Df98hL4T+JMclMlanTh1Zl9zynMGPzBmZNfUy+ozQk84cpv+1w1efoVuC2TNZWFjEDVjDoYVF\n3IUJkQhYX/mZPQd73GtyUDfkw3urITl4jybSEDln8RLnUBZe9obwMsQa/zpzglkS7O5AVA4fxwSQ\nMxMO0chrTIRGdEcFsrCwsHDCEmFxAOSdShjAoBg/AkMjC0Wt2rXFYEOOhqfKP6XSpU2nF5Jrqtkr\nzcO91xg2mjdvrmrWqO73Grdh2Fvn0Huvh7Nobt6yWXKVQUo0aFBf8rqkuOcetWXzZjn17kZil7HQ\n73PjJ/CeHHHjRhBxgNngkXftmp/73cCQPPyj4ergzwelX19+uYlKfd99slEYOWqkCgZmXAmr9pif\ncEmJEiaSfDD+kDhxSJila34Mt3jVxfO5NjGrvBAu5AfzB2e+FUgbE8bJjfgJInYURXaol78XZUN4\nug18zrw5gcBGvG3b1yTs5cqVqyTkHTnEpk+frmZoksMfwRWmjIRhY5lTp67d3lZLly5V//vf/yTc\nI7lTIKCbNGmqzp47G2G5xjOzWLFiqk/vXmH+bkIgAgx+M2fOEG8a8q1AhkHsQeoRrjIqGzJIyoj6\nEH1A/ivmHfnqXvt0tMy7VKlSSk6iFctXqNhCMONr+nD4sKHiZeSGP0I4IkRWjyEbiQLoGkO8BwLk\ndJOmzSTfDeFs8diF5KFdxUuUDL+eiULaXqVKFdXWkT/P+2yH/Lhh9MjVcOK381JLSFI8fFrotcB4\neG7d+p14gLgRTC4B9BNGedYTN5j6EclxQkOU+NG3btXBgYCPRnwknqtVqjyn8uXLLzkmkyRNonp0\n76GCQcIEIbLAiz6579ygLoTX9Acjm9euXgu/fF3xq1fDjsOVKyFhPdx6NXFokvGIQH7QDRvWq40b\nN6pZs+dIHkkOTwwcMEA988zTfu9B9sjZBzkyb/58yVVWr34D9fJLL6neWkeFR1TSXog7wuA6w0sa\nuOciejUi4jOyeLbis0Igcdikbt26avacuUKAVa5UWUUFbdu+rpZ++aWqVbOmerfvuyqD7h8OW3Ro\n31HCURokTpI44Polf08UIvcYifq9/16YtQyYtYixJWQ1uU1XrFguOTZZawihOXr0J2HCPzuRMGHE\nsoFOr1uvnvrxx32qycsvSR7KDOkzCFnNHu/GjbBzK0kS/7oY3YMnOF6E06ZPU5P1+jpTyxm53ZxR\nCYLR5Uaf1a9XV72k5c0Ntz5LEHp63cLCIm7D5FSxhkMLi7gL9xxlL8EelH2aCTEXyMOGXOJ4eeMZ\ntn79elW2bFmJZmK8v8zePa7rAMKCf/PNN/JzoP0cUVn6hObB7tWrlzfiUjBo2rSpmjhxYrjl3wkw\nMnIrYYgwp7yaT2Tl0IyVc8xsrjALCws37FvpbQ4Msr/8ckQbIl5UnTp19H6PwfbUqb9UxocyBrwX\nIwUGnr9OnZJcF5FZIMiLRQgtTtFjiCFJuhs7duwMIeq0UYqwZQbnL0Qc4ioQMGARyo72meSuBnh9\n/HPpn3DvJzQfOVB+++1omL8RttEJwpERVo0NY8MGDbyeGCdOHJd8ZE57p+k790Yibbq0YnD8RxMx\nJp9ZsMiY8UF5Jifb3eA0/w2HJwonujnpRWg4wqfFdixkQt6t//ZbGX+3xwK5U0C27FE//Q1xQY6Y\nqtWqqqFDhkqep+UrVoiB1+vmHolNG/KydctW9ViePKqXJoQghgAEGSEfnazif+X7bnrTpU2rXxRS\nSrg58msljsBYSDnknnuzUyfVuFEjPUdfVl99tVy91blzwNw50c3NgGfChm83qIcfflhyCxovGl6I\nIMvdzwI3gvRoUjGwf4SUA4Sny+/IZRUdREePRRbI9s+aGG9Qv65q366dlxhwe2n4A0b55MlTyBgF\nIz9OQA5wPaHezIuuG+QiZKMPQfeAw/tS5DuKgAxJljyZhK7D8O70RqPciE4PQrRwP57K7pcQPL6c\n3lno1aNHf5MxrP7Cf4QmBBlrBh5kBqYY94spHnP0DWtBZPUtc4b67flxT8AXJvQeIVT37z+gqlat\n6vM3ZACPNhNmMypAh1eoUEGVK1dOcnC279BBk0OzAxJhznp16thR1qmmzZqpL2bNkgMFrAuB1iZC\nC4fkzEoUY3MRBHqeP6BTK1WsKPUlJOKuXbtUgccLiFdVZPHPP5fUV8u/Uo9q4w7knpkjyAIeXs76\nZc+eQxOOm+Sggj/ymQMSEFh4f2bKlCmoAxgQzxBChCV8v19/OQBBTsSqVaqo6IA93q5duyXvHHkX\nDcweL02a+yJVHnqEMMVlyjwpOUjfaNdeTZ02XZUqVSpS5Rh9dknPz5iUHwsLi1sLY1C3HmEWFnEf\n5n3fEFfGO4w9GOu9IRj4m5nT/ExUBw7G8B6/ZcsWIYiw1Zi9051CGgwfPtxLZtFGyLBbBWeqhMgQ\ncncD/JFgICpyaAkvCwuLYGBzhN3mMOGv8B4yhieMWyShP3PmdLj3YozFewCCgRM1zhMUFy5eVKdP\nB76fDRSnichLtf37772nkjlNTw4VgJETsgLiyZQLgfP999tVVIGhMGu2bEJG7PnxR+/3hODarDdy\n4Z3mB4SvSq+NpVs0KUI4QQOMrWvWrPW59vqN6+K1wMnn69dveK/bvv17bcQ9FaZeeKsdO37M5+WR\nvCoYjOhfNpveMGr6Gsq6EA4pSLgCQvYt+/JLCWNggAGMMJhOcJLrKW08JeTfwoULfQzMhI37w9HW\nmEClypXEgDr988+lHSFN8qg9e35Ui5cskbo/4sfjJyIQftKZrJWT+fny5ZXNvNnW3BsaRpTwVsG+\nqONZeVnLJf2SPHlIiEVCBmJ8/cNFEGH8h9j9/Zhv/jY2VlWrVhHD5GcTJvjUk3KRSVMfjPzOumFY\nzaNJOHLLhWcghgAkN1wwOYL8gTpSL/SC8ehAH+Bdh/HeCU78EeqM3EIR5Q2jXNoAgeU0KkcWzzz7\njHjMjPpklPSjU+dgsI4KaRMdPRZZ4EmKNxDyZF4+kf+JEydFeC9h2EqXLiXh3+bOm+eVn2DajlGe\n3EGEPtypyQLTRmTJ5PoxpJTn+n/yRf46XnCjCsY9vyamILK+37HT+1yehRdPREDfPqDJmJ90vZ05\np9B7mzZt8pkLhNplHXG+rPOc5SuWh5nnRrb/+ONPn9CUGTVhQT99r9ckTro6ZYF++uefwPMKspHc\ndd9qIvmbNWu8dePfs+dCcr8VLlxIPZQxo3hfmdCNlE2uQcgcwsq682gFA/oDOTX1xRDBgYakSZOJ\nB7M/ID+sYc4+RE7Ix3Zd5DRkTkNGAucaAooWKyr3jv9svJeoNO0hl0RUjaCBnucPzKHq1V9Qly9d\nktB/7A+qVqsS0Fs5POC1yDqdOEkSn7FbunSZOnTwZ59ry5d/SvYmoz8Z7Q3fR3vPn78gMocM4j3F\nYZiRo0b55NNy63rIMuffja6XkEQxEGYmOns8JxhTZ6hC2pj70dx6zUkVpdPARp99/fVKCWcaE7rc\nwsLi1sMSYBYWtx+cJBiHhE3uMD4cFjT/8jE5wPjw/oRnFXvK5cuXy37mTiISyP1sECjqxs3CU089\nJRFjyrvyq8cVxPYh6kAw7ytOD7DoyqAlwywsLCKC9Qi7zcGiTn4RwihhEEyrDWHfbduuNm/eHGH+\nLsiTrl3eUm1ff0O1bvOqnEIn3wQGDAgNNkfkOvIHiJ/nKj+nPh3zqZowYaL67rtt6n5tSPzr779k\nIW3apIl6PH9+tW3bNv33CapkiZKyudqhjZMsePGjmidJk1IVn31WHdCEz7jx41SJ4sXVPSnuEUMk\nxrwIQ33pjWG5suXUtOnT1cCBA8UYSPivvXv3Sj4vJyAlCJ+3S9d56rRp0rc8BwN+woS+odXwiiLf\nBwRb0iRJ1b333asey/OYnPipVLmymjx5svrgww9VgYIFVNo094thlXxJefM+JnlS/AHDLDli3n6n\nu6rfoKHkz0qiyyYE2slTJ8PkCmrXrp14hXTo2FEt0kRZrpw5xLAH0fHr0V/VWm3cjSmULlVK1apV\nU/JtQV4VL15MnTp5Si1ZulTCy73drWuUjJmERuP0O+Vh0D5x/ISEM8QLsGjRonINfYqBff6CBSpl\nqpRCbBYtWkzlypUzYLkY48mRslEb31u2bK2vLyIns9atX68Nl/f4XMu8YFxWr/5G9ezVS8vAw3ou\nZFdPP/20eqvzm5IvbvDgIZKPDU8M5BovoVN6TJZqEhAjYM2atbSR8VE5XUdund0//KANhl9L+Clj\nKPaHYrqNP2qClxBfpbSRkTxO5M4JFsgsm36IljavtlFly5QVef165UpNXifXBmdfj8mSJZ+QenV+\n6y2VTxveyUFW/YUX/NetWHE1deo01fnNzuINg8EXGYgMsusXADxVPv54pKpZq7Z+KSinxy+9Ovrb\nUfEGadWypWrYsGGkygykx/7+62/xpgxPj0UWkELo1VlfzBLDMbK3c+cuOQwQ3rgC+v+N19uKriFP\nD/2Oh9zFixfUIU3qQvp+pkkJf+HD+K5G9erq41Ej1dixY2WMmQMQIYRLZO5DnKCHJ2pd8/jj+WXu\nb9MyGlG4x4jwdIWn1bp16+W55PxLow3geNIgp0kDhHU14CX7f8//T0I2jhj5sY++JseQcx1Ah6bR\nunH37t0SyhEPMMiUvT/uFWO9E4Q3TJ8hvaxzSbWeSallMZcm3wm3Wa9uXTXi44+FwMBThXIhln/X\n68MDDz4g+Zv85VnjpYmwsk2bNlOtW7eRk7KZM2dSR7Se4H50OJ5BzCvCtdbQcxxvJtzTNm7coH7W\ndW3cqLEm0wqqyAJZGDJkqCr95JNaJrKKp+rSZcuEuKhY8Vm/90BsEKbzgQcyqMKawONwCusrXqfo\nGeN1SihXiNouXbtK30AOv/H66yLL9erV1Tr8C/XiSy/rNbq47uf75AAAc/HdPu9KzrHIItDzAgEd\nWlzLxZq1a+UABfdHBcw/9DqhQDu9+aZ6NPejonfX6nLde6Eyup9ZTxcsXCTjyHrG+CNvhFil3U2b\nvKzWrPlGwszSH4ULF5YXdPTpNr3H2rJ5kxiUyOl2UROsRYoUEX3A4aCFCxeLrJg1Kzpgj5cly8Ni\noCKfGuvR95pMX7duXYR7PCfoh8Faxso8WVrWUDzoILDOnj0nejhREKGpnTD6DMKZ+YLeZZ08r9e/\niPSZhYVF3IUNjWhhcXvCzFvmMGsv/xq7iDPSgfNn/uU9ir0X78Xk6OX9m/fXyO4L4iKaaHtU9eoh\nUSYCRWOx+C/n3K0IkeiWx0B/i2rZFhYWFv5g31BvMSCxCKnjjjsGkUJIHneuBgyLfG+SvEM2vNe3\nrxo2/CO1aNFi+Q7j3UfDh6tt27eJF5IBRkbuTZDgv2HHeDF92lR9/3Ax9mzdulXyf2XUdYooHBOn\nntu+1lY8gAghuP/6dfH+IrRRPBVfPfHEE0KqrdUGGwwukGdsrEqVekKIJaeBBBLN5JxwIr42WGLw\nNaHsQM4cObXhpbVaMH+BGH7ZqHFKH/KNZznzeWAc5H7nZg7PKZ79lTYsER6JTSKGIfLqDB02TKW4\nJ4VclyplKtWoUSM1Z95cMfZwHWQYoR4xQP/088/ecWMT+bI2JpL7jHBIXJsmdRopt5Tuh/s0QbFo\n8WK1b+8+Oa1PHi7+nifPY+H2cYMGDaQNo8eMUfN1e5PrPsyrDZijR32i+rzbxyePC2HwyKPV9733\nxGtt+/fbxbOJZ9eo8R/ZhpdBJk3wGc8qA9rA94Q78hkD3RYIwXTp03k3I2yW3uv7roT+wyts3759\n0sfIRIcO7VVxhzGT75G7NPenCdM+Qrhl0htuYxBnbCD6aCubF+7F46dF81ekbECbhwwerN5//301\nd+48qV8Gbex+5JFcKr2u440bYXOyME8+/PAD1bt3H7Vz1w61a/cu8Z4gFxmG+YWLFvrMwJ49ekjO\nn2VLl4mhu1nTJkKEkZNnzuzZapB+PrKD5wkyAFHHRhu5Qv5KaKPy2rXrxSibQI81da5Tp45q1qxp\nuC8WEBp4RezSZABGbV5MIMJSeMfGN28P45E69b26LWm9pwG79+gu+fK+/fZbIehSp75P8gc+pOVj\nsK63c0PZo/s7QsRAdOAd97w2Dgciwp6uUF7myJw5c9QYTYpAPJDLyZ9eMcgQOr7OPWy7N94Qg/e4\nceM0ObtWXb1+TYym6AY8csIDz8HLSbk2xcHqMcgV9KNbryYMlVF3/ijGkuvRBYCXQ0i1Dz4cIF6Z\nRrbJebZQG9XjOYh4mU/6b8xfg4IFC6qJEz4TkoY5ivwwl9IJAVk9XCKffEWdOnRU8xcuUD9rfQuh\nxr1mrj1Z+kkJlbZhwwZtNF8heYIK6v7EyD9W93WKUNlBJ9yvdSIEmvvdgnlCONfkyf6TM8LrdQwN\n0bdz104SFIpOhdAU4t+hbwldC5mawiGnhJZ9443X1YIFC3309Wuvvqo+1/oyWei1yHYLTUKgQ/Hu\nhcC7X8tWq1at1OHDh9VhR44nCN96deoKGb5Bk9s0I21oLibkqJsm4lkfjuh7ftZ6mn5Km/Z+lfex\nvCq8GJ8QddP12jR4yBCRIfoSoq3yc5VD+y6+aqSJWtbfUVoHz9ZzgfbQRz3e6a5q167lDSuDLjBr\ntfsljjbzN7OuodsezPigWrFihbp27broDAi8AR9+KDkNQYg8PeyVJ8olxN2SxUvl8AB1Y8wbNmwg\n853rQZXnntPkzisir598OkbmWtvXXpOx7qGJFeQK4hGvUTMXIVpD9iUh7WAO4PkYph16Pcosa8l/\n63Og5yUK7Q/3OsC4l9bkDEQY/f+wn3xlbuDVS1kcPnFi0KBBqnev3nrcNopnHwcgevfqqYmqS2qh\nlhUzNuyjOAiTR8vK3Dlz1UK9NtN/qbUeNyE4kbGJEyao0aNHqy/1XmHRokUK2eHZ6Hqjxys8XUFf\nN1HNmjVLr+0eCRn9xBMl1Oua/GN/FwiB9n4h620mb24xxmnEiBGqb9/3ZF6H3Pugd4+3Z88e771G\nH/nTxSGkcAa971khexDGlfWsr95HEIbYeX/qNGHXamQWOXD2OfpsyuRJasjQoeqHH3ZLfRhntz6D\ntGb9soZ1C4u4D2NItwZEC4vbE05SITLrLjYL9gUcdGM/CjHGv4R0h0Ri70M+VH/g2kmTJknUi/Cu\n528d9DsF4J2X6whfyH3hPYPy3dcFAmSeCYfoBOXilRWo/sGWb9phrg+vvfyd64DxlOd68o8ZcO9Q\nvY9ygygn9KkJqQipx/tubIVVZI8cUYSY2IB5v3DmrjayG9XQiIGINQsLCwuDeAkzVIzRne7VE1+p\nOwXOEE1xHRg2CK2EgSeVi+AIFrjFs0hTBkagMIvHkcXh3kuuCIyG7sTyLKqcqL9HG1ASJohZ7pVQ\nVwyR09gcGZw9d1Y8uMLzXgoJsXZByJoUKe4JtzzCKV44f0GILjyB3J4H0k///KOS6D5KJt4Ujj7O\nUi3cOrBxwngVkecJoM/xGDDy4C+nUEyBNiF7PMdN1EQFyDJtpVzKTCH9GHYjg8GY0FUYHtP4Mdz5\nQ0j4q/MSbop7wiMeuJbyeTZGSXcdKIN60seMibuP2djxd8gRyMjIeMidpv36fp4b1RN5zDk8S4Jp\nJ7JCv/O8iGSFMG7kbKJNGMKjA8qinvRfTMgOMHosqa5bSk0GxMYmmBBsp0//LeQ9ZEZUnhGR/AgC\n6FzCz166dFl0CF6iThAC9PLlf8VgnSB+zM57vB/JKXdPBHow8P0R62sTWo1DFU5Czh+QWeZzwkQJ\nNfkWVk8QQg75Yg7RV2E8wcLRucwdyoZQ8iebnJpk/GATU+uX2JiQM8qjj+kfdF8wZRpdb+oRKPcc\n5crLuibQkrvmrelzZJJnx8RcDO95buANB1k7evQnqlzZyHuhuSHjooI7/WvWVmSJPvfXf96xViGh\nD91eTvydteK6/jcm9GKgepowr8Gud/7KYJyZE9SRfV5MhcIJSp9ZhIvb6Z3D4s6FIcF69+4t8/hW\n5tSxsIhrIKwdcyIQoXIngLX8ySef9DloYwAJwyE+5/5q/vz5QuyYfZITHJhZvXq193pIHcIDAogd\n7nXfN2zYMCHJDLiHg5Lu6yjTfOdcOyHBnEST8/tAJFtkyofcQg78tdfdP5BZEYVC5B4O/DkBWUg/\n+Lt23rx50q8xBdrGuwTvPeGl7IgtsH9mreH9g3cu9qfsJdlrR2aP2qdPH3nv69q1qw+xRtl2T2ph\ncfsj0QOVVEzCEmHhwL6UuhAOEWYRAwjHKGthYXEXwurc2IXVubcc5BwklGy6tGnV+PHjhJyxsLgb\nYd85LOICIPaRQ4yKlgizsPDF3UCEQSIZj6rSpUuLBzv5UCF1AAQWaS8MILYgkyBp6Bv+xQsKkgtA\nqhs94iTCAF5UkDp8b54JiQQxZMgkSCrIJ0C/83FeD5xrp/GkMs8z9Q5EhDGm5ppgyvfXXp5nrne2\nF7LM9APklvEec3qAuT3Q0L2UAegb6kxkIlO+P+IsOqBtEEgcaOIAIAfDbhbMYT4O4JmDeCaPHetP\nZA4ZGiKsW7duXq+wBKE5vflY7zALi9sbMU2E2dCIFhYWFhYWFhYWNwUYWjE6kKeK3HN//vmHhDC0\nJJiFhYXFrYUhZK3R0MLi7oOTAIKcwfsID3/2bJBheIlB7BgiDGLHkIIvvPCCl9CBwDEEkCGx3DDl\nG0AI4QVFmdSDMrjX3O++3vk3JwyZBWiLIbkCtddJguG95u9vBs72EqYQUtDca7zb+NcQYbTJXAO5\nZYgw850/OAkvpzcdz4OkNPWKKTLWkEaQRXhi4Rl2s0CEAuOxZUirmPDeiulcYxYWFnceLBFmYWFh\nYWFhYWFxU3D8+HHVsVNnde7cWQkl2LZtW1WmTBllYWFhYRE3YL0TLSzuPuB5ZGCIFrx0qlSpIj8v\nXbpU8oAaQNIYUgxyBhLnyJEjPmX6CyFo7nXCmfvK3OMsy038BBP+OiI42+vOC5bVTy6u6LQ3GFCm\nyQlGewORiORBiykiDF1vvKYIJU+KAQ6sxTbwPIN0IxQiYRD5GC+wqHpwOXNcOu+3JJiFhYUblgiz\nsLCwsLCwsLC4KSDH1dQpkyQMS4YMGSTsjn1JtbCwsIgbsPrYwuLuhMlFCgoUKODzN8gwyJetW7cK\nIcbPkGTh5QiLDPxFBQivPjEBZ/nBEmuQUzVq1PASVjEJZ5mQbM7wjLEFo++NNxZhCWPbK8zk1oV4\nMx+nV1h0yjUebs5w03ZNs7CwcMMSYRYWFhYWFhYWFjcFnP7Mly+fsrCwsLCIe7BhpCwsLNyeTgDi\nixB9JjwfBIYhwfCgIvcVIQ2BMxdYbNXnZoN2GxLM5Agznln8G5N1pDx/XmkgNkhBQ4QZz6zYzBVG\nLjJgSDBCMhoyzJBYUYG5zxBghlSza5qFhYUblgizsLCwsLCwsLCwsLCwsLiLYUMiWljcvXASL26P\nJzy/FixYID8THjB9+vSS59V4gkGCucMLxmZ9Yrp8PL1efvll7+/+PNwIpWjq0b59+3BzfQVCeJ5z\nhkQ0MGEYYxsmHCEfiDCIqdgKkXju3DnJO5c0aVJ5Dh5okGCGgItqWMRAsCSYhYWFP1gizCJ4ZKmm\nLCwsLCxuEqzOtbCwsLCwsLhJwGB4M/LDWFhYxD0YLyTInmHDhqkXXnhByBm8vzp06CDfG7IG7zBn\nOMMVK1aoqlWrqosXL6rhw4ermADPImQh5JG7Pnz8gWtNbi1nDjDjxeYsl/aa8glDiLcbZF6g8p2h\nFJ3EHO2NyBusUKFCcg3P4vp27drJz84+5V/qZJ7fp08fIecYE/M710A6xgacRBgEEmRYTB2OYF2h\nvZQJ+cXHkGGGBDMeYdGFIb9M/jNLhllYWLgR9SCsFhYWFhYWFhYWFhYWFhYWdwSM4dDCwuLug/FC\ngrSAvIFAKF++vJf4IRygAaSRya01atQo8RIjJGLv3r2910THk4uyzfPc9QkEPNf4Ox/IMwPqZL43\nRJmzPZRP2ENTvj/PLWd7KTt16tTywTssIkDiGXA9z+Fe2uTsI/rfeKpRZ/rT1AkyDMIuuvnY/MHp\nFeYMV8haEN31APLr5MmT6urVq0J+mQ9kmDMsoqlHTLTF+a+FhYWFG9YjzMLCIno4slhZxCKsV5CF\nhYWFhYWFhcVNgD09b2Fx9wKPpHnz5nk9wJzfO3NiAUih1atXe/NmQdDgKdaoUSN14MABtXXrVu/3\nhkCKLCCNuB9vKGdd8IxyEl1RRWTKpw3ff/+9lxg0hBTeXXh7QcIFai9hFPmb8zkA0stJbPE7fcp1\nkF5OUC+Isqj2ZTAwByEgpwyuXLmirl275iXKggUE2IULF+R+42lmwiEabzA+xhssuvC3btlDHRYW\nFv4QL2GGijGqHa6e+ErdKTAutRYWFuHAEmGxC0uEWVhYWFhY3NGw7xwWcQHIICGsMMJimHR6f1hY\n3O2AAHGTQXcyTJhByBlnPi1/MAQQ1x07dkx+z5s3r8qSJYuKqbpQJiRQRHW5GeU72xtZYsp4pAVz\nL9dyjfnENowH2PXr1+WDFxeEFh8ILb6DDDPEFQSXgbne+TFhD91EmPEEM39nDxSdAxisWZB13bp1\nk99NHSkzpkIuWlhY3DokeqCSiklYjzALCwsLCwsLCwsLCwsLi7sc1mBoYWEBTB6tYOAkjwyZRCg/\nQuI99thj4ikW3bqYXFqxgciWHx0yLjLPic02+4M/QsqQSRBXkGEQXIYU48PhCXOQx9wLEcWYG28v\nQ3yZnGAmHGJMkGBuGK+1mC7XwsLizoElwiwsLCwsLCwsLCwsLCws7mLERD4YCwsLC0iQKlWqqB9/\n/FGtWLFCyLBcuXIpi9sDEEgQVs7cYcazC88rPoYIMx5kTuLJXM+/xhvM3M/HlBkbZBX1MSEeLRFm\nYWHhD8EHebW46/He+/1U57feCura33//XW989soJkZuBS5cuqW3btqmLFy8qi5jH0aNHVfcePVTV\natVU7Tp11ahPPpGTQHEd586dUx+NGKE2bNjg8x3hDNiwRYRfDv+iBgwcKPHA72b8sGePqt+goVq2\n7Et1q3Do0CF18OBBa6AJxa5du2RMli9foeICCJmxbft2df7CBXWzcfr06Zu63sQWbmUfRgZxaT3o\n2bOXatmqtc93u3/4Qf3999/qbgJzYMeOnXJK93bByVOn1HYt78GAU+UNGjbyyVcSGcyePVv0JeuI\nhYVFYFijoYWFRUwCAuzZZ5+VcIlLly5V//zzj7KI+3ATWs7cXsmSJROik0+KFCnkc88998i/zu/M\nNVzPvXwMERYbnmBOuD3ULCwsLJywRJhF0Pjhh91q8+bNQV07cNAgbbRoKIbrm4Fvv/1WvfhSEzVp\n8mRlEbNgw/pa27bq889nqPvvT6s3NsnV1StXfZKoxlVcv3Fd7d+/X/2miVmDlatWaXJrgPr54M8R\n3n/h4gW1d+9e9VdUjap3CGlzURvmmWNRNUJGFxAEPXr0Us1btFB//vmnsggxfDMmvx/7XcUFbN6y\nRTVq1FhNnnTzdfD48eNv6noTW7iVfRgs4tp6sFMTwps2bfL+zmGYevUa6D3IYHU3gTnQqHFjtXHj\nJnW7YMCAAaqhlvdff/01wmtZgzdofRdV/X/kyK+iL+M6yWxhYWFhYXGnATKkXLlyQopxsAUvsZuN\nW3GQ8nY6nOQPhqgy3lsmpCGkmCHE+PCzIbzMv+Z7PhBgJh+Y8TKLLRLMPc7Wy9nCwsIfLBFmES1w\nErxHjx5hvic56uP583sTacY2iNOcI3s2lT59ehVT+OOPP1SduvXUnj171N0MPBR++GGPql+vnvps\n/Dg15tNP1auvtrltT9g8lDGjyvhQJr0hS6xiExc1iTZw8GAh4iyCA156vXv3ViNHjvL5ng13njy5\nVe7cue3JrlsMvH2fKFVanT9/3uf7jA8+qHLkyK4yZnxQ3WzkyvVItNabQG2KLcTFPgwWcX094GX7\nscce1XuCmEnOfruAOZD7kUduSiL1mELOnDlVzhw5VKpUqbzf4dn/cpMmysLC4tbAGgwtLCxiC9hr\nyDnGoarY9A4z5AeRIviYPFbOnFbOvFYxDQiwnTt33hEecE7SyniHQWqZj9NTjI/5nX9NXjCnF5gJ\nhxib9Q3mOwsLi7sbNkeYRZTByesVK75WadKkCfO3Fs2by+dmAYPKokULVUyCcHi7d+266134j/76\nq2zoypYt493I3M4oXry4fGIbhID46aefxKvMIjicPXtWrfh6pXr2mWd8vmcD2717d2Vx67F48RL1\n22+/hQktig5esnixuhV44YX/ySeqCNSm2EJc7MNgEdfXA+oze9YsdbchunPgVqBVy5bycWLevPky\nNywsLG4trOHQwuI/nDlzRvXp00ft2LFDNW3aVE2YMEEIHYvIA4+hokWLSpQRvMMeeugh8RSLbmQB\nQ2oZgsv87s8jyJA6wPxrdF50dR/v/ni8QfqRI+12iKATDNz9Y/Jv8XH2sbP/YjP0oYWFhUV0YImw\nW4zJkyero0d/Uw0bNpBQQ1u2bpHv8ahq07q1ypQpk8/1LO6TJk1W69atk3Ay2bJnVy82bqSNUmW9\n15w6dUobjXuoF19srP4+fVrNmDFTHT9+XKVNm1aVKfOkavLyyyplypTe68mlMX/BArVp02YxQCRN\nkkQVKFhAvfbqq3KPP/z8889qyNBhkt/h/vvvV61Cc3TUrl1L4kDTrl27d6tOHTuqBx/873T7vn37\n5W+7f9itEuqNQcHHC6jWrVupDBkyeK85fvyEGjNmjIQ8YuOZPl06lTdfXlW3bl058ewP+w8cUEOG\nDNHPr+01ok+ZMkX30VHVokVzNW7ceLVx40Z1+fJllT1HdjG+FC5c2G9ZGPlmzJypRo36RF3+91/1\n4YcDpI3UsWPHDt4T11u2blUz9Jjt279fpU6d2tu3nIYBbAgYhyeeKKkKFCgg4SL37t2n7tfE4YwZ\nn0s4p7lz50mZU6ZO1ZvBNeqKft4juXNL/fAMmDx5iiYGvhbPgYcfflg10nJSvnx576aCkHGU8eWX\ny9Tvvx9TSZImUTmy51AVK1ZU1apVVeEBj7ex48bJ6X7yZj2i+7aOHr/SpUvL38m7tuzLL9Ws2bPl\n99GffirPwlj7xhuvy2kff6CsxdqY+9vvv6nz585L3+TLl0/qBAjptm79OnXw4CH9898qebLkKvej\nufW4PSvxpc2zZ8ycofLlzScySD0glpIlS6py5sgpuWnuSZEiTHuW6X5AhjlxlCNHDlWiRIkwG7Dv\ntn2ntm7ZqqpXr+4jm4d/OaxWr1qtfj16VKXQm3TGIXv2bGHaxxzklNd3332n/jx5Ul27dlWlT59B\nPVWunMqTJ4+M+5YtW9SSpUtFljgNtmnjJtloO59JPVetWqWO6HlMfbNly6Zq1qgRsF+doC/GjBkr\nc+z69WuqSJGiqqWW8wceeED0wuDBQ7RuyKbavfFGmPYP0nJ48NAh1ffdd0Wuv/tum5o7b646dOiw\n6I6MGTOqunXqiPyEt3ll/v/11196jnfwIcMhs957731JiNy8+SveZLXkr/li1hc+z6mkZQLdxzXb\nNfE8bNhwqT8yj84CLVu20O0rogbr+U3Z6JR7773X+7w1a9eq+dp4ekDrAOYeL1OvvNJMXkAMeH6b\nNq+qqlWryHM/HjlKHTlyRN2nyylarKjMN/rCAH2CnmJuXLhwQaXTMoi+aNiwodbJDwXsE158Zmkj\n/IGfftbyeEJkt1KlSlpHN/YSBk79fPnyv+oz/TIdnn4G5AObrPUZebBo+5NPPqny6naGB8KAoT+q\n16iunqtc2edvjBsyQvz2Tp06Sr+dOPGHGjd+vITAPX36jMqVk3lWVcaI8SEpMp561Be079BBJUmc\nRGSuT5/esiYMHDhI1apVS8/1Z+Ua+pD51PyVVyRs7fp132qdelll02PTQo9rUT2uThnbtWu3mjBx\ngrST/nrwwQdUgvghXl54+/bt+67fti5ZskSt1i/TZr1Bzw8ePFhlypxZ+mr48OHqxz0/yst3/sfz\nq9atWqnM+m8QUZ99NkE8m51t4qX1449HyHfMd3TzvHnz9Lge0OOUTpdZWtpkXm5j6nn++tCU/8kn\no/Uc2a7+/ONPlUX339MVKqiaNWv4vGCja6hr585vqplffKG+1qQyawfeUQ0bNFRPP13Bey1rx5y5\nc/Xa8aU6fuy4Spwksa7jw6pC+ac0ofJCGD0UzHpA+8aMHau26rWRUHRZ9JpVokRxPR9f8SHMGK81\na9aqt9/uppYtWyZlslb0799fG0eK+B1j6jtx4kS991mvTmn5fVTr5yZNXvYaMAzMXMdAVb9+PfmO\nOTx12nS1VusK5iUeSCHyXU2VLVNGZBBdvV7Pmfnz50vdL136R+v/7Kpxo0aqVKlSPi/+X331ldZl\ns0VXMYfSp0+n4scLqceTeg4z351t/HzGDPXlsi/lUI2zjfv27ZM1GHlPped80WLFRI879RtgDEeM\n+FjWHXTg43o/0bpVS6mfs0+/+mq5ev31tqJ73TI5Ss9d1otkeq47ZdLZb8G0ywn2juRoY4xffPFF\n7/fsuwYPGSzlv962rVeWaH+fPu/KetGuXTtZD75d/62u5yD5+zA9b5AF6mL2lPnz51dt277mI4fo\nb4xnsi/Sz/jf//6nnnuuclCk7A0toyM+/litXh1yP31Yr15dVV7Li1MXMe856MXaePjwL7JuVNR7\n2zp1anvnHHL17rt91VN6zjym137ykaLDcugyP/10tLKwuB1hjJoWFhYhYF/QQe/X2BsdPnxYfocM\nY5/Rq1cvn/cNi+BBv7G3591pxYoVYvvKkiXy3vw+BNjlUyrev3+r+FfPq3hXz6l41y//d138pOpG\nAv1JdJ+6ljidupYopU/YP7enUmQJnJPaJsD+l/0TtjDeAe5kOEkud18ZkuxWwPnsW1kPCwuLuA0b\nGvEWA7Jn+uefS8J5NlZpUqfRBp8raurUadqAWVPt33/Aey1GpiZ649VTb7rIeZQzV04xjDRt2kyT\nPlO912FswAj/bt/31JtvdpaXfYw+v2vD+4ABA1WXrl19YhZPnDRJb+R6y+Yuq96AxNMbAYijxi++\nFPCEPIYSyjVG7huhH/PuRLswwl1w5GPA8FBTG/jmL5ivyaD7VZJEifWzJ6v/6Y2l8bo6o4081Z5/\nXhtDJ4phiE0RxArGw73aWBQIf2nj8tKly3wSoWOQmDZ9uiRIxxCV5v40YsxYuXKVeqF6DTFy+wMG\nt/37DniNKjcc7TOAKHtR98/XK1dKGCuM2/36faBaauPSxYv/eZCtWr1aLVq8RJ63fPkKMXCb8I0Q\nIXO1cfXFl16S8YPwwwC2cOFC3fcvSvlDhw3TRqTEYhBev369atW6jTbmrfOWjywwnie0cTSvJpso\n+0ttzJo9Z44KD8hNlarPq/HjPxODWbp0aTUps1K99HITMbgxppCQ367foP4Jbc+NG2aMA78gQy50\n79FDiIwLFy6qe++7V/2ivzM5utikztNyvmjRYhlzxgOPqYULF4nRHmM7uHr1iq7jLjVHt2OQNpId\n0/fTB5cuXZb2YeCjLAPItX7awLheG9USJEioSbJ71AZNfEKsmDINIJG+27ZNXXCEJYNogPAkRw9k\nXKLEifR4LVfTtPHUDYx/GLz2aiMmBtX77kstJwQ/GvGRhEGkf45q43987yYs7Gm03dog2f+D/mrT\n5s3yPGRtlZal3ppQQP7Cw+4fftBzprqQpxB2yZIm0+T4JD23aov8Y2TkNBrEujv3CqTbFK1b/tDy\nwgYdoyKyxin8JIkTq0cffVTPix/EQM+YhIdNun9Xf7NaynCC35kX27Zv844RbWrXvn2Y53R7+22R\nQXBA9513rFw6hb7btHGz+mbNGpFXgyFDh4r+43lp9fyJrwlF5jz9g5HZgPvRicM/GiF6DeIJYzFG\nZQiGV5q38PY7oVDr1q2nZW+uJj3uF3Lz7Dl9nTZs/vHnH+H2CeVM0nJ848Z1fd9j6hdtQMXwC8Fk\n4NTPbV9/PUL9TE47QrQuWLBQSHiMyh9rQy5zPzwwt+iv0aM/DTNnt2giGGKA/oYEg5zEmDxu/Dgh\n57gX2WzZspWQmuDKlSvqB903xqjtcekDyLWlmtRw5uliHeAgRgOtg6dqHYcOhqiCvGzYsJHMG4MN\nGzZIOyE6KmiSp5gmKL/9doOUCXnmPhTiBPLuXG/ov3VaFwz/6CNNhjQQXZIjZw51Vbd3ypRponOp\nL9f9pMmnQG1i/eNARNNmzUQ3PKyJotN6/vfr11+PUzfvOMXU8/z1IfqGMiEJTp08Jf3A3Hmzc2eZ\np8419gDzXq91hJaj3uTv4gAF5Bh7B9YgA+S+q27DMU2Csc6m0wQfa8xnEyb6fWmMaD1g3iP/9M2R\nX47IQY5Dek/x3vv9VA29l3F6VjNetLNHz56qa7e3dZ+e1mvFfVoXpvA7vsx58gNSFjoNYg/920DL\nELrWCTPXf9jzg/feDpoghYCir/Lny6/1bSK99s5XK3R/mLZCpLdt+7qWw42yHj70UCYhQppo/UK4\nPgOIqxZ6XhzX6wgkd548j8qegrUeXZ5O6yF3G1lbLur2O9u4Wl9fp25dkVv2EP/q+TVy5EhVt149\nkQODEydOqOeqVFWfjB6t9Vt89ZAe/0WLFsn+0FkvngeRZe51yyTzmf2dWyYN2HP5axdtcLbLCdYt\nDlVAnjnXgfXr1wlJim5nb2TAQaiFuu7o0cR6jd2l54nMbz1G7P0gIAmjI/Jl9L9y6C49Vr21PkX/\nsY5wivxbrTfIWcd6GAze6tJV9jjJkyUTIxyHytBzEMIGZt6zn2Mdod/Y26CbnfOeeqOfZ6LjtCwu\nWbJU+op9j4XF7QpjOLRkmMXdDjyWOHyKJxgeYMP0Ozn78CZ6j0XUGH7m77yDWUQNxjusWLFi8v7F\nIdNgI/GYd2vWbM/5X1X8k5tVwlNbVYLzB1X8y3/6kGAg3o3LKsHVMyrRP7+oZGe2qqR/bVDqwlF5\n/+Mdh7VdygotN1gdSH3X6PctSDDaQS60O50Eiwi3mnzy551mYWFh4YOEGSp6YvJzJ0GJHo1ddOzU\nyZMp88Mebbj1nDx5Ur7TxmPPyFGfeLJmy+F54412Hr0wy/ezZs2Sa3v07OXRC7V8p8kGT5my5TxF\nihbzaAO/fKdf2OW67DlyevSLuZQHtCFLnpMv/+OevXv3euvw559/erQRyHsd/2qjk5ShNyXe6+rV\nr6+fVdb7+x9//OEpULCwp9krzf22q0DBQlIu0AYDz7MVK3kKFymqy/zRe93MmTOlnoMGDZLftbFX\nnjtp0mTvNdSHOlJGIHz77bdy3+hPP/V+p0lA+a7yc1U82vDt/X7BggXyfee33vKEB+qUO/ejni1b\ntvh8rw1vnpJPlPaUr1BBfgbaoOzRRkUpd8aMGd56l3yilHxXtdrznlOn/vIpx4xnuaee8hwLrR/j\n2r//B/L94wUKejZu2uS9ftmyZdJXb7RrL79rA6mnSJFiHm048+hNmPc6fjay5A/8XRumPY/oti1e\nvMTRrt88VapU9eTNl9+zY8dO7/eTJ0+W+nzzzTf+C/xlkXxuHF7oea/lE54mFdJ5Ns3s7v3+2sH5\nnsv7Z3t//2v7JM8fW8d7f7+0b5anX+vSnnY1cnqObRoj353dNVV+p6y5w5pJGXx//dACz5B2FeT7\nn74e6i1jUt86nhaVMnrWTOns/e7s7mmed5uXkGtnDnzJ+/2CES08zZ7J4DmwfLD8fuWnOZ5eTYt6\nWlfJ7Nm1uJ/3uj+/+8zTpmpmuX/F+Pbe7/kcXDXMWyc+2+b1keumf9DI+93aKW/Jd9/N7e1zL+3t\n/lIhT/uauTy/rh/l/X7d1C7e9jqvd0IbGz3agOl5NM9jHm209n7/hZYl9EX79h1EhrRBVcZs3rx5\nPvdrw6Qn88NZPZro9n6njameixcven/XhldPjpy5PNqo7f1uk5ZDytPGQe93derU9TxRurRHE7o+\nz2CuFSxU2KONiF7dBTQpEuY5uR7J7alU+Tnvd5rIk+doYt6nTOZS7dp1PWXKlZP7gCbuPXkey+up\nrO8/5pjfGzdu1N/n89SqXcer0+gTyuWjyWXv9/Rnc93OnLke8axdt06+GzVqlOfhLFk9K1as8KkD\nOsjZHn/YtXu3R5Oy3t9pb9FixT0Vnn7G+51TP2vSLlz9TP3QX8zV1Xr+mWvRq8gA5Xw2YYLfuugX\nO8/LTZp6Hsub16OJV+/39AVjQ9/rlzbRXawz/K6Nwd5noF80WSV9oYkZ7/2a0JTnOtsJ/MmIWd/Q\nK04dvHbtWk+27Dk8nbSONs/TxmypgyZ5vNdpIkLu1ySQJzwMHTrUZ705d+6cyBX3sg5cDNWPtF2T\nr6FzY36EbdKGe+nnGjVr6r+dke/0y7Ln7Xe6yxxZuXJljD7P3Yfc/8GHAzxZsmbzaKLCse5f8HTo\n0FHP5Sye6VqGvP2gZZv7S+l5afoCaMOCfN+wUSPvd+WeKu/RBJWPTCMzrOvhIdB6wJpNPT8cMMBn\n3mliTK4fPvyj/+qpx4vvGO/PP//ce30gzJ07V/TbK3qvQdtN2T21nqCc/I8X8F5r5vo73bvL76zR\nWbNl1/L1us9zmG+MmwH98P33O2R8DRYuXCTz1JTF/ei2EiWf8NmPfPbZZ6JDNMHrt43LXbqEZ1d+\n7jlPseLFvXsIykbOmW8DBw7y1lWTeFLO4sWLvfcznshfba2DzfjxvEf0s9B/IDIyybO41l+7uM7Z\nLie4j30UfWLkDX3y0ssvS3/wmTV7tvf6sWPHSnnz9R4MdOr0pvzu3K/UrlNH68unwzxr9pw5ci1r\nzv79+73f79b6opB+/nNVqoj8BsKgQYPlfvbK6GCD7du3yxhrIsv7nZn3mgD3rlnsm15p3txn3lNv\n9rSUy1gcD12booqb8c5hYRER0BHM4x49enh69+7tsbC4G6FJL0/WrFn1+0ivcK/jXYTrqlevLj9b\nRA/YnZYsWeLRJGS417H/QFddv/inx/Pb177vzZH8XP91uef0yWOyN2OPyT6IvSDlh7c/5RrqO3/+\nfB97mcWtAetVd71fZ9/G+zMf9oWsZxG9Z1hYWMR9xDRvZT3C4ggIIWbCEHJ6oVnTJipHjmxycp4T\n4QBPDk6Sd+vaxRsOiBPfL/zveTnZS+gxJ7JnyybhlcxpCLyNnnm6gnhBOE8Cc9IX7winezMn8oHx\n5IkuOL39008/q0aNGspJY4MaNWqoBzJkkBBCgFA8gFO6xvOD+lDHYELG+cOrbVpL+C6DqlWrSig6\nwvdEBZyu/+23o6pNmzZeLwXKa9y4kXgIMWZOTzr+Nmrkx+r++9P4La9B/QbqwdD6Ma5VqjwnPxNq\nr4Qjl1XBgoXkBPRR/WytC8T1PmmypOqXX46on3/+z4MgWbJkAUNaAk42r1u/XkI6ECrOgJBvhFXi\n1PziJUtUZIGXDaG9ChYsKCEJne13jh0eS+nTpff+jkcKHkLknOPjBOHqnq7wtJShQvunRMmS8rMm\nJrzX4TnCWJQuVdr7XaqUqVSV555TEYH+I1zW44/nV4/l+S/cHB4SJkykG9mz5/DWyfyOt99ff52K\n8Hk/7v1R+orxzZzpv9BUTzzxhLQvkKciYOzwrERGnHUjfN0jj+QSTzM8N55++mnpZ+aV8criX7xO\nU6a8R1WqVNF7LyH/nCfXCAFKuChOQsYkHs+fP8xz6POoPod5hjdVp06dvPMHlNTy0aBBPbV582bx\nknCCMSIkmNF1yB7x2zkNiCcEYO7QV3gaOL3z0EERhd7Kny+fN3QqoL2EVTt//lwY2UY/165VK1z9\njFfroUOHRR8/qcfbXIu+rlO7drh1wbOidq2a6ty58z6eQHjUbN/+vcqXL694AvH7ho0b1DPPPCNy\nY55BSFNCwaBP8FCODlq2aumjg9FllE84U05hgj17fhRPNHScgQkh59RvkQFzgLB8eH8A5lflSpW1\nPkoalNzNnjNbToi+/vrrelxDvDwIi9asWVNd76tq0+YtMfo8N/CGJnQgfVKvbl3Hup9CwsWl03p0\n5swvwnhuE8ITGTEgtCjhZtB1Bqy1eIjipWOAzBiP5chixowZev1Lqdq3a+eVIepL6E2etchP7rPq\nL7yg6tevH+GJTTxtPOqGatfuDWm7Kft13QdOPewPtOnee+9T+/fvkzDUBsw3ZwhS5nbBggV8Qk0W\nK15M1vSTf54U78kzZ86KhxNrnHNNK168hOxXjjj619lGd87Drd99J3qecJVmD0EfNNB9wZpH2GXK\nQ2fMmjVb65AnZN9iQKjhkiVLiH4jpGl4CEYmeQ46x1+7gL92mToXKFBQ+oQQ0QAPPbz3n3nmaQlP\nvPyr5V5PX8JvoxMLFyqkoorGDRtJGGcDQsTm0r/jURaRNzUg9CxekgaE9iTMJmurmUdm3r/04kve\nNQs9yO/+5j1y9P57fWUva2FhYWFx+4Kwu4X0GsX7Ep7b2rge7vV4FhNRBy8g7sN7zCLqILw99onw\nvMM8xlvr3GHxAlPXLqnoIP6Nf9V9F7epRBcPe73D2Lc4vcPcEK//0BQIvEc+FkG4eoubC2fUIOsV\nZmFh4Q82R1gcAC/YToM4wED7eP7HJV8CxATGqYMHfxYjxltduvhci5GQBdvk1DHAEOY23GIQYkF3\nGgz4nVBLGCl+PfqrOnf2nORLAu6wclHFn9rgSS4lXMfZMDpxWhvuMWIADHaEGSD8XSlNarz40ouS\no8NfWJ5g8YgrrxiGM4xb7pBuweKX0L4h9A85RwwIBYjx6k9tNKN/k4UanvJoksdpeHECo1u2bFl9\nvjPGuRzaQONcvAmRyOfGteuywGPgwxjavXtPVV0TihieGjdqLHmGwsOvoaGkivjJkYbMkMPswP79\nKrIwxBSGpfBA3dlAkoeJMGPkYSMsnMT2vn7D51ohQJP6EqAmtNSlUKKU+cGmlee6jaJOo3ogQDRz\nP0Y79/3ueWlw5sxptWPnLiHQMFYTspExDxRK1Im/Tv0l15En74S+3w1CYQWCCQOGEfX1N97wfk+Y\nsj/0feTdYy7RFxBc6//P3nmASVE0YbglZyQooCCSBBOIOWPOiBhAEBUUjCgi5og5SzCjoCAYAANi\nDigiUSUKCIr+oEQJkjP8/fZdrX1zs3u7d7sX6+WZ57i92Zmenu6envq6qsb+4Ayc1CN9/Pd58+wL\nRosMogRG0K+//toZxJf9s8y1YcaSqlWrmGQSdh5EHsJgZgeMuPSB/fbbN9PfmjVt6n5yfL//c48l\nh5+AwMEYyD0Exh9CWxAelrBlCBBt2lwUl0BAOxo16lsX737xksVm44aNZsrUqS68oz8pB/qahAET\nguMz92HTpo22rzbPNJbvG3LdQRAFMbQjbF9//XXOyE0IQtoYOSAZo2gfK1astMbpgzKfY98mTtyY\nHwixmQjUd93A+FfG9mlCmG619SX1Qjl//vknVx4RE+ekj0M1a2bPwExuN1lcIXA9JUuWMOsCwmQY\n9DfKR0ic999/P/K5PDv++GNeUs8XBAPA338vNMcff1zkeSKkiYZ7RAQAX2QmX1EQhEc/VGqnjp1c\nSDlCE7Ng5hIrniGuB3NuxQN9m7xdjDvBNs3vBzc/2I6X05xwLc83xtqsnlUCIRZr71k703he3dX3\n7hnCpQZBWLriio4u99qp6bkzu3Tu7BZfBEHQIc8W8x/6BAL22rXrzPb0Nsq9pD3z/GIMl+fF7F9n\nm1J27K0RaKfRrvHv9HEcMX+e14ZoazzPeJZyT+VZQPhKf7xnjCB85ubNzDeWxsxbGE+bpO2whV0X\n1IjR//Zt0tjVyfjxE0zLc85x4aIW23KfddbZ5ptvvjFjxqQt5mIfQjKz+MHPx5gowfkccyRyPTKv\njOf5GzRWMeaVr1DBtV+Z70q/H/D6APPe+/+FmV6Rvigt2O8ZJ2OFblWUgoSERVTjoVKUYBEhIha5\nSJnzkdM5EW666Sb3HY5BzmfyyrK4REkc5iOIS5I7jOe2LO6KiFKr55pia343yaTc1jRbxMbSdSJz\nWcmDJfnDyAPGXAb7DeKnv/hRyX/o80xRlGioEJYP4GEaNPZDhXSD0dp0Qz8r+1kN7ecEAYyEbMEX\n8SpVq5qswNB61113m7HjxzlDE5O3qtZgVqZ0GZNMxIAghh4fEq2XLJk24aAuBvR/zQwdNszlKMIY\n/cILL5ouXTqbzldembABhYmLrCBPFkut0MUDlXsSvBYMlg3qN8hgTKwRY5UwRpiKFSuF/q1CHOW+\nuG1bs0+jfdxq/O9Gf28+++xz543Vs+f9bqV0GJKzA8+gIBjKy1iDK4ZNjELxJJ8XVlsBFSp5q+yD\nYNh71d5fDHusniYXS9my5aIaX8uWLWOKF4u94n/9hv+MeUGYyPor/MPAqI2QVK5c5vquGLiWnTt3\nOEMpud34W506dVxOEM69Y+cOEw9r161NP9Z/Yp5wYNMDY9b58nRPIe5NsO01t2JJxQoVnUEWQ+bF\nbduYLt+McqsbL7roIieGYFhvY/8v5yCX3H333e8EtP2sMQ+jMmJMTiaMTtgILJ4jh9ftt9/h8tMk\n6zy8jOARG1ZflSqlee+sWrUyw+dV4xgTMa4PGviGGT58uMtfQ56+vs8/Z67q0sXcYIWDaJ6peLF2\n63aTy/XTuPE+platPZzBuUSJ4mZLiNYXz/i8zrYV6pO6CkKexazges8880wzePCbLvcRY+1HIz92\ngsLxxx/v9uH5worG8hUy91uM1whWq62BILuIkT0rOna83EyePNmKFleathe3deIGOfoQ0S7t0MFk\nB8ofFD4TYe2ade4FirxpxYtn7G8nn3xiJqN8Ts8XZL0VUhE7KlbIPFYztpUuVdoJJn5OOSBvYVac\nccbp5v33hrvcUJMm/WTHtY623TY299x9lxPEEumbCFx4ypSOMm9g4Qlj1gY71sqYSo6neBa48Jzd\nYMd4+kDYWE7euUULF0X9PmNh1+uvN80Pam4GDxnscmwOH/6eS2R+9113ujkPzwBytT7zzLNOMKxf\nv57zCK4QqHeOdd2115rnnn/eXGLb5IknnODmNm/Zdnp8i+PN0UcdlWH/aNf4z/L/PPKD4/gxxxxt\nx6Dd3DNRxnvaYHA/hDzaWsUYz1uIp01yLsR+rj94XXiOBq/Lh8UFrIhHxMaQ+NnnnzvvQxYjrLdl\nRkAmJyfzAhaNHGnnJ9nNnUGbDJu3JEI0z3yBvhSt33M/w/o9hrCs5hmKoihK/gTvr06dOpnLL7/c\nLarIrrjBsxARDTGNiDd4Nt1///3ucyVxEMCoO3JvsVAH4cktCkuBCCZU2L7I7NxkxbCde0VEN94z\neX/mHQX7CIslc7JAW0k9ImDK/xVFUYKoEJYPwMCx+t/VGT7j4bt48SL3co0wVSrdoMLPAf37xzWo\nxzPuv/HGQGekvu22W53QJKvO+736qhk/YYKJiziSie5Rq5b7iUGzTZs2MfdlwtG+XTu3TZ061fR9\n7jmXuHynFSvuuON2kwjF01fw5ITg5e21V5qXULcbb4gYk8O/l/7FGKfnTzl9Ph9sBRC2VatWuRVo\njz72uDUqdzITrLgZFjZqt/SwiUuWZg6ptGrVv26St3uN3RMSwaBa9TTD/PIo4QERij4cMcKFWaId\nHHvcce7+wNvvvG3++vvvTN/ZhRrKon4qW9GDe7x6dWZjfZiROEilypWcIfDfEGP/mrVrM/xOGKp3\nhw51k3M8asSgx4p3JurxIGIMxsZjj43PI0LYc4+0lf+IG7f0uDnmvoRabNCgvm0TH7rQep9//oXZ\nf//9IisUMV4jTtWw93rIkCGmnvei5ns6RsXW+Y7tmcU/6mLrtv/qnPb0wAMPOm/G4cOHZTjPlCmT\nnXdddkBMw3t1fYinzdJ0T7vg4oB4+xoGcJJhX3bZZWbGL7+Yxx9/wvTp09fUqlnLhXcNQl/v3v1m\nJ4K9ZeuyWbOmkb91ueqqTGFr4y1L9fRwjEtDPAdF0I4F7fr81ueZN9980wqhHzsj8kx7Paeffrp9\nuazr9uGFn3FiyZLFmb7v7qXtP7X22MNkF/9lJBYt7Fh69llnuXISfpbQddQ14eOy6xFmcji2Vqte\n1S1IuPeeu82BBx6Y9ReS/K5VrmwZN8aEjdX03w2brLCEd0/ACyuetsU9YSzoY4XeZVZUHmENQS+9\n/Iq5uUcPM3zYsKhezGEgxpQqVdK2lxWhf19k5zLMXapkw7jE96pVq27+WbYsEkZToN+t+Ce+foBn\nFtvf9jnzyiuvmIGDBrs6fHPQQDN79mzz7LO9zAH2Hr/wXN+IgePP//3PtUWfq67qYsfSz83cub85\nkZqy4Zl96aWXxr3opvaeaf2JhSxt27aJsV/aeE8i+d69njXZIs42ScjAj0Z8lOm6CF1ZoUJ08Yl+\nesghB1tD4ggzduxYM2vmLNP84IOdlxohHfk79UV7wvtbwm5n91JybNDI4vvMuRPt97sku+MrSh6j\nhkOlKEBkCQQw3v94f0a4Sga8P3CsPn36uCgThFdEZFMShzkwAtj/3HzsO7NfvWqmXvms5305oeKO\nJWbjpvJm6y7V3SIuvMQRSFkEQ1mU/I3Y3/yf+kxTFCWI5gjLB2B0GG9FC5//zZ9vplnjKSthxNiO\ncRUjzrjx402ywOiBkYiQNiKCUZ6JgRwIYfBQwdthw8YNofGTferW3dutFidPSKwwRsHjYKh7+KGH\nTJUqVV2esdykRImSVrzZ6Vaj+5BXh3Ji+NkZhwiYSvzzs5L9iiuucCv98byS3HJBmMjhMUDYN3+V\neVo7HO8EtQMPiMPoG6BWrZqmhDWoY/QPC6m5ZfMWZyjFqHZQ8+YREQxjpIT8yw6sdscrgBx069dn\nXDU/N5AjKgwRmBEIfNGMuiWvjM+i9DxSjRo1zLCqnQly0EgrIuTmTRnzluCNg7Ft0qRJUcICRm9T\ntevUdh6Eo6x4He3+CnhhYPj9+eefnQBJmzj1lFOdYRLIiUKZjzryqAziFGGtFsbwsBAQVMlntXrN\nmgyfs/rfF6cI88V+YefhnvkUK1bc7GLbxfoNWYeRO/yww1zIMsKo+nAPEfdLWsO8nycpXvw+xdiI\nZ8MTjz9u23ctM2XqlNDvICAvtddJ7h5fBKN/TZ0y1WQXvKFo39+PGZMpnO2EOBcq4PFy+GGHuzx6\nX371ldliRUpyA4oXJt4btWvXMd98MyqTqEjoNgwE+3ph5BgXISxuf06YZcUIvEmuueYaM/Tdd8yr\n/awo07179kWwBIh2TYz1eMxRb8HQlqk4XxD6MCGS586da4XPjCIToVn+/OMPU9uK42WykT/Tb+e7\n2zGwc+fOTpQhD5aMc/GCAHTggQe4/uzn4YKFCxfaMWiy6/vBsInxgoclYuD06dMzfE54QES8rPCv\nFXGcFdqHHnqwu07G0cWL00LcHnPUkRlW+U6dMsWFPPb52M5haKvk/Rz67rvmpRdfcG02Ec9zPO94\n/jEuxwrnx7OC8fq7b7+NS/jOCdGuK56V8SwIYuz4wIqpCxctdmGaGV/wmGbsICfhN3a+Ua/e3lkK\nrPQNyc+RF/Dcln4/aVJ8i1sUpTAhOXHy+v1GUVIJIQwRqRA2COmbLBFMwH7Tq1evSJ4xBLdk514u\nSvCuctxxx5kaJZaZ3KDqzgXm19m/uDy9RA0gigCe+Dou5n/iXYCpKErRRoWwfEK/V18zn3z6qTN2\nkPPrkUcedYbV1uedF/EgISwXhqRbbrnVfGGNv4Q1xLhNMtHnn38+1KMlK+rsVdsZ+BCoMLRhnMZ7\ngFw+WUFZyDU0Z85cl/ydskdLVo4X1UknnWDGfD/G3HvffU6Aw0BOzhIMMBhAAbfz/v0H2MnifJcr\n5h97THLurFmz2jSoX8/kJm4FsxXtMIJSVgQiOMFOmlkBPeKjj8wjjz7mJrZLrZEOI+DAgYOc0Sc3\nwPD0zLPPOiMjYeJWrlzlhB8MpBhQo63ixqDfqlVL86sVFh9/4gmX/4d2NHLkSPNa//7OSHfGGWeY\nRCFU22GHH+7u6ZC33nJ1Qpv8888/3EsGoinhrajTmTN/cflXyJH1yaefuDafE06zAg/X8P4HH7q6\noL3MmDHDGho/zHIyhLGRHB+//f677QcjnWH0XytsIFT99NPPGa+xWjV3vHm2vCtWLHfGU4yzeLQF\nwztKGM/xE8a74yEGMYGuX7+BW2U+c9YsM3jwEOctQT1RblbU/2z7QDTwEGjf/mInCt919z0u7xd9\nljZIP6If++B1tmXrNhdeFAPfWWedGakPQnbibTRh4kRnUKa/zZ79q7nxxm52TMg610pTK/gg9DD2\nYOymj3z11ddmwIDXMxgxGb8Q2cPOE/TWIxRmzRo1zY8//uTaJ/cimkGU8G3kSXr55ZddWBPOTz4l\nrnX06O9dCEg/F1q8MLYSapRFB/R52tXYsT+YdVawrRclvEnlypWctxWeJbQ7rpH8ZLfddntchvpo\nIFoTloz66Nv3OTfm06/eeeddF7YxHjDQI3zRvt6y/bLxPo2tWNcs8nc8jtu2vci144ceetiNB9Tl\nqG+/c/cWbx/fC27PdG8WPCO5TvZNxosh+cJ4frDik7AygwcPtuV923knytibKqJdEwtECP32xutv\nmFftM3pBet38bseKfv36uQUryTxfEOq+TZsLzRo7Vt52223uvOw70fal3n36uP7bocMl2crrRb9B\nJF+6NO3ZRtgZ8oTSV2ule3AnQsfLO7rykCeDvst8gBxvN3a7yXkChXlSxkvbtm1dSFLaJ2Xm2Dxv\nez7wYJYO6Yy7Tz/zjOuX8hxHRCaXJ2M0QjOLOBCmvrFzDfqYa/+jRtn2/4ILTekjwhjhmwcNGuTa\nKeMF87C1AQ/iaDD+n3HmmbYc482TTz7pFlJwTnKhDbPH/caeG1gwcVO3bmalLfM1117rPOSXunHu\nb5d/q1+/V02yWL9+Q+h1ERkgq+s6wApH5BZl/McTTLyoeNbgfcqii19mznQLbGQhRjTqWKGSuQxz\nUMb/VAuAYUi/7927t3n77bddm2CbNWt2jvq9ohQU1NirFFaYYzZv3tz9FJEqlSCI8YxHyOG8CHBK\nYogwX37HMlOudO6YLkuYrWbXYqtM06ZNnQDGO7QuEih4qDeYoijR0NCI+QCMMYcdeqgzDCNgkFdh\npx2zz7Ev4+3aXRwZwJlAPfboI+YJazjpcvU1ppw1WPE3jNGEQGtjjUUQKyZu8CPCD2K8ePLJp6zx\n401nmN6+fYcT3fr07Zsh4AvhX/xjYqQ7t2VLJ8ZcdtnlzhDSzh6PcDrBc2Oo63n//Wb7tu3mvffe\nN8OGDjMV06+1WPES9tq7mjOt+IKx9rHHH7cC06POUL/NlgdDMiHdWE2VFbtk+YGJ1E1Wz0Xy6eDh\ngTH2a1tHNaxR/cUXXjB16tQ2z1rD2i233mZefe1V89prrznRiRxuFSqUNw8++IALVeifK0ohTGIX\nk/Fz7tXIkZ84AzliA/cDIzmGvXvuuTvi4RcEAZP7S10PG/ae3Ya7fTG27tOwkQuNVa/e3iY7ID4g\n0P1ghQO2UiVKurwweO/Qflu0ON4ac39zYgkGMVZ+U3dHHnmkGTtubFznkDBEfjgiwqrNtIa278d8\nb8ZZMQlvoM2bt7i8WYRiDB7Br9tiuxQzbdu0cTnOPvnkE2eAY1X6disGnXbqqU6glnMhjh7U/CAz\nfdp088CDD7l2jVcHXkOVK6/KUCZefvbdd18rVs009/W839V7p04dzf777W8uad/eCdB4d/5gy4t3\n2aZNG22TKGZatjzHHHLwIaHXjmH06quucsZc8sERcoo8VGvXrnPH57sY8QTyxdWxhklCfHEtrNAX\n8Hxo376dE1XOtt/BSxDDY6OGDc2xVmRauGjhfzUmbdVrsxdecKH59JNPbRv82L1Qli9fwd37Vq3O\ndcKe7Ml97nj5ZXac6JXpPAg0X375ZeSYeDWee25LJ4RceOFFbjy8+ebu9v8XZrrntPc+fXrbv/dw\nxnY8F+gTCGdHHnmEue3WWzOVP7QvRq4t7Qd96L77e7pca4QmxGODHFnNDmpmzmvd2oTBCxJ9qlfv\nPuZ8Wy/kGeMaGcMw4vOyHU9Zgh/Rvu659x7XV5+3Y8+A1193ggDXeOWVV5oXX3wxrgk+uQupW64N\nb41grrQunTu7/oMRnLxx1DteboRwu/++ezMYry+84AL3rCCUHEZ7PBQ/8gVnrzzxvnykvVTuYu9h\nZReKksUVfMLzYuPGDe759oa9dgwJoWTjJcf/RvCaNm7cZMeRH5zQ+uADPV24WZ67Tz/9tCltx1fG\nesrKooG9o5UpG+cLq8OW9hm7YMFf5gV7r0fZdsR8AXGH/nv99dfFHV6VQ/r3g3Ht8SeedG0BsZSw\nr4Q3JORrImERhWOPPcbl3HriyafN6Wec6UKX0m4Z2260fePss8/OWJgEYH6EwIYwdYEdFxBvya9I\niFrOS9v979AZ+xcizhsDB7rvUmf0n+W2XLvbvkn4IsYNPIBa2nFnxIiPXNnJvbZu/TpzhhVxttn+\nL8Wl31VPDy38iR37yBdJ092+fZt7lp1yyinmqSefSPOiinGNjOMP2GfCFisQsgiKDSGdZxDP72uv\nucacnB5C8NJLO7ix+N13h5pzW53n2h2iFWU54YQWLlRjdurUfcV417Vb+HXxfGNhTOS6QkA4rVe/\nvllhxUByk9b12g/3h2c881TGIT/kcthYyHhJ2+x6w41u/OQ5OmTwm7GDD8YVCzTDj5hfl37fs+cD\n5vY77nS5wej3XANjo/T7XXaJcVBFKaDIano1HiqFCd5LEKF4vyCP13nnnWdyEwQ35hyUgUgNvBfw\nfFPig/eEYuvmm9xk/zplzP+2V3TzO97ziqWn2whLO6HkP+QZpmKYoihh7FKixmlJXdawdckXprDA\noJnqVR89brnFeTy9/dYQZwSR0Fv7NGrkcvyEiRmsSsdThXByO+0/jBBHHH64MxJSZrxUvrDGZULS\nIOT4/L1woQt/hzAhRkXCA1EGPB9q7VHLGer53gcffuC8EfZMz1PBynwx9ggYnseMGWN+mTnL7LAG\no6OPOdodG2Mm3h/HH3dcBqMr38e7Yc7cOc6YX8Eaz+vV29sZ8zCY4RHAam08XgjRhLCEwRzvj1h5\nKsKumRB9lOG0007NlFD+o5EjTcUKFc2JJ55gYuFWXo8a5VbN72nrBqMkhhDAs2nipElu1TtCBAYq\nDHMHNWsWuW+UiWs8xtZL2H2cPGVKpjr61xo5v/rqK7OfFVEw0AkYq3744QdnAMRAB6zipy3gVURb\n3X233Z3YFM/kmvJT16xy3mqPvXfdvVwC2D0C+YAoJ9d5zNFHZ/qbY35GLyQMh7NmzXQrqDHw7lo5\nrV4wjFJGvIdm2r/zt+rVq1kjd0OXOwZPNkLZURdc69RpU03ZMmXtd/d1ApFAu8GbqmGDBhk8fpyn\nmT3uksVLTHFrbCMHUn37svHrr3Nc22po2xEgBvw+73fbVvbNUO8Y/AgNtcgaHdm/7l51TQNr3Btn\n64jV4bXSz7Vt21bn9cf1sR/hCjk296KEFXXx4vGPiTccq/gxcB56yCGuHuR+8h3qY+26tbbNlHPC\nA3VAGNEIdc/JVOX0OzwB8QDEqFve9hP6M8cXQ62ApwJCWGNbLla2+SDyfGtFLPK6MMHn5Yxwinie\nUM8nn3xypM4Iz3dw84OdKCEgfDF2UJ9lbJmbNj3Q5bNhjClhjb20GcYkRD9C81EX/nnwgsBTo7Un\nMHEf8caYM3euu++nnXqKaz8cc/mKFeakE0+yhvv/wlLiUfPd6NFO8GSMqG/Ld5QVVoOhyoYNH272\nqLVHpr4YHBMxMk+aNNF5rSEOV7JCD+HUMOJmFSZs3LhxbtzZsnWLu0bGT0Jq0F5PteMmRuBEx2dA\n+ODY1Ak58RCVDzhgfxeK7GD7f9pnLGhrjNPUH2ES69bNLHQwNhMKbNr06e7/e1nR9BDbniSXmA8e\niIyL1D39EIMCokewjUR7DjAO4HmHKEGoEzxdrrvuetPIttFOHS83NfFIIiytrTvK3dsKjJdfdql5\n+OGHQ68veB7aNWPlhg2EMzklg/EdYwghHzHWS748/5qW/7Pc7Lb7bvZ8l0VedrlOwgXPXzDf3U/G\nK+4d/YlrSNb58H4J62ccf8aMX5xX5Qbb5/AoI58VooMP48lUO44S4me3wDhAP6W/IpYDfRzPMsIC\nMsupaUWHww4/zI0TsV4Ys3oe4KVKOfFiwrsHb6FgnqVo7SIrGCt4Zq5aucrUr2/719HHuPEaDx0W\n5Qj0delftH2eLdOnz3D1W6x4MdefmTP5z0naPGMhohp9rGGjhm4frocx6Wh7vUOHDjV33HmXufji\ntuZ8O2YxxhA+mXp9883B5lMr4DzzzNPub/FcI+M4CyG4b4gszFP2abSPW0gTnLNMmzbdPp9mmUUL\nF5my5cq68QWBUMb7nPQBwsuyoIBFCMHrGjFihFssIdcV9d7Y8+MJ2KhhI3vM/zxOKQde9Vwf3vR+\n6El5NnHvSnvhPWmXhNjdaMtO+RDvWVGPtzT3YY+AxyLPlQV2Psy8qHSUMKHcV57vp5x8iqlS5b9x\nXMZG8juyWMT3rqTf05Y5N/eqapWqbj4i/Z42Qxhe5pI8V7LjmemTG+8cipIV4vGA4Z5nIKFkFaUg\nQ9QIFtOSp4t2vWs28pUmE8Q4BDHmavQvFcRiw3i0fcMyU2J57ocr/mtrHWNKp0U2YWPRKfMpFVby\nH/Qp5nR33nlnZDGHCJgiYiqKUnApWfN0k0xUCItBbglh5GYZNvTdbOWzUZQ8JyCEKUkmRAhTlMIE\nIWYJ1fflF587L0ofjM0NrHEdY/6A/v2NouQV57Q81wqHi8zECRMyCEsw1grVF1/cznlj47VbkLjW\nitCI/2HXRajUY489rkBeV0FDhTAlP0AbZPESRkUVwpSCDAuOEMBY/EG+rmTnAcsJlI0+RkQNxDlE\nOiUcxqOdK2ea4utz1yMMVm6tbFbtsodbIIQQxiIYxDD1ms1/hAlhCGC+N5+iKAWXZAthmiNMURRF\nUZQ8g5dKcF7OniEYj5RBb77p/i8enYqSV5QpU9rlCMNDVtopP/HyfPvtd9zLdkFsp/S/aNf15qA3\nC+x1KYqSOBpGSikI4FVFO42Wc4vPTzzxRNOqVSvnNZyoCJbV8XMKXmCEaJQ8ZQh2iGPxwr54umUn\nP3xBQoT5YlvXmLygXPG0UNRsTpBLL49SMNBnmaIo0dAcYYqiKIqi5BnnnH2WMwb06HGLadykiale\nrZr5d/W/ZvGixWbR4sXm9NNPN9dff71RlLyka9euth12dZ5hTZo0diEUCTdKeNuVK1eZG27o6vJV\nFjQI9Thp0qRCd12KoiSOhLNWlIIIHlbdu3d34Q8LQh4uykf4XcQwwp6TDzUeL0zJd9a7d2/TrVs3\nUxjJ4CG9ba3JC0rusj2DAEa456DnvKIoilLw0JE8jyHpNvmlgvlsFEVRFKUoQDjE55/ra40W35lp\n06e5Fa7knyJHGfkj/byLipJXkOOKfK5fff21mT17ttm4aaPLQ3nssceYs8480+XqK4hJ1Mmp+MrL\nL4VeFznHmtn+p8nhFUVRlPwK80bEIbykCINI7tqCBEJYx44d3TWQAzQrEU9CKeLxVpiRnIW77Nhm\n8oLiu6SJX+IRphQsNNy0oijRUCEsj7mqSxe3KYqiKEpRpX79+m5TlPxM06ZN3VbYKKzXpSiKohRu\nEL8ILYg4RBhEvMEKIhIuEU8vwjoi5uHtFSaIEeoxP+U8SwWSNzOvxQzxBpPNL5OG3suf+DnCQEP+\nKooSRHOEKYqiKIqiKIqiKEoRRg28SkGC0ICtW7d24te0adNcWMRYubbEc4zvIDZltT/wd/Zjf7aB\nAwdG3VdCM8q+0Y5PCMRo+cfwDEP8EkFMzofYF9w4Xyzivd6pU6e644VdmwiNYefi2Pwt7Nr5Xk7w\nc5buLJY3a/e37yyWoRz+Tx0j8x+0dzYRK/VeKYoSDfUIUxQlZ9Q9xyiKoiiKoiiKoihKKhk9erT7\nidEbEML4P+IR2wcffJApPCICEAINPw866CD3HYQ0Nr4j4QbDvgOIU4g9bAhHhGD0QRQixCHH5fgQ\n7fgY5tm3RYsWmTy75BwIYniEIWLxO8cIEssrjDJSdurFv16pH/+7UncQrAcERv4Wdi4pK8dH3POh\n/EmjeBljdqwzuc2GbWmmUl8EU1El//L888+bSpUqmbvvvjtyn/R+KYoShnqEKYqiKIqiKIqiKIqS\nlHBkeIRgjE8WGPXVqFm0QXRp3rx5xDsJcYp8WoRElA3BBy8lEckEEcFkf37++eef7hiIOMH9gTZM\nuEL28/dHUPI9q/g/whZ/k31lf8oTFIkkt9eIESMynVO8su6//34nMHGMunXrRoQs+iZligXlEU85\nqRcpD/C3sOvNLlwf5eX4lI/z5TR/mS9kbCuRN+EuN2wrGQmzJ2XRvFP5G7lfsun9UhQlDBXCFEVR\nFEVRFEVRFKUIkyyhSQzx4k2jKDkB0YawewhcCC5sgNeR76mEcMRn7O+LTHg00SYRbPz9fREsTJQK\n2188ncQrDRCcEKfwtPJzlLE/3+f4vnAmOb4oly9I8X/EN/7m5wZDZENcQgCsV6+emT9/vokF+3E+\nEdP88nAsztOnTx+TLPCOEyEQxAMtWWwrVd3kBf9uLh3JNcXmCyy5hYTRlDCX8YTopG1KOMuw8Jhh\nsC/fYR/2jXX84P5stKdYYUaDoTOjHZ+yShnpC1JuzhU8PtcmYUIlFOfIkSNNly5dTOfOnc0VV1yR\n4xCdiqIUTlQIUxRFURRFURRFURQlx4jAIIKFomQXxCLEH/E0CoY8DCLCle+NKKIVAo2E85OtcuXK\nmfaPBd5ZQRB9EMg4PseREI1BocuH6+Bvfu4tjPZ8FhamkT6F0EafCguT6CMigy+CCeKplUxvzazu\nSXbw8zvtKFnF7NwldzO6bN5ezKzfXsYJYMWLF48IYX7ZcgPaBJ6AeELyE7h3tDc+CwPPPNoI7YB9\nECk5jrT5ICKwiWjkHz+s/YqgJfuzD+O9eF1GO760W/aJdnwJAyrCN/tK6E7299ut9B8RfmHBggXm\nhx9+MGPGjDHff/+9+109iRVFCaI5whRFUZSiwfyPjZJCNF+goiiKohRYkmngDeZQUpREwLAtIQ6D\nOa1iIcKWb2AXI3msvFU5DRWIKCDlRRgTj6hox0XsQqDAk0aEJIQL3+ssDPkb5+L7cqwwwoQw8dpK\nphCWCvxwhIhQm8vsacpsnG9yi6Uby2UQwfgZFMRyC9oQ+eLkfovHLfcQkSnaggPJ7Ya3orSFoFDF\nPhyXNsh+0m75jGPTPv3j4zmJIMf+9EuBz0S8Igxndo8v18u1SWjR4P4SGlRCkYLk6Lv++uvNXXfd\nleHeaW43RVGCqEeYoiiKoiiKoiiKohRhgqG/EgmxJUKAv0ULw+WTaIitIOzP9/1Qb/JZNGM/n/N3\nrkfJf4gHCd5LeIHFK4L5+KH55P8Y0CV/V3DLifein5OLY61atcoZ6NmieUtJ7jDpWxyD/8cSwYJQ\nLxj/w8LGQSxxzw+9mJ+RsIRbS+9pdhQrY3IDvMGWbaxgSpQoEdn80Ih5gYhgIN6BEObh5e9He6Sd\niDgbFEdlDGThgt9nOJ/kpfOhbUOwXdOWRSDzkXE57Ph4VwaPL/iimV+eWNcLeXmPFEUpOKhHmKLE\nYPPmzWby5CmmSpVdTZMmTUwqyc1zKall48aNZuq0aaZqlaqmceN9jJI127ZtM7/+OscsWDDfVKpU\n2TRs2MDUrFnTFCV4id26dasLAcNLV6L8YV+4i9nJf355uZ05c5ZZv36dadasmSldurRJBhs2bDA/\n/fyzqVO7jq2nvY2iKEq8LF682Pz222/mwAMPtHOtKkZRlIywcl42kBBbEDS2B43s0+y8NxiyjflI\nLM8whDIMoWKglRBbfIYBN6v5DB407M93/fMw75DcT77XgoBxlrKKZ4GSPxBRVAz42ZnP0g7B/678\nn3aWHVEtKyS/GMb6RI6P0CdeYWL0j+bdFYZ4+3AMCYGH55CEgETwDZZHhISw+smPRHJ0lSht1pVp\naCpt+MWkmgXrKrn3sJIlS5pSpUrlGzHMh3uGkBRLGMpKVBUBlvbCz6CYKu2Iz6WNiKgmwhxjrYhr\ntL3g8WmD0Y7P+27w+P71BRFvz1js2LEj8n8VxBRFiYZ6hClKDNasWWNuvuUW82yv3lnuy4P3scce\nsy9ivZ2olcpzxcOMX34xV1xxpRUXfjVFCSZdb739tpmShyEfVq5cae688y7z5FNPRT6bNGmSufqa\na8xff/1lcpMZM2a48/Izv7Jx4ybz+ONPmHbt25vru95gOtqX4AGvv2GKGp9/8YV5rX9/szJ9td3a\ntWtN/wH9zbjx4+L6/rChQ13bzy8MHDTQ3NjtJrNw4UKTLFasWGGuvLKzefPNQSa3YVXyNbYvzS5i\nY2puM3jIEHPHHXea1atXGyV1FIRnQ7IZNepbc8WVXcz06dONoiiZiWY4RDQScQKPALagiIRHTVBI\ni4UfYovjcWyeswhaEhYvFohgGHqlXL73AMZaPpecSz4cW64nEe8bJXVwjySsGvc/XhEsKAJwHPEw\nkVxY/v85R7A9iKdjMgga+sXLKxoIBLRVySdGX8iOKIUoQd+hvSMuIE5A2HVJ/jBfcBNvoTAPSskD\nlRfIeCRh7naWqmLWl9zTpJK/15Uza7aWdSKYv+VVWMRYcK8hEQ9aH7nf/BSPXH8La7u0T9qa5MVD\ngGVhUZgHrvS1RI6fTPw8c4qiKD7qEVYEwUj/888/m2OPO86ULZM7LuYFmS1W1AoKW19//bVp3Lix\nqVOnTuSzTZs2mY9GjjTlypazk4GO2fKACDtXdpk8ebL5ypbz+BbHFykPM16mb7/9DnNphw6meUhs\n9Nxi65YtZtPmTZHf58ydaz799DPTvl27DO0mWSA2/Dpnjjne9msm7AJ9/bPPPnefswo+PzJ9xnT3\nAnjEkUeaO26/zQpA60z16tVMUWPH9u3OI2xn+mq2f5b/Y+/fZPvZNnPkEUe6F7BYbN22zWy3x8gO\nS5YscSLTfvvta18YkrNGhrIwLma3TGHwUsMxt9h6ym1mzpxpPrV96aijjzb7qtduyhj7w1jzzbej\nzMXtLjYHpRtz8hOTrQEAz8uDUvR8mTdvnlm0eLE57thjTSopCM+GZIPn8Wb7XN7urRhWFOU/oglY\nIjb55HQMjBViKyvDZSwRTODv4m3jh70T42tOQuEpyYP5PwIVwowY2OOFe4khnnuNt4iE1cQzxReU\nEJu43whD4jmFNw3eYwhnGOwRy7LbpvmueDJy/hYtWmTykIwWppByIQpALO9JXxgW4YPjS3uWsIx8\nJgIYfyNko4he1A+fUT++pxjfpR/yXc5D+YF+ltPcaTlFPLB4B8Ira0vZvd3i44rbF5tks3BdebNk\nY0VrwynlPMHYeKcWb7D8JoQJ2fXok74m/SPe44sYJkIvIXRFzKUPBD3DEj1+TvA99uR5pjnCFEUJ\nokJYEQRPmfvu72k++XikCmHZAGMxXlsXnH++ufLKKyKfly1b1jz26KOmfPnycblup5pzW7Z0otyp\np55iihKRSY9JXsLvZNDavmBUqljRHGnFnlTw/fdjTL9XXzVD333H7LbbbpHPzzzzTNceTz75ZJNf\nmTF9BjNXJ14WFYNsPNTes7Z7ua+7115ZimA5ZaR9HmzevMWJ5sWLGyWEc85paSpUqGCOtkKYkjru\nuOMO09I+vxrUr2/yI4888qg5YP/9UyaEPff8Cy4EaKqFsILwbFAUJW8IGg1T4TmVSIgtn6AIFs2I\nyjEwyophVoy+IhKkIkSeEj++1x/hK7NzP2g7eJsgQgncaz+fkr8vbYX777dnzosAlZNnuuRsQtAT\nQYD2RlnwbqcNIhaEncPP3xSrDoJhR8H3qJEwpFwbx+E6+Q4eXeLVxTkQJMLqh+8iekn5gfIjomXl\nnZlqGI+cR5h9x0cE21R6L2M2GVNxR/LEsPlry5t/NlV0C5n9TYQwzp/fxBTafk5EJPkufTHe/sc5\naSfidUt7Y6Nd+eE5wfc0zM3xlnaSX0VLRVHyByqE5TGswscDaC9r6GRlHOHsGLL33XdfU7169dAB\nfNk//5g///jDLF++3Oyxxx7OcOznkyE/EeHXateu7R7eCF//LFtm9tlnH1OjRg0zdOgws27dOpcn\nASNIuXLl3Ip9VsqG5abBILNgwQJTtWpVs/vuu0e9Fr4/f/58t5qZ4+IxFVzVxbH+/vtvd71MKKZb\nA/iiRYtMrVo1zf7WsISYFAv/2rZv3+G8ntauW2vq7V3PGnAbu2PiUTFt+nSzZPESVz8HHLC/W9Ej\nEG4M7xn+VqlSpQzHJ38EdcOD3feqEainb+2kc86vv9p7tzgSdpB6Y7LEdfn1J9fboEEDVz94Bf39\n19+mUaOGpr418hWP0+LMNf1h7/mff/7PlruWax9h5fPh2AceeID9mfF+IuTNnv2ra2/VqlW1ZWmU\nQTgB7uPv9j5u3rTJ3ptaZr/99ot4uBHCkXqqVYv6q2iC9ceEn7bmG+6ZkCyzbXDW7NmmeLHi7l5z\n7iCUDa8LzlHdlqlJSBvKDhyP89ex92dLei42aTdpHjC7uH5IX1n+z/LQdkPbo15oG+w/Z84c13a5\nt/HkdGLiTp8IAw+o33//3bWVGjV2d/e3YsX/6hYPmN/s3xctXGTKWPF6//33c+ODwFgwbPjwtP1s\nv6Ye6Uu0R35yvDAh5d9/V7vrwEt0n30auWsLtknGKK6da2S/n3762d3PBg3quzYcPC5tftasWfZ7\nS61oUN59j3JEm4xSL7Nmz3Ln3bhpo+tTXPuee/4X+oK2ynUx8aa+WcUZrG8ZS/G2W79+vZk4caLZ\nsmWLW9WIOB0N+uXSpUvd96lb7r2fO4byLV+x3O6zzGyz/ZBy7bZb9QxeU6tX/2vrfrMbX9etX2fm\n/T7PbNm6xdSw42WdOuHXTp/mfv9rv+uO6d1PoVixXawYtqdbmRhk40bG5b/MBntvEMoYn6PB/Vts\nr+/ff1eZypUqu/HT91ilbxAejbxbCxf+bc9b3N27XXf9rx6oW8q7yt6DPW0dkb8tnhcMWZnHuIrH\n4kbbPhgfeJaEfZ8xlrY+z27cS/pMNO9a9qW9/GXH1KpVq7hxCqEqbD/Gzr/+WuDuN+eXNsl1kQOF\nZxZjXRD6OGWnzXE/6Ethzym/jcrxg32DZxdjCu2EsVLCsyFEJJoT7h87D3Dns+MtbQQBM/ic45nx\nt33WMVYceMAB7lkvyDOF9k67Z+XyYvvMpG3zIkud0/Zn2zGbF2T6BPXrj8fUHXMD2gLHZj/uB32e\n50rYM4r6d/fi779sf9rmxh3q1m8LtHc+D953rpnxavXqNe5elSv3331o2LChq0P+zvOM+8k4NH/+\nAvd/xvlq1bL2MmVso17/97/59vq3u2vjnktZfvzxRxfmtpb9XJ7/tGXqhf5YtmwZd39pN7/Y+Rzj\n2nHHHRe5N4yh5PJbsXyFq+sD7H3x79tMW2YMu/vu2yTD8f3+zb3l2lbb51pjry370ObT5gx/ujlA\nzZo1ImM74yv3PdazgWfmrFmz3fOceQT7B6ENzZjxi203i+y9KO9y9gXvZbz481qeQ/T7sHltXfs3\nPGdpr+zL/aFd+m3brwOe2dzP2nYs2ce2SUVRYkP/jTe0YU4RrwI8VkSYEM8UyXMUhuzL8zaWtwrH\nQiDBMEsYRgz6ko9GhDQlbxCRhvvsi1jxIsZ3QXIdcU9jvTfK99iX70TbP3j8eP5Gu2WT8HD+sWN5\negFzyGj9LujdEg+cm9CleKohzlEOEfui1Q+fI+aF1WW0ugh6iaYKeZdgHsPcgDnZhh21zdrNu5rd\nd/xuSuyS/SgRm7cXM3+uqWyPV9Yet6Q7NvNiNvEKExEsL4WVYB4tvPu4V0GP2kQQ8ZVxkT4Z9NpC\nQA0KtOzH59x7/3NpL36YRt/TMOz4nDen1xCE+aHfl+T/KoopiuKjQlge89TTT5sp1ih/8iknm4ED\nB7mXfcAwcf1119kJ4o0RAwzG3S5drjJjfvghwzEOOqiZeeXlV5xAAhjX2l/SwTz55BNm0KBBzugP\nhGQbO26cMwzAhRe1cT8PtkYvDC3kp3n3nXfM0UcfleH4b7wx0Dz2+OPmoQcfiDoR4qHX45ZbnYFI\nwMhy/fXXmWuuvjqDEenKzleZu++607z33ntOsBIwaLz80kvmkEMONtHg2tpe3M706HGzGT78PWfo\nEU477VRz9VVXm/vuv8+KKbMin2Mg7P/aa9ZYlBaO7ptvvjE33NjN9LYTwgsuOD/D8R977HEz+vvv\nzUcjPnQGnSC33nabGTZsuPv/y6/0cxuwP5PLSzpc6upyyJDBpoI1vsv13nvPXc6LDCOYgIA5aOAb\nGQSNMDBQ39yjhzWKzYl8tr8VaSh/kyjCCnz55Zem+809bJ2+aM4++2xntHruuedtmV+JtDNgcnfn\nHbebq+19crmt7rrLfPH5FxlCB2E4e2/4MGc0+8Ie92Z73N69ezmvOJ/Hn3jCvP/+B+aXGdMjXnEY\nkR959FEzePCQyH4IkHfZNnBx27YR8bJv3+dMv379nGFfYPL5yCMPu/1ywldffWVuu/0Oc8ftt5tX\nX3vVGXyFSy5pb86x9cPf/fxdtJsP3n8vYlifbu/DhRdeZO66804z6M03nSggHHrIIaZ3n95OkIhV\nhpu632xGfjQi8nKPoe5Ne6xHbbvz7wnCyIT0vFDvvfe+eejhh524JdCf7rzjDueRiHDYpu3FznAJ\n9A9o2rSpGTb0XfPZ55+bW2zflHYg56Wun3jyqQxh67i/L77wvDMqC0888aT5wY45N9s+9+CDD7n7\nCUwozzrzTPP4449FXpQ+/vgTc781OCCs+Jx26qm27fXNZKzESNv6/Asi13bjjWkryE61+w/o/5oz\nmve2E/1+tp9t3PRfmMlmzZqaJ21bwwAqPPPMs+4e3XRTN3PPPfdGyjBp4oRQIYxJMUb+AfZF0a/b\nsraMd9h+jnGZ8vF3/14Dhu0Ol1wSMWCP+OgjM2HCRDs+Xm5efTWt3AKiL2O5L57M+2OeedmO2Rhy\n/7umZplCCCImPvbE4+bwww4zl1/2Xyz/CRMmmNftSwVCn3DUUUdlusat27aaDz/40HwzalSGkKuI\nGldd1cWOH01c++nTt48Lv4hQfX9PWSndInLOH3/60b5Qv5GhjSL2XHvNNVkK1TzL3h061Lbzwe4Z\nJp91u/FG07Xr9RlEAEQV+gjjpoBo97xtO4fYPuazxoohl13e0Xxvx2uBsfRJW1+0H4EXom43dXcL\nNHzatm1jn2kPuTBpZ519jrvf3307KuM5bJ8izyJG+s8/+9Q9e2+25aOvt05/aUN8fv6FFzK10eOO\nO9a1Ucov3HLrrW4BAe33gQcedPcbsei3uXNMvCBMPGGP+/Y772ZoZxdeeIF5xs4nqNv77rvfvPPu\nuxnuFyJQPzv2H374Ye53hLhTTj3NPaMnTfoxQ503bXqgrZsH3fgwbty4DPVLPz72mGPc7wg6F110\nkWlnx5xx48dnyLtUz74Q93u1X4ZnFItI6JvcZ4Hxv0OHS5yhskS6UMO86JtvRrnxC0GNvvr888/b\ndvq8u19hTLT9vKYVoLimyy691J3ju9GjI39nDLjbPtsuvbSDiQbPv6uvvsZMtPWxc2fm59+XX35l\nnn7mGfcZfZ4Nbr/9NnfOa20/b2THzubND7LPvMdcn2M+MPq7b93/uecYDzZ7/ZbFBK/aekKkYZHS\nbfYZRbsYO3acOfW00yPH73r99e7/n3zyiZ2H3O7EMOB+n3nmGc4bXQR8RH3G/NFe3/A56aQT3fgf\n9mwAvC0esH1ja3r4UYxOjHd33nlHZAyfMHGi6WHnAQsCOS9POvFEO7a9lOWiJiGReS3Ptp497zf9\n+/d3QqVAH+tj+yTjpMDihpus8e+HH8ZGPkNYP+OM042iKLHJTYNvoiG25Dt8joEfES1WOD3xCuN4\nCGGSH0nDIuYN3GO8i7Ly5ksU7n8iHl2pFEETKYdvrAf6HYuQovW/RPuliHPMsah3RMdY3paQaF3m\nFr5XGBvvwrzZLNq8rym7fbmpsss/CQlia7aUNCs2lTUrNpdLF9dKuncSBLCgN1h+8C4ifCb3EfsK\n7zb8Xzz8cgKCqRybcVjy6bF4gHETscsXvGg/zGWlPfH+yvfYX8KS+lA++n3w+Iz1jM20tWQKYR9/\n/LGzaR1//PHuPY57x7NCURTFR4WwfIDz9LBGqRu6dnXGR1buP2kNUM9Zww+rnsVwgyGnYqWKVoTo\nbk5ocYLzxvnAGjn79O3rDE49vQchBoxHHnnErdLFUL2XNQBgXO/cubN56KGHnOfLq/1eiXiE/ckL\niH0gDX9vuDniiMMzeIW8/8EHbmIQ7SHFQ+aaa69zhidEgmOPPdbltnnppZfN008/444lRhzhPlvW\nY489xrw5aKAzDH711ZfO6Ha7FWS+toJBLDAScVzEi969nnXX+syzvZyR6ttvv3OG54FWYMIohvEW\nT5kXXnzBPGrrI14PrGj0uPlmc/DBB1uD0F1WdLsqIqRJstJo3HPvfe5lDWMZXgVvW8HxHWvIJETl\nC88/F3VyxapyjGt4DD1hxUgMbBj777XHwwj1zjtvZ/AcigUryHvZCQcTg1usqIHRzBkLvxttDk43\nMr/99tvmcyuCYdBv3769KW4nD1OnTjOzf52drbxW3KtHH3vMXSuG58suu8x5DD1l7/UD1tC6V529\nnMEYI+xLVgQ92hpYe9j2XdEKZXiEjLL38+gQA392QDRAkLvoogudKCztZsiQt5wBkvM8ZcVj6kXa\nTf/+A5wY7cP1nHLKKaaPrcvixYu5775l6+0ma2zHcJuIZ8ewYcOcwZG6veGGrs7b6Ve85rxj4OmC\nOH1+6/PdintWt993/wOm73PPOQGd7wwfNtQKVbc4j5+nn3rKeQ9giIxmjEREfvKpZ5znB/XNNSMo\nPGX7FQL5uLE/ZBCtllijIm2uc+crXb/jHva1ouonn35qmh/c3PUFBDJEML73xusDnJi2fPkKd9xa\n1pgZVhbGt7ffGmJetPee/vv4Y486AVLa9IcfjrAGzr5urEBQr1KlqjXujjYvvviSucoarD/79JMM\n7d8JKfY+0E8QIQiPicAeBl6hjLH0PdpEo4aNzOo1q62A9o/znoBy5cs57w6Muw0bNTSbN202Q+09\nGzNmjMs/R/0JiA6vWDEEgzLn57ifffqZFZF+smPrd+bMM850+zFevvzyy/bnWtO2TRtzwIEHOMGL\nVZj0d98bLYxFixeZwUOGuBe1LnY832PPPdzihnffHepEEv/lvkTxEqaMrXfa9qGHHmqq2LY0zfbn\nEVaMRWC9xQrsePbdYtvOc7Y94TFJmXhpEAEYjyLqm3t13bXXupeun37+2b3wUI7g2B4EQXLgoEGu\nrKeecqo1fK+zz6vX3FiE9+Ml1sAOtCnuKS9JTz31pFugwVjHi9OVnbuY720d+h68H9iXMLxpEBEQ\nXSZOnGSfIU+ahx951L2UifcyzzieCZSTxQdr165xCx6or1NtPz799NOtcfwMM3LkSGdsR0AWEAbx\n0EHsieYNzb0MttHPPv/MCg2vmquvuda88/ZbGdoo/YFFIO3sGHT2WWeZXYrtEvdzCePIww8/4kQu\nPB0vs3MD2sskO34efvjhEc+e6rtVd8+ms848y4oEe7oxnmfuvffda76w4ofPCy+8aI6w36Ufcm8Z\nq7lfjAMIDC9YYRwx6ns7P+jVu4+7rsNsW/K9tVhcwYvs67bf777bbi7vFOLgZVZI/WHM9xGxk2cy\n7e0m+5JMPeOVS5hB7sV59sWYNhoG5e/T9zlz5BFH2Gf/U07U4yX8biuqnXbaafbZ+JibH+1IX7zB\nQgW/beCZhTCFwHbMMUc78SkMnn8//vyTufXWHk7kR2jk+Tf3t7lujL744oudp3DHTleYc89tGWn7\njBECL/YsKuJ6GAtKlCzhyobRpnyF8va7nWy7O9lUs6LiN19/49rss88+a56z8zieK4PfHGSf+V1t\nm93X3H/ffRmO/5MdS5hrNbXt+O6773LtirYwaNCbplLFSm7xEzgBc8J4c+8999h7cKlZb/vWA1bg\nps8MGNDfnGgNGtGeU4xDzFcQnlmsUt6O59xL2gRCKM9D5iO0w3VWxEJEo64R9bl2PGDjFcEgbF77\n2mv93dgSnNcyn0Dkpd8gBlex7ZW8m7S/R+39JSwwbY26ZmELIljbtm3NpVZoRYhkvGehgqIo0ckt\nbzBIJMSWjwgofBcvA96vonmm+B4JiGD85Hf1Bstd5F7x7MbwXlTDUvp9S8L8SZ8L81yReZ3kyJK/\nJyrK0JfoW/QVxIdkipC5hVyz5Arzc4dt2VLD/LWliim2bZ0pZ9aYcsU2mlLFtpmSu/y3YGzzjuJm\n49YSZsP2kmbd1tJm3bbSbv5dtmwJdzzx/mILE8HyWghDyEd4Ei9YCceZ0/soorR4aUpYzGhhNOm7\nbiGrbUu+N2e0/bM6fnY8QqNBWHXe5QYPHuw2QHjjOZLqFAOKohQsVAjLJ1xuBQIM4YCxjpBt519w\ngTMGtGp1bsQA+Io1uvngGYVh1uXY8WCiRKiu96wxPyjSYCTn4c6Kfgm3g5ET49DX1jCD4VJCRCGe\nEGqoZctzoq62wwsErwIMGddee03k82bW0NWmzcXOE+jcludGPLKgvi3TC9YoIedv3HgfM37CRGck\nZKVzVuIOZcVYKsb62269xbS3BtWyZctZIeDJSAi6+++/zwl8c+fMdSv3Y4VIiwfERPH6IZwjHjRC\nrBdHXuj69ukd+R0xbak1fmM4oo4x1IaByPL33wvNs888Y84/v7X7jHP+Nvc380q/fmbs2LHOiBsP\nhF1wXjxnnRkx4DM5QRgTFlpDPHV0wfkXuJBL4HsHJQpeGBjcyXWCkCcG37vuustc0qGDNcoNcAZk\njGisksfAhREbaCO+Z0cyQFB62ArBYsSl3Vx4UVtnaOxlRVUJESnthhVXQRBW+r3yciTsF/2VkF2s\nvh89+ntz8sknmXhgJTwehbR1BGHxQDzYE1eAVVqSRBkQvhDPe1uj9B/z/jB72+/R3ukLiDH062Co\nSx8EK0RHwnJhOJTroA1yDIygiN8d0gUKAREXjzrhHmuInWEnmz/++FNECNuyZasVNg9x5WXCyTXF\n8vBEzJEwsLSN+vbapE8h6iAyMDb4YwXeKpXteIgR/JNPPrXG6bYZru2Yo492HqCx+joG1c+/+NwZ\nuhFoEBHCqLF7jUxCD+Mx3ot4JDQP3CsM2ee3bh35/corr3Rizh9//Bn5bMLECU4gPOeccyJ9l1xg\nVa2ggaE+K0Z/971rO7fe0sPst1/auLFHrT1MxQoVrbD7bIZ96e8t7XkyXNNpNay4M9OFjmWspe73\ntIJHMVv/3H/ED1+Y+cIa9XkRvLl794j3KvsQQhEvVTwvfCEgjEvaX2LLe0vkd+7xSSefat60zwZe\nWni+fWSFKELBsZ94gNKWEQ7vv7+nE5sRmgTaA0Z46Tf0AUJsIvIi3olwxRjHYgMfXrqusPeGsG4I\nYW3bXOSEML7rC2F40zFWnNvynNDrIuze22+/G9pGaVt4/QXbKGMFHoJ33HG7SRRCJ+MRdNhhh9m5\nwEuRNn6Y5wkDN95wQ4bfmQN8/c037vnKggDfCy/Ny+s59zyDHj32NN9boXfJ0iVuzD7qqLSchjwP\nJk6aZOcDc13784UwrvulF1+IeL9Rhzxvhrz1lhv/27W72H3OfR+UvhpfwDscr9B5f/wRVQj72Qqv\nCBnMMUTYRpyk/fD8DOvrwbaBl9TTzzzr2lg0IYznX5Vdq5iLLrwwch4/nC3i8KbNaeH1EOP85794\n5BI6lHaK95RvNOH/DwSMA4h0LIohVCRjN4se0kJKFnd9wj8+sFCBe/eyff7USa9rngfMbxDfmH9x\nL5iP7dtkX+dpJ+F9rr76KucZSgheBOAwMMg99dTTrk3wTJJ52CMPP2zr+Vc7Hx1sOnXq6BaRLF/+\njwvxfBZirr22tLH+EJMdgvNa7jNlDc5rARH2mWeejsz9qK+p9jmNd+/69Rtc/SAY4qHLoqyHH3rQ\nXT+8bucbRx19jGsLiqLEJjfEsERCbPmI4ReDK+9ReBuw4j9a+DkMyBhfxUCblUeMklyoe+4P9yGW\n915hxxe7mNPwLGVOxnxxhxeFRcLw8X4moQB5p5JNPKOEeAUa8b7kfvCeJqJzQUOu3xfC2NIizJQw\na7eWN/+S8mNzWr2y8JHIH7znRsS04sVMmRK7uLqVTUQwEcD8vGD5Iawe45fkxKMPxRLAYoX2DENC\naTKGMu5mdXxpS4hykqcsq/2Dx5ctSKxwm9GeCQI2pHfsvJpoShybOTGbhkVUFCWISuP5AB7ehKrx\nwcBwiBVLMFpIKDIfJk4Y+zAeYTAhh00QXiqy8lQSePBj/CFn0KhR/4WHeu/9993PNtboFAaTuZ9/\n/skZTE4JGFcwFJ111hnOy2HBgvkZ/nbEEUdk8nzgmoEwVFmBsdv3WMFwU7lyFfugrZvhmjFcIQpg\nnJIwP3nBKadkTkaPhxT39vff54V+h7odP2GCqVqN3Gy7uTBUsu1eY3eXowijZLxg/KM+WIHPqv6w\nuPpHHH6EM8jxkogB1w+nlh0wUuLpgfA3f8GCSPkJO8XEBE8j6qBxkybu94cfecSFfOM7qeD441tk\nMODSbsjpgnePn4NF2k1YWzzl5JMz5L6h7xCWjD45b97vJl4It4cAiEdcPN52tAf2ZxVWyRIlXb4q\nPJgSxZ3XvhAQ2i2Yw6dtugAxdcrUDJ+zwp88Rj7UXVXbx3m54CXOCSp77uFWp+F9gpdSTgwp9FkE\nv9NPPyNT/ite4BClCcUaPMc111ydpeDNveLFiLEzKGZFg5xctIetVuzjxWjN2sx1L2HnhLR8ULtH\nQqJSVoze1OehB2cUCOvUqR2ahyfIn//7007uK1sj+X4ZPucFr0zZMlG/x8vgqlUr7TUss4bhsmaL\nbT9bvRBtYVDeuXPnuHJt277NiSOycb/Jt4dBPBa8fJwaGP+4n4cddqjzbpTnGyGCESgJ++qPdYh8\nEAxtiBdKMHztPo32cWNWtJwhiKuMQyyKoO3LcxODOcIZoe78cIOE8uMcR0XxSv3777+cB3dYG211\n7rn2uVgptI12TV/0kijMB9ba+mJRRDyLOqhPvM3nWcFcPPyC8wlEOxHBQPLkkS+OPF0C85SGVnSh\nLW8OtBvE7qAY2r59WohWxMkwKAcenDLWr/43+lgmz6FgzrBS9h6uD5kfNbDPukxtwwp53FtE6Gjw\n/Fu5YqXpYoV9REO/LcQL7eDyyy+L+dLNcRFj/mfHSPryunVrzdYszsW9JO8hwo/L75beP5Y4IXr3\nSA4tjr1t23YXZtI3lDmjjv19/br1Uc+BqP2XfT4wJv5jnzVyjhX2nteps6c9xyY7n1vs2lLTA5u6\nfJGESc7KMBEvMq+lzUab1/Ic8ud+XFejhg2cqL9lS1o7mWvHlQ0b1lsBu2VEBJN9CSOpKEpqkHBZ\nsgHPY/8zf7wQQYrPyXeDoIWRHk+DsBBbYYhHBF4uAwMLLQQJ7SU5doqqN1JuQ30zX+e+cJ+4R0VV\nBBPPL+afvDexWChtAeGWDCIYSN52nuvsw0Ib5krMhUQ4C4pniYBAgtjA/cFmEq3f5Fd84UsELJ71\nEgmF+THzBOYq/D/4OT/DNvaRvGD5TQTzIQJDqrz5JCxmvMeX/GGJ7C/HT9VYQD9jQR7vAUV1vFEU\nJWvUIywfQFgYP+STQJgqJjwYITBMsQr7tf79XQ4mPzcW1K+fWfBKNDE4BoLnX3jRfPTRSBeuiokY\noRcRYciJEwblW7rsH2egqh6SiJ4V4jyQMGz4cD3BiQVhvGBnHBO73XbP6PHiJkTFdnH16K92d8ct\nkffNvLY12gchhBCT2KXLloZ+B8MOhtt/bP22a39J6D6Llyw28UIOHLwI7rjrLpdzCu8RjLUIB7JC\n/pxzznYeC8/26mWuufZa5xlIOMMrr+iUULgjQV54OVfQWwUwRjPRx9sAjzm8kQh99Owzz7oV/6xi\nz8rbJBF23y1zu7GmerNrlV0zhSej3QRzNkG16pnb+Z7p9xcjYbyQo4cXIkSwWO76GNJfePFFM27c\neLd/pOzZnJhjuOc4YfXKCwD3XPIICvSpatUyGvrlRUSgvsjxd+ttt5pBgwa7nFAtWhzv8kgdeeSR\nCb9ILLYCOv1DcsT40M/xCqOtMgaJgZzyxCP+851Vq/51IeSCYqAPhuEvvvzCTJkyNWZCdgFvkiAS\nzx54ccXozTkrV844OeczRFn7bhyV7Tu2OyFit912z1Sf/F61SsZ75Iznkya6kLH/m/8/K57+Z2wP\ne+YEWbN2jX3x3uLCRRIONgjnXLN2Xcxj8CJaKT1foA/tjPuwMv35Rvng0ksvCz1OUMAIEw0jY70n\nPDEGEdqN0JurolQu94jFHuyHAHLSSSc5Tz4WceB1HRRghIULFzlRP6yNIqSXKVMqUxtlHK6QTc/k\nvxak5WPCgzAaac/tD8zgIW+5FZFbshA7g+OAW2lr+xHGgmBOP+rXteWAsEdbCj5nZUxc7I2JLIzo\n9+qrLv9XPP1JQKwrYcV/xsHHH3vMnQ+DKaEr8XAOUitG24glzvP8w7OIeRb5PhlLyCGJN2y8zz/u\nrXjU+/Cce+fdoebdd991Xva+yOZ7y0eDcZt7i7dXixYnZPo7zwPmirz0N2xQ33k0f2SF3fPPP98J\nZ2+9/Y75184nCA0ZDcndRj7Lr0JCVNMeuG+05UcffcTV5fD33jMfjhjh8sbxvD7G/kxkrE90Xluj\nZubnVgk7dqatsk/7HW97YHFBkN2qR/eWVhQl7RmQ3UVMRFGQsFcCY4b/GV5BYjRNNMRWGOzLMw/B\nRfLVhOU34m88NzQ3WOrhniNsct8RM5MZ+qygIX2J5zCCVlZzsjB4F+K9DSGM9zQRaeRndkL3iYeO\neEpK30iVwJJs5FpFrBJhjHcpEQnZmDcxd0FIlAVkUl/yHdnkd78+1ZOoYEF/88OJKoqiREOFsHwA\neWfCvJVICs8gzqpnHuZXXHGlmfTjTy5M0x233+YMapXtC8All5BDLPNLSzTjXTQwXJ1+2qnm3WFD\nnecJBheMeN1uvDFmDpNiu6TFrA5bPS3XhQeLj79KNzuUKlkq9PNdEoj/uzOkzjZu2mhSwbqQVdib\n01cvlyoVfp9kcoehklwhYata8MBJBATN70aNcmGHyE/12RdfmJGffGxefP4F+xJ5gjsneaAuvPBC\n8/HHI83Ijz8xTz31lPn888/Na6/2i5pvKXKdAaO4xPBGbDvu2MxiarlyZSPXRc6bb77+ynz+xZcu\npOegwYOdgY2QW3gQJoNSpcJFj0TiRod5yUU8FsrE3+fSDLO7OA+jaBCijDw7hOciJwxeP7tVr24+\ns/fj8cceN9mhePq14uETRjB0GlA/JUuVMlmBR+ZQa+glTAIGUu7lxe3am+uvu9YKCj0SytEnfXlb\nyNjIiw1jIvl3fIqnx43P8tjpL0DbGbN4SQ2ZLCOCPUsOQnt/Dj30EGdcqVa1mvOoIuRdGPGcu1h6\nHSBq+VCMrNohxu4SJYpHXQXqT/oZkwmjR14gQqx1sM8JwrpWqFjB5cULGp1Dz8fLoEnzJpXQrMHz\nxRJlgGfAjhBBGW8yCf0CLITg/vXq3ctUr1Y90/7VAgstSpfOuj1iYLvU9h/qi1ybR1lBtiZC7//m\nm66B8IGELyTXEDmXEMIIrcHYFAwt6UNoFQhro2kv4iZTG83Js0+OFctTqVev3uYFK0gffthh5qGH\nHjQH2DGjStWq5sEHH3T5H4OUitKvpY/EA30kmNdCvMZKpc9DCEnY/pJLXfslByX5vmrUqGlWrFju\n8pHFghCiF130g8slNmrUt86oQR3ggXnP3Xdn2j+ethEG4xMhK6+44gorzLxnPv3sM5d7auTIj+N6\n/rljlCieqd54Pjz44ENuTMS78KounV3IYfLJ4X1G3rqsKJE+buC9fOutt2b6O3XfpEljdw233Xar\n+X3e7+aWW29zOfOgnBXyCE0VDKOZ4Rzp87Qzzjjdin+ZBWmOvd9+aeEa8Qjt1+8Vl39t6LDh5tNP\nPzWXXd7RXHnlFS5XbDwGiGjz2uJ2LLj6GsJsh8xr43gOlYz0k8zjjuaIUJSs8Q3AiYTYwpCeqNCU\nSIitaCGzEL5WxVpFZNKEsL3T85ApqQNBBQ8/yQtUUISVVCAiGF5dbNn14PKPx6Ia3jVKptuGgnms\nEkX6N2IYYjI/EasLAkExTER8fvdzrzHvxibG3FG+Ewyr6IedVAGs4CJtICcLOhRFKRqoEJYPYJUP\n4cr83CQYTmbNnOXC5rD6mZW648aPdyEU+3i5pjAIr1y5ylStGr/rL8/2aJMxjIHkB0KAwAuCyZXk\n9wiDCVjtOns6rwPy4Pgh3jBU/WKvoYydfNQKWTGfV4hhbu2ajMYnHpis8I+XRCa0v/3+W6bPJk+e\n7Oq3dhQxq3z6ynKMufXq7e1CgSUD7tkZp59uTjv1VJdH4/quXc2Qt4Y4IUyg3XXo0MHe+3bOS+KZ\nZ3qZL7780uWyQ5hlgrFhfUZxj/ogjJIPYZyoVwxs5ALLamKJURaDWMtzzjafffa5ubHbTWbA62+4\n3DGJiCiphLxcQaam5xKLJ8ShsIcVnvEAmv3rbNdXwkSU4VYQpI8/8cTj5qD03GkQzZsinjaJlyYv\nBL/O/jXT38hHR8iOho2ynxeOe0xoLTbya3WyRuX+A153L1aJePeRn6tcufJm2rTpmf72119/O+8H\ncnuVKpW40Zs+UL16NedlRDhYPAKD4LWBJxSeQmee+Z/XCZ58YZ6C8cA9xmts7pa5LhejL+6wWpEc\nN7EgHCreYIwJQcESwYl7J8Z6XpYn/fijE3O6Xn+dq0vge9EEf7ybfCqWr+DC3uKdSmi54IKGeAh7\nvlHWOXPnRp5vQBg+hF88iwkXmgwmTJzovBsff/wxc0n79pHP5/0+z5Yho5hECA3Oi7cSYevwjD76\nqCNdDqZoICwi3oW10blzf3P3gNCO2WmjYYhBCfEhLNwudY3wiQcyHrbS39LCqq4wqYIwo7QrX+Sb\nNjUtvOpe6WMiYX7//XeV6W3F5fPOOy/Dd7NCPNHIqdXtpm5OhKlpRbR69fZOicc3XvDXWCGGsavX\ns73Miy+9HHn+yTNs5474X7DxLCR/5H5WkH7+uedsm0/LvUX7cPMQ77EY7fjcywoVKrpx74gjYo97\nPAdKlyrtPL5bndfKeWUS6nKPLOZheGBxfrxl8RzLSjRiX3JksrHYgUUbeHaRXzIYmjKMaPNa+l+i\n81ofFnVRtl/ts/WEE1pkPOdfC4yiKNER43FuIyG2UgFeL3iHqzdY6uC9RHK+4WlU1MNPSj9i/hyW\n4iIn+B5Pch6ZJ2VXEEMAQxBDDCOEpYQcLShI3rAwIYx3Pt57ZYG4L3T5wpf/WX4iWeGnixK+Z5ii\nKEoYOkLkE15/Y2Ak7BlG1o8//tjlxznssMNN5cqVI670eA+JsZuJEKIVxqVEwIsM9/yw1XNi1Ph4\n5McuVxirl/cMCesn8JA54/QzXFnee/+9iAcY1/CjNcKyMgwvlvpx5irLDcQwN278hEh5eWBizJw1\nc2aW3y9vjUpMOH+LktsrDIyqvsEPb5PBg4e40GzNPIEjyNlnn+VCBxGqkMm0QLk5RiIvq4irePhJ\n++HeNW68j3v5lEn6kiVLM3g8sQ/5VjC6ybSQkGRlypQ2P4wdG2mXHPPrr792OWx8uPdMpN977z23\n4lMEBPbHaC9tnvBo/vUxCW3cpLFt+5XcNbI/Idreeust5xGQlxByihBfAvf17bffdgb9w2Ostg+C\nsZoV/JMmTnLXJPeSOpK6EG+xEp4ISI4pPBR8uE8YV6nHFen5qKLB/TjQiqoff/KJ8/qU83Iv+loj\nLZxy8skmUWg3iDu+GIfQ07BhI3dNieboI+/N0UcfZb78+ivz888/Rz5n3Hr//ffdGHbaaadm64WF\nl6EmTZq40KPfjv4u0uYpu+QsEq8bfyJNP6HdZzffIGWlT9Bvfhj7g/P6lXMRkm3RoqxFgf3338+N\nCYTwE+GKco/5YUyG0JlpL4E73Fi1Y8d/oRl/mfmL+dsKiRnqw74k4t1E+9m6dYtfYHOobdOMG4QW\n9K+bY2H4iGcM8p9vaXklf3ZCozzf4ORTTnH35dlevd198a/DHysSITI+bf+vTWJgxxtW6t6HPJl8\nBy8aynD++RfEPD6edk32bZKpjVKPQ4YMse1+W9xtlDEF48MPP/wQdZ/mBzW3faq6GfJWRo8+6oaN\nukXg43QiEFF/P/ww1kydOsWkimnTp7t+IVB3hECk78gCi+3krXIewsUibYZxLp7cFPR5xkjCRROC\nj/FrN/vs5F4l02AbfP6x6OOAA/bP8PyrVDFNxPrTGibiXQyDF+gm297oP3hBAzn6vv9+jAst7cOK\n5WLFipuFdizwj08bYj6AeDTAGhn9cgbnA4zrv9jtyCOPcLlmCT1coUL5LMct8raSf5VcZIRV9Pfn\nfEvt+C4sXbosQxl4/tEf8PijDVJ2ntd9+vbN8Gz3iTavffuddxKe1/qQk5R5zbDhw52oJpBD7dNP\nPzOKokSnMHlCIMoQog9vWPUGSx3UMaGEeQbxrqciWJoAI55gqSDtvXhzhrxhct7szovoIyy0I5wl\nghjCZkEh6OEloSPFY07CJvq/+6ElsxNeUsm/qEeYoihZoR5h+QCMf4SDaNP2Yrd6lRd3XtbxpOrU\nqaMzjLC6tm7dvawx8ktz9z33WDFnLzP7119dHofddkss58Ghhx5m+vcfYG655VZz+umnu+O3bdvG\nlYNJQZuLLjS33na72/fCCy/I8niEJyKfE8ZFPDVYSbzKGgK/sYYrQo91tNew++67m/wCXkr7WiM4\n4f5uvLGbE/4wkBA2ilBFO3bGNm7hBYA4yAtW2TJlTM2aNayB6uyY3kAYRAn/RB42Qvt8YY3KnPOu\nu+6Mef/OPuss88UXXzjvqHNbnWeFgaOdIW3B/AVmim0zb701xDSM4bHgw8rrB3o+YA47/HC38ptc\nbKO+/daJV7JCv+9zfc3knyc7Txvylqyyhm7OjecGXlmAsQtxA8P4TTd1d4bCedYo+8UXX7prwWgu\nUE/XXnO1NSw/Zq7s3MUcf9xxzjtw+T/LXaisk0852XS/6SZn1H/8iSetkfNoFzJq06bNLnzj6tVr\nXJ9g4sr+jz3+hJvsz5g+Lc9yv5UuXcZdC+Gj6DNc97x5f5grr7jCec3EC8bV7rb+CAHVzdYBL460\nrf/Nn+9ebF4f0N95qHzy6afmlltvNS1btnQG9k8/+TQ0BCii9ddff2Nutf2a9ohh8oILzs+0H5P9\n22+/3Xk7kAeHNoYgi3CNwZw2xpYolK3txe1c6Cz6Fx6NeMpRP4TkTDRhLePS9ddf50K/dux0hcsF\nVL36bmbGjOnOk5FjZjdkJnVw/HHHO/H7s88+c6vt9kzPw4i4Q45EvOK4vyOsQXi1Fd3otzOtWIGB\ntlix7L8o7b/ffk7MmmgFUF6QMR7ggTEbcTWOFzCEgLFjx7kQfhjja9ao4bzUyM2B54eAWI03E/v2\ne7WfFf72tULlUvPLLzOdsdp/PyDHDs8UckoNeOMN06BefVPVipiHHnKIE0URZ/BOpA/WqV3bbLPC\n5j/WKM49v/fee2P2Rdohx21tRSVEEbxgaKcl7Xfk+QZH2/aL9x0iD+3oEHtuxjqEZryTn3zyCXPc\nsYl5ih1mxyxyOyHwEtKS2h1j2/jSpUtCVwqeYsU4xIARI0a4MeeYY4+JeXzq+47b73B92G+jkyZN\ndGU+v3XruNsoYUQxJvV69pmo+xAKt2vX68xDDz1sLmrT1o0Z1apWNXN/+800PfAAc/PNN1vx43CX\n25OxmTGBtk2IPzwsFy6K3+M5EcqWLWcNJze5+UTt2nua7779zvX90047LXL9Bx6Y5tH87LPP2vHy\nd2fEIXfdX3//FcnbEA3qmX4yevRoc07LcyP7kycQoRZvpGQkxOb59+uvc8xBBzVzz64li5e4kH/+\n84/zMM6PGTPG3Hf//a7fNGhQP2bIQfooYhRecVdddY0Ltcp9GWP7VaVKFTJdK+MDdeMf/2TbD2+7\n9RY79o03zzzzrPnpp59cyFKE+99/n2eWL//HPhs+cc8VPuc4993f07z8Sr9I2CTmYXj9E+4zmrEH\nj4l27dub7rYtERq5UcMGbh7w+2+/u9Cc71qRitDZ5A6tY+cI++27n/ManfHLL24xDONyrVo1zRor\nfg156207Rqwwbdu0cfsESea81gdjXruLLzYvvfyyfcZ1cHXHvIGxPrthMxWlqFEYjIiE6GNOx5hQ\n0DxcCgI8x6hjoH6LugAGfk6w9evXm1Qji8RExMlJmEQBwZh7iRDG3KtXr14ZPPkLAv71+6EPlcKN\nHxrRJ+wzRVGKNiqE5QN2rVzZPPLIw85D6C1rOMDIup81lt7QtatbnQsYZJ+zxjwMYAgQQGivntZo\n8ef//nQrgAUXrtAaK6tWqxp6vlOt+HDjDTeYoVa4eqVfP2e0btXq3IjL+Mnp3iCs1CeEXlYQDume\nu+9yYfwwlpJ/hs8aWUNy5ys7m+OP/y83lAvRU2fPUMNXlSq7unLHCvkT7do4X20rRO2a7l3gg/Gw\nfPlykd/T6rKvefjhR8xPP//swmdVtcbEyy6/1FSxRi7yeETydtmHJuGE9vCS3+PlQqJ47sWIkSNN\nKTvpbHbQQU4Io2x4MQUftT2tQWrCxAlObMMToXKlyuaWHj2ceBIh5FxcV19rHB14yCDnVfX556xm\n3sWUKVvG1uvxodcrUNeUR+oaDyTy42BMxGDFhJCy3nffvebSDh3cPie0aOFW8+EtJOEEuI8977/P\nCWByXIy1jz32mJloxRNWjxOq6haXA6qYCyMlYQyZdLRt29Z5keEhQF2zco3jIng1tSIkIEa6ePLf\n2bJ9M8pN5DHaPfTgA5HcRBgg+YzriRUmEZGI6/bF16pVq7nPyD3iQ/3utVftiFeKD+0mLBfPdddd\n41bfY6zbuGGjqWyNpOSV8e8lbSzYHqUMvmiAx9PgNwc5LxhCZVI/CASs/Ic21oD4txUChr/3vnnt\ntf5ONDj11FNdDrebund3hmChfbt2zkvkq6++dnXdyNYvhnnamguH6IUta978IPPSSy86wzshvzBK\nU1ZC6HW1445fv5Xs53Xq1M6Um4V76Iu/CAgYi8eOHetEHtoXRsf27duZq7p0ySDSBKlUKe0c5LHx\nwZvhzUEDTZ++z7k2izcJ96rzlVe6XDR+KLbda+zu6jzeiS5tltCNtPVf5/zqQujtYsfe+nvXc3l+\n6uxWx1xxRSfnzck1kXembt29bT1fbN63QoOEGgSMvByvePHML1nUCx4eAvfwCms4+MiOHQhECxb8\n5cQiROFyVlD49rvvInoY50RY8c9FeLTrrr3W5bDCiwwv1l2rVjGXXnqpWWLbpXieEo601bmtzLat\n29Ovb4GrO1Z5MsZ8+NGIDCHZMBzT3ufMmWvm2u2QQw62QtjBrrzk/CFcLqHGEPCpY9rDUbb9hl2z\nQL8/6qgj3erSZ555xi2W4Lu1au1hHn3kkcjzDWgvPXve70LAElaHsTLNo62kW2xRL92A5fKSBfp3\n5J5aQZe/ycsuY9YzTz9levfp656vPFsQZB6w53naignBfo9oxniFRzahXCsG2myZMmVdG/P7XYsW\nx2dqo1Xt/bj9tludoOq3UcIkliwR/nybPXuWG+MQr2LRyRoouH+v9HvVeVwD7Y9Qt3D3XXe524rH\n8yzbPnimISg3atjI3HvffRnG5vB63MU944K5zYDwfM5DPNDHWrdu5e41z87Rtkzl7POWXJM8EwRy\nuNx15x1m4MBB5k17LxgjyV/2oB3jX3rplQw5TTkWYgplwZt00KBBztsUb8qGVpihTWD8mTdvnnnl\nlVecCNTLCmxyTYQPDcK9529hYVAFnn88zz78cETk+Ud+xi72WuT5B0899aR9bt5vPsO7yJ7zCivo\nsniEkIo7dlTLdFyujfC2PXs+YKZNn2qmWzGfOiZvXYXyFexY8FGGOcN9VlzesmVrhuMzL+NekT/z\naduXxtv7y7OaOkKow0jFs4UwjG+8MdAdn3xbeNZyLSwqYf/u3W92Xm0YucKeDXgpv//ecPOMrc/J\nk6eYyVMmu/Grhj13+/PbuX1o03ibsVjl558nu/7GOMGCKMZMntFz5851YvkRRx5pqlWvHlrf0ea1\nzHl+nvxz6Lw2+AwHwmTWduEQ//usR4+b7XmrOeFu2LDhziPu1FNOtW21tbnOjvuMtYqiZKYwraJH\nnOG5yvtFMhZLKGkgLvL+QMhJ5nfkX1P+g3cqPNlzmhMsHpj3bE7Puet7NeXU8E+fYS7OPcajkgVi\nLJRRMTl1ULe8ixYVTyaEVkJy+ohXYnYJtnupSxVBFUUJskuJGqcldbTduuQLU1jIDbfaHrfc4nKS\nDBv6rvNUYhUtnjoYRsMmMJRHQhoi3uQEwtWwWolQiWU9QwjGhzPOPMsa8dqbx63YkQiIHEyQMYrE\nMnznF6QOMDAl+pBMy8+20n2PexF2vxCdrux8lenT+1nnpcNklXvMKv5Ez8e9JxwcdUz78A2HiRwj\nLV75epefiuMERaU0o9lqt9Icg1a0tgh4ymyx1xTv6m2OuXbtOidMcuzgcfGQoXwY2jBSB+sIbzPa\nVlYeBKlg4qRJVoC6yNx++21OQMEQS9vh5ToZ+cs4HsbKihUrRLxkBOqNe4aBPStPOFeHdkPYKhsQ\nlsKgvxKmazdrrEzGaqm061jtDLgY4ZORH8m1fdsu6D/0nWzX9/yPQz/GY5P6RXiizhAzhB2EqrT1\nSW5Bf5xMBoQh3LBxkxNcsjNJp65lPIhOWnJtVqcimPjXlmlPQrmsX+fGtopWcAvWMy/19E8xfGe6\nD3XPMbGgv1DmaOOlD885QqwR8rNMDuuda+d4XH88fSI75KSN8t1DDzvcCcmvvPxS3N+jrzM2MFYG\nnweMs5s2bcyRZ01W4L2D+HHOOee4uYI8ExF/o41ThLhdvfrf0DKHwQKByy7v6ER9Fv74YyN1ffY5\nLc2SJYvNL1ZUTgZcA2Mix6ZfhT2nQEJ28jdEp3jGTnn+0merZjEHSMvrtjzq8WWuxfhKu5b29ro1\nWiE6cz+Yc/jfGztunOnYsZPpYOd28eTKod9wP+kzFULGKPoyZWDxya6B+4lI1tnOfV7t97LztMyq\nXpI1rw3CfeIaeE7nlRd5vGgoHyU/IOHIMVIyrmheLcWHBTh4gYlQosLIf0hYQua6awJ5yFMJz2rm\nAjyreQ6zcERC/iUDnvOE7iaUNcIFOZ8LEnguMp8Sz/7chvpjYx4SS5AvakIYkZUQWP3fqZ/sCmE8\ns1jQeeedd0baflpI9l1y7CWpKEreU7Jm1g46iaAeYfmMSiHhY3wYxJNlKMB4EgxXw8vPe++/7yZQ\nl7RvbxKFiVh+CoOYFWF1EC/UUaJGRiaou2VDwALufeUYHmDxHgPjXizDOftkNVkTKsc0wGcGI2ZQ\n5PHB2BZLQE2lUTdRMM6XSaIwEut4WdWbT1Z1GCTZq2STXS/g2n6CbS0R8DKI1rfI75PTfheNkiVL\nmcolsy8UxlfXu7jQdfHoP9QzAlg00rxIs18XiArxitiIKckCo0Cqn0s5aaN48a36d5XzNkyEWH0d\nQZ0tN4nnmYiXaCL3Ag9EDEoHN2+eaQzEVEAo4zKlkzfecA0IT1lBX0j0eSTP33j3jXX8aHMtFjLh\n7YQHXvClf5MVxLm+0nHWF/0GL8BolHGhoWuG/m3WrNkuxCMhTrMimfPaINyn6lE80hRFCUcNhkoQ\nDPkYmjFWI4BpGMRw/FzDuQXPORbHYPT3814lKxwc74kIYIRMJKoEopiGGo0f+gziMd51BU1ETCVE\nMvBDbn77bXJywMtiDvoAP0UMUxRF8VEhTHHMnv2ryx8zbtw4F56x1bnnunB1iqIoiqKkDsJd9nul\nX5ZhEYsijfbZx4ktg95804kl1apVdy+5ixYtdOFF5/0+z9x0UzejpEHOrg8/+NCFHCSvJMIzHqHk\nPhs2fLgTtwiFnWrOOvMMFzZUw5EpSv4Bzwhy/iBixDI6ptojAcMwRnQE+1SA1xJjT6qOX9QgDKJ4\nAhFiV8f1cOg3eKSEhdVPJQhfeIXhyc7/RQhLphgGErYOIQxBDGFMPUaV/IaEBxV8YUxRFEVQISyP\nca667n95u1LhhRdfcDlZSpYq6XLDkLdDyTlpD2MTMxyZUjCQCVTxYjkPg6goiiKQ4+mUk08yBQ1m\nLTzjiqfw5ZIcpnfddadbSXvb7Xe6HJu80OIdRi6xxx971Fxw4YVGSaNNm4tcrsBPP/3MjPhopJt/\nsBoWsbVp06bmqSefyJDvLFU0aNDAKIpSMAkaEpMJYhy5+hBTJCRqso+PkT5Vxy9KUJd4sgDCqQqL\n0RHxGDEqrxARjhDPiGGpMv6TEw5PHjwEEdbVQzAzeFCSWw3oR8A8VnL7QqtWrTJ4RPmwL2EDOQ4C\nZKz8bByTsJWch3GPYwY9zzge6TrI6cd947gImS1atHC/811+D/NY848PHJ+yxyoPZZ86dWrU8iQK\nZRePurC2xuIKNkK1+/Ac47sfffSRmTZtmvss2nX65fevl3GPelMPSEUpXGiOsBjkRrx+VtastBP1\n/ffbL+nhxBLhjz9sOVaucGEC69ev71YNKzmHHCJzf/vNNGncOKmhvpTch3w8M375xU2EakUJB6Xk\nc6LkCFOSRBY5wpTCRW6OiRg0Fy1abNavX+fmShXsXKVmjRpxh4wtSmD8WrZsmVm6dJnZsmWzqyNC\nMuJZp3O7/IvmCFNSTTweYbmRIwwDcd26dZ1BPRWk+viFHYzkeIFheMYArPWYNdJveO/HOyu34Zxs\neIHzzGeeJGESUxkWjjbCWMGYEkusyUvyIkeYCPIQLUdYsG9JjjA+o175ne+JwIU3ZrB+qXu8NcUD\nln3Z+D9jvJxPQjPyOZ+JIMf/OSbf4Vx8xxea5HtyfPZB4OI77Jvd8oTBsWirYTnCOC92tGjPLuqa\na7rnnntcjjBZzPHoo4+ahx56KFN5OFeYd2uw/P71Eg5UFwMoSt6R7Bxh6qaSx/BCcsjBB+epCAb1\n69dzE4TGVrBRQ0nyINfIUUceqSJYIYBcPNxLFcEURVFyd0zkGUrOqcMPP9x5NtW3cycVwcJhBTii\nV7NmTc1hhx1m621/U6dOHZ3bKYqSL+jVq1dKxZVUH78wgzG5efPmzviLwVnrMT4QwmTLCxC88AQT\njzC23CgL3jUiKCBG4Emj/BdGko3xCAgpKZ+xRetbLPzi79QrPxEYRZz2QaBCtMHjiv3or7I//Te4\nP+C9x358DygD50HkATy5BP7POTg+ZeJ77Mv1+N6iOSlPvNC+EMEYn6gLH8rie9oJgwcPdiJYs2bN\nzB9//JGhPHwnWB6OESy/f73i4acoSuFAQyMqiqIoiqIoiqIoSiFADKcYIPk/K9kJZxULDIEYM2XV\nvHg0xNrfDyEVLeQUIat8Aytg2BQDcbzHjxaSKxnHjxXCS0KJcTy+Q73GE7KsIMH1cJ3UpYa6yx6S\nIywvYAGMCGB4pokIlswcYdGQvoaHE2MGYwhtSEPJZQ/qzwexSvqmP6bxmdS979mEmMMYhfAW9OiV\n/fCYBblH8tMXmfxxN1iesDYlwlJYebimsPIkAt+V8dc/johgwTFr0KBB7uf777+fqTw8L4Llkevl\nOP7+cr1BAU5RlIKNCmGKoiiKoiiKoiiKUgjAIC05WhDBMEQGDaw+fkgoVtAD+4tnUFYhpCTHDJ8F\nQ06RmyV4bgyvsYQqVt9jqPRDVGGQ5LNgSK7sHD8Y8ovrlDwzGPH98mNolbrk/HJuvs/+BT1/FoZl\n7hsiYFi4MCU+8jq0LQKYbBKqEU+x3EK8oOgjeBXSX1MRWrWoQX8U4UqQkImINrJwwYfxSLynstuf\nWXTAuCDeYzwXZJxD9AyWhzHSDz/oQwQsyiNhCbMD18rxgwIWzyKOyd9FiKY8Y8aMcWXmnAsWLMhw\nLOpE6lDKg+DHc8d/Dka7XkVRCj4qhCmKoihFA81hpSiKoihKIQbDIEZJhA0RkwChKix0mR/SasCA\nAS6nIMd48803IyGtfMOjv78vGvEZ32PzRSi+638/K0MoBlPKzfElZBfwGYZKRCw/T0yix6d8kv+K\nYwoivmH8DBrwMZoiemHol+uV8nA8v5wFBT+8WUEX8/KS/JTb0Q/RmFd5JxHA6Lv0CwQQza2UfBiX\ngbEyLCygkBMhTPJotW7d2j07QDxnGTv9eyreUpQrK0/inMC5ec5wzRIqkXGM5xD51aTNr1692u3P\nIomTTz456vF8IUzysDEmBq+XZ6l6ySpK4UJzhCmKoiiKoiiKoihKAUc8nWRluyAr+4NEC7GFMVC8\noHxihcAS77OcECsklwhkOYHyYfwMXpdcD5+HhcHCoB8MmcXvYpQuKEgYRLx28PpQESw5YIAnRGFe\nsHXr1gzhEOVnqsMiRoP+hTiBoIyQgrgQ9BJSso+MQ4gz9N9oW07DU4oYxgIA7idjL+MnY0dYzq9U\nlwcBjmuXBR3yU0SqYJvHq+ubb76JWp7guEf5JJeYXC9iG+JeTnKcKYqS/1CPMEVRFEVRFEVRFEUp\nwEhYKgyD8RgdgyG2MABiTOT/hFULhtiSEFjRjo8RMae5VCRHSzwhuRJFPAiiiWmIfwhh7BNmJA1S\nuXJlU5Dg+hEluDYM3JrHKXlggKfPEJIwt/EFAH7mlQAWhP4k3mGICRKCU8kZfk6vVHkqSX5JGeu5\nl2yImwhh3EsZjxmvZVFAKj2nOAdlQIyTnI387o9j9AVCSTI24yXWokULJ1Bn1Sf8fJr+9fIskOul\n7WroWEUpHKhHmKIoiqIoiqIoiqIUYESEilfg8ENsYag+6aSTXCgpwiJibJSwW3LcrEQujITJ8kIQ\noydGyCpVqjgBJ1neV9E8oMTISUitwgT3jfpjw9MB7zYVwZKDb2AvUSJv1phv3rzZlQODf155pUVD\nvE0RyRET8BArit5hyfQcpU4RnCR0bRA8pWKFTIwHES+Dx2HckEURfnkQPMXbNAjHILRsMsCLVcYz\n2lFQWJX+eOmll7r9HnzwwUwimOSE9KEeJbemD9creSoVRSk8qEeYoiiKoiiKoiiKohRgEl2t7ofY\nYqW/5BfCkIpBXYyMuS2aiBiGoRMj6ujRo53hEnEOj62ceoZlZdTEo6CwgIFXvBlEYFRSAx5hecGW\nLVvcucXzJT95hQn0aTxOaYuI24QWDebiK4wgEEn+QfoeYws5rPh/TrzjELQRbqhHyQnJuDZixAg3\nTjKm58Q7izGWMRfBiXPgmct4zLOBn8ExmHvJWM395e8IViDlQUzyPXE5Nn8TJK+X5C2EsNxccl18\nnzYV7RrvvvtuM3LkSCeE4Rkm5+ZZIrkg/fKEXa/Up3ie6dipKIUH9QgrpDBgt2t/SYYVN3/88YeZ\nN29eXIlTFy5caGbOnGlSAcfufNVVpl+/V012WL58ubmycxfz5puDTSpYtWqVnVBMc/G242X79u1m\nxowZZtmyZaawM3PmLHPZ5R3NyI8/ibnfihUrXJ3kRYiI/MyLL71srriys2vHwqzZs82Cv/4yijGT\nJ082F7drb74ZNcooiqIoiqIo8SEhquL1BgiG2JINY60YGX1Do3gDRPNuELEqJ3BsKb+EqMLoKyJO\ntFxn8SCeYNHK75+3oIMNAEM59wRvHDHEK8lHhKeSJUvmuhiGvQI7BCKYL4bFEw4uL6D/ishdr169\nQu8dRp9j/GJM4dpFaMmpx5bks5JQgfR1vO3o74hS/C0nMO7LmEt5Ob545XL8YI7FYHkoS6zy4HXL\nfrLxDGLzP0PACkMErGhCKrZOyv311187MQ3xTsrDccPK44eLlev1y49Xo6IohQcVwgopK1auNOPG\njo0IM7jM33vv/aZzly5xiTW33nabE9I2bNhgks2atWvNhPHjzR9//mGyw7Zt28z48RPM7F9nm1TQ\nv39/c0mHDu4c8TJnzlzTsdMV5tlne7nJaGFm+fJ/zLhx483SpUti7vfGGwNNpyuuNHPnzjXKf8ya\nNdOMnzDetWNYsnSp6WL75UMPPWQUOz6sWWPG2rFrwYIFRlEURVEURYkPjH8Y9MSTyifM8OqH2MKw\nKR5hQliILQydGCz5mw/nxPMhLFRXIiQSkitR5Ho5dvD4Umfx5lfLr0h4Mrxu8MrA4BstFKSSPER8\nKlWqlMlN1q9f785LWEYRwvKrCCbQvxCHEBhEYCnMghjCDd5wCC38ZNE11+/D9UdbrC75G4NIPXI8\n/9jBxQLsw7FlXGMM53ff45ffg2UScYhjMo5EO36s8ogXYFCE9z2Qo23RPObw3uLvXIeP1J+0fRZ0\nYNdbae2iWZVHys91htWnLiJQlMKFhkYsIjAp23ffxqZipQoZJkYDBgwwc+b+Zh55+KEMca2bNNnX\nbN26zZQqXdoUNRo12sc03mefhB54FSpWMI0aNjT1G9TPs7AI+Y3adWrbumxoKlSoYJTolCtb1jRs\n0NA0qN/AKIqiKIqiKEp2YeW6rGbHUEiIJ1bWB1fwCxJiCxELQeyyyy5zhtcxY8a4n0GvMAyYrJLn\n2OyP2MLqfo7P/uSf8kk0BJYcPxiSi2OEheRK9PhcLyIR9YOBk+NLuCzx3iioIORx3b53g5I7iACF\nVxgLkHMjIgqLbzdt2mTKlCnj7Di+GJYfwyMGYQyhX0p+JgnhWVhJlSAtCyBShSwgyC/liQbtHTFM\n2r78n/KQZzJe8qr8iqLkHiqEFRF4CNx5551u1VDFihXdZ0zQPhzxkalZs0am/W+/7VY3uSpRBEWd\nc89taSdjJ0TqKR7q1K5t+vV7xZRX0SfChRdcYM4844yE6rEoUqlSJfP888+ZslYQUxRFURRFUZTs\nggGPVe0IPSJ+YdhDYELsCiKr4PEiImyUeHrJd4Kr//mc/SXvjZwDQykiUtBgKiGwgvif+d+h/KzE\np/wIYf55w8qT6PEl/5gIbf4+iIgFUTzCC4z7gRAWdg+U1CKCEz8RoliAjECVSrDjEGYf8QvxjU3E\nsPzuEeZDf6PfIXCLJyj9XEXcgoGITf7vkBftT7wyKQP9g74QLJ+iKAqoEJbHDBo0yPz119+mfft2\n5u233zGTfpzkPt9///3NtddcY2pbgcWHwXzIkLfM92PGuJxfNWvWNC2OP95cdtmlpnQW3lu9+/Rx\nq+R63HyzC3n40MMPmxkzfjGLFi401113vXtIHN/ieHNJ+/bmxZdecvnEnn/uuQzH+PXXX03/Aa+b\n3377zYlqtWvvac5tea59WTnPlY38UR98+KHdb7ZZvmKF2a16dXPiCSeadu0uNuXKlTOJQt08/8IL\nZvbs2W6Cd/DBzU2rc8+1k8zMUT1JFPv2O++Y0d+NNouXLHFxp9vb8x5zzDGZHoCscnz//Q/M3N/m\nWsFvhxOyLulwiTmhRQvz6aefmi+++NLccENX06hRI7f/3Lm/mZdffsnu/7ub2NaosbtpflBz07Zt\nG1OnTh2zaNEi8/Qzz5hDDz3U1Z+AmEgus+/HfG/mz19g6u61lzniiMPNlVdemcED75NPPjGjR39v\nbr31FjNs2HDz1VdfmXW2fuvZSWAbe46T7MSQB3s0xo0fb9vSm+b+++41b9gX2O+/H2O22vrYZ599\nTNeu15smTZqY1+0L4Scff+JCU+69d13T7uKLzUknnRSpG8r688+TzYiPPjK///67WblyhalVs5a5\nwApa55xzdkxPNyYbTz75lHtx7dz5SnPYYYeZTz/7zHxnX5Rvu/12U2P33V3Iu0ceecQcb9vrbrvt\nZl5+pZ9boVq5ciW3f2dbJ3wuEPP8/ffft8f53Pz9999m18qVTdVq1Uyx9PK2tILlOWefHVoeXOBZ\nHTp+wgT73YXuheSQgw92ZatVq1Zkv2eefdZUr1bdnHnmGaZP3+fs9f9sytt22q9fP1OtWlW3z/D3\n3nP34/ff57l7ffLJJ5kOl1yS5aSK8rvvfvmVWWjbR4P69U3Lli3t9zLex3Xr1pmHHnrYtddrr73G\nfUbYxHfeedd88eWXrm0hkjVoUN+cesqp5qyzzoy0hY0bN9r7OtBMmDDeLFy4yFStWtVd5zXXXO36\n47P2+ho2bJhpdd2MX34xr7z8irnqqi6madOm7jNeovsPGGAmTpjoXqyo6yZNGpvzW5/v+h1k1Q+E\nr77+2tX/b3a/6nYMOO64Y01HWwZWLPr8YssxwI4nM2fNMjVr1DDHHnusqV+/nlEURVEURVGyh4hJ\neGwhIIlR2Rd+fCSkFfNGvoeIVM3OA6PlYGF/PL+YO3IOfo9muOYY0Y4TDRGrUnl8xDyOj5eZX0dB\nYuXayQ/h3PCmQRxESJCcPkreIHm6sFnwLidh8FMB79XAuXjPFSFMPMIKGvQ/CVvHOzE/E+3XSu7h\nh3EU70dfdAoToFItSPmhfcUjTFEUJQwVwvKYadOnm88//8K8b18mittJywEHHOBEnMGDhzgxZsjg\nwaZx433cvggVHTt2Mt+NHm2NzrXNAfsfYP6yAsGDDz1kvrQGczySorn98iCYMH6iWfrPUnP9ddeZ\npUuXmrVr19mJkn1IGB5g9mFV7L+H2sSJE82PP/6Y4RjfjBrlBDMEpwMPPNAZ3SdOnOT+D2utwHLL\nLbeYeVagO9ga4xvWb2Cm2JcXBJ4Ff/1let5/X0IPwCW2Hi5q08aV9ZBDDrET+8pOGPnggw9dGXwQ\nE2699TbzsRWU9ttvX2eUH2/FoU8/+9Q89MADpkOHDpFzv2wFgEcefdSJC4gAfPztd9+ZU089xf0d\nke+LL75w4iRC2Jy5c82FF7Yx1NTRRx9tilkRbvbsX82kST9aw/0x7lyIS4glvhiJSHGtra9Rtt4I\nm9igYQMnJCASfGwFqXfffSciDnLODz78wEyfMcMJnAhDFStVMqO//958Peob85x9yTk7iugDf9n6\nRUxDWFpohc3DrCC3Zu0aM/Ljj921HWPLzc8jjjjCeWghlH1vj/2qFXxaWPFP6vum7t2diMT3GzZs\nZO/vBPe9EiWKRz0/beY+O1EdOHCQufTSDk4MhLlz5tpr/cZcd/31TggjTMTX34wyE229rVyx0uyx\n5x5OpPndXvuLL75kJk+eYl4f0D8SSvGRRx41A+xL+dFHH2XOOON097L5mRXFmORfdOGFpmqVqlHr\nAzGwd+8+7viIOYiQ/V591UydNtW8YY9JHUifsFMmM3jIEHf8ffdtYqpVr+ZeJuCuu+42b9o+SIzp\nAw7Y3913PkOYfdSKetFABLvnnnvNW2+/bfawwhthVxYuWmi6WQNE8AUVQYm+1dxzwb/3vvvcGLDv\nvvuaprZ/IUwxHqz+d7W9D2e5fVZYoZm8dBgIKB8b9/+70d/ZfnqtE6q/taIwgmowyMTSpcvMZ59/\nbs5tda5BBuNFrfX55zuxD+H4gAMPMAsW/OVE9z332MMJYfH0A+jTp68VFfs6A0rz5ge5un/00ced\n6OUL66z469zlKjd5Pv7448y2rdvShEkrnCmKoiiKoig5I9HwThISKt4wUomGzIoXP6RVKr2bCnII\nLN5bJPyj5gHLe8QbRfJ1IU7xjpOKEImIYLw/YnfgPLKJEFYQwiJGAwGMkIl4qCKI0bbVOyzv8UUl\n8bjy83kF8b0Sg+0xlW2TsogQHEuUUxSlaKNCWD6AyQwG+/6vveqMwAzWL1mx5qmnnrYCwYvmmWee\ndhMbvJ0QwS6wBuunnnoyYqx/4oknzAtWSCAZJEJUPDBZftoe48yzzrIi08HmxRdeyOChFAThCcM+\nIsUbrw+IiF98LhM8Qrz16vWs2d2KHhjB4Z9//jFt2l7sBB2EoUS8wvpaozkCwKOPPuK8l4Dfr7ji\nSjPFimM+eHF98ulnpkvnzuaOO253k8HFixebCy68yHnCnXzyyWYPa9BHJHr1tddsfTcwg9980+y5\n557u+5Qt2vV/Y8WcDRvWm2FD33UCH3CPltlrq1Y1uhiDZxfG/i5dOpt77r7bPYCpqyeeeNJ53CHI\n3XzzfyFKNm3a7FYmfm7Fu/r167vP8FzrctXVTqg5y96rrB7iy5YtteX92uy2W5qY8PjjtI0XnWfR\nm4MGRl4mv7b7dLL1+OGIEREhjLp46cUX3LklnCECXfv2l5gRH400p59+emgd4QmGCHbBBeebh60o\nm1UZWe3FdXe9vqvz7GMi3/WGG6yQ+LWZYYXAo446ynlBEbYTEez1AQMiYQO739zDDB8+3FxvxbU9\n9qgV9Rx4H51x+hlO2KI8CFM33tjN1cMcK9AdeughkX0RfRs0aODqnZ/CrFmznAh2+umn2Xp50fU3\njnPllZ3NCFu29u3aO3EsjB9/+snlLEAU7PfKK+5+0GaGDh1mbr/jDlO2XPQwiOz37rtDnfj7wfvv\nReoTL86NGzdF2tFrtr9Pt0J6V1sXPXrcHHH/RxTm/iGExQseYohgeJLdfdddkc9JECtJn+PpB9QZ\ngiO5FxjPMDAg4DN20IbbXdzOCm1Hu/I/9PAjToB7660h5mh7z4Hr6ejldFAURVEURVFyj9xaRR80\nrMb6u29QLerwrogXGCEp8ZiJ5uWn5A0IUbRd3n94d8RWkqw+xfsT0X1YXMr7GUKYiGHiESZiXEFG\nPFTxTCVc4nnnnec8HlUQy338tkubpj1jD+En7/G+0CsibNA7UTwlwW+bqRjPffEr+JmiKIpQsJ+S\nhQhCtoknBIP1FZ06WqN8PScg4aEDhEpjonPvvfdERDDo0qWLWzEz1AovGMtTwdixY114uvPOaxUR\nwYDy+OHO8GAREQwIddf0wAPM2jVpk7ZEGD78PdPQChN4/wjUEd4uPjyM33r7HRem8YorOkUM94TA\nI0/VsmX/OPED8NpatmyZue3WWyMiGCC0+HXqs/vuu7kHPYKJhDjgHuHlFEs8fMcKl5UqVXSr9eQB\nzMMf0YJjvh4Szx7PNRHB4KCDmpt6e9ezgsS/TuDICry2RAST3+Hwww7LsKISoYL6woPIB88lP6cX\nZdlrr73MihXLM3nhwWtWVCR0JbnAnnn66bgm3rSJyy+7LBLekvZz1plnuokUIQQBEXPTpo1mv/32\ny5A7q/E+aaEqCdsZC7wV8QyUeufetjihhWsry+21+FBmxFZfBIOPrPgHPe1LprQNfhK+EPH6Jyt2\nRePLL74wm2x7v/qqLpH7QVlatjzH1KhRw8SC/agj7g0ehAIisoRr5Px4kiLuXn31VZF2yHezk5Ot\nenqfxQtUkowDK4LLly/v/h9PP6DOKNutt/SIeL4x8e3Q4RInlEt4GTzq5s6d60RGEcEAj9iW57Q0\niqIoiqIoSu4iK+dTKYb5XgTM/SWEHHN0tuD/xavG90IoqrDAknc4okGwsFBFsPyFeL5IeEQRqaJ5\nzSQCdhQWGPOT4/L+LBu/FxYRzAfPMAlhiiAm+QuV3IVxl0XjLJBlwyblL4YXEMoYs9mXSFHYBLBN\nsi/tlr+xD1sy+kQYGg5RUZR4UI+wfACG/jq162T4jElN0wObmmHDh7uHDV5WeOdgrPeFJsDA3KRx\nE5cnCJEnFatlODfgpRILHnx4Mf0yc6YLtcfDb8qUqS704o4EHkw8ZDnWPo0bZxKbGtvPfDDcr7FC\nGw9cQh76+/OSAPMXpAk+C/762/0kRGC8MPHipePRxx53Xkrt27VzgmDlypWjfgdvHHKk4ekXDC/C\nhPjg5gebz61YQplFuKDc5IHyKVOmtCltt3Xr1roXwqzYp9E+GX5HiIP6geNyLgSODRs2ZvictjbK\nTjgJa0hb4joQnfa2QmtwYjFu7Dgzdtw4J1Y9//xzMXOI+SCoBMMDSl1u2rgxvdyV3QvEvHl/uMmT\niJsLFixwP2N5gwFlxTtpnC0fYTkJKfi/dNGPyZcPIQX3bdIk0zH+TI/7/8STT2b4/N9/04QiwpJG\n4w/b7hDjuP8+iFl7WgFyzew1Jha3WCHp5pt7mNOtwEhYSHJ8HWnb7H/eYRudME1OrWTkAiCsIe2a\nUI5HHX2MuezSS80ll7TPkPcrnn4gdYbX5ZC33op8vm7deuf5J3VGKE84qFnGMC68vJEfUVEURVEU\nRcldJOpAKlbQ+wIYc3vZonkV8K7ie7lI6Lng+0ZRWO2PENC9e3cnhOEpk8pwkUrOEDFM7BHS5kUI\nSFSs4nu8n2MHoO37nmC+R1hBzQ2WFeIdRihQ3kXpA3hCqndYapF2S7tD0ApbEJ0VjOu8/9OGsW3S\nJ2SDeG1HieB7D/v5whRFUXzUIywfUKp0KSd2BKmUbmDm4YMohKiE6BWEh0m5cmXNVju5WrNmrUkF\nK1akeaXFysv08+TJ5oQTTzJXdu7iwsLhiVWyZCmTHRDCoEKF8pn+xoPU9xJab+tl/foNbnK5ZMlS\ns/DvhZGtlD0/+a6qpotRrKSCWCJWEIRHwih263ajK9c9995rjrZiAfmroolTiHNbtmy15SxnSoQ8\n5CvvmnZ+38uLl71dEyhXGLtWCRdFypUrn9VXXf6to4851nTteoP57PPPzIqVK1xdF4/i9UauM9ok\nIulMK3zGS/Xqu2W5D6ErCYtIfrXru3Y1/fsPcOH1hg57z5x00omZvLd86C/knjrjzLNM7z59najn\nv5AEqWLrLMwbECEX/PbEtt7eM9oUub/CYNJH/j3aaJmyZUOuP+scWHhBfjxypDnzzDOd51fbtheb\ni63wJMIuIQqZWFaNM4dDpjKmr8Tyefzxx8zLL73ovDoJp9nihBPNnXfdFUnGHE8/kDpbsnhJhjpb\nbV/gmzVtava2oiP888/y9LqolqlsVatm75oURVEURVGUnJFso6EvgDF3Jcct0U6y8ipgXxYM8k7F\nwrww8SxVXgX5CcIgEvmFhXtTpkxREawA4IeDk+g5bLxv0r5p22ziDenD7wgHvH/xvoUIShvn+yyo\nZCEr75juPdN+5otghdngj/DFezD9gIWZ5BBTUoN43zLuMlZnRwQLHg9bJhttW8Zw+kIqcuj5Aliq\nPZwVRSmYqEdYPoAXgdX/rs7wGQP2okULnfG+StWqbrLD5GepNTQHEz5ihF65aqWbCMVjZM8OtWrV\ndD8XLV4U+nceak8/9bQry+uvDzAnn3RS5MFz1VVXm59+/tkkAqHh+L4IYj54w2zc+J8nU2UrDlas\nUMGKW5VcHizymEVDPInwdqpVK7ZXkQ+C3C09erh8TF9++aV58aWX7QTsQXeuNhddlGl/BMtSpUqa\nlfZljzphtZYPof+4vqpejjHuaE4nsNn9NmH4Hnr44UgOOMkBxST94nbtQ79D3jVCeF5zzbXmuuu7\nmveGD3Oh+rIsYxzXyD533nGHmTplqpk1a7ZZunSZ86zr0aO7PWfsHFL9+r3qcqCRm+3WW26JiKbE\nGSf0X8jZOGGmT+vUqe1ylr399luZ7l8seBEhHCKedBsDoUrpDyuWr4jrOM2aNXU525YuXepyBr77\n7rvmmmuvc/XMfapUsZJZvGRx1ASwfozs4D4IwkERl78TSpNtwsSJ5iXbxgnHutVOVp9++mm3T1b9\ngDqbNn2aee65vhlCfAbZc8+0drJ4ydJMf1uRHgpWURRFURRFKbgk26tAQsCJt5jvXVPYRADCH+IF\nBoSHI7+3UjCQ9y7xePFTJPCZ5Fhik1BxwbCf4gGJ/YeftHfZsPlIH/BFsKLg+dKzZ08XMpG+gUBM\n31DvsOQhIhiLEBLJNx4PsoCB9i4hQ/30Dslqv/5xOEdh9JRUFCVn6KiQD9i+bbsZP35chs8I44YI\nwAO+QnqOnuOOOy7tczsx9iHM2I8//uTEI8LOxUsJ5wWzixWVNmW5UoLcPTxUyLEVDC0HhD4jBB2e\nPCKCSdkW/LXAJArhAjGWI4KwEspn4qSJGX5HdCKEG2H0YuVtgsb77OPK9v4HH5h48euGlVfnnnuu\neeKJx015OzGdPm166HcQBg488AAzZ+5clwvJZ+HChe5+kf8sEYElleC9hzh31JFHRkQwQMxBiAnj\n2GOPMccff7xbkcV3b7jhBveimiyGv/eeWbturXnt1X7moxEfmoFvvG6uveaamHXGi8WcuXNc+8Gr\nSkQwPAYTFWObHnigO96IER+ZRGnSZF/XbhGUfKjLv+LoD36bI6fYvffcbU6xwuOiRYuc1xXX1cD2\ntdmzfzW///576DF4caKullkR0V9tyAR04qRJMc9PGMY+vXu50I4TJk7KtOI2Wj+gzhjPPvhwRMwx\nBY8+XtwIb+GPJ5Rt/LhxmfbHeMKEXFEURVEURUkdyfKyEoMq0SOS5VUgnjS+Z1gq883kBbw/8G5F\nGLhWrVqpCFYAEaO+iGG+Z5h4c+HZxSZeXv7vwc+wK8j/+a6ERBQhrKiIYALC1wfWlkOIRPoJoljQ\nXqRkD8ZRBLBki2ACzwTJGSZ5IJM5hocdRz3CFEUJokJYPqHfq6+ZTz791CxfvtwatueZRx551Cxd\ntsy0Pu+8iNfQlVd0MiVLlTQ9etxiJk+e4vZFGLvjjjvdS8Z1110bNfxbGHhSMaGaNm2aC7XAS0o0\nYzPiCMbx0aO/N6+/8YbLT4RBfpI1qI/54Qfn/UQes7lzf3NeN5Tt119/Nb1797E/55jsgOcPQtpT\nTz3tRDa8WHgZ6NWrV4bJHqs8una93v283dbFx5984sqGaEBZXnjhxcjD/NRTT3XG/ZdffsWJYeyD\niENes6DAKPA3PGPYDw81hKyxY8e6UJR16+4VtfwdL+/o7seDDz3s6oI6mTNnjrmx201mk334E2Iu\nv4AnIYLrJFtfUtaptl0888yz9noXxfzuRRddaC684AL73Z/M03b/ZE020jz/Npk3Bw8xg9580wwe\nPNi89/77Zvr0GW7yFAb1XbNGTeeJ9c03o1wIPtrCgAEDzKhR35lEuMBeE56Gjz72mBk6bJirB4Qs\n2jOhGiVfWRitz2vlBNrevXubb63YQ30SzgFvNUTHrHjwoYfMZNsn8Vykzc2aPdtMnzHDlC1X1o0H\nHPvitm3cpP9hO1ZwzygboutXX33t6oeXptq1a5sfrTiMmEcZaO8DBrxuvv76qwznI+56n759zW9W\nVFu+PC1kDfnVFtp+vvfedV1/i6cfUGeErOjfv795+ZV+rv9Srt9++93VGeMDsM9JVjCnf/a1511s\n79ESu9+gQYPMF19mLBvX8uCDD5mzzznHCeOKoiiKoihK8klWThUxRkpow2SGv5KwiUQHCYbYKugG\nTxaIEfaNd1LeG2666SajFFz8vHbiycUmkX7YfJGL/7OxoFM+l/34jnzf9wQr7CERY4FnGLYh3ofp\nNwMHDjRK9mEMRZxKlQgmSM48EcM4b7LG76AorPnBFEUJQ0Mj5gPIvUPOoRtv7OYM3OQg2mnH7HOs\n4bddu4sjA/hRRx1l7r/3Pic2tLICWc2aNZ3BmtVFN95wgzn7rLMixwwO+ZHEkd5fEA06drzcPPLo\no6bDpZeZ3awYcuxxx5rH7O/sFxSbHn30EXPrrbdZke4x8+STT7kJGGEdr7nmGnPsMceYc1ue40Sf\niy9uZ3avUcP9rXbtPU3Lli2dwTxRLrnkEicGvDt0qBNAypQp7Tx7Tj/9NDNjxi8Z9mXy89hjj9rt\ncSsIXu8mjLJycK+99jIXXniBm0wysbz//vuceNi9+82mDN5F9jo3bd5k7r377rQVd4EH5pw5c80T\nTz7p6gOxb7M95jo7QTji8MNdDqdo4DF19113mmd79Tann3Gm+y5iHmW7sWtXVy/eDTIxyeZD/L+E\noaF/jbSGvfaqY+/bxVaQfdWc26qVC8e5bs0607hJY3PkkYebrVu2xixLz573m19m/mJetd8/7NBD\n7D06PdIIdwmec5eYBXY/eLnFw5H8ZB988L5tf8UjybWZMLWzZX344YcyCb9cb5s2F5nR34+2/eQZ\nJ6wgOuK11KpVSzN06LBIebKaGNEv+/btY+7v+YC59bbbXL45Vt/xQk8IyGPs/Y0GK9Ue6NnT9Hzg\nAdvHOpldd93VTvC2O++uk04+yUwYPyFDmdOrJgLC22uv9XdlYExYYsWnsvYa7rj9togwjkfWH3/8\nYQYPecu1L/ajz+3TeB/TtFlTU8O2N/o3IvfNPXq4cI3UX/HiJUyrc1s5jzs5JR5XL774khPudt+9\nhqtrBCyEtB72uxBPP6C8eJLdedfd5vEnHrci9lOuvZO7kLCKBxx4QOQa77v3Hif09en7nBPXt2/f\n4W5/+/bt3LVL6+R+I37+b/4CK6TNMfvtt69RFEVRFEVRkouEtc+pQZLvMydNtVeBnAsQB5Il5OU2\nGPI7derkBLDXX39d84AVMvzQiLRT2i92FN8Txg9lLz9F5JKfvveXhntLg3du+gx9p3Xr1k5MxlNM\nwyUmhoydLHZNRd6uMBDCgm05VSESFUVRfHYpUeO0pC6d2rrkC1NYyI3kij1uucWMGvWtefutIdbA\nvsZMmTrFfb5Po0ZO+JLQbj6Eq8M7Y9k/y61hfXdzqBXR9t9vvwz7sIrs58mTzdFHH232SM+FNX78\neLN8xQpz0oknWVGonPuMCRif/zx5iv3/Nuf51eL4493xSWbMhMKHh+MPVtQipxQG6po1a5kTT2jh\nRDkemlOnTjMTJkxwq/P2qruXE/jKli1nvh/zvTn9tNPc9bA6EC+ZWvY7hx12WKzqcS9QlIWwh3jD\nHXjAgS530oQJE53h/1AruvjgrYKXGuXbxT5UMeofcnBzl6/If8iy38SJk5xXzw57j/eqU8e+dLRw\nIsOMX35xdXz8cce53xE+Jk6c6IQAPO8QNZhcHXPM0ZF8ZLGuCS8wvOZW2rqrY4WFA/bf3xx44IEZ\n9gmeU6D9jRs33vy7+l8XchLRM4y//v7b1TuiBMKfQHnxNKQ9NWvWLPI5Ew8miqWssHNi+ssW94xj\nTJ4y1RS3dYUn0BFHHOHu+XxbT7QLJu94FnFP9t13P9PECmUCogxtDo+s46ygOnPmTPOHbYfS3ijL\nN6NGmd2twMVxfaibb775xoXg3LdJE/PU0087z6VOnTra87Yw5a2IsnPHTif8Pv/88y7k4McjR7q2\nEAb3H+/FZf+k5YLj2hvYNvDd6NEuPKbkr6LtI662aJF2bWEg1tDeCPG5ZfMWU7VaVduuD7PX3yTL\nlxDqhLazZMlSlz+refOD7UtMMdvPp5lTTz3FeeHxIv+1vfaKFSq6eoPZv/5qfvrxJydG2deiNOHN\n9uXgpJ7+O8VO/H+ZMcPVTYWKlWwf2d+1QREJCZ04zl4nZSDcaLOmTdNiqtv7f4jt79TPtm3bXVhR\nxEz6fTnbZ+tYcZR7Tm42iKcfCLzQ0w/n2evHs2/XXSu78yJYS7x8Oeb334+xZfzNVLft4mD7d7zF\n8GpjX9ogfPHll2bmLzOtWNs2rjx0iqIoilKQyI13DkXJCjGAkoeH+RoG5USQNszclnlpqg2qnE/C\nxEneJBELCgp9+vRx9d2tWzfnAcb8Wim8SB/xPWB8IQyCHi1+HjwVwGJDX/L7FFFPsF1gL1OiI2Fs\neTfPLbAlioekH+ozO22ccLLYsu68884MYjFbIhGzFEXJn5SsebpJJiqExSC3hDBCuA0b+q5pZMUK\nRSnqMAk78cSTnQjy+usDnEeRzzvvvus8E/u98nJMjzxFURRFUZSCgAphSn5A8no9+OCDzoCYHSGM\n7xMBIyyndLIRoQ1DKosFxZBaEMQwPFjIbQSE/dc8YEULf7z3PcF8NMRb9kD8wsOSn3iLsWBThbDo\nyLjNYljEqdxCQtpi62H8lrCf2Qn36QthICFJOY4KYYpS8Em2EKZLShRFyVe4lUAlipsVK1e4kHoC\nEyXy5g0bNsxNaFQ4VhRFURRFUZS8RzxaCG+eGyIYYOzkXBI6XULN5VZor+xA1ASMtieeeKJp1aqV\ny3GkIljRQ7xWfC8vP+dXcFPih4gl9CuEfPKG0efYlHD89BO5CTYfCXPLuWXszsmiIBGVg/9XFEXx\nUXlcUZR8Ba7xl3a4xLzySj9zSYcOLlxeqdKlnCg2ZfJks8G+YHe78UbTsGFDoyiKoiiKoihKcsiu\ndyLfw4iZqrxg0UA4IOQ7i+QkNCKf5UcjKGHp8VQhBxhpDDQMoiKo91fy6dixo+trr732munSpYsL\nl3j55Zcb5T9kAYPkXMyL8yOC4QmGR5d4cmV3/Jbv+Ln1VBBTFCWICmF5TOPGjc3atetM+fLljaIo\naXTp3Nk0PfBAM3bcODN3zlyzY+cOU6NGTdOxk53QtjjBNGhQ3yiKoiiKoiiKkvfIyn6MmbkJRlMM\nqZzbF8LyUy4lvFEQwAiHSKi2E9LzMyuKknrOO+88c8opp7g+iBiNp1gw73ZRBqGIxQR5AeM0zwy8\nefnJGM6zJKfhDP2ce4qiKEFUCMtjrurSxW2KovwHq4KOPfZYtymKoiiKoiiKknpysno+t0NrBc8t\nBlXxKIC89gTo06eP80Tp1q2bE8HUC0xRch/xwqQvEpb0pptucn1SSSOvRCMEL0Q4yRcmoRH5mYzF\nDOoNpihKGJojTFEURVEURVEURVGKMGIMTdQoKqvvN23aZPIChC9EMBHCxKCal+D9hcH9ww8/NFOm\nTHEGeBXBFCVvoR+SP+yNN94w9erVM//73/9MUYexO7c9eQXJ8yj5HWVLhnilApiiKNFQIUxRFEVR\nFEVRFEVRlIQNiLKCP6+8CkQI8w2qUq7chjCIDzzwgBPBWrVq5YzuGoZNUaLDeBPcBg4caFIF/RFx\nmhCJ9FP6a1ElP4QQlDIwhvseYTktV14vhlAUJf+iQpiiKIqiKIqiKIqiKAkbIDFc57VXAUZPMaTm\nlUcY+YeaN2/uvEwIw0b4NUVRYtOxY8fIlpv58zgfQjX9Fe+wVIpv+Zn8IISxgMEnO95c8p38EhZX\nUZT8i+YIUxRFURRFURRFUZQijBgOs+MRltfGVPEgSHZ4rXjAC6xTp04uHCJ5wHLTmK8oBR36jEDI\nQgTl3ALvMM5PCNPu3bu7c+MpVlS8OGWMlMUEuQ25Hf3z+uN3ojnCfAFMRTBFUWKhHmGKoiiKoiiK\noiiKUsTJTn4wyGvDo4TTChpVU02fPn2cN0mzZs1cuDUVwRSl4HHeeec5L866deu6cIlFxTtMxkjC\ny+YFjNe+cJUsESs/LM5QFCX/oh5hiqIoiqIoiqIoilKEya4XlRgc89KrQJAwjakG7y88SAABTPOA\nKYUNPB1p4+S6mzZtmvOWop3jMTVixAj3+6677hrqQcXf2Id+AgcddJDp1q1b0voJZUOs4jz8X8qV\n0+P37NnThUxEDOP/RSXHH0KYP47mFps3b86QG07IaWhE9QpTFCUW6hGmKIqiKIqiKIqiKEWYYI6V\nRL+X114FkGoRTMQBDOUIBEXFUK4UPWjrhCqkvRM6kFxa/E4ePEQi+Z2woD4PPPCA6x/8Tejdu3fS\n8nBxXspADj7+D5wrWcenP+MdhrDGdXA9hRXGTRYwlCiRN/4RiG+c39+yK2D5IXFlQYQKYoqihKFC\nmKIoiqIoiqIoiqIUcbIrgkFeGVPxKgDJKeOXKZnCGN4nGOARCDCUY4hXlMIO3lx4PbLhAQa0fwkF\nKl5ZgDCFSCZiEkIxG//nu8noM4hTnIfjUgY5Pufk+FKWnIJnGMfmXIhsiIGFFcbu3F7IgAi2bds2\nd15fBMuJcCUCmIhgGiJRUZQwVAhTFEVRFEVRFEVRFCXbhsi88ggTrwLKTRnEyyFZngAYwlu3bu08\nX15//XW3iSCgKIUdaev8rFy5svspn4k3pIhPfE7/+OCDDzL0EfYjDxf7iRdXdiDcIt9HpPLz8Ulo\nRAmZmCw4LtfDsfGMYwzISfnzIzJulipVyuQm69atc+f1t5x6hYF6gCmKkhWaI0xRFEVRFEVRFEVR\nlGx5hUl4LYyZ27dvN7mFeBVgxJXzi2eYlC0n9OnTx3m4kN9IBTBFiQ39A5EKyA8mOcIgGQIS3meA\nl5r8P4h/zmTBNbExFkj+sMsvv9wUBkR8YvzMrTyPPCM2bdpkypYt68bskiVLJs0rLIgKY4qiBFEh\nTFEURVEURVEURVGKMCKA5cQjDEFq48aNJrdYv359Jo8CEeZyAsZ0PECA8GuaB0xR4gOBSjynfO+x\nZIQslGPkVVhSBDAEMcQw8p7h+VbQxwYRnhDCSpcunfLxG6Htn3/+cedjQwST8TsVopWESVQURRFU\nCFMURVEURVEURVGUIo7kVUn0O3npVVCmTJkM3mA5Ca2Fof2BBx4wb7zxhguHpnnAFCV+EL8QiRCH\nyK/lhy9EHKNfJQO8M6MJUKkWpiT/GUIY14owxlhREJHx3h+/2fCyTRVr165152XRBMIbQpicN6di\nmC96aW4wRVGioUKYoiiKoiiKoiiKohRhsiOC+d8VQyoGTgSqVCJeBeKFJsZU3yssUcSTpVWrVs7Q\nrWEQFSUxyOEFeE75IliyEJFr9erVKTl+IiCSk/cM4bxevXpOnMvrMmUH3yOMcZXxlJ+pWMywZs0a\ns2HDBrd4gfP4YpiIYNkVwoLfVS8wRVGikbOYAYqiKIqiKIqiKIqiFHhysopexDAxaqYS36tAxDc2\n36MgXkMoXiytW7d2IhjGbDw9VARTlOwTzAfG79FyeiWC5OWijwbPgTcnOf2SEYIxXhDmGDPwCGP8\nkJCQBQ1fDGP8ZkumkISotmrVKhfKVkQwBDB/EUMqcoNpWERFUcJQjzBFURRFURRFURRFKcLkVARj\nQ4gSYWrz5s254lXgexQkmmsGwzlGdQzsGLRVAFOU7IM3Jd5gbAhCLVq0MNOmTcsQEjEoVCEeCSIi\nsb8IZ/TJXr16uf8jPCE64YVFWEK8spo1axY5B7n96tat6zy1chPCI3JOCZfI9YtoV1BgEQPPAMkV\nxv+3bNmSYzGJ54Dcc8Zsjs1PGb9z6skrBJ9fEvJRxTBFUYKoEKYoiqIoiqIoiqIoRZichEaU70t4\nRIQpjoURNFm5WhDVCInGMTGmyhYMjRgPGMy7d+/u/k8uo1TnFVKUooB4SNG3EKbYELK6devm+i5C\n0ejRo81BBx0U+U5Y3jDfe4xjihAGiEx8hhjm5/AjLGEwL1luwnVSNkQxxDCuK1Yus/yEnyuMcZT/\nM7YC4y05wySPWLzwvXXr1jkxjfHZD4UoWyq8wVT0UhQlK1QIUxRFURRFURRFUZQiTk6MiGLMxFiK\nwRMQrzCIyt+zi+9VIEbUsmXLRv7vi2CxzsMxMKBjpMazxDekK4ryHwg4QRE7GPYPoYfNB88oNsRm\nOY54WvqClnjqZEcoR2xiozz0aY6fXwQnykGOQUS/5s2buzGGsSa/I+OmiGF+iFnGXwQt8fDl7/5P\nQCxjYz/5P8dinA4KYRJ+ke8nKrBlVX7K6B9PhTFFUYKoEKYoiqIoiqIoiqIoRZychpHyDZASYgty\n4lVAPjC+i9AlRlQJsSUiWDxeBXiZEIaN8G0YqjUMoqKkDt/ryxe9RPgKG2v83+MZh/KztxUCGIIg\nwnu9evWcYJhX3mrxInUuiwoQrhivJeTt1q1b3VgsYW/Ztm/fHvm+3FMRwPieL3oFvXclJGIykLbl\newVTlqAwpiiKokKYoiiKoiiKoiiKohRhfAN1TvBDJPq/i1cBP/kszKsAoyrGVvEq4P8YNhG+fK8C\n2XyvgmhCGF4jCGD8LAjGaEUpDPjjCP+nb4cJYcFcTtKX5feC7NEjoSLxQGUMYuzBOyw/C3hS37K4\nQBYviKjFuMwCBH5yTxGa5L76XsEinsnPYB7HnOYEi1Z2X2CVtqUoiuKjQpiiKIqiKIqiKIqiFHGS\nYXj2vQrkeL5xFHHLF7vEswDESO4bXsVwKsIXP8WwmpUI1qdPHxei7PLLLzcffPCBeoEpSorxhS76\nNf082N8FGSN8LyHp+yLAFAZBjDCO4h1G/jByiTEm5Vf8MVzGV1ncIPdQhE1fCAN/f1/48u+piFPJ\nvqc59WhWFKVooEKYouQBxLImPMf8+fNN5cqV3aog2RRFURRFURRFUXITCSOVrGOBn28m6FUgHgW+\nV4H/fTGSB70KgmG1wozkvGdhdIZvv/1W37EUJRfwRbBNmzaZdevWOREsGhJWj7EAJL+gL3JLXy/o\n3j2I8ORI69atmxPDPvzwQ/d7QfAOk7GWcZr/y3gdFMHkHvmLH2Qs9z9PlVglwqn8VBRFCUOFsHwA\nYRqCiUfDIM6yrmIr+LAykVVAkvBZYJWivqTlDJlUEXaAl94wSNzLizH7MBFN9vHzK7Q3SVpcUMcS\n+gfisSQhDkPuL9cXTN6cjOMrOYP7Exz7wtDnnaIoiqLkLskKjSj4YphvDBUxzBfBggKc71Xge4j4\n3gVhBlXmGMwDCUVGCDLy9CiKknpEEEH4WrNmjfMASxTGAQQ0wqcSDlXy//kiWGEIl8h7Jvag5s2b\nuzGKsSq/IvXt3wNfCAN5ZgRDWgY9glNdTt8jTH5XFEUJokJYPmDgwIHuQZgVmtS34MNLmf9CJl5g\nvLTpvc0diM+NMZ5VWC1atMiQyDe3EQGce5/q+49RgNAwsGrVKlNY6d69u1sFDAiWeRl2Ijfvb0GB\nsCCIjVmhzztFURRFyV1SYTj0jahsEupQDKjBHDPB7/meYb44Fs0LjHl+q1atdB6hKLmI9N8NGzaY\ntWvX5tizlGNt3LjR9X3yUXE8P3RiKvJL5TbY/wiZyDt6vXr13KLovLRLZIVf3+KhJz8h6InlC1K5\nQTA3mOYHUxQlGiqEKUougugpMNnBKKzkLs2aNXNCGAJkXr4gI5Iw6QUmwYl6LyUKwh/Q5gqzYQDj\nB4YQrhGhMy+R+1sQPQjzEhUOFUVRFCVvSJXR0vcOE2Mpxu1gCKswMSzoCRIsI3NqBDB+Mp9m3qUo\nSu4gogMCGKEQkwlCOR5i/CRkIptQGMQw7BGMWSyWbt26tRu78A4rCFGCgl5ifo6wvEKeKcbkvhCn\nKErBQSXyfAbGUplMBLeC8EBUYiPh1riXKoLlDUw0uQ9TpkwpMn0K4U+8kxCKCjN4XHJ/2XTMzH/Q\nDsOeb/79KuxiraIoiqLkR4JeWcnGN0xK7i8/7xc//U3+LuJZmOGbkPPk22HxE3N7FcEUJfeQ8QIB\nLNkimIC4QahEQi2yiRepf/6CDotisQPy/sN45i+ezs/443Feh6z0vY99NDyioihB1COsgEIoPUKA\nAaG/cKPmRUDyr8hqkuB3/H0wOvLdaC8MCAYjRoyI7MvxCK22evXqDCHH8DRhPwiuYGF1HlC+YD6m\nsPJgpA8KRHJ8STAaVq4wg3c818vf2AeihVGTa4DseO1Q3tGjR7v/U3dSNv+4YefGYMwkyC8/dRjN\nZV6OJ3XIdeEZI2EX8UDLCfHeL4Fzc5/8vFTsH2xv1A11BNxf9ue6uf5Y95fjB/eLBiEHwvLwxbqf\niRw/7Hqj9S9pz36eJAnlIkSr1+A9ZZ94Qv9JG+c7TLTD4Jhcb7zHD7vesHLHur+cg3oNa9OJ1L/f\nx3w4XzRBRfp+oveX/aX9h/Vb/3r9c2XV30HahtRNrPoP9kf257jcg4IoAFK/0kfzc5x8RVEURSms\n5GZOleBq/URX7zNvYH4PGJB18ZOi5A3kBFu/fr1JNYRKlPEJzzA/TGphgDGMd1fsPYhhjHEFxTss\nPxDNI009whRFyUSJGqftTOZWmDBuPE09PXv2dOdisxP5uL7z559/Rr7D9+0DMvI7mzUsZ9h/ypQp\nO62hNMM+/vdjlUk2ziHHsMb0uMovn1sDbabyBMss20033RS1LPwtuD9loj6yc72rVq2K7MdPfvex\nQknke/41JwLfCyuHvwWPbQ3pCd0v8I/F/Q/WUU6IVZ/B+wVh7Sda+YN1HPadYLsKO75fvmB74/ew\n40bDCr4JHT/W9cZqz/HWEe07eE/9vh5st0Gkr0Vrwxw/Wn8M+04i1xvP/bUibYbv8Hus+qGsPtGO\nGxwXsnv8sPYQrX786433O9y/aG2UsiQyvvF5sD4Thf6W1ZZVm0sUaX9W/NupKIpS1Ig1J1GU3GL7\n9u07t23btvPee++N+r6R1zD/YK7JfIc5l6IoecOOHTvceLF48eKdf//9d8q3v/76y23Lly/fuXbt\n2p2bNm1yYxbliAbvUD/++OPOgogVwdw4l1/H4vwEdXTPPffstILszg0bNuy0ounOLVu2uPYZq30o\nilIwSLZupaER8xnz5893q+KDWyxItBncx185wt+IOSweKIQOY7WJ7MP3ffdrVp/wGeBlwP7yu+/F\nkl2kPFLmYHnwOovmDo6nhZRH9hfPiLDr9cvvXy/X6F+fHCd4XvF0g+x6KeDRgecRm3in8FM+Y/O9\nPig/ZYqn/GFQR+KlI+Q08Wqw/fjl4X5J/inw2w/nxRONa4yn/BxHju97UsmKT6B+5Ph+eWKFUsOz\nBk8otqxWVUn9x3t8vzxyvWx+/fjXi8cO9UGbF7hWvz0EwxdS/3JPuRZJrgu+V2MYvqdNtLCIrDqT\nfTiu3x9pT9Hqn33CrtdvDz5+//U904LlF29XKY/f3sIgHE689zfR4/vtwb9e6VNckz9u+PdSYN9o\n/V3KI22E7/v1I3kvfKQ/SnlYCS3ji3ib5mSspj1ktQXHmJxAHUr7C3oOK4qiKIqSO+T3lfPMlZo3\nbx4JqRwtyoGiKKmHfoiXFqEKcwPGJytsuDCJeKFxXradKQ7pmlfwPki4V8krnpVNUMmIeoIpihIV\n9QiLjjG57xEWbQt6xPgeYWysGPFX6Pv/949vDdwZ9hGvAt/Dxfeu8Ffa4YVgQjwaEvUI8z0m/PKA\neL34+/vHpwxh5fc9OPzj++X368z3WolWD/7+QQ+g7FK3bt1QjxMf3+stWP6wcgp+e7DG5AxtIJpn\nTDxEu19+vfntAW8Ufmfz75cVRyLHwcMm7PjBlZ2+t57ge+f45Yn3fvntO9HrDTs+bT7sevlc9g9b\nyeWXN5a3oX+c4H5yLWHejMF9orW5WMcPa29co1yv39/98cHvX359BuvB94KS8vvtxC9PtP4e7XpN\nFI+wRI/PMeR6fU+reO5fPO3RP07QG8ofC+Ra/HYY5n0nZc2Jx1ZWz6OwsT4niDdYrPuqKIpSmIk2\nJ1GU3EQ8PO6777585YXAHIi5FPOEZM4/FEXJHowVeGMtXbo0V7zBZJs/f74bD5YsWbJzzZo1zvMn\nltdPQfYI8+Edj/GPd7yc2HUKK2EeYVYsVY8wRSkkJFu30hxhhQDxaPDxvVd87yc8E3zvFPndX90v\nq02C+YRiedwkgu89ESyPnCOax5BfBv5fuXLlTJ4PvheXX37xnhBPCv847CeeO9RFsFzx5GFKFnIv\ngvVPmaVcsTzC8CjhWnxyElt62rRpGY4tiFebeK4JeCyx8TnlJGcS//dXMUXzVgmWU67X399vq34+\nqmTFz/ZzTQWvNwz2YQtebzK8J8Fvz5wnrL9I/UbLtSXfDcO/3mA7p79IvipBvJs4J/cCbx48Wf3r\njff++r9LO/Lvr1+eaP09URI9PmUMu95k4d/faOMhcJ8oC5/xk/tCP6dckhdMvOJyys5cXFXpe4Np\nbjBFURRFyTt4/udmnrB4IGoA8x3mbHjAK4qS9zBGiGdWblK8eHHnBcZ52fg9P41XqYL3O97lidJC\nZA5sf7lpnypo8ByzAlimfGGKoiigQlg+ww+55RNLhMpKACB0BGAw5cEZhm/8lf2TJXxFKw9EKw9g\nHM2OuBHLUO4LJz5MJEQ8wjDNPZBwcGJgzi1i1X8w5GVY/SRLEBJ84SDYNqPVJy+tTNCSJQb5+IJa\nsq81SLwhJVN5vf4xY7XDsHP7YRGjTZZj1Wc08awg31+/zPEeP7fub3BBQzQwBEk4S4QkNpCxivCC\nqRq/k40sjMjtcVZRFEVRlIxgNMytMGdZwRxW3sWY96R6zq8oSmJs2bLF5AUIHCKElSxZ0v2O8MH4\nVZjD4cniTN7/eA9kjGQRoY6NGdmZHiqzsLcHRVGyjwph+QxZ7Z+qY0cTLvKCrMqTm4ZcBA/xtkEQ\nI+dQfvRS8I3muVU/YV47sZA8UMD9xSjPMajbYK6j3ChPTkj0emlHtBd+yiQ1mVCf0coT9rkvMkQT\ntRKtP+5jKq831e060eP7OcL86wXitSeTWPe3bt26kf9zPxHMycWGcI9YzSb527hHOVk1Hc9LA8eP\n1qbixfduzemxFEVRFEXJGfnBs4K5NwIY82ty1uoiGUXJXzBOID7hEZYXIHCQK0xyhLEVJc8feQ/k\nnY+cibynalSN/5D3WPFwVhRFCaJCWBGAB6SELkOUyMrLRfbHqBqPEOD/PR6PCYzlvNywL14qyTaA\n+uHFJMyhIEIM5wx6yDCBkDB83bt3d5/lhZeC1E9Y/Yt3loRIyw184Ynz+/eLidfq1atdHdO2wA/1\nxgusfD9ZAm+wPpLdfhI9vh86klVa8XqRxYt/PMoi9SzE6qPxiAzNmjWL/F/C7wkYIiQ0IvcS/Pub\niuv1zx8sTzIICzcYCz+UK3WQnfYWa1z0BS4R2oLf9cvM/ZD7KmFI5XPGNxGXgmNffsSvW32BUxRF\nUZS8Ja8Nhyzw4R2MkM8YeguKd7uiFEXySjgvUaKEE+EQwxDkxAOoqIEQhp2KMZPFmeo5mxEJ86ti\nmKIoQTRoahHAN5y3bt06YkSVFXc8OP1wZL6hlwerCDKEBwvDN6RjJJf8SCImBfEFKDHcSnk4B+Xx\nw/ElCi9PYeWX1YVsYZMlyfUEcv688FLw64f75Zdf7lNulgvvOEHqEzBic7/8HD8QNNoD5feN3jkh\n2v2N1t6A+ykCgV9W+czPyxSr/YQRlhsrVn8RfDGTF39pc5zPLyPtQfZjwiv1KDnJEK7D6pa+mFVY\nRPC9kDi+fIdj87uI1mFIfrF4rjde/LJKeaT+o+XmEnEoeH/9+57V8Sl/2PH99iwiYFbtTRCRi3Jw\nj+W7wTx3fv1TDqlvyo0w7rc9EbzY/M9pT8l6+eFFKqstpyKbhHUEXuL0xU1RFEVR8p68MBxKVAHm\nViyyIjqHimCKkj8RjzCEqLwA7y/OL95gRVkM4/2J1CosKJQx1H8XVvKHp7OiKPmMEjVO25nMrTBh\n3LiZeqzx052LzRoY4/rOn3/+GfkO388K+3CM7B+28Xdh1apVO+1DNeb+1nCZ4fjR9rcvMe6nFW6y\nXR6/frhuH2todp9zfh9r7I56bPYNHkewL14Z9o22X3aJVt4g2Sl/tHuTDGLdr2B5aMPBvwe/c9NN\nN0X2ty+8Uds/7Ub+Fu3zsC3Y3rLaP3g/Ejl+8HqlzcfqLwKfx1Mev47i2d8/dlZtDXr16hX12FxP\nrPub1fX6ZbfCR9Tr989B+0jkeqPVo7/5JHL8KVOmZLre4DVbMSu0Xv2xK3gMH84RVo9+eRiXBb99\n8jd+9/tZtPLkJ/x7xvUriqIUZYLPKUXJC6xR2W333ntvXO+XyYB3L+Yw/rufoij5F8aIzZs37/z7\n77/zbJs+ffrOefPm7Vy2bNnONWvWuPJQriC8X/744487iwJcK+9XjKfBd+7CDs+re+65Z+f69et3\nbty40W1btmxxbcIKpTsVRSnYJFu3Uo+wIgKeBqywC666l5Bn/N3/LLjin8+CIdl8gq7Y7M/qlGhe\nA4mUJzvgaRCWPBRPqlhu4763SF56KUj5g6shsyp/quB+xFuffObv64fWk+vJiccf0Lb8kJUc18/d\nlFOCxweOH+aJx2d+W5ZQdvFcb7TcB8F6Zp+wnExy3VZIyHQM8UCKx3uQEJdh/THa/aV+Yl2vnDu7\ncCzJyyUw/iQrTGkix6dNBa9XjiEeXxJSNQj3JngeOaa/P79zD8PuL2Xib/5YwD2RPibecNLP+Jx7\nmZ/xvcG45vwewlFRFEVRigISSio3kKgGzBmZ1+T03U9RlNQj40NujROxyrEz3TNtZxH1BgvCeyHv\ngLy3Mp4SPaSoeYcF24K2C0VRwtgFNcwkka1LvjCFhdx8GchNMMCK0TQrQUX2ZT/+T9hCwDgbZmwV\ng38ihs1EypMdEsmrhXFW8ohhfM4PBtq8yAsWi0TKw76puq/gt89U1E2ix8/u9Uq4PDlPrHP5+0Y7\nT07acXbub1Zlzi758f5CouVJ9P7KeBhPvXJcvrN3EkMjKoqiKLlLYX3nUAoeGJYxohYvXjwl+Tv9\ncPXRFoQpipI/EaFh69atZuXKlW68yG0495o1a0z58uXdVq5cOVO6dGmXO4xxy4d3quXLl5tDDz3U\nFDUk5D4/Yy1oLwzwTCFU55133unmU2y0BcJosmmeMEUp2JSsebpJJiqExUBfSjPCRCIrIawgw/Wx\nMpEXNPGEUZSCiIgjkBd57hRFURRFiR9951DyA2LkTpUQhvcXOWzIx8s5NA+YohQ8EL8Qo1avXu1+\n5jabN28269atcwJYhQoV3M8yZco4IUxEEKEoC2HA9TPmYhvIi6hCuUWYEIYAJmKYCmGKUrBJthBW\nwiiKYqpUqZIhVBkrFBWloKKh5hRFURRFUZRESFWIMYyxEqaLhZS6SEtRCjaICwhPeSGEbdmyJSJ0\n+MJXUART0qKYECoRD9wTTzzRnHfeeaHpNwob2hYURYmF5ghTijwIYCKCSa4jFRIURVEURVEURSkq\n+AblZEFoLgywLVq0MH/++aeKYIpSwJHxIRiGMLdACJOQd+rtEx+SbxybFxGQBg4caAoj+SWHnaIo\n+Rv1CFPihhUlhfGhgvglYRARwDRMh6IoiqIoiqIoRYlkGhG/++47F5JL3rM0j6miFA5kfMAjDCEq\nN/OE4YG2fft2U6pUqQweYSqGZQ1jMB65jM146PIT77DCNDZrO1AUJR7UI0xRTFoeJTYVwRRFURRF\nURRFKWokw4iIxwECWOvWrZ2RVUUwRSlcSFhCttKlS5vcZP369ZHcTwhxbPxfBZD4weaFd27dunWd\nty5eu4UJhFq/PWjbUBQliAphiqIoiqIoiqIoilLEyYl3xYcffujCbmGIxNBKPhpFUQonkieMn7kB\nnmAbN2505yxZsmREBAvmClPio2fPnm6hAuN2vXr1XA7HwoLv1axhEhVFCaKhERVFURRFURRFURSl\niJMdoyEGVEJt4Q1G6C3NA6YohRc/HKGIUps3bzaphPCL//zzjzuXiGC+EJZbYlxhA29dxLA33njD\neYeRS6xbt24FOkqSCKIqgCmKEg19YiiKoiiKoiiKoiiKkhCE1cKA2qJFCzNlyhQVwRSlCIDYgAjF\nRr4uRKlUsnbtWndOEcJEDBNvMCVnIIAhiLGoAa/egQMHmoKKhEbUdqEoSjTUI0xRFEVRFEVRFEVR\nlLhW0n/33XcuFxieA5oHTFGKFn6eMPEKw2uLLdmsWbPGhUQkHxmim/wUrzAVPZIDYzgevYRKZGxn\njCfPY0Eb22kLwTxhiqIoPuoRpiiKoiiKoiiKoihKTAh/iJG0devWzkiqIpiiFF0QwvAKEy+tZIKY\nsXLlSrNhw4aIAFamTBn3f98jTMMiJhdyO5LjsW7dus7bt6B4h/mCqIphiqLEQp8aiqIoiqIoiqIo\nilKEycpwiKdAvXr13H4YSjGYKopSNBGvMBHCEKr4yfiQ0/xM5BxbunSp2bp1qxO+EMDYfG8wFcBS\nS8+ePd1Ch969e7txn7CJ+Rm/3QV/Koqi+GhoREVRFEVRFEVRFEUpwmBYDgtt9j9rAO3UqZPzBvvg\ngw80D5iiKA4RwxCmEB0Qq/gMIWvbtm0Je2zxPfKB8V3JP+Z7g4nYpt5guQPevuR+fOONN5x3GLnE\n8ATO74gApmEzFUUJQ58ciqIoiqIoiqIoilKECfPkeOCBB5wBtEWLFs4gqiKYoig+IoYhUPneW5I3\nbNOmTW7DuwuBy2f79u3ub+QBIwwiYjvw/XLlypmyZctGfgZFMBU4cg8EMLzDWBSBd1h+Dpcons3y\nPFOvMEVRgqhHmKIoiqIoiqIoiqIUccS4PHXqVNO8eXOz6667ah4wRVGi4udlwotLvHD4PxsCmGwI\nYYhj4nnqixSIWwheCF0ieEkYRPnJ8UQEUyEsd+EZ8PrrrzvvMMImfvfdd847LD89G2hPtA/ND6Yo\nSizUI0xRFEVRFEVRFEVRijhimCYfGEZOFcEURckKP1+YnzNMPLrKly/vtooVK7qfFSpUcJ/Lxu+y\nj+8J5nuXsflCmJI34B1Gjsi6des6b+H85B3mi7LyU9uKoihB1CNMURRFURRFURRFUYowsoq+Q4cO\nLgRW9+7dzUEHHaRCmKIoWSKiQ1AUw5OLEIiy4Q3GWBPMRygil//T34Iih5K34BWGKIYY1rt3b5c/\nMj88K4LtQ73DFEUJoh5hiqIoiqIoiqIoilKEEWMhOWBeeeUVc+2117rwiPk5H4yiKPmLoBgmucPE\nQ0w23/MLTzDx/mI/fvId8QLzRTYl/4DwhXdYt27dnCD2//buBF6K6sz//6NexI1NjVuACzHLRGUx\ny0wiezIaFxBxMllUZDFxA0VGTYwYFo2OuIC4RMFEQDOJOI6g809AEyM6ETTxF8BEiRuCGuOCbO4s\n8u9vwdOee6ju292379b38369yu7bXV116tSpajxPP+doTsnGFg63yfxgANIQCAMAAAAAANlO7FGj\nRtn//d//2fjx45PssHXr1hkA1CYMhCkjzOf5ChcFvHzxvz345Z/RNhgKselTZpiG0VUmsX5IoaF1\nmwLaDYA0BMIAAAAAAGjBvPPaH9URrU7NRx991DZu3Jhkh6mjEwAKEWaH+aL7ige7FPgK//aFDLDm\nR9lhM2fOTOaW1A8nRowY0eDfF8oA86EQyQYDkAuBMAAAAAAAWjjvRPRFGR177723TZ482X74wx8m\nc4Y1heGvADQfaQExH/LQ5wQLM78IgDVfyg5bsmSJVVdXJ8MlNuTQut6GwmAYATEAMQJhAAAAAAC0\ncPH8Pt5JrSyNU0891RYtWmS33XZbo/zaH0BlIeBVmdq3b28TJ05MhkvUowJiDfF94UGvMBim7y8A\nCHFXAAAAAAAAO2Rv+FBleq6hEp9++mk76KCDks7NpUuXGgAAMQ2X+OKLL9rgwYOT74v6ziYOs78Y\nHhFALgTCAAAAAABAwjM1fPgyBcPC+cPGjRtnV155ZdLByVCJAIBczjvvvCQ7TFlh+jHFwoULrT6E\nQ2t6EIxgGIBYlSEv0rUBAAAAAC2J/3+wAl/qTPQMsS1btiR/H3/88datWzc788wzk47NmTNnJhkA\nAACE9N2g74hZs2YlQ+v279/fJkyYUC/fGR999FHyIw7xIRIBwBEIy4NfDwAAAAAAWiofKjH8lb06\nGvVcnZjz58+3K664Ihn6aurUqXbCCScYAACx4cOHJ98RyiTWd4bmEBs2bJiVg/9gI0QQDECMoREB\nAAAAAEBO8dxhWnzoRA2V+Mtf/tLGjBnDUIkAgJzat2+f/GhCwyUqEDZkyJBk2MS6YkhEAIUgEAYA\nAAAAAPKKg2EKhGnR8x49etiCBQvs+eefT+aBKUfHJgCgMimj+MUXX7R+/frZ4YcfXtYfUZAJBiAX\nAmEAAAAAAKBWYTBMjx4I02N1dbXdcsstdtJJJyUdm7NnzzYAAHI577zzbMmSJcmPJ/QjiqVLl1op\nwiwwMsIA5EIgDAAAAAAAFMSDYWEQLMwQu+SSS2zRokU2fvx4Gzt2rK1bt84AAEij7LCZM2fahAkT\nkqESR4wYUaes4nCYRAAIEQgDAAAAAABF8+ywcJhEvabssMWLF9umTZuS7DCGSgQA5DN8+PBk7jDN\nIzZgwICisop9OEQPghEMA5CGQBgAAAAAACha2PkYB8U6dOhgkydPth/96EfWs2dPmzZtmgEAkIuy\nw6ZOnZoExCZOnFh0dpgHwUTfRwAQ4q4AAAAAAABKEgbBfPFgmJZTTjklyQ6bMmVKnYe8AgBUPgXE\nXnzxxSS7WFnFkyZNyrmugl+++N9khAFIQyAMAAAAAADUiQfE4sCYD5X49NNP20EHHZQMeUUwDABQ\nG2WFLVmyJPnO6Nq1a97vDg+AEQQDkAuBMAAAAAAAUGe5ssP8+bhx4+yiiy6yfv365f2FPwAAouyw\nmTNn2oQJE5IfUsSZxQp6ffTRR9lH8eERASBEIAwAAAAAAJRFmBUWDpHo2WFDhw61BQsW2D333EN2\nGACgIMOHD0/mDhN9d8yePTt5Hg6LmPY3ADgCYQAAAAAAoKz8F/lhVlhVVVXyqF/4L1q0yI444oik\nQ3PevHkGAEA+nh2mgJiGTZw1a1aNjLA4IAYAIQJhAAAAAACg7DwY5tlh4ZCJek1DJd588802ZswY\nhkoEABREAbHzzjvP1qxZY4ceemg2EBZieEQAMQJhAAAAAACgXoRDJYbDJXp2WN++fW3+/Pn2xBNP\nWNeuXRkqEQCQk74jlEl899132yOPPGLHHnts8l3i/LsGAGIEwgAAAAAAQL1Sx2SYDeYZYnpUAGzO\nnDl28skn15j7BQAAN23aNDv88MPtq1/9qv3v//6vde7cucYwvATAAORTZQAAAAAAAA3AA2Iaxsof\nRUNbXXzxxUkw7Oijj7alS5fa1KlTDQDQsq1bt86GDBmSDIWoDGIfDtHFQ+8KQTEAMTLCAAAAAABA\ng/Ghq7zT0odL1PPq6mpbvHixrV69mqESAaCFmzdvXvJdcNhhh9ljjz1m3bt3z35/+DC74XeIvwcA\nMTLCAAAAAABAg/Jf6+vRs8L87w4dOtgtt9xiN910k/Xv39/Gjh1rY8aMMQBAy6AssBEjRtiSJUuS\noXN79+6dfFcoEyycdzLMBGN+MAD5ECIHAAAAAAANLu7MjH/ZP2rUqGQYrClTpiQdouoYBQBUtoUL\nFyZzgXXs2NEef/zxJAgmYRDMM8LCQBiZYADy4Q4BAAAAAAAaTfgrfn/uATENlbh8+XLba6+9ko5R\nhkoEgMqkHzsoA3j48OE2ffp0u+qqq6xNmzbZTLAw4OXfEWEwjIwwAPkQCAMAAAAAAI0qnjMsfJQr\nr7zSLrroIuvXr59NmjTJAACVw7PANm/enMwF1qdPnxpDIer7IP6e8L8JfgEoBHOEAQAAAACAJsE7\nNNW5qQ5QDZe4ZcuWpEN06NChSefod7/7XVu6dKlNnTrVunTpYgCA5klZYPpxw9y5c+3WW29N7vG6\n92uRMFvYg15h9hdBMACFIiMMAAAAAAA0KbkyxLp27WqLFy+2Qw45xAYMGJBkEQAAmp8wC8znAvMf\nPmgJ5wKLh0EkEwxAscgIAwAAAAAATUaYAeDDYqnTUx2jotfGjRuXZA4MGzbMRo4caRMmTDAAQNNX\nWxaYhAEvX4TgF4BSkREGAAAAAACapDAzLM4Q69u3ry1YsMCeeOKJJKtg5cqVBgBoujwLTJlfmgvM\ns8DCoRDje344DCLDIQIoFYEwAAAAAADQJMWdn/HQWJoj7M4777Rjjz02GSpx9uzZBgBoWpQFNnbs\nWBsyZIhdddVVydKuXbsaAbBwKEQ9ao7IOBgGAKViaEQAAAAAANCkhR2g4RBZPlyihko85ZRT7Oij\nj7alS5fa1KlTDQDQ+HRPVgCse/futnz58iQApiywOMMrDHoR/AJQbmSEAQAAAACAJi/sNI2HStRr\n1dXVyVCJq1evtq5duzJUIgA0Ms0FpmxdZYDNmTPH2rZtm2SB6UcMWtLu6R4EA4ByIhAGAAAAAACa\njbSAmA+lpWDYLbfcYmeffXYyD820adMMANCwlAWme/Dvf//7ZC6wgQMHJllgLvwRgx7jYW/JBgNQ\nbgTCAAAAAABAs5KWQRB2po4aNcoWLVpkU6ZMsREjRiTz0wAA6p9+gKAsMA1Xe//991unTp2yc4F5\nFpjft30eML9/E/wCUF8IhAEAAAAAgGbLMwrCzDDPDlu8eLHtueeeSWYCQyUCQP3RPVYBsHvuuSfJ\nAtMPEuJhENN+uODzPgJAfeJOAwAAAAAAmi3PIPDhtMIO1g4dOtjkyZPtoosusn79+iXz1QAAyktZ\nYP3797fjjjsumavRs8AUAJM4ABYOccswiAAaQpUBAAAAAAA0Y+pEVYerZxZoLhp1tvpwXEOHDrU+\nffrYMccck2QtTJgwwbp06WIAgNLpfqrhZ3Wv1TCInTt3zmaAiWeBSTiUrb9HAAxAQyEjDAAAAAAA\nNHthZoFnHYTZYV27drXly5fbQQcdlAzftXTpUgMAlMazwAYOHJiaBZZr2FqywAA0BjLCAAAAAABA\nRfEOVnW+Ou+gHTdunHXv3t0GDx5sI0eOTLLDAACFibPANB9jHACTMPDlj+H7ANCQyAgDAAAAAAAV\nJ+yM9WyEqqqq5HHQoEFJBsODDz6YZIepYxcAkF+YBeZDIWoo2ngoRL/XkgUGoKkgEAYAAAAAACpS\n2PnqHbMeFNMcYfPnz7cjjjgiCYbNmzfPAAA70o8FdJ+87bbb7K677rKzzz47yQJTEMyFgS8Phvn9\nlgAYgMZGIAwAAAAAAFQsz1CIh+ny5eKLL7Zf/epXNmbMGJs0aZIBAD42e/ZsO/zww61379722GOP\n2WGHHZZkgGkJ52UM5wQj+wtAU8McYQAAAAAAoEUIO2qVzeA0Z5iGSrziiiusa9eu9tBDDyUZYwDQ\nUq1bty6ZC2zFihX2wAMP2KGHHpoNgIVBsLQfGhAEA9DUkBEGAAAAAABahHCoxHjorurqarvlllvs\nrLPOSrIflAUBAC2RhorVjwI6duyYzAWmIJj4Dwh8mFm/f/ojQTAATRUZYQAAAAAAoMXxzlp14Prf\n6uQdPXq0DRo0yI4++mhbunSpTZgwwdq3b28AUOmUBTZ27NgkK3bOnDnWt2/fZB4wzwJToEvSssCE\nIBiApoqMMAAAAAAA0KKEmWE+XGKY3aBhERcvXmybNm1KssNWrlxpAFDJFi5cmNzv9tprr2QusD59\n+iTBLwmHlfVM2jgLjCAYgKaMjDAAAAAAANAiecetHsM5b5QZtvfee9tVV11l3bp1s549e9qkSZNs\nzJgxBgCVRFlgur/NnTvXbr311mwATPfB8B4Zzv8VBr8IgAFoDsgIAwAAAAAALVY8b1g8383QoUOT\n7LApU6bYiBEjyA4DUDE8C2zz5s32+OOPW69evZIAmAfBwozZtPsjQTAAzQWBMAAAAAAAALMawbBw\nqa6utqefftoOPPBAGzBgQDJ3GAA0Vz4X2PDhw23GjBlJ9mubNm1qZIKl/UBAC1lgAJojAmEAAAAA\nAKDFCzt20zp/9fySSy6xiy66yAYPHpwMJQYAzU2YBaa5wHr37p0Ev3x42HD4wzgbTAiCAWiOCIQB\nAAAAAABsl5YJEQ4HpqES58+fbw8++GCSHcZQiQCagzALbPr06UkWWNu2bZMgmHiAK+1HAOFcYQDQ\nHBEIAwAAAAAAiITBMB8OzDuIu3btagsWLLAjjjgiCYbNmzfPAKCp8iywFStWJFlgffr0STLAtEg4\nH1h4z/P3wkcAaI6qDAAAAAAAADtQx68PF6aOYe809nl0xo0bl3Qon3HGGbZs2TKbMGGCAUBToiyw\nWbNmJXOBDRo0KDsMosRZYJ79FS7hegDQXJERBgAAAAAAkEPYEaylqqqqxpBhffv2TYZKfP7555NM\nMYZKBNAULF26NJsFtnz5chs4cGB2GEQPhKUNgRgGxACgUhAIAwAAAAAAyCMcJtH/DjMoFAC75ZZb\n7KSTTkqGSpw9e7YBQGOZNGlSci86+eSTbc6cOdm5wOIAWPhIAAxAJWNoRAAAAAAAgAKpozieW8ez\nLC6++OKk4/mYY45JsjGmTp1qANBQlJE6ZMgQa9OmTTIXWKdOnXYYCjFcPPClYBgAVDIywgAAAAAA\nAIrk2RM+rJgvXbp0scWLF9vq1asZKhFoBLoGv/SlL1lLM23aNOvfv38SjL///vuTIJjPZyhhJmuY\nDUYQDEBLQEYYAAAAAABAEXzoMM8O86wKf71Dhw42ffp0u/HGG5OO6bFjx9qYMWMMAMpNwfYRI0Yk\nAS8FwDp37pzNWk3LAAuHQGQYRAAtBRlhAAAAAAAAJYo7mauqqrIdzaNHj7b58+fblClTko5qssMA\nlJNngR133HG2YMGCJAi2ZcuWHYZCVNaX7k1aPAOMIBiAloRAGAAAAAAAQB3EWRc+7JiW6upqe+qp\np2zPPfe0AQMGEAwDUGe6j+h+cs899yRZYAq6K/ilIJgHuHQfCu9H/roH7QGgJeGuBwAAAAAAUEfx\nsGM+944/nzx5sv3oRz+yfv362aRJkwwAShFngWkuMAXANDSi34fiOcA8EEYADEBLxRxhAAAAAAAA\nZRTOISY+V88pp5xivXv3tu9+97u2dOlSmzp1qnXp0sUAoDbhXGAPPPBAjWEQw+FZw6B8+DoAtGTc\nBQEAAAAAAMoknjMs7JDWowJfixcvtkMOOSQZ2mzhwoUGAPkoC+zwww+3gQMHJkMhduzYMQmCSTwk\nazg0azgkIgC0ZGSEAQAAAAAAlFmcFSaeuaGMjnHjxlmfPn1s2LBhNnLkSJswYYIBQMizwNasWZME\nwA477LDk/uHDIIrPBRZmhIULAICMMAAAAAAAgHqTNmSZZ2z07ds3mePniSeeSLI91OkNADJv3rzk\nvqDhVB9//HHr1q1b8roH1P1ekisDlSAYAHyMQBgAAAAAAEA9807reNiy6upqmzNnjh177LHJUImz\nZ882AC3XunXrbMiQIXbeeecl94aLL744GQZRWWBhECwMhlVVVdUIihEEA4CaCIQBAAAAAAA0gDhz\nwwNjek1DJf7617+28ePH29ixYw1Ay6M5A7t27ZrMAaYsMA2fquCXFonvH/7cEQADgHQEwgAAAAAA\nABpIPDximCXWpUuXZKjE1atXJ53hDJUItAzKAlMAfPjw4UkW2NVXX2177bVXNgsszCKNA2FhhhgA\nIB2BMAAAAAAAgAaWlhmmRUMlTp8+3c466yzr37+/TZs2zQBULmWBaS6wzZs322OPPZZkgSkA5oGt\ntCwwPfp7BMAAoHY7Ve1/1FYro02v3W8AAAAAAAConQ97pkWd377o71WrVtnRRx9tX/va12zq1KnW\nvn17A1AZlAU2adIkmzt3rt16663ZAFgYBAszvsLnQgAMQCVrdcA3rJzICAMAAAAAAGgkueYN03Nl\nhy1fvtz23HPPJGOEoRKByhBmgWkusN69e9uWLVuSAHh4T9C9oKqqKlnC+cAIggFAcaoMAAAAAAAA\njSbM/vD5gNQprteVHXLVVVdZt27drF+/fjZy5EibMGGCAWh+wiywGTNmJFlgng0qHgSLs8DEg2AA\ngOJxBwUAAAAAAGgCwvl+wnnD9NrQoUNt/vz5dtttt9mIESPIDgOambS5wOIgmAe+PCs0XAAApeMu\nCgAAAAAA0ESkZYT4sGhdunSxp59+2g466CAbMGBA0rEOoGlTFtjYsWNtyJAhNnnyZLv66qutbdu2\n2bkAw7m/4iBYGBwHAJSOoREBAAAAAACaEHV8+1xBPlyi/60hEy+++OJkqMRhw4YxVCLQhC1dujQJ\ngHXv3t3+9re/1QiAiWd6xYGvcEhEAEDdkREGAAAAAADQxITzAoVZIj5c4vHHH28LFiywBx98MBlu\njaESgaZFc4Epc1Nz/N15553Wpk2bbBAszgCLh0IkCAYA5UUgDAAAAAAAoAkKg2EeBAuHUauurk7m\nDTv22GOTDvfZs2cbgMalLDAFpxWk1lxgxx13XHYeMAmHPQ0DXwyFCAD1h0AYAAAAAABAE+cd5AqG\nac4wf1Tn+bhx4+yXv/yljR8/PslCAdA4pk2blgSlTz75ZHvggQesc+fO2WEQJVcmmB4JggFA/SEQ\nBgAAAAAA0AyE8wfFWWI9evRIhkp87rnnrGvXrgyVCDQgXW8KgN1zzz1JFtioUaOSLDDPBAsD2b4w\nFxgANBwCYQAAAAAAAM1EruESfajE6dOn21lnnZUMzcZQiUD9UxZY//79kyEQ77//fuvUqVPOIFg4\nDCJDIQJAw6kyAAAAAAAANBtxx7lnl4iGYRs9erQNHDjQjjnmmGS+ogkTJlj79u0NQPkoC2zEiBFJ\nwEsBMA2DqOc+FGI891cY+NJzAEDD4a4LAAAAAADQDHmnunesh3MOdenSxRYvXmybNm1KssMYKhEo\nnzgLLAyCpQ1h6vP5+QIAaFhkhAEAAAAAADRTYXaYgmDhcGwdOnSwyZMnW/fu3a1nz542adIkGzNm\njAEoTVoW2JYtW7Lvx0OXhnOAMQQiADQefoIAAAAAAADQjMXDr3lWmD+efPLJSXbYlClTkk58ssOA\n4uWaCywMdHn2l5Zw/r4wexMA0PAIhAEAAAAAAFSAeJhEPQ+HSnzqqafsoIMOsgEDBiRzhwGonQLH\numZuu+22JAA2atSo7DCIPh9YGPSKA18EwACg8REIAwAAAAAAqBBhdkqYGaa/laVy8cUX25VXXmmD\nBw9OhkoEkJuywDTHXu/eve3xxx9PssDCAFgY+AoDYWEwDADQ+Haq2v+orVZGm1673wAAAAAAANC4\nwg57ZbBoLiPPZFGWy5lnnpkEyWbOnJlkjAHYZt26dckwoitWrLBbb701mWdP14+unTjTKw6ECQEw\nAKibVgd8w8qJjDAAAAAAAIAKFHfYK+jlWWJdu3a1BQsW2BFHHJEM+zZv3jwDYMm1oOujY8eOSRZY\nt27dsnOBhZleYfaXsi0JggFA01VlAAAAAAAAqEjqlA+zWJw69mXcuHE2aNAg+/a3v23Lli2zCRMm\nGNASeRbYkiVLbM6cOdanT59sBmU45GicBRZeVwTBAKBpIiMMAAAAAACggsUd98peCbPDNOzb/Pnz\n7fnnn08yYTRsItCSLFy4MJkLTFlgjz32WGoQLJ4DzOfeYz4wAGj6CIQBAAAAAAC0AGE2iwfBwqES\np0+fbieddFISEJg9e7YBlU5ZYGPHjrXhw4fbjBkz7KqrrrK2bdtmMyYlDn55IJngFwA0HwTCAAAA\nAAAAWhifMywMhmnRUImLFi2y8ePHJwECBQqaI2W1aa6n5lr++hDPGaelJQY8J02alBy72reCvps3\nb06ywHr37p1kgDm/RiS8Tvw9AmEA0HwQCAMAAAAAAGgh4rmOvLM/HOaturo6CQy8+eabSaCgOQ6V\nqCDHkCFDmmWgR/VdH3WurCdf+vfvb01FfR1vbebOnZtkgV199dU1ssAUDAuDw54FFmZUAgCalyoD\nAAAAAABAixTOfyQ+J1K7du2SIMGNN95oPXv2TLJoxowZY83FsGHDrH379jZ48GBrbhSkWrVqVY3s\npHKYOXNm9vmsWbOSebGaghEjRiRlKffxptF+dOyi7EdlgW3ZsiX5O74WmAMMACoHP2EAAAAAAABo\nocLMMO/w16NnwJxzzjnJUIlTpkxJAhbNJTvshBNOSAI/Xbp0MSCcC6x79+7Jawq8KQvMg79hBliY\nEUYADACaPzLCAAAAAAAAKpQCANOmTbOlS5cmz5XdpcyuOEB06aWX2osvvmjnnXeedevWLfu6AgUv\nv/yy9enTx37/+98nGTUPPfRQkrGkzJoJEyYkr917773J9rVdvZYrAFVoeZzKo0DE1KlTk/1oqEMP\nxuk1fd63q0BHTJlh8TCAvq6yxZYtW5Zs18ut7Yd/x+UqtPwPP/xwUj96T5lp/hlRMEblCmldfUbW\nr1+fPCrwGAozupzXvW+7tvqsb3H96NgVlIyPV/O3qdzi5zPf8fo507nMta20c61tqzyqX21DwyCu\nXbvW7rvvvmwATO378ssvT+pMc+PFgWHxY1LdepsDADQfBMIAAAAAAAAqkIIAAwYMSB7Vea+gxHXX\nXZcEBRTMCjv0FUTQfGAKxixZsiQZGlGBAgW8zjjjjCSIsHjxYnvkkUesX79+tvfeeyeBAV98W9q2\nbz8tKJFWHi2ar0kBk5iCHAoMad2JEyfWeE9lCp/7kHehtLmwfF0FkbRd/a3n2pcoIKL3VU4dRyHl\n1/phgEZBRb2mbel9ravn2o8W1ZkCeU5/+1CFfly1DV2o4SpVJ9q213+u8jSEtPrxeo2PV+v48Xkg\nLN/xhuc3Pi4FM/VefK61T5VHn9W8dwrwXnjhhclz8YCX/n7ppZfsF7/4RbK+thMOhajyKSCr85cW\njAQANH0MjQgAAAAAAFCBPAigYI6CW3pUgCZ8z6mTX4EKdfp7ZpWGh/vJT36SBMOuvfbaZJ2hQ4fa\n/Pnzk0wx0Ta0TW1fiwc74uyefOVRwETrh+UJ6XUFd5ShpWweBej0+TCQp7LpdV/ioFkafd7LrTKI\nH4uCIQrMhGXyIE9cfu1bgZK08nuQT+uF6+v1cJhJ/a33tHigxv/2JaTP6hi1Ld92WJ8qT0PzoTPD\n+vHzpOMLA10qnx+XB7DyHW+xFAQbMmRIck40193y5cuTdvvUU09l5yILh0JUJpjccMMNO8wH5uVu\nTnPkAQBqIhAGAAAAAABQYTyjSYGpMFMmDNr4cHpOQ/bpPX1WQ8Fdf/31dvvtt9u5556bZOF40EDb\nGDVqVPZzYUBHn9f+woyfsDwKZsXlUUBH5fGh8tLoODz7STzjqC7883pUBpwe/TUfWtCDW15+P76w\n/F6fGlYxpjqN19dr4kMhllp2ZSdpCetB21dmncrT0PO5eRAuPl6VsZDAZLkoU07ZjTr+U045xU4+\n+eRs4NaDuc7nA1OQUwFIz0CMtydpGYsAgOaBoREBAAAAAAAqjAeVlNkSDzmnoI8oEBMPJ+dzfqnz\n3+f8UjaPz6ekgII/l169eiVBspEjRyafFf2tbWjIOt++l6dDhw47lMczdBSYyzWcnwePGouORXx4\nw5DXZxxYlLRgnWd81YW263Xiw1O6hg6AOWWEKeClTCyfS8uHbWyIebV03AqAtW3bNgmAaajDQYMG\n1Wiv4bxf/twflQmpoKaCwN6Wda61XdV1Y827BgCoOwJhAAAAAAAAFcYzmfIFkNICJp5ppICCaFg/\nDxyEQ8YpeCB9+/a1cePG2Q9+8IPkM1o/zqYqtDy5hkZsCjzQ1BhDDuaiII0PRxhmszVWPSp4pKCT\nMuOUYSUKgKnONK9cfQeSFLBVW1S2oob0FAXFxNtu2IY9COYUhFUgT9tRIE/16Vl+HhgDADRPBMIA\nAAAAAAAqlAJTuYYQzBWYCIf403MFMxQ08MwtDSXnAQS93rVrV5szZ45dfvnlSQAkzjKra3maAi+z\ngoS5ytmQ5VfwS5lXKpfm4grrXMExDeXYGBRI0qIgnTIO9ejZVOFcbOWietBwhnLVVVclmWA+DKJs\n2LAhOxdYmP0l8VxgPreayq8MRgXvVI+qW7LBAKB5IxAGAAAAAABQYbzjPp6zqTYaFs4zYhQk0HNt\ny/92acPLXXzxxcl8TMccc0zyXo8ePbLrK5imoEix5WkqvD51rE2h/ArUKPNLQZumUB6fc86HQlSZ\ntCiTSkMOqh2FQw6Wg7anueN8aEoFaj0I5sNPPvnkkzZ48OCcgbCY2rnKqgCYB371GgCgedvZAAAA\nAAAAUFF8ri0FIeKh8vS3gggxZdcosKKgjx4VtPDnPoxinEWjQIMyxDzIEA41p3375xSMyFcezUnW\nlHn5VRe5yl+uIQmVYefbrU28juo7nsOsIagcygbU+Y153eU6Hs8SS5tjzakdaj1lf+kYta977rnH\n7r///myQ0gNXcvzxxyfra56wt99+O5vFqCXfHGo+95rqUMeibZ9wwgkGAGjeyAgDAAAAAACoMJ6N\nowCN5u5SAEeZM6tWrUoyXhSUUIAinM9LwQU9hkPYaShDva4lbWi766+/3tavX29Dhw61F1980W64\n4QZ76aWXkuww7U/lUEBBWTVxeZS1s2zZshrlUTZRKfT5MAjjQRVl9nhgSNsuNbsnrk8NoaeMNy+/\ngisaSq8c2Vnahsqs/XgGlfajsvv58vmsPEipfWudcEjEOPCkIROdB4PC+tG5VYZVKVQulUlDaWo/\nOpfanteP5Kp7rasAl4Z6VL16O43bgw9bqHrp3LmzjR492k4//fRkH+JBWgW79t57b/vxj39s559/\nvn35y1+uMedXbYFCzwpT/ZVaHwCApoVAGAAAAAAAQAVS0EDU+a8sF6dAizr4w3mPFOBRcMSzwJwC\nET68nRbNkRXSexqmL5xXTAGKSy65JHk+aNAgO/roo5PAlO9T+0orT6lBMFHQIm1erDDoof3UZZg7\nz5ZT+RWUCbergGFdyh9Snep4FIzx4JWCOGHgUn/rXOic6Li16DUfwlJl1RxdYZlqqx9tuy6BH21f\n21BbCPel+sk3t5raggfMvF51LAo0evk906179+5JFqLqR0EwDcWp5YwzzqiRlahF29IcYTpfHiRV\nWTyAmIvKqf1qH2E7BQA0XztV7X/UViujTa/dbwAAAAAAAGg6FEhQx74PMVdXCnQoSKNHZQKtXbs2\n2YeyvNq2bZvM1aRFw9VpufDCC+03v/mNPfTQQ0kZyl2ehublV9lzBXjqStvXfmrbh2e/NaW6LKVM\nuY5Xw3gqcDVu3LgkyBq2NWWPKQCmoQ8lDIb5EJ7KWFR5tM1CzpW2reEpFQSLA78AgIbR6oBvWDmR\nEQYAAAAAAFDh6itY4zp06JANeCjw5UEIBcP0/Oqrr04yfDSE38iRI7ND/jVX9V2fovosJMusXJlo\n5VRKmeLjVUBKwdY1a9bYAw88YN26dUvaU5s2bZK2JD4cYjgsYvi3b7eYISs9C6+5t1EAwMd2NgAA\nAAAAAKCOPPDgQQhl6fiiv0855RRbsGCB3Xbbbcl8UD5PFRDTnGGaC6x379722GOP2WGHHZbNMFSw\nSzzzK2xn3ta8LRZKbVHZjRpCUUMwxkOEAgCaNzLCAAAAAAAAUBZhAMKfK3ihAIUCGRrO7umnn7Yr\nrrjCBgwYkAw9V0y2DiqbhkdURtaSJUvs/vvvT+YE27JlSzbLMM78Ch9dsUEw0RxlngmmoT7zzSEG\nAGh+mCMMAAAAAAAA9cLnCPNsnnDusEceecTOOOOMihgqEXWnLDAFo5Q5qPnANNec2omE2YbhHGDh\nXGClBMCcMsK0FDqPGACgfpV7jjACYQAAAAAAAKgXHsgIA2JhMGzVqlX2gx/8wF555RWbO3duiwpC\neN2EzxXMiYM/8fNKoyywSZMmJed/xowZ1qdPn6R9SBwAyzcXGACgcpQ7EMYcYQAAAAAAAKgX8XB2\n4VxO+ltDJd5555127LHHJkMlzp492ypVGAjcvHlzMuTfpk2bsote27hxY/LoSxg0DANnlULzcWku\nMB3r448/nswJFh9rmP3lbSgMhAEAUBsywgAAAAAAAFDvPLgRBnZ8/ictGprumGOOqbihEv34tHz4\n4YdJ0MsDXp75JArwKLDTqlWr5HlVVVU2+BMu0twDQGEW2K233poNgKk+wmMMs7+8fvw9AEDlIiMM\nAAAAAAAAzY4HL9KCO1o0LOKCBQvsueees65duyaBseYsnBvtgw8+sDVr1tjatWvtnXfeSQJhYRBM\nFBRUcOz9999P1tmwYYO99957SfDMA2daJ8wSa47CLLDHHnssGwSTuI149pcHwcgCAwCUgkAYAAAA\nAAAAGkQYzNCirKcw2KFg2PTp0+2ss85KgiXNfahEBXveeuutJACmYFYxFOxSAE1BMT16QMyDYc0t\nEKYssLFjx9rw4cOTc3z11Vdbu3btahxLHPyKg2AAAJSCQBgAAAAAAAAaVNrcYT78nZbRo0fbo48+\nauPHj0+CJwqiNCcK7rz77rtJEKzYAFjMM8qUKaZgmJZ4/rCmzrPAFMRTFlifPn2yAT2Jh0GstKEg\nAQCNi0AYAAAAAAAAGlzaHFAe/NDfyg5bvHhxEkhSEKU5DJXowyG+/fbbtn79+h2GP6wLBb8UEFN9\naNFcY+Eca02RZ4ENGTLEZsyYYZMnT7a2bdumBsA8COrtgKEQAQDlQiAMAAAAAAAAjSoMgOlRQybq\nsX379skQehdddJH17NnTJk2aZE2dhjLUUh98uEQtHgjTIk0tGOZZYCtWrLDly5dbr169soFCSQuC\nhe2AABgAoFwIhAEAAAAAAKDRxUPiKTDiAbFTTz3VFi1aZLfddpuNGDGiSWaHKcij4JSGRKxvPkSi\nzxnW1IJhClgqC0wZYHPmzEmywDxzLcz0ijPACIIBAOoDgTAAAAAAAAA0CXGQJJw/TEMlKrPooIMO\nsgEDBtjSpUutqVCAR8GoNWvWlHU4xFxUHwqEKfCmIRPD+bYak86JssAefPDBZFjLgQMHZsvmQbA4\nAyzMBAMAoD7wDQMAAAAAAIAmI84MCgMnMm7cOLvyyitt8ODBTWKoRM/Cev/997OZWfVN9aIAWDhX\nmAebGsu0adOSAOXJJ59sDzzwgHXu3NnC8sZzwcVzgQEAUF+qDAAAAAAAAGiCPEvIAyV6VMBn0KBB\n1r17dzvjjDOSuahmzpyZZIw1FpVJgbCGpLpRVlg4hKQWz7xqKBqmUsNVqg4ef/xx69SpUzYopyVt\n2EPP8hOCYACA+kZGGAAAAAAAAJqccJhECYfQ06LA1/z58+2II45IMpHmzZtnjUHBHs/MakiqDwWc\nfN963tDDIyoLrH///nbcccfZggULrGPHjjUy08IssHioSzLBAAANhYwwAAAAAAAANGkeMAmzijzo\no6ESNRfVd77zHVu2bJlNmDDBGopnPTV0ECzcv/atYFirVq2SzDDVi9dTfQmzwDQMorLAVBbfd5wJ\n5gtZYACAxkBGGAAAAAAAAJq0MIMoLbjSo0ePJCPpueees65duyaBmoaioM8HH3xgjUHH7/ODNVRG\nmGeBKfh4//33J1lgXoZw6MNwCQOYBMEAAA2NjDAAAAAAAAA0C2E2WJwdpqESZ8yYYTfddJMdfvjh\ndt1119mwYcOsPvkQgP7Y0JQBpiCcAlG+6LX6EGaBKQBWXV2d7M/nJIuz9jxQKQTAAACNiYwwAAAA\nAAAANCthRpgyjhT88b9HjRplixYtsvHjx9vYsWNt3bp1Vl88CLd582ZrDDpe7d+DYD48YbkDc+Fc\nYAqCde7cObu/8FyE5yEMiBEEAwA0JgJhAAAAAAAAaHbCIIsPx+cBGGWHLV68OAlQKTusPoZK9PnB\nGjvI4+XwpZxUbwMGDLDbbrstmQts9OjR2WEQxTO+wuBXGAQjAAYAaAoIhAEAAAAAAKDZiucM86yk\nDh062OTJk+2iiy6ynj17JllN5d6vZ2A1pjALrJwBMdWXgoi9evWyP/7xj9apU6camW9e7x6ADB8J\nggEAmhLmCAMAAAAAAECzFQZcFIhREEjBGHfqqada37597eijj7alS5fahAkTkoyxcu7bhyhsaJs2\nbcruN5yvrC5BKA0lqbnAVqxYkQyD2L1792wWWK55wMK5wJpClhwAACEywgAAAAAAAFARwuCMMsM8\nM0mBr+XLl9tBBx2UDPVX7qESw8BbQ/I5usSP1f8uxbx586xr167WsWNHe/zxx+2www7LBsHCOdnC\nJZ4LjCAYAKCpISMMAAAAAAAAzZ4HYMKMJA8K+fCB48aNs+rqauvXr5+NHDkyyQ4rx34VdFN2VkP7\n4IMPssGncmSBLVmyxO666y7r3bt3drhFCffhwTCpS9ANAICGwrcVAAAAAAAAKoYHhDxooyCVZy5p\nGTp0qC1YsMDuueeesmSHaT+NlRGm4Ftds7EWLlyYzAWmLLDHHnssmRMsDoKFQyCmZYCRBQYAaMoI\nhAEAAAAAAKCihMGwMIvJAznKCnv00Uftq1/9ahIM05CApe5HS6tWrRo8O0pBsM2bN9cYojAMVNVG\nWWBjx4614cOH2/Tp0+2qq66yNm3a5AyAaR8eVCT4BQBoTgiEAQAAAAAAoOLEw/mFQSIPHmmoxJ/+\n9Kc2ZswYmzRpkpVK223durU1pHfeeSd7HGHWWyE8C0yBNGWB9enTJwmA+bCScfAwDLQRBAMANDcE\nwgAAAAAAAFDx0oI7Wvr27ZsMlfjcc89Z165dixoqMQyyNWRW2JYtW2zjxo1JAMwXP658Qaq0LLC2\nbdsmQyFqCedW80XbLjTLDACApqjKAAAAAAAAgAoXDpcoPgSgdOnSJQkMXXHFFclQiRMnTrRhw4ZZ\nITxDSoGoXXfd1T744AOrTwpYvfnmm0mASsE3LfHwiGlBK2WBjRgxwgYOHGiPP/54EgCLs8DC+c7I\nAKssr/xjtT386DL7y9Mv2sqXX7Onn1ll69a/a+s3vGvvf/Bhsk7r1rta2zZ7WKeDPmH77N3Wuh/a\n1b7c85+sx2EH28FdDjQAaK52qtr/qK1WRpteu98AAAAAAACApsgDYAooeSBIGVb+fNWqVXb00Ufb\niSeeaFOnTi1oe9qWhhlUEEyLntcXZXV9+OGHtttuu9kee+yRLLvvvnsShPPMsHh9Dfs4d+5cu/XW\nW5NhEMNj9yy2MAssfM0DZWheNm/eYv/32F/s7v99xOb9+lF7Y/U6q4tOHfezAb172LcG97dvDPiS\nAUB9anXAN6ycGBoRAAAAAAAALUbavGGeVaXn1dXVybxZq1evLmioxDgjrD6HSNywYUMSaNN+fAkz\nwuKAlc8F9tZbbyVZYL17906CfgqEiZczzCbzLDB/jyBY8/Le+x/aNTfdZR27f8eO+uYPbcbsX9c5\nCCYvv/KG3X7nb23gd8fZp7801P5z2p1JsA0AmgMywgAAAAAAANAieXaYZ3X5o4JFcuONN9pPf/rT\nZF6tMWPG5N2WPuNzdylYpcdw+MW6UJmU2aVtKvClDDBlgikrrHXr1klALJwjzLPAZs2aZTNmzLBB\ngwbVyAKLg4EeyAuDXgTAmpd1G961G2bcY9fPmJs8bwj7faK9ff+UY23U9wbbJ/ZpbwBQLuXOCCMQ\nBgAAAAAAgBbNA0RhMMyHTNRQicccc4x97WtfS4ZKbN++fc5taH0Ni6iAlYYv1CJ1CSppGwpsiYJg\nCn754kEwz0LTfpYuXZrMBda5c+ckCKa5wDwDzMuSFggjA6z5umXW/2cTrpxta9ZtsMagYRMvHvNd\n+97QYw0AyoGhEQEAAAAAAIAyigNDnl2lxy5dutjTTz9te+65ZzLMYK6hEv3zmqdLgSkFqbTodQXH\nwmBUIRQA0/CMa9euTbarbSkTLAyChUM6aj/KAhswYICNGjXK7rzzTmvTpk02qBeW0YdSDIdE9DpA\n8/HsildswODz7ZyLbmi0IJho2MSzLpxmvY4dY6teft0AoKmpMgAAAAAAAKCF80CQZ4eFryuYNHny\nZOvWrZv169fPRo4caRMmTEjdhgfDwswrLQpseTBM74ePomyyTZs2JdlkCpzpuQJVCnppPWV+efAr\nHA5Ry7Jly5IsMGV/aX4zzXPmwztKmPUVBvzC40bzct0t/2PjLp9pGzPtpBzUxtTu6uKPf/6bffZf\nhtulPxxmPxzzHQOApoKhEQEAAAAAAIBAPFSiP9eioRK/853v2Kc+9alkqERljKV9VoEore/BLT1q\n8aET/X1f3+fuEs/aUnBCjwp+hYte9/euv/56u+6662z06NHJEpbXg10e+GIYxOZv46bNNubim+xn\nd/ymqM/lC3S12rWV7dOhg732+htWLqNOO96umXRmZr+7GAAUq9xDI5IRBgAAAAAAAAQ8QKRAUzi0\noCjwtWjRIrviiiuSYQhnzpxp/fv3r/FZ/3w45KIHrxQAUzaXD5foiwuDVv4ZD3r5c733yiuvJFlg\nKtv999+fzAmmbXtWWzjcoT7r5fHX0fx8lDmvY8f9tOggmHT85IH2j3+8bh9mgrCxTRs3lTUIJjf9\n/L7Mf3eyqT85i/YGoNGREQYAAAAAAADkEGeH6VEBJz3/wx/+YKeffnrqUIkePAuzw/QYLh4Ei4di\nDOcp84BY+PcNN9xg06ZNS+YC8yywMJiWNgwiWWDNm87xyHOvsV/89++s3PbdZ29bu259jeE0y2Xo\nv/+r/ez6C2xn2h2AIpARBgAAAAAAADSQcLhCz7QSPe/Tp4/Nnz/ffvjDH9rhhx9uc+fOzQ6VGGeF\nKcigYJYH0fwxDGC5tCCW/n755ZeToJs+s2DBgmQuMA+mhfORMQxiZdm8eYudP/6WegmC+fbrq33c\nkSnz7ru3tqmXn227tqIrGkDj2NkAAAAAAAAA5BUOeRhmZ3Xt2tXmzJljxx57bDJU4uzZs1M/H873\npecaHlHLbrvtliytW7eusei9cD6wG2+80b72ta/ZwIEDawyF6HOLhZlkWsKsMIJgzdsFmSDYT2+7\nz4oVZgLms279+pzzh5XDjNt/beddfJMBQGNhaEQAAAAAAACgQD5UYjxcopZVq1bZ0UcfbSeeeKJN\nnTo19bM+h5f/Hb4e8r9XrlyZZIFpnenTp2ezwOLPxNlj4YLma/L1d9olV8y0UrRqVWU9DjvYXljx\nd1u7/h0rpz333MM2bdpkGzduKvgzV088w84780QDUD6XXnOHPbLoSVv58us25vtD7JzTh1glKPfQ\niGSEAQAAAAAAAAVKG4LQFw2LqCELV69enWSKKYgVfzbchn8uzDALA1nXX3+9feELX7Djjjsu2W6n\nTp1qzCnm63m2Wdp20HytynRsj79ytpVq06bN9ubqdTbipKPtnz7bOW97UNvZfbfWVqg9dt89yVzM\n5Z8+++mkXYbGXXGbPbfiFQNQPgqCPZxZdL/o16uHIR2BMAAAAAAAAKAIYSArHJLQg2HK3DrrrLOs\nf//+Nm3aNCuWMss0zOJtt92WDIM4atSobAAsbSjEtCAamr+Tzrh8hznkDtx/H9u7Qxsr9BS/9Mrr\n9udlz9m4806yY77+5SRLLI3a1SGfq7a2bfYoaLtvrn7L3n47d5bZ8ytW7jDcorLHTv+P6wxA+axd\n/272eedO+xvSEQgDAAAAAAAAipQrK8wDU6NHj7bf/OY3NmXKFBsxYoStW7euoO3OmzfPDj/8cOvV\nq5c99thj1q1btxpDIcYBsDAQRgCscvzsjt/YH//8zA6vv/3ue3bskV+xfz++v+2/b4daz7mSB//v\n8b/YXfcutMvHjbSxZ30zE0hru8N6amOvv7nWvn3CAGvXtrBgWD655hz7w2N/sVtm/X8GoDzWb/g4\nIN2+7Z6GdMwRBgAAAAAAANRBONfXli1bsplber5+/Xq7/PLL7de//rU99NBDScZYGgXKFDBbsmSJ\n3XXXXUkAzOcfC7O84sBbONwiKsObb62zr3zjHHvplTdS399rz93tjGEDrV+v7jb/d3+yeb951F57\nY022HaapqtrFzh55vI37j5PtN7993K656b9t+bOrMu3r48+oDf378X2t40GfsJtn3Wfvv7/R6oMC\ncc88PqvROu01hJzmU5L27fa0HocebE2Zyrv0qReS5+3b7pXM+9aUAx7rNrxr981/1Nq128sGH33E\nDu89vGhZ8rxnpt6rm1gGk8q36uXXbNlft9V3dacDmnx9f/rLpyZtRHX5/J9ut0pR7jnCqgwAAAAA\nAABAyRRAUBDCA1MKgCmApWyt9u3b21VXXWXdu3e3fv362ciRI23ChAk1Pq8sMAXBTjnlFLv55put\nbdu22SHx0uYkC4dlJABWeW782b05g2Dyzrvv209n3mdr1m6w80f9uw377lE2878W2H0LFucMiG3e\nvMVu+6/51iXTWX76qQPt85+ptutm3J35zGP23nsfJOvoc/N//ye7asL3bdi3j7KfZ7apecbKTeW+\nfsY9Nv6CodZQFCiYdutcu+POB5JgR0hBjuOPOSIpT1MKzNwwY25S5lXbg3YhBZiuvezMRi+vzuP1\nt85Lnj94z9V2+5zf2qXX3JF9X+XT63rU8ei9sP7HX3CK/bgB20EuKpPKltY+5NRvH9lk2se/nnhh\nNpAr/zNrYtKGFSxVUCzNPZl1uh/6KWvJdtl5r4MnWhmNbwINFwAAAAAAAGhIHgzz53GAqkePHjZw\n4EA7//zz7cknn7SePXsmr//oRz+yqVOn2u23327f+973rHXr1jtsx4dA1EIQrLIpYHXqqMn27vbg\nVKxdWw1ruJN98MGH9te/rbS31mywY772z/Zvx/e13v9ymH2UCcK+9vpae/f9HT+/MRPU+uvylXbY\n57tY3yO62Ve+eIjttcfu9vQzK7P70zxeG95+PwlQvPT3N+25Fa9mXi3rgGKJJ/+6wkZ/74Scc5aV\nkwIwJ595hT2y6En74MNNO7yv15Y9tSIT0JlruqL6HdHDGpMCX98cMclm3P5rW58SlJFnnn+5SZT3\n/oeeSAKwKue6De8kZVKwSOVSva7fngH2Yeb5f4y/xXZrvav9yxc/nw3uPZw5Jyp/l0YMMCn768tf\nPyvbPhRU2n+/va19u72y9a/2ce+CRTY4EzDV643p0mt+kdSfyqblpqvOTcqkOr76hjnZ18PlWyf0\nb9Q6LsVlmeMsJzLCAAAAAAAAgDLwYFgYpPLnyvCqrq625cuXJ0MlDhgwIHn/uOOOs8WLF1u7du2y\nWWASBrvibDACYJXrmpvusjfeXJvz/Z13zpz7rdvaiYJm//P//V8SIL3k/FPsq18+JMn6ePz/LbeZ\nv1xgv334z/bW2g014lh/f221XTntV1bdeX/7/Gc627nfP8E6d9zPrs3s96lnV2U2vdWeWPqMLX7i\naZtw4dBMUO0t+39Ln601FLb7brtZVSao9fbb71ghFDT56c/vtQtGf8vqkzrTwwylfkd0t3NOH5IM\ny7du/Tu28pXX7b75i5JMJrl0e+d7Y2UpKRvp6ydemA0UKShzzukn2rBvH5n8rUyg2+c80GTKG1KZ\nfpwJoHqijDKXFOhSEEnnIMwO0+t6XxRg0nlpDKpnlUP1rrpWPZ76naOyQyHqfZVdx6bnOjdPPHhz\now6VqEzA9es/vs5OG3NN9vnPp52f+pnmFgSrD8wRBgAAAAAAAJRZOG9YPHeYAl7/+7//mwyB2Lt3\n72S9OHgWZn8J84G1DJ/+0qm26pWPhz1TcEnnfuOHuefralW1i51wbC+b8INT7XOf7pS8puEO//DH\nv9odmQ58BcTWrH072ya1vW8N7ms/ufi0TFBivyQL7I9//ptNm36PzX/wT/Zh5u8vH/45m33TD5Og\n3PfHTrHnVvy9xj6Vubhly0eZYNy2DKtdW7VKgmWbNm2yQu2zdzt75clfJfOX1QcFjE4bc23yXIGL\nu2dNzBlwUVaQB0TCYE5DO//HtyRZVRIGjmIKzIQBkN9l1muMYJKCRJ65o/2rHJYt48f1L5q/yo9F\nQchPfO7fkuca5vHuWROsMfj8WmofKrvmA0ujuvbgY2O2jzQ+l1aPTBBcQbpKUe45wnY2AAAAAAAA\nAGUVZnLpsaqqKglueWbXoEGDrG/fvjXWFx8G0dfTos8SBKt8Dzz0RI0gmLTeddck2yqfTZu32D2/\n/oNddOnP7P8tezbJFNtjj93sqP5fsuuvPCfJEhl+0jfsgP32zmYnzv3No3btzf9t/3j9Ldt111bW\n+yvd7KpJZ9hFY75jnT65XxIYmjNvoX2hx2fsiktOs09/6qAa+9xrzz0ywbBW2b83ZgJgxQTB5K01\n6+0Pj/3F6sulwdBq1152Vt5AkQIgygZqzCCHAjIeBJNcQTDRnFXnfH9I9u/Lgqy3xnLqt4+q8Xd1\npwOyz1X34bFoKD/PqlJ2YGNQoM4z73TucwXB5NpLz8yW94YZ86ypCOePa+whG5s6AmEAAAAAAABA\nPYqHNwyDXT73V/w8HAox3AYq112ZwFPs3Xffs/XrN9T20SQ76ze/+6NdMGGGPfjIEtu4cXPyeodM\n5/hxR37Frp54ut12w4U27DtH2f77dUjev/3O+23mrx6wDW+/l6zbtfMBNuq0E2zaFWfbv3zh85ny\nPJwExAZ94yt2+cUjbf9PdMju7601a5Oy1dXd//t/Vh/CIIcyjk7dPrRgPueePqTOQbB1y+fZW3+e\nbRvXrbRiTZvxcRBM5a2uZTg7zePmwRkNNRgGRQr1jwcn2V+v6Wor/2eEbflgndVFvvL2TQlCtqtD\n4Ob9fyy1Z382wJbfeHhS56WYtj2g1b7tXsm5z0dBJg+UKXBXSl27Nx6dlq3zUtoJSkMgDAAAAAAA\nAKhHYSDMg13x4plf4WMYCEPl+/2jy6wulOmlDKuLL/+Z3f/QE8kQh65dmz3tyH5fsCt//D372dTz\nk4BYu3Zt7Obb7rP7Fiy2Dz/ctm6H9nvZNwZ8ya6adLr1/Wq3THDtcXtr7dt2fCaY9INzv2177bm7\nldPc3/zB6sO9mWNyQwsIgpXDK78eay/8YkgmwDHcnskEaYoNLCmY5eLsqjQKzhx/zBHZv++dv8iK\n8cai6+zV30+0D9euzATvZtnrmQBNXXRowIyk5/9riL394kJ7LxMQU50XW9camvHJp15Invc47FMF\nfSYM5j28qLRrVfX88m/Oy9b5yrtHWLkooIfcqgwAAAAAAABAg/CAmIIWPv+XC/8mANayrFj5qr38\nyhtWDn95eqX953W/sl1bVdmA3j1t110/7gLeZ++29q/9v2CH/lO1HTXgizb314/anLkPWdfO+9tX\nvnyI7ZJpgxoq8fBuB1vbNkNs0R+fspf//kYSdBl50jFJ8OAXdz1oWzLtt1StMttX+9a8Z2+8uc5e\n+cdq63jgvlZOK1/6OGOnX68eVt8UiHk9E1hyGzOBDgVp2nTtX/A2PDAj+YbpC/U4VOttm7tqWfD5\nQrz3as1gjrKs6qLd9uy0+qa61RIqtq6XPbUi+1zzwoXzrRX0mfXvWik+XLuqxt91zcJbGWSmtWvX\nMPXfXLX4QNi6dets6dKl1r9/f2vuVq5caQsXLrQuXbpUxPG0RGqLs2fPtqlTp1pTMGnSJBs8eLD1\n7NnT6puOvX379kn7LQddCyq3ttnUFXvsWl8a4ryg+fPvhXJdW3XRWNel9qvvSH03ej34a83tOzPt\nWIDG4v+Obi7ftwAANDXKAtu6dWuySBj4IgjW8iwtMoiRj9rUn5b8zcZd/nOb+INhdmT/L9aYz6sq\n0/Y0D9hBB+xrR3z5UPvjkmfs5VdX2wGrXrODu26bC0zt87MHd8wEw/a0V19bnQTDDu5ykF128Uh7\nfsWr9mgmQFaqVrtUWevddk0CYfLIomV20r993copDCq1b4AAzS67tU+WMLDRukOXgj+vDKVQoWVu\nHwQ/1hcZnGl/6GB7a8msj/8+ZLA1B7tm6lVBL2WESevtf5dKw39qaQiq43/8fmL273bNpM4rQYsJ\nhI0YMSLp0D/hhBNqvK6gw6xZs2zJkiXWnM2bN8+GDBmSdEToOBu6U+/hhx9O6lEBnLgjRB12CqgM\nGzasSXY2qm2kUVlV5tqcd955dvjhh9dYVx1DY8eOTTopJ0yYYIVQPekczp378XjAqtN777032Z7q\nVfUbdnzqM9OmTcsGRoYPH55aZn1e6/Xr16/GOch17KJya1sDBgxIylRo0EX70f7C4/b6GDNmTI3t\naF3R67o2VZ5c9aU2rvUfeughq43qReXWusW0Oa8ndTSLn7/67mwOj13nUnWlOs/Vqehta+bMmdaU\neN15e9VxFXINlUrXh+49IZ1v3QNL7ZD1bcZtNeTXTWPVv18L+dpISNeCjquUdhxfE7nuMbrH67rL\nxQPqKsuLL75Ytg7zQu7ful78+H1ReSdOnJiUSee6uQiPJa196r3169c3yWPy74FQ2vdsse0bjUvf\nWeW+rgEAaCmY9wuxP2WCUeWmDJYf/eTn9sHGjTagV88kGyy0yy472ycP3NeO27e9vf76Glu9doO9\n9PLr1jmY6+mA/TpkgmG724qVr9n6De/agfvtbddeeqZ9c8SkJJOrFO+9/36yfFzOFzOBMGv2Pvu9\nh2zV9rm2PnHEGNu1fZeCP6u6rSvNXVWM9p8/wQ4+ZW6SGdbmU/3qFExqaCr3uqfn2Zb319k+Xxxu\nxVr18mvZ5/2O6F7rfGyxQjP2Ynsc2NO6XfCirf7z7EwAr9r2+cJwQ8NoEYEwdQxpkTgQps69uvyP\nuwcqwuBFuXknZL59qHNJHZSN1THbrl27pC7Sgo0qu94rNCDU0FQ2lTnuVNQxFUKddup4DDvz1Dmr\nzqFCgjbOg4VeDv193XXXZTvkFbRVwE1BW+/QVueT2q/qVp2MCsrp0TtBVffajndi+3Xg0jrG1Znt\n50vvq12pfRVzLCp3eL49UBp33uq1YgJV9dnJ5sEz7cPrT9d2XOcNQWXwYFI56Pxpe/V5f1AQV+1M\ndae60jlX2wnbY7lpH9qn9iPal4IbWtQpW+o21S7VHtLavNqEX0eNdb9V/aptNESns9/LdA5Vv7nO\naXV1dfa51td9UefB1VdZa7t/q6y6H+lceTvxz5XzO1PtUHVVarsrRK5jCan9qu021UCY17vacHi9\n6lrze6y3bYIqxdN3mK6H5hTcBQAAwMeefKq4/5/43GcOtmeey5/F0q5tW/vbcy/ZuJ/cZud8/wT7\n5qA+dsD+++ywnoZQ7NRxP9s/E/T6RyYg9uprb9lBB3y83h6772af/2wne/2NdckcYV/s+Vm74sff\ns++PnWIfbs/qqotVL71m5aaMqnXbg0t6bIisMAU5Pj+6tGSLYgMxLhyir5RtKBimpblR9l1dgkjV\nnQ7IPtfcX+MvGGoNRRltB329afaTV7KKD4R5NpI62z0YEL/vHfH5Op5zvadO0Xz7DjvPtQ0pdh9p\n5Y4/p33lygSK91lIB3vaOvk+p05I1aOCdmlZd2lDOBW7j3K8n0s5M1cUdPAgWKHBEw8+hZ2o6hwM\nOzxVxg4dOiT1qSCTD4+lz/h+Vq1alXzOO8E8C0yZZAroxNKCk+rM9Y5K0bbU+ar9FRK00v7CoZJE\nneI6L9qG71Nl1zppw0CmnUcdf9y28q1fzPui+4SE2aGqB3Usqk7ioEip11Ft76nOSg2s59qm3yOK\n+Uyh74vars5x2Ba9Dak96tqK70FSjms5zrpUMF7nLK29FrPNMLMt5AHdUuszn0I/m6+NlHP/fh3r\nPuR1qaC/6iDuaI+DTGoP8f0lrrNy3c/z3b+9rcVtIfzuL3a/ud4vV5vIdx1LKZnVpf77o9h9FLKN\nMDtc939dr55RJHov7Rgb4t8HDfXvkvoqq+rQz3Vt6us7DAAAAKVbvWZ9Ues/+/yKgtddseofdvmU\n/7IPPtxk3z1xQJIFlkZzgymYsnHjJtu0abO1avVx17GGSjzowH1sy5Ztc4NpO8+/+He77JpfZIf3\nrM2uu+6aCaTtYWvW1vx361PPrLJyU8bOw4ueTJ5r2Dtl/TR1qvtV2+d8evKpFdb90E/V+plwXrBS\ng2ktUZegrlYF82yhcu1sFU5BA1Fnizqp4g4CdfJpUYBBS9euXWt0ZvmQL3pPqeo+rI86SbWuHrV4\nkEGBB62v97T49n0bWtSpHpbDM1F8H/5+rn2E1OHor+tzPkyUdyzp8/5+rv04ZXRo0fpeFz5EUa76\nCakzUscaH5vK7p2UXj/atwd1REGIcB8elHBxGfS+tpPrPOkY8g3TVV88i0ud1MVkEOn4wmCh/1I+\n7gwMt6lf/sfz/ngQyo9d5fDhvwoRZoM5dXSpHH6uauPzhIRD1nkAzIMLsmzZsuz64f7TrjfxtuO0\nHbXXsF3EQWO1i7A9+1CMMc9USAsMxkEc1YO2lXYdqfy+n7BcYd1p3fg6VHAhrKv4OlM9+HAZOub4\nPqbr1I8zLJOXR+/7dn0YzdruB+ExxOcipuPT9R+3eR8OL6yf8F4YX6d6z69t3298L6iNn6vwWPz+\n6futbZtq79pO3F5UVtVlHJD1Id/Cc671RPWtv+PyhK9pXW9Tcfm0XZ1z1YnqQ5/VDzC0fijX/mPe\n/rRNF57rcP+qA3Wsh/ehcnR+q/z5rtv4+8DbbCn78XuGfyd63YsyaMNrTe242O8hUV36d294n4mv\nsdq+l+LvMW3T1087lkLUds2F98j4PpDWznLdh/XZtO0Xwv995u0gPNb4GNLqMa43PQ/fT/te0d9+\njeiYdNy+jpcj1/kO6yJ8P7xf+L+n4v3G9R1vU2VKuxZFn1c5/ftA7/v3gbdr/RhG/waJz1so37+3\nvC7C+4nKG96//J6W9v0GAACAunnl1eKGGSwk+LR+w4bs89VrNtjVN91ld9/3iL1ay5CGCoiFQbCQ\nhlN0l/zHydbnq92sUB999JHtvPPOKeUsbki/QvQ9okf2+WXX3GHNQRismzf/0YI+48G+bZ/vYSiM\ngoaeJXjf/MXZ7MHmpgvBz4JVdCBMnR8KAoRz/IQdav5cnXrKAtGi596h5R08PXr0sLVr1ybvq7Nc\nHQXq3PUMEXXi+K/z1Rmh7arz3DOCwm2oU9GDS15GdZSE72sb4T58SLO0DAB1yOqX+Cq31vXsGs8W\n8s/l248LP+OZHaoLrxstPl9MGh2z3g+z5HzoSe849g4bDVulcqmjXJ02qlf9rS9xZRrovHlnlB7V\nYanXVS6Vz4cuc3EdS775r2IeNAiXYvmcMypfoYEnpzYTdjb7cIfxfGDetnIJA2ml8OzJOKCRK6My\nFx2/X196VNnVTjV8WnhePWjmPItE51Bt2TPR/Jji4JBn3um8q17iIJHaqraj7akN6vyk1Y2XNS14\nqXL7tefHoX35PSG8nn0dtU+VS+/rGNV+w3L7sHsql+okLlN4nDonvj2tr2BneB9buX1uOV1L8T1G\nx+PzpGkJsxR1P9C+/TPapgdHtE2VWedC7+v4/d6XRp9Pa/N+D4uH8vR9hvdb344Pq6nnetQ5yxcI\nCa9dtRWfP83vOX7v8/rR9al95Ou89ePXeiF9RtvWvSakfarOday6h4Vt0YeAC/fn29Hx+/nzNhWX\nT5/VtrVPbV91qvXia0Hr6DyF10JaBpYHCXxIQN2vdax+//U6T7vedR7UDuqaPRtfH2FQzufA8mPR\neVSZ893Tct2/da34cerRM9v8uzscks+H2NT9QvuN60Fl8nry9/08abseRNf2vH50XGF7l1zfS/F3\ntOpG9e3rpx1LIfR5D2j6NedBJv83jrbt+/ThdCVuZ2Fdh9vX3/qstq/yF/PdK2oDuhf5jyfi/ear\nx/jfaZ4RFZbBy+htTv/+0HH6DxD8hxDhNebn29tD/O+SsD34v1v0d/h95T8ACb/PVBb/TtJjuE2/\nB/t9V+c4fN/Lqf3p8yqr3vOse/2telQ7zjWUsV9f4b1K+/D6Dvfh/+5buX0uUvH7ldqMyqDjLzVQ\nDQAAgB1tCDriO7RvZzvtVP5u2zWZYNjk6++0X81daH8vcX6vkH6kNeuGH9hBKRlm++yz9w5Br82b\nN9vqt9bssO76eghCDPv2kdnnChaFAaOm6tRvH5V9fsOMebUGZ26f80A2m0mBneaQ9daUDN1e35pb\n7foZ91hz1C4Y8lOZj8ijav+jtpZzaUoynQFbM50D2b8zHQRbMx0R2b8zHYf66USNz+j9TIdL8jzz\nP/nJ+5mOgOz7mc6DZBG9Hr+f6UDZmulUyP6d6czIru9UpkyHSfJcj5lOuBrvZzo/tmY6VXLuI6Zt\nhMeZ9hnVRdp+/FhVTn0mLKve12uqB5fplEy2lYvKEZZFz8P1VTe+z7C84T5E+810xmTLHm7Tt+PH\n43Wsx7Rjq432lbYUSu1KZfHP5TtXuaisfrxpdGzah7cLCevAeZuN25yEdZrGP6u6i3lbKJSuIy+b\nnvv5U1v1th9eB6J6DP+Oyxyfc72X6YSrsb62qWNPqwc9j9tzIe+F9H5ct2qfui78/Xi/fp/Re17u\nuI517H7fiMuiY46vOd1n/LVcZQqvmfjvsEzxaypj2vvhvS+mdcP7Xppc12nYrsJ6CLedq93quNKu\n3bB+0+4f8T0z3qbeS7sn6lxo23G543tY/Nl4f76dXOUL21Ta+/H+09qUPu/Xh9ehXtO+w7L6d154\nXvS5+D6mz8T3oFxy3S/SvlPD7+G060Ov5bs/1nb/9n3m+46R+Lsqfi285pzaaiaYkTz36zakcoft\nWWVIu79K2r8FfJvejnIdSyjt3z1hucMy+PbC+6j25X+nncfwPpz2b420cxy/l3YfCa997Tesi3z1\nmPZvrLCMufYZf7fE11gp7SH8TtNzv4bDY4w/E5ZD68efqe1eEJcj7R4aqu3fW2n/rgjLkPbvwrTv\nCwAAAJSm1QHfyPavfrL7yZm/j96h3/WQ3meWpf9238+duPUn1/7X1mdfeGXrli0fba2rRX96autu\nnzymxj72//y3axxTvkXr1Yexl9yc3cfBXxq6deVLr+Vd/9Kr78gst29tTF8fckG2zCPPvTrnejoW\nHZOvO/vOB7Y2hkmZ+vIyxPW78NFl2fcmpdSrl1/H3BiW/uX5j6+Jz5xYa/tYu/6drddPv2drU7Pv\nZ4Zkj0NlTLPw0aVbl/71ha3NSbnjVhU7R1iYleH0K+g4IyzOYtAvhf2X5/qVuH5lq1+/6jGc10I0\nBI34Nnw+lXDOI/2K2X+d7L+41S94PVvBf4UeCv/WPrSNfBlG8XHE5fJ1wqwUPz4/Vq+X8DMaui7O\nDtIx5JqnSfRLZv/1vv8iOv5lcjyslv/6WpkJab/61z7zHb/Xj36x7L+cXpkyDGY++qW2MkZKpf3p\n2PWLdrUXzy4sVG1l9UyaOEOlnDxLJW6P4m1gZTTvXS76Zb2fg3AoObUn/5W9zlU8z1ChdZbWXsXb\nWikZfYXwaya8ntPuIyHdU5x/ptCMwVzz/4X15GXyDLlCyqT342wsb4N61K/99XkNiaVzpvOn13Kd\n+0LOW3id+hCq5ThPYYaPeNaF3799X/FQa4WUV5/3LEndn1Zun1cqzpaq7R7mma/+HeHbkVLL53Jd\nC3EGsfavdeNhW9W29J6fa/+ui+m+pn2U4x4Utpfw+vBj0b0oHk403z2yrvdvUXaLZ2XF5fHn8Xdo\n2lCq8fu6Ln2+OtVr2v3Vtx8PhetDdPp3cSlUZs9C1flTPXkZ1A70vs6trnHtQ+8Xco/3MkvasKm1\nfW8XI189qn5U3vD+tzIaFlFKydKurT1I/H7YttPui/nqVv9u8KEdw/Lnu78WO0xpbfeqXMIhjbWN\n8DjCaxgAAADl8/rrb6a+/vLLr2af77FHa/vcpzvZnnvslsz99cGHG21j5vHD7fN7bcwsysDavHmL\nbdmy1bZ89JFtzSyZsJet3/CeTbn5blu7boOd8q0j7dDPVeccCrEQX/3SIXbFJafZDybOSLLZqjLb\nevPNt5L3dtl5Z9t77w725uq3rKGNv+AUu2/BoiRrSsuXvn62nXv6CUnmVTif1sOLliVznXnWWHWn\nAzLrHGmN4efTLsiU86wkG+z2Ob+19evftWsvO3OH8p425tpsNpgywRqrvM2Z5pE75/tD7IZb5yZZ\nYV8/8cKkzYSZeU51fv746UnWldb98QVDralQZpuOQc7/8c1JG3JqR5ddfYddn3n/nNOH2JRLz7SW\nqmIDYT60TzyPRvg/7+q0iDslFEQKO0zCoWfUuapOGB+SKO5sTuuQ9GHN1JGjRZ0J6nD0obU0/E2+\njpHaOrR9nTCgkPaZuINGwg4WdW7oebhOru3k6/zzoe68E9M7o/MJ68jXDee3qK2zxutU+/bhBH24\nr0J5Z1qpfNg97zhTW0kbyrIUPmdLrqGOQt7pV8qx5JojK1Rop1vYDnT9eHBYwRQPUvt6TUE4dGpc\ndz7PnzpeVXa1NV1vOiYdozpgix2KstjOy3zb9zanzuFCy+TzPKUFPPw+4MOkKbirti1q02nnLPwB\nQVw2D/xrm36dqv5KuU4L4UMaatu6n+geq/3GgZJCzkEY2FebVRtIu7Z8aELVv9dPeA/zgIauB/8x\ngW+nLuUrZn0dg/arsnp5/HM+nKaf63DIQFfbvb+cVM6wc13ttLYfQ9Tl/i0aJs8DQeF+6zIfmtqi\njsXndfO6bah6TCuD2rP/GEH0qOPU+2oDfv3EP1LIJ76P1Ha+Yrom9G8vDeuX7xjiNqp6DIc+9e9/\nBdtzzZFXKL9e9J0VHlfYHnSM+d4vhQcrQ3XdZsj/vZXrXgUAAIDGtfture299z/Iu84nP3mgvbBi\nlW3d+pF98MGmTHBpvX3pyM/ZUf2+aJ/Yt53tsssuSRBs06YttjETEFMwbFPm8QM937jZ3v/ww+Rz\nH3zwYWZfH2aCYh/Z319dba2qdrHPfKqj7bpr6V3FY8/8N/vTkmfsv+99uMbrCsC9807+If52a93K\n6kP7dnvZg/dcnQQ4FDRSAOPSTMBLiweW1q9/p8YQhI09xKD2/7tMmf81U2aV695MIE+Lgjaa02pb\nIObj8ur1u2dNNJRmymXbAkMKJKmNKMCo9tHz0IMzfRPbhh1c9tSKGsMObrWmRcOAeiBMwdP75m9r\nLyu3B4CdXicQVmHUoeNzjMSBHe8g9rlZ4uwmfc6DMeowUIeE/0penUha3ztb4k7ztGCSOpTUYeO/\nXvZMgrCTKO5A1n7VoZK2j5hn3cTHGX/GM9NC6pQN59GJO658fptwu5KvPNqPjlWdUN6RVButq8/k\n+qV8ON9UGv/ldthx29C/UPb61/4VKFXHnDrjCu1MTJsnStQWPKsurnd9Jj7/pQbCPDCV6xx40LTQ\nDjnP/tG5VVm8bXmWjfYX/6q8GL69OENNda6OyWI7Dr2Mfo2HtM2V2+cG86y5UrNivKzqzC3k2L3O\ndW/JdS2pTMVmC3oWmQeoYjpv6phW+9X58oCQ2mNagFfBWp/bK9ye2q7/gMCv0zCYVl/XqbIqnIJM\nOtZcbTsfDxiFc4ClUXvWfT7f/U6d+dqG6iDMGlYndKnlk1xtSmUKf4ig8un7TPWhDCA/Fq3n8zhq\nUdk8mBCWc+vW+v9nnrcL/VCk1Ayouuzbv79yvR/P0Zjvvunzaeoa8u83v7/otbTM6Ph7zu/v8Zx0\nhfIyeAZVXAaf01PXrc9l6NdyId9d3t702br8qMHvYWnnXHWg930OLi2qd5VTr+neqHXC+1+cMStp\nGXf5+LWfqz3o+zff+6XwgFQ5txnTv09Ud4X82yyN6jPt350AAAAoj3Zt96g1EPb8Cy9mn3+UCTC9\n8uqb9vM7fmMLfvcnG3JcLzvh2F52yGerbZ+92yb/H/fRR1uT9fxxS+Zx2+vbXstmiWWeb3j7Xdt3\nn7r9f/pNk8+xhX9YZm++VbOP6/0P8h9X2zZ7Wn1RYOmJ3/00CW54sEDCAIFTVtW1l52VBJwak4IY\nTzx4cyYoc002Sy2e/0llPOf0E+3c04c0enmbOwXDembq/NJr7shmD6a1D7UlZVs1tbnY1F5ULrUX\nUaA0nBMvbCstWflnXWwC1GmpjgQf6seXMOgj6hhRh4r/T706eX2IO/FJ48Nh/tQJEHdgewAj11BA\n4ZCIPnG9dyDo77AMPpF5vO1c0ob9CYfdcqqP+FjDX/jH2V8+hFfYAZc25GIadbbqWONMtVxUF95B\n7HUQ8l+r+2TtHugMPy+ehebnLaR6joczC/kwbeESDhsZDtNVG9W9OpDVYef71Da8/GniYTtFx6DO\nPc9ADMsmHsTwY/XzWkonmj6Xr2PMh0Nyqv/a6sSHkIvbovajTvu6dJx6p6kP+WXbj0F1XmrnnK4F\nHVd4zeuc6TXv/PaAso7Lh30sJvPAAw6ePejl9msrjWdoePvQ/sK27EF9Dz7H77vwXuLHE9afzqd3\nxGpdldGPza+PXHXrHfvxELA6Ns/+8vumOt7D9+sqvnb9mPwYtf/w/uH3mEL37R3vXfJkt+o9v4dp\n8SEn4zr38xJea2p3aeXLd78IeWd82KY8gzntBxEKRIb3I7W9eKhPBRLj4IsHhOuTX9dxO9L9Md++\n892/C6Xzo/McngeVw+9z/r5fh7nab3gf13Xr9xN/T+ck7Try9hHezxWwzNfuCqEy6JjCMojfy9Ru\nwmMOfwDj9+hc370ql9ZJO1/56l9tzrNF1dY9uyvtxwEe5A/rRZ/3evRgeq4yev35fcG/J2vjw5nm\nag9+X/C/4/dLoXuV7iOl3gukQ4cOea8V3ePz/XurNn5fjb8nAQAAUB7tSgxmKIj18t/fsJ/+/D4b\n9YPrbcpP77aH/rDU3lq7wXbZZedkyMPWrVvZ7ru3tr323M3a7LV7sq8O7feyfTMBs0/s2972369D\nnYNg0qF9G/vljIutapddivrcJw/c1+qTMsMU7Hj+T7cnAYPBR381CWb4kILXXnqmvfnsPcl7TSWo\n5JlhCuKpfCqnFg1v9/Np59tzT9yRDOPX2OUdfPQRSXm0tMvUc6jHoZ/Kvqf1YhryUe+d0wQCNKpb\ntY+7Z01IyuNtxOtc50LvN7UgmPPyqw2rvPr7x5n2oeNpKm2l0ZV70rHGljaRd0iTrmc6N7KTvGui\n+0xHSfJc74UT2Wsb/p4WTUoeTgCvz+p1n7w8nCg9Xse3r3X06DTRuyYh93X0fr59xHQsKle4PUuZ\nGD7ej44r3I/KlOkgzf6tz2s9fc5pEvVwX/lovbQyp03EHtdzpjMomfA9rMtMJ1mNetSxhNuJ39dn\nw/LreXh8If9cvHj5NVF8XOaQyhpOVu/0eX1OZdBxq1xhfYZUtrBd+HZzlc3pPIV1p33mavt6P9Nx\nt8PrtV0zovMZXhuq/9ragrehuC36tRefDx2v6ilXmeO2o/KGbTpsw3ov3reXJ99x6hjD+tQ2dQ06\nnT+d67C+w7ZYyH7TrnnVpR972vrxPrWEbc7bu9+ntP2wPfk2w7LF153WD8sdXlO1tS3fnvYdbk/X\nctjmc12nvt3a2kAsrJewnHHbCu/ztR2Lthneu1T++LvBrxmnNh3fw/y7JhSft0LKF5cnbf9xG4nL\nG9ehf6/4d0DYfrRkOrtr7M+/V8Jt5hOXz/n1Eda9t818xxJeg7Ha7t9p+0yrE1H7zNdO4vYb3xv8\ns36O43YRX2Mxtdt8+891LKG4vaSVITyPtV0b8TH791pYJr1WyPny8sfbi+vE78P5jiH890tYRq0X\nf//H9zq17/i7Je3fK9qu9hXWTa77Wfx+2rVeyP0tXxtMuxfE+wn/zZkm173Ky5X2b7R4v+G/O/w+\nX1u7BAAAQGG+9b3LytI3u+uBR2/99JeGbj1v3E1bH3zkz1tXv7Vua0ObeNXtRZX52O9cvBUAQuWO\nW+2k/1gZbXrtfmtu/FetuYZ+yzfcnP/qOV8WSvwr62LXKWQfhSqkLI2ltuH3wrLrl9f6ZbvmMUp7\nP6T1NByY5sEp9bjLMQxQvm3oPf1SW9kapfz6f2WJQyIWwjMZ4+EZm8rQSPXRpmurz3Lss9ht1LZ+\nqe/X9rnarstc+8n1mca8BxV7LA29/bp+vi51W8h5a8jrvbby1Kd856GQfy/E7xV7f66PdlpbGWr7\nd05d/g1TLnUtY5jVqswpfd8WMkRgbeejvs5Xqdsspi7qUub6vp8CAAC0RBddeqtd+9O7rSQ7me28\n086mn1tttY+Snz7tvPNO1vGgT9jAo75ig77x1SQ7R9lfDeHDjZvsX44cbU89s7Kg9S8Y/e/2n5d8\nzwDAtTrgG1ZOBMLQ5KmzRUNEqdNKHTsemNEQPRpSqTYawmft2rUlz+vUUDRckYYpUnCvKXUsKUDn\n87MAANCc6HtV/3YIh/XzOf+a4o+CAAAA0HL9190P2vDRVxX1GQ1tvzUT/dpll12sa6f9rVsm2NWm\nze729tvv2Ztvbcj0h22wt995PxkK8av/fIgdnwmIfaHHZ+0T+9TPnN2hRxY9aV8/8cKC1p3zsx/b\niQN7GwA4AmFokXzuNP8lvjq0mnpgqxQK7K1fvz6ZY6wpaC5BRAAA0igr3LPIRfOaae7NusxTCQAA\nANSHV/6x2roefnJRnznk85+15X97LgmGZWJi1mavPazHoQfbkQO+aP/c83O2z95t7Z13P7AN77xn\nGza8azvtvJN1yQTM9txjdztw/72T9+vToJMusQW//1P2bw/cxZ55bJZ9qsuBBgCOQBhatJYwFI8y\n3koZHrE+qOOQzkIAQHPXlIeGBgAAANwnD/u2vbF6XcHr5wos7bF7a+tx2MH23RO/Zsd8/cvWqeN+\n9tGWj2zL9uWjrZlly1ararVLJii2m5XDhg0b7N1337VWrVpZmzZtrHXr1jtkhXXt0tlef/1Ne+/9\n97Ovdc6U7YUn7jAACBEIAwAAAAAAAIAKM/oH19v0239t5dKqahfrWn2gHXfkv9ixmeWfD/8n22OP\n1lZuCxYsSIJf2f1mgmGf+cxnkvl5B5xwvv3hsb/m/Oyp3znSfn7dBQYAoXIHwnY2AAAAAAAAAECj\n+rfj+1o5bdq8xZ594RW7bvo99m8jJtrAk8fZrZlA2z/eWGPl8uc//9kef/zxGplpmzZtsmeffdY2\nb95sJxzbK+/nvzW4vwFAfSMQVg80fJ+Gt0O6YutHQxlVUn1W2vE0JLUdn+elJWvO9xi1f83Xo2Oo\njeaomz17tlUivw/osZJwjbZMasuFXNMAAAAA8uvzlW61ztu1yy672Oc+e3Dqe5/+VJfU1xWk2rDh\nPfu/xX+xc350k/3zv46y4aMn2/wH/5gJlm22uliyZIlt2bIlmWM+pCCYXjv+6K/m/Gx1p/3tGwO+\nZABQ3yo6EKYORnWkDhgwIFmGDBnSIB106rhVR29zMGvWrKRevI4aotM5rh/tf9q0aTnXnzdvXlK2\nhqTypS35ylmohjge30dT6WR/+OGHd6jLsWPHFh3M0fWszzm1nXxttr7rQdtVefz6qa0jWPeftHoo\n9rqLryFtoxxts1CqV+0/rte0a0brhnQO27Vrt8M8PWoL4bmVYcOG2XnnnVdy0E/nI60MhQrvj2nB\nu/j8F3Me1Raa0jWai447/N7UtaxzmEt8jdamMe7vMV07cRvReUl7XdQOSjnv/m+SXP8O0fvaX776\n9esk173Gy13b/SBfOUqhelDbqCuVKVfZdOyF/HslXx3Vdk2Xem4BAACAcqmq2sXOP/vf866joNMz\nz76Q+t7zK1ZabfT5195YY/919+9t8Cnj7dAjTrMfTJxhq15+3UrhmWArVqzY4T3NYVbdcf/kuNJ8\n75RjDAAaQsUGwtSZcfjhhyedHoMHD046VNu3b5+8VmqnaKVRZ4+WHj16JPWjjunhw4c3aIe66LxU\nV1dbuagTrGvXrnX6dbrajT6vOgkXdeA3RTresF2rTn1pCl588cWkTsO6VIetOhrzdfoWIjwn2l5Y\nD9pPfdaDrh/tb8yYMcl1pPtLvsCG3lM9qDxhPei6q2vwPG1y3PrgHcU6jvBY/djyHb/eV31dd911\n2dd0/pMxw6NzJ6qfCRMmlFw32rb2uWzZMiuWB3R0XnV+dVzx+dXfut/ofQ/alfP+qW3FQSKVqaF+\naKFj09KzZ8/sa95+y0X12dj3KbVHL4MHKNUmdT7T2o7e9/Ouf1/Udt5VZ77NiRMn7nCN+DWl+7iC\nNGmBX9+GlvD6cR5k1zZUnnxBLu1P24iD0Y3Jj0/XVFod+ft+Pfq/V8K68uslVx1pG6oj/zePB9ac\n6sV/0BCe22ICuwAAAEA5jDptsLVvu6c1BPUlvPjSazb1lv+xT3/5VDvlrP+0Pz/5XFHb8D69t956\na4e+uL322st23jm9+3m/T3SwC0Z9y5q6dRveTR7vXbCo5GBhIR5e9KRdP+OeZB+3z3nAGoIfW22u\nnzE39fXzf3xzwXVy/o9vsUuvucOaq7TjvCFTL4XWYazUz4nayZNP1Qw8N+e6bShVVqG8c/2hhx7K\ndvao00TUqXHCCSfs8JnaOuTq+n6h69T184Wsow4hdRQpQBHWj56rE8oDh8Vst9T3Z86cWdT6hayT\nLwhW6Dno379/0glfF+Xu5M13vOvXr8/+rbJrKWYbha5Tl2OK69Pbmzodw20Wuo+5c2t+Eas9h/Wg\nDvx4nUL2Uej+FbhR+XU/0aKOWHVA56p75x25TtebOmD1GH+2kLJMnTrV6nIcxcgVuPRrTtdzrn2q\nfsI24EM8qvwKOKT9SEEd0dqn3ku7b+eie5y2Xerx6/7obVO0bwUylCGi13wouPAeumrVqhqfKUba\nudJraVlodbm/FdMmdKxhe9R+Va865lK2m7aOvnf8u7k2pRxbbZ/R8Ygfp/7u169f0k7TynXvvffu\ncN51z1F7yXXelSmlbaqdK9AT0z1D5dS9SnWedn7V3jwwk3YdeFvXNmr7cYHe1zbS6qWc7aeYz6j8\n+epI9w6dD11fovKrnsI2qntEvjrSces934Y+p8Ch9q3nHswMvzP83Oa6xwIAAAD1YY/dW9s5p59o\nlzVCx/acuQuT5TOf+qSdMXygnXBMr2T4wnx69eplf/nLX5J/+z/zzDNJxtnBBx9sHTt2tN12282e\nfnaVbd68ZYfPKRssV6ZYuSmIER6HByEUcMz3nnxz+ET73T1XW89DD7Z27fbKuc347zTadhjkjPel\nv9tlnh9/TK+Cyl7b8aatG25PAZVh3z4q+3favvTZfkd0T/18GMyprVzLnnohqcdc68Z1k3Y8+fZV\nW92mbSf8XNq5CP8+bcw12fL7+8cfc0TO9WurD29XhZY1XEfP165/p8Y6g48+InXdQsrSUlRsRpg6\nNtQREv/iWR1V6kwJf22szg91cGqJM2v0a2EfJkfvK6U3/nVw/Pn4l9jal7ajz2oddfJ4R5ce9Rlt\n07Mi0vgvlb0M8TBs2r5+6ZyvnCF15qnjJ64fdcQreBCWT9v0ssfHV4760WfDX9OrYytcX2VNq4u0\nMnk9+HbDsnjmiX+m1OHW1CkWd9Sp8zR8Ld5Xvo7J+Pglboe5tqe60d+iDj5vP+HrubYRDvnk6+c7\nV3quY/TzXOg8T/movfm2pbZ2HvN68vIrEJGvHnwou1zXe5gNov2rPeXbv64fL7vqV3+H2TOF8o5c\nlT+sh/CekS/DIx5eND4OP1d+vwmP2V8r5Hrw4FJagNjvqbk6vH3uqDCwovrSjxV0T87XUV5spqr2\npfOhcpaaxakxzr19plHgzjP7nDrhawtUxeL7nZ9nz2oJz5k/etar1o2/Q9Ku3dru42n3KB+mLzzX\nHjAIjzm8Z4Tfbbn2Ha+TlvUWlyPfNatr3Ie580BlXC4/vrT96PPhMXoANFcwW/WmazysA//OzJUN\nqeCwtpmrjevfKlonXwBd157ubbnas95TsKa2ILzoPHrbztV+4qB0WJ9a8n2naV3/t4Gf99ru5Tq+\n2uooDjRq3bDOdS/JVUd+XeoadX6/9n9jeAA0pF+25styBQAAAOrLmNOH2N4d2lpDU+BKnlvxd7tg\n/PQkS+zrQy6wmb9cYM+/+GrqZ/bYYw877bTTrE+fPsm/s7WN/fffP5spdu2N/73DZzp33M9Gf2+w\nNQRlIk27da7964kXJoEDBSCUybTsry/UeE/Bguszz/Xe9869OsnK0tI3EwRSNtjszHN9RgERLcrA\n8SwcbVPb0etp2Vy+XwWe/DP/Mf6W5G/fl1v21IrkdWWIaXva75f+9ezkvcuu+UVSPi16P6btaLva\nh45Jj759lUGvaXvfHD4pORaZvX3fKp+ee118PfOY1FOmPOdntileHl/HhfWWq1xej+E50CLhvmI6\nhvAchXUQbu/Sqz8+H9peWLfhsft2Ls1sR+trO34+9Z7KEJZRWV9h+bWe6u+++duea924TFr87xtS\nsuly1YfWjcsanncdjz4jXhZfx8+R2oqO/UtfP2uHY9H13JJVZCDMOzzSOqT1mjo6vLPFO1/0C2Cl\nA6tzKOz81rb8l976Bbg6mvS3dxrrUR0v/r46s+IOa3UG6TV1rGodDcsTdshpX+p00mfTfnXsHYn6\nAtEkk9qGyh/OL+PDkqmTJyxnrmEgc9WPd0z7e6oL7Uv71aKOonAooULrR/Waq370uh+HyqVOb19f\n5yVePy6TOsi8PrV978gKn/sQadqePuPnubZh7Dx44IuofCpTGDhQ56vXmQ8bF7YptbFcgYzw+F2Y\n4aVthdtTXWt7/gt6nS/Ra55dp2MMOx3DMuk9Dwj7Mfj6aqO+qI7j+bi0P62r99PmdCqW71/7KqSd\nx7yevB702Xz14JlFcTvwdfRc14Dv34cby0Xt3Yfs8votJQPJ24Z34Pox+z1D13W+jmStG15DOg7d\nZ+Lj8OEYw6CSzoE+W1sHehhcShtSTe/7+VLntwIeYbDVM1ZKGY5Nx1LMfEYqp46n0EyjND6spvjc\nTvrbO9LTslzC9Qul9qi269ectze1Yc/S1fs6Hn/0516XHmT0a1f3ovC6Udn9+lZ78Humv6/96BqK\nyxUHfLSdMDjowRm1CW1X95W0HzqEbVllD4eYrC1w6MOPxtdseO/Sc107WkfnJ+17x4e7Dfl3byHB\no/Az8Xn367Y5BEziDDhZuT0z09uh2kI4B6CfZ93vVN+qT33P5wqGeRA1GWIlU//a5srt8/WVSm0s\n/DeLt/kwsJWPnzP/sUH4uh+nrov4nqFsvrrcRwAAAIBSKSto0g8L77Tu1PEgK4e9O7S3XXapmaX1\nyOK/2On/MdU+/9UR9oUBZ9p/XHKz/Xbh/7MNb7+XXUf/X3TkkUfayJEj7Vvf+pZ9+tOfToINY8f9\n1G6/67c77OdHY75rn9intBFcirFue9bMlEvPtGszy8rMc2V1/XzaBdal0/7Je8qkUcbT7Xc+YKd+\n+6jMcmSS6aOAjv5+JPMYZtto3fEXDE228eRfVyTraZvah16v7nTADuWYlglwjL/w1OT9devfTYa1\nU4aZ/r72srNSg0ei97X0OPRTSVmXZoJXKlNS3pSAm/Y95vtDkrL1O6LHtuPevn1lDl172ZnJca/b\n8I71OOzg5DPKCNP73TN/6zNaT0Eyva/taN9hefR5X+fjen43OZ4fb38/FtajAnXarha1ER2XPhPv\nS1Qu1bE+p/LdN//RzH6fz34+rNspmWPzutX6Yd0+vGiZnZOpF712fOY9bafnYZ9Kjl3bUdlVV+d+\n/4Rk+7Pn/DZZX+WenWm/Yfnbt90rqUe1ExeXaf36bVlm2l/fIJsurT4UzNK2kn1lzmn19rpQnXjG\noupar/1s+/Z1nrwNxs7dfpzjLzglKZfqZ0qmHrTusKDMLVHFBsJiHrjwJewgVCeHdwqpE12d6WEW\nkg97pg5BdQap48TnDVGHsj6rz+n9uPPVh5JSx5F3Kmpd78Rxel/7SAtOeXl9HhNtQ+vrtbicKp+X\nU8eRa24cdWYV0mGvji8f6kyLBw3CDsV89ePDFvl8JLV1Tqs+tZ6v74HLfGUKszDCjvawI1vb03a0\nf73mQyPF2WYhfUa/jA8X34e245/VvsNf2OvRO6zF91XKPEXiw/v59ryO1aEXHm+uIIO3nfD4feio\nuCMzrHcfesq3oef+eS9TvoyZNB7U0+JzMKk9aHvezj0rIGznYUAlTan14MMahhlp/p62oWPMN8yd\nt0GV3a/xQqjteD149oT2p7L4kHvad3jPkNrqQdLuF2GA3Y/X74HaZiFDDhYSXFJ5vf3reRhsVXst\nJVtOfC61lQVkWml/cSZTSPUdX9e+pGUMeUaLB1gLCeQVExDxdqMlDCSF9y9/nvaa8wClthN/P+i5\n76PL9nnXwjbh10RI7SK8vv08hudf6+hv/97R87AtpbVl328hGX7h92d4zYbD2Dm1dx/ur9DvHZXP\ng40tRZwB53RevI34/Fphdp0PYan69X9raL1cbT3tezz8t1dd6bvD21yh1A48ECjxv8Ni/sOJug6R\nDAAAAJTqzOGDrPdXDito3dWr11g5vPqP15KhDUO7VO2S+X/jbV3If1n+ot3ws3l27Hcutn0+M8QO\n7XWaHfedcUlw7CfX/pdNvv5Ou+jSn9m/jZhoB39xqN348x373f75C/9k3xt6rDWE9RpqsN224eCq\nOx+QBHd8rifPaFr18mtJ8EHBJWXN6PW0YJYLg1badvtMECwcKrB9uz1TyvFOEtwUva9h7QqZB0wB\nnNBOtjUpryiIE9N7/pn4swqmaK4vHdva9e/u8DnVix5VDwrCPBkEurat83qSOZVWNwq6dO68f5IZ\npkyp2vgQk+0yQaX124NhaVS32q7K1TMTJFMAaGumFpz+Tqvb+xbULMO64Hj9/NwblPPeHdZ/J1sf\nCo7VeC+zv5VReeMybQum9kqCXI/kCHLG5dO+fnzh0GS/aoeqZ68n7dPrQ9vXuV0WnR8XtyvVT+ft\n7bP79uBnS1Wxc4TF1JHjnTBafI4T/yV02AGqDJOwcyTt199h9kW+X5N78EMdKnHQQe/Fv8JPo18k\nqyMpLId3iqqc3llZyrwdtdF+fd6jMOskVFv9FNP57cNO1bVM8Ta1jj4TBhJq61j3TL+Qd5iqI1Ad\nsuo8VEeZd7Z6+dTZpg7HcnT6+fbUfsIsikJ5W47r1QO4oVxtSK+rM1ABG31Ox68AZDFzNkl4DXjH\nv+pZdD3EGShhO68rP9dxPYTzwfi8QKrv2o7Rh4rUZzzbQQEgHwrVM3zSeEez6Ph0DYf1kBbMCwN2\n+fj9ItQ/mDPOMxTVPj17xrMKc/Hh+PKtF8/1pP2pXvzHAoUEsepKda/zkCtrTXTMyjBLk3a+PGNT\ndaDvCc+4KpdSMggL2aZ+COF1rnOuelF71blQHeQLIHiAILw24vnCxDO8clFb9CzEUKFt2b8/09pz\nGNBIK38h50j3o5Y095NnwNV2zPF9V49+f3JqQ7qPFDPnppehrtePZ9nXdt+K6bh1DSvo7Zlg/mOG\nmNq7jxbQkgKlAAAAaHqmXzvWDu9/pm3ctCnveu9/8IHVpnXrXa1tmzb25uq3rBj77r23bcrsf83a\nHfuinn3hlWR5YOETBW1r5513tl9Ov9gaSvX2rC8FrxSg6REEApR9tPKV15OAwyOZwELPw7Zlsa3P\nBEG0fByE2JZllHMfHfdLgh3ahzJwFKzocWjNgIOyfTRcXd9ePZJ1lbFzmRVPZVK2kYJDW604H8+F\n9U6SDeUUVFGW1O1zfputi3AutOy+t89Npc+HwyKKhudT8KdLMC9ZLsqCuiFTFwrKPPnUC9Y9ygIL\nqW4VkNNnHtke2NM51BCCK7dnkhVStwruJXPu7WTJcSo76uE8AaqemX3oXFZ37pENOOVrB3GZ1mbW\n7ZDM9XZEzsCg1tX2FNhKgrGdt2XZKeOsenvWnuueaU+3J0NzrkjNuMtH27/s6tuT+lEZw+zGlqYi\nA2H+S/kwWOBDpYVBL39fwaiwY0adhoV2fCizqpD348wZ/V1IECyfunSgqiMoLZjiHb7+y3p1nOpR\nHUiqE9VfMcMbFRsIytUpFfLz50MlFVomdfyGc4f4fGj5ypKrHXgwQfv2+dacD8Pov7CXeL6uYvj2\nwqyN/kUM5eX1mVavxZwfHa/qUO1Di2cE5MuYinkAOk2+QGs5gwX5thUeow+vlusY1RnrAVGVW+1S\nATCtW1vncDisXaFlLCToWwjP6FOb0tBlYRA3Fx8C0wOZXg6vg1yZgX59NhQF3dTRrgCK3xP0wwad\nT73uGV3FdGz7uj6XUDgMaqy2edIai2cb61woOKW68azONDrP/h3gVIcKAsZKOdZyteW68HZZbDA/\n/rdF/F5Tlmvu1DSFHkuh57GUH3Gk8Syt2u6hadTm1Yb9xzGqC/0bJw6Me+BP3+HFtg8AAACg3D57\ncEe7fNxIu3DidKurzZu32AcffmjFev2NN61cJv1wWDZ7qqEo6LE0E3BRUEIBkTAY9j8zJyTv9c0E\nCxSQ0fB4+ltD5XkwS59Ppj7JBFwUIDq33YnZY9AwdAp8adjFZZnP5com8ywrBZ3unjUxeU3D9km7\n7UPo6VHrhI9e1nNPPzE7ZJ6ylxQs6Zcy5J6CHh7Eircf1ru2J9uGRVyWHIPXk+pCATMdk9NzraP6\n0vrjzz8lybDzuvjdPdvmruqbOfa0cvk2RAEzBaEU/MnWRbCvUFwu7UvZZ9rXtqEcu2fXU+Aq3l54\n7NuGSdxW/zo+r9Nwfa8/vf9wp22ZaF5XOnYFVb0dhOclrUz6WwFVPw+x/8mUQ+0qrA9tr/327DYF\nwnz7GvZR2/M2vGr7EJ9h2ePHsC34cfq2W6qKzQjz4X3yddJ7wEzDXpU6B4Q6UfL9sj0cpi+ts7mQ\nLAkdizp+ws51z2Qrdmg658NGqaMn7PDyuYT0vmdMhcP8ldLxVEw2j7afa14z8UyFYsoUvl+uuT58\neCh1iscdxOpsVx2WqwNN24+zbXz+sEL48avewrrQ34UG1LSuD6mlDkIt6pAsNhCWT1o7932X2s5D\nuepBwRN1hGqfaceoQFeuYwyHY1RQQcEwnfu6tDOVRe08rR4KaVNejyFtT23Vh/jy7D6prQ2oHPHx\n+H1Lx+/BZb9vhOcqnE+pHEGx2q51nyMuli+oncbnq/Mh+cLteEe+jic+T7myLxuayqWhKH1iYrVj\nzwLz4Sp1fLkycH2oT6egaVoAUQH+fPd3/dgjLWuo0LbsAYr4XlVb5nAhWaRpGW6F0Lbj720FXv3f\nE01ZMRlw4Tny7/Hw2g6H8Cx0e76tUvl3jr5vi/23iAvbsc8bF8+X5j9oiLPgAAAAgMZy3pkn2rMv\nvGy33vEbK5WywfbcY09bU8sP+mOaLkCd9eVw9mmD7aIx37GGVr19TisXzkMVvxf+7Y/xvFXtg789\nUKUghYITCnykDVno2zs1eM+3qyBO++0Bi/gxXlfyZfSkHWe4/ThIFZZph3oKs+e2P4+PoX2B5Yq3\nt60c3VPfSzumOHga70vH2iPlvITHnqv+w/XD/cRlTCtHvvNSa30En433lRZMDLeXdp7iR19H7dKH\nS1QwsSWryDnCxOdI8TmtRI8+Z4p3WHnGh3ccax0FtwrtsFVnidb1+Ur0PByyyYckU+aEl8M7IQv9\nZbR3PoXZGHpeSCZHvnKHc355ubwTP+zU8yH+9L5nhhRKZc9XPzF11qo8fqzqPAuH0/PsIC+T3o/L\n5OUOszP8PPux+rB2+QKRHgiMl/DYdCw+r4pT57BnoGgbtdVZbeur/PH7cUaF1gnnfYo/r+OP26DK\nXmiAyefu8vPodR/Wtc5TIYHdXMJ27senMvucbIXKNQ+NtqO2HdaDOsN9fqMu2+fiCq+z8BhjPjyb\nd/DG85SVStvVdvzaDOu2kKBj2v1Cxxze07y9hsF0D4LHdefDYoaLf0bl8c7yLsH8h75ttVtfNwzw\nFcuHzXQ6Z2kBc53fuKwK1KlOi5nnx9tDfM1o8UxePapu4vtyGDRU+8gX2K+NB97CetNradeZ2rJf\nN7pOw+tGZQivTx9y0Ntp2I79OzK85rTttLbn90AfctbryOVqy3rM1ZbDOvPvuPiaDdtVmvh7R8cW\nfu9o/55lW6z4+lK59N0S1lddz3t9qC0DTvUanyN9H4ufZz8mbUvr+L8j0viwqP48zjLU9ooJjPtQ\nhR6gTftOLoTf132OynAYVQ+A+5xy4T4aO4MRAAAAuO7yUfb9U4+zUm39aKt9tPWjoj6z55572EEH\nHlDw+gqa5XL2acfbtZNOt0qlrCNlLinbqKEz3oB8PJNQy7mnD7GWrGIDYerY0K+G1YGhQINuxv7r\ndWUTeWeMzwmkjjpfRx2chXa8ewerOmb1eW0n7mjy4bi8HFpHHUyFdpZrPZVZnVD6vDLYPFOr1F9F\n+zbFy+UdQP6LcR8SUR1W2qfK7Z3RhXY+FVI/8fqqL+3TyxQOIellUl2oTOH7YZaKFgW6fHg0H1Yw\nPFZ9Ll/9qXNT64dLOJectqfyxB26Kp86zbS+yqhfzuTqvE5bPx5u04O6/r62E87/48en8uqY08TH\nr/Og/RaaueTnRfvwNqgy+dBqKos6Kesyl5fqSNesn1st6igtZo4WtTNvr2l0zGE9aH2/Pj2ry9ue\n13Wu4eP83qE69/X9ddVTOB9dscJrU9tVmQq93v3aDo9D5yrM8PGgYBhM9+BAqR2+Om5d22Eb07Xh\nbcznOSyljahNhPdk/e3BnPqi+lJ5c10zafdl1WcYXFEgwIMBpfDvCZXBA1QKSugcaZ9hIEGv+XXj\nQ7N6e1EbVr37sfj8hv6+AgLeXuMAkWcfp30neuBRj9quZwWGfN68sC3nu6bjOtO6ajvhNVvbkHXx\n947u22Eg1dtTKd+fOh/hd5TKpe2EmVYKsvj5aipqy4ALz5HuX35fFJ8vU+fX61NtM5zrMKZ6UrvJ\nVUdqc8XUkQcydR3G38vFBNS0X5Xfv1vCDFIPBmpf8T7qch0DAAAA5bDrrlV245Xn2Cn//q9WCs0x\ntm5d4aMLybvvvmd/f/UfBa27xx67W5fqTqnvqczX/eRsq6qq2IHJADQDO1Xtf1R58lu32/Ta/dbU\n+K/k8801VMg6hewjX8daIevUJgz2lEshx+5DnJWa6VLKsde2z1Ler+t5LkaxdVbX4y1kfqJyHH+u\nNhgPf1YXdWnn5bgWi91/Xa+PXOp6z8hXLg8Se4BMnb/qwM83j1sh8rUxbV8d0B7oK4T/mEHl8npQ\nZ73K3RDz9xRyDvK1l3JcF9p+uO2wTF4/qlMFe/Jd37mOxT+jRwV2w6CrD22YL+hR7u+/tDor5VoI\nP+NZkQq2q+3rhxB1HSo31/VVznthOaSdVxe2HwXK6vo9JD6vpa7Z2tocAAAAgOJ89NFWG3vJzfbT\n25rWj+9yOf3UY+2GK8+1nXfeyQCgGK0O+IaVU4sIhAEAPubDs4bBJc+STJtjq1y8Qz6eeysfBS3C\nub98iNZwXr7mZuX2OdvKwYNUnuGHbeIsNs8oKtc8kZWiPtqP6l4ZiJU2x1a+oSABAACAhrR58xa7\nYMJ0u+nnTTsY9v2hx9p1V4yyXVuRCQageOUOhHEnAoAWRJ3dq1atqjE3jhSTpVUqH35Sw5sVMtSj\nOug1tGgYnFNwoyHKWp9UD+GQr3XhgQzNwRYO/9fSeb145pGGlGyIDMLmpj7ajwK9CoSVq403FQTB\nAAAA0FRUVe1i111+th243942fvJs++ij4ub+qm+7tmpll18y0s4740QDgKaCjDAAaEHUQa0O3cbM\nHoqH+stFZSW4g7qor2FLAQAAAKApWPXy63bS6VfYH5f8zZqCPl/pZrdcO9Y+e/AnDQDqgqERAQAA\nAAAAAACJn90x3/5z2q/spVdet1LstNPOtnVr6Zlle7dvY5MuGmZnDh9kAFAOBMIAAAAAAAAAAFlv\nrl5vN/58XhIUe2P12oI/t1vr1ta5c0d79rkXrFjt2+5p55x+op17+pDkOQCUC4EwAAAAAAAAAMAO\nNm/eYlffdJf9PBMQW1Vihlht9t27nf3H2d+0UacNtj12b20AUG4EwgAAAAAAAAAAed3/0BN217yF\ntvDRZfbSK29YXey3bwc74bhe9s1BfZK5wKqqdjEAqC8EwgAAAAAAAAAABXth5T9s2V+ftz8tfcb+\n8tQKW73mbXv51Tdtw9vv2ocfbkrW2X331tauzR7Wru1edug/VVuXTgdY90M+Zf16dbdPHrivAUBD\nIRAGAAAAAAAAAACAilTuQNjOBgAAAAAAAAAAAFQgAmEAAAAAAAAAAACoSATCAAAAAAAAAAAAUJEI\nhAEAAAAAAAAAAKAiEQgDAAAAAAAAAABARSIQBgAAAAAAAAAAgIpEIAwAAAAAAAAAAAAViUAYAAAA\nAAAAAAAAKhKBMAAAAAAAAAAAAFQkAmEAAAAAAAAAAACoSATCAAAAAAAAAAAAUJEIhAEAAAAAAAAA\nAKAiEQgDAAAAAAAAAABARSIQBgAAAAAAAAAAgIpEIAwAAAAAAAAAAAAViUAYAAAAAAAAAAAAKhKB\nMAAAAAAAAAAAAFQkAmEAAAAAAAAAAACoSATCAAAAAAAAAAAAUJEIhAEAAAAAAAAAAKAiEQgDAAAA\nAAAAAABARSIQBgAAAAAAAAAAgIpEIAwAAAAAAAAAAAAViUAYAAAAAAAAAAAAKhKBMAAAAAAAAAAA\nAFQkAmEAAAAAAAAAAACoSATCAAAAAAAAAAAAUJEIhAEAAAAAAAAAAKAiEQgDAAAAAAAAAABARSIQ\nBgAAAAAAAAAAgIq0U9X+R201AAAAAAAAAAAAoMKQEQYAAAAAAAAAAICKRCAMAAAAAAAAAAAAFYlA\nGAAAAAAAAAAAACoSgTAAAAAAAAAAAABUJAJhAAAAAAAAAAAAqEgEwgAAAAAAAAAAAFCRCIQBAAAA\nAAAAAACgIhEIAwAAAAAAAAAAQEUiEAYAAAAAAAAAAICKRCAMAAAAAAAAAAAAFYlAGAAAAAAAAAAA\nACoSgTAAAAAAAAAAAABUJAJhAAAAAAAAAAAAqEgEwgAAAAAAAAAAAFCRCIQBAAAAAAAAAACgIhEI\nAwAAAAAAAAAAQEUiEAYAAAAAAAAAAICKRCAMAAAAAAAAAAAAFYlAGAAAAAAAAAAAACrS/w/KxlsM\nVuSYyAAAAABJRU5ErkJggg==\n"
}
},
"id": "bf95cf4b-a3e9-442a-9f8d-fb7fea23c4d9"
}
],
"nbformat": 4,
"nbformat_minor": 5,
"metadata": {
"kernelspec": {
"name": "ir",
"display_name": "R",
"language": "r"
}
}
}
 \n",
"
\n",
" \n",
"\n",
"*This notebook was prepared by Laura Nelson in collaboration with [UBC\n",
"COMET](https://comet.arts.ubc.ca/) team members: Jonathan Graves, Angela\n",
"Chen and Anneke Dresselhuis*\n",
"\n",
"## Prerequisites\n",
"\n",
"1. Some familiarity programming in R\n",
"2. Some familarity with natural language processing\n",
"3. No computational text experience necessary!\n",
"\n",
"## Learning outcomes\n",
"\n",
"In the notebook you will\n",
"\n",
"1. Familiarize yourself with concepts such as word embeddings (WE)\n",
" vector-space model of language, natural language processing (NLP)\n",
" and how they relate to small and large language models (LMs)\n",
"2. Import and pre-process a textual dataset for use in word embedding\n",
"3. Use word2vec to build a simple language model for examining patterns\n",
" and biases textual datasets\n",
"4. Identify and select methods for saving and loading models\n",
"5. Use critical and reflexive thinking to gain a deeper understanding\n",
" of how the inherent social and cultural biases of language are\n",
" reproduced and mapped into language computation models\n",
"\n",
"## Outline\n",
"\n",
"The goal of this notebook is to demystify some of the technical aspects\n",
"of language models and to invite learners to start thinking about how\n",
"these important tools function in society.\n",
"\n",
"In particular, this lesson is designed to explore features of word\n",
"embeddings produced through the word2vec model. The questions we ask in\n",
"this lesson are guided by Ben Schmidt’s blog post, [Rejecting the Gender\n",
"Binary](%22http://bookworm.benschmidt.org/posts/2015-10-30-rejecting-the-gender-binary.html).\n",
"\n",
"The primary corpus we will use consists of the\n",
"150 English-language novels made\n",
"available by the .txtLab at McGill University. We also look at\n",
"a Word2Vec model trained\n",
"on the ECCO-TCP corpus of 2,350 eighteenth-century literary texts\n",
"made available by Ryan Heuser. (Note that the number of terms in the\n",
"model has been shortened by half in order to conserve memory.)\n",
"\n",
"## Key Terms\n",
"\n",
"Before we dive in, feel free to familiarize yourself with the following\n",
"key terms and how they relate to each other."
],
"id": "d3bcd253-d9a3-4381-ab13-dce0115e3b66"
},
{
"cell_type": "raw",
"metadata": {
"raw_mimetype": "text/html"
},
"source": [
""
],
"id": "f3152375-c59d-4ad2-8732-e939246204b8"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"*This notebook was prepared by Laura Nelson in collaboration with [UBC\n",
"COMET](https://comet.arts.ubc.ca/) team members: Jonathan Graves, Angela\n",
"Chen and Anneke Dresselhuis*\n",
"\n",
"## Prerequisites\n",
"\n",
"1. Some familiarity programming in R\n",
"2. Some familarity with natural language processing\n",
"3. No computational text experience necessary!\n",
"\n",
"## Learning outcomes\n",
"\n",
"In the notebook you will\n",
"\n",
"1. Familiarize yourself with concepts such as word embeddings (WE)\n",
" vector-space model of language, natural language processing (NLP)\n",
" and how they relate to small and large language models (LMs)\n",
"2. Import and pre-process a textual dataset for use in word embedding\n",
"3. Use word2vec to build a simple language model for examining patterns\n",
" and biases textual datasets\n",
"4. Identify and select methods for saving and loading models\n",
"5. Use critical and reflexive thinking to gain a deeper understanding\n",
" of how the inherent social and cultural biases of language are\n",
" reproduced and mapped into language computation models\n",
"\n",
"## Outline\n",
"\n",
"The goal of this notebook is to demystify some of the technical aspects\n",
"of language models and to invite learners to start thinking about how\n",
"these important tools function in society.\n",
"\n",
"In particular, this lesson is designed to explore features of word\n",
"embeddings produced through the word2vec model. The questions we ask in\n",
"this lesson are guided by Ben Schmidt’s blog post, [Rejecting the Gender\n",
"Binary](%22http://bookworm.benschmidt.org/posts/2015-10-30-rejecting-the-gender-binary.html).\n",
"\n",
"The primary corpus we will use consists of the\n",
"150 English-language novels made\n",
"available by the .txtLab at McGill University. We also look at\n",
"a Word2Vec model trained\n",
"on the ECCO-TCP corpus of 2,350 eighteenth-century literary texts\n",
"made available by Ryan Heuser. (Note that the number of terms in the\n",
"model has been shortened by half in order to conserve memory.)\n",
"\n",
"## Key Terms\n",
"\n",
"Before we dive in, feel free to familiarize yourself with the following\n",
"key terms and how they relate to each other."
],
"id": "d3bcd253-d9a3-4381-ab13-dce0115e3b66"
},
{
"cell_type": "raw",
"metadata": {
"raw_mimetype": "text/html"
},
"source": [
""
],
"id": "f3152375-c59d-4ad2-8732-e939246204b8"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" "
],
"id": "f2065b82-c866-4391-8bdb-0b5c00171337"
},
{
"cell_type": "raw",
"metadata": {
"raw_mimetype": "text/html"
},
"source": [
""
],
"id": "a47de43f-5ef1-4139-917f-0a0885cb18bc"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Artificial Intelligence (AI):** this term is a broad category that\n",
"includes the study and development of computer systems that can copy\n",
"intelligent human behaviour (adapted from [*Oxford Learners\n",
"Dictionary*](https://www.oxfordlearnersdictionaries.com/definition/english/ai#:~:text=%2F%CB%8Ce%C9%AA%20%CB%88a%C9%AA%2F-,%2F%CB%8Ce%C9%AA%20%CB%88a%C9%AA%2F,way%20a%20human%20brain%20does.))\n",
"\n",
"**Machine Learning (ML):** this is branch of AI which is uses\n",
"statistical methods to imitate the way that humans learn (adapted from\n",
"[*IBM*](https://www.ibm.com/topics/machine-learning))\n",
"\n",
"**Natural Language Processing (NLP):** this is branch of AI which\n",
"focuses on training computers to interpret human text and spoken words\n",
"(adapted from\n",
"[*IBM*](https://www.ibm.com/topics/natural-language-processing#:~:text=the%20next%20step-,What%20is%20natural%20language%20processing%3F,same%20way%20human%20beings%20can.))\n",
"\n",
"**Word Embeddings (WE):** this is an NLP process through which human\n",
"words are converted into numerical representations (usually vectors) in\n",
"order for computers to be able to understand them (adapted from\n",
"[*Turing*](https://www.turing.com/kb/guide-on-word-embeddings-in-nlp))\n",
"\n",
"**word2vec:** this is an NLP technique that is commonly used to generate\n",
"word embeddings\n",
"\n",
"## What are Word Embeddings?\n",
"\n",
"Building off of the definition above, word embeddings are one way that\n",
"humans can represent language in a way that is legible to a machine.\n",
"More specifically, they are an NLP approach that use vectors to store\n",
"textual data in multiple dimensions; by existing in the\n",
"multi-dimensional space of vectors, word embeddings are able to include\n",
"important semantic information within a given numeric representation.\n",
"\n",
"For example, if we are trying to answer a research question about how\n",
"popular a term is on the web at a given time, we might use a simple word\n",
"frequency analysis to count how many times the word “candidate” shows up\n",
"in tweets during a defined electoral period. However, if we wanted to\n",
"gain a more nuanced understanding of what kind of language, biases or\n",
"attitudes contextualize the term, “candidate” in discourse, we would\n",
"need to use a method like word embedding to encode meaning into our\n",
"understanding of how people have talked about candidates over time.\n",
"Instead of describing our text as a series of word counts, we would\n",
"treat our text like coordinates in space, where similar words and\n",
"concepts are closer to each other, and words that are different from\n",
"each other are further away.\n",
"\n",
"
"
],
"id": "f2065b82-c866-4391-8bdb-0b5c00171337"
},
{
"cell_type": "raw",
"metadata": {
"raw_mimetype": "text/html"
},
"source": [
""
],
"id": "a47de43f-5ef1-4139-917f-0a0885cb18bc"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Artificial Intelligence (AI):** this term is a broad category that\n",
"includes the study and development of computer systems that can copy\n",
"intelligent human behaviour (adapted from [*Oxford Learners\n",
"Dictionary*](https://www.oxfordlearnersdictionaries.com/definition/english/ai#:~:text=%2F%CB%8Ce%C9%AA%20%CB%88a%C9%AA%2F-,%2F%CB%8Ce%C9%AA%20%CB%88a%C9%AA%2F,way%20a%20human%20brain%20does.))\n",
"\n",
"**Machine Learning (ML):** this is branch of AI which is uses\n",
"statistical methods to imitate the way that humans learn (adapted from\n",
"[*IBM*](https://www.ibm.com/topics/machine-learning))\n",
"\n",
"**Natural Language Processing (NLP):** this is branch of AI which\n",
"focuses on training computers to interpret human text and spoken words\n",
"(adapted from\n",
"[*IBM*](https://www.ibm.com/topics/natural-language-processing#:~:text=the%20next%20step-,What%20is%20natural%20language%20processing%3F,same%20way%20human%20beings%20can.))\n",
"\n",
"**Word Embeddings (WE):** this is an NLP process through which human\n",
"words are converted into numerical representations (usually vectors) in\n",
"order for computers to be able to understand them (adapted from\n",
"[*Turing*](https://www.turing.com/kb/guide-on-word-embeddings-in-nlp))\n",
"\n",
"**word2vec:** this is an NLP technique that is commonly used to generate\n",
"word embeddings\n",
"\n",
"## What are Word Embeddings?\n",
"\n",
"Building off of the definition above, word embeddings are one way that\n",
"humans can represent language in a way that is legible to a machine.\n",
"More specifically, they are an NLP approach that use vectors to store\n",
"textual data in multiple dimensions; by existing in the\n",
"multi-dimensional space of vectors, word embeddings are able to include\n",
"important semantic information within a given numeric representation.\n",
"\n",
"For example, if we are trying to answer a research question about how\n",
"popular a term is on the web at a given time, we might use a simple word\n",
"frequency analysis to count how many times the word “candidate” shows up\n",
"in tweets during a defined electoral period. However, if we wanted to\n",
"gain a more nuanced understanding of what kind of language, biases or\n",
"attitudes contextualize the term, “candidate” in discourse, we would\n",
"need to use a method like word embedding to encode meaning into our\n",
"understanding of how people have talked about candidates over time.\n",
"Instead of describing our text as a series of word counts, we would\n",
"treat our text like coordinates in space, where similar words and\n",
"concepts are closer to each other, and words that are different from\n",
"each other are further away.\n",
"\n",
" \n",
"\n",
"## Making a Word Embedding\n",
"\n",
"So, how do word embeddings work? To make a word embedding, an input word\n",
"gets compressed into a dense vector.\n",
"\n",
"
\n",
"\n",
"## Making a Word Embedding\n",
"\n",
"So, how do word embeddings work? To make a word embedding, an input word\n",
"gets compressed into a dense vector.\n",
"\n",
" \n",
"
\n",
" \n",
"\n",
"**Skip-Gram** does the opposite, taking a word of interest as its input\n",
"(for example, “me”) and tries to learn how to predict its context words\n",
"(“Call”,“Ishmael”).\n",
"\n",
"
\n",
"\n",
"**Skip-Gram** does the opposite, taking a word of interest as its input\n",
"(for example, “me”) and tries to learn how to predict its context words\n",
"(“Call”,“Ishmael”).\n",
"\n",
" \n",
"\n",
"In general, CBOW is is faster and does well with frequent words, while\n",
"Skip-Gram potentially represents rare words better.\n",
"\n",
"Since the word embedding is a vector, we are able perform tests like\n",
"cosine similarity (which we’ll learn more about in a bit!) and other\n",
"kinds of operations. Those operations can reveal many different kinds of\n",
"relationships between words, as we shall see.\n",
"\n",
"## Bias and Language Models\n",
"\n",
"You might already be piecing together that the encoding of meaning in\n",
"word embeddings is entirely shaped by patterns of language use captured\n",
"in the training data. That is, what is included in a word embedding\n",
"directly reflects the complex social and cultural biases of everyday\n",
"human language - in fact, exploring how these biases function and change\n",
"over time (as we will do later) is one of the most interesting ways to\n",
"use word embeddings in social research.\n",
"\n",
"#### It is simply impossible to have a bias-free language model (LM).\n",
"\n",
"In LMs, bias is not a bug or a glitch, rather, it is an essential\n",
"feature that is baked into the fundamental structure. For example, LMs\n",
"are not outside of learning and absorbing the pejorative dimensions of\n",
"language which in turn, can result in reproducing harmful correlations\n",
"of meaning for words about race, class or gender (among others). When\n",
"unchecked, these harms can be “amplified in downstream applications of\n",
"word embeddings” ([Arseniev-Koehler & Foster, 2020,\n",
"p. 1](https://osf.io/preprints/socarxiv/b8kud/)).\n",
"\n",
"Just like any other computational model, it is important to critically\n",
"engage with the source and context of the training data. One way that\n",
"[Schiffers, Kern and Hienert](https://arxiv.org/abs/2302.06174v1)\n",
"suggest doing this is by using domain specific models (2023). Working\n",
"with models that understand the nuances of your particular topic or\n",
"field can better account for “specialized vocabulary and semantic\n",
"relationships” that can help make applications of WE more effective.\n",
"\n",
"## Preparing for our Analysis\n",
"\n",
"#### Word2vec Features\n",
"\n",
"**Here are a few features of the word2vec tool that we can use to\n",
"customize our analysis:**\n",
"\n",
"- `size`: Number of dimensions for word embedding model\n",
" \n",
"- `window`: Number of context words to observe in each direction\n",
" \n",
"- `min_count`: Minimum frequency for words included in model\n",
" \n",
"- `sg` (Skip-Gram): ‘0’ indicates CBOW model; ‘1’ indicates Skip-Gram\n",
" \n",
"- `alpha`: Learning rate (initial); prevents model from\n",
" over-correcting, enables finer tuning\n",
" \n",
"- `iterations`: Number of passes through dataset\n",
" \n",
"- `batch size`: Number of words to sample from data during each pass\n",
" \n",
"\n",
"Note: the script uses default value for each argument.\n",
"\n",
"**Some limitations of the word2vec Model**\n",
"\n",
"- Within word2vec, common articles or conjunctions, called **stop\n",
" words** such as “the” and “and,” may not provide very rich\n",
" contextual information for a given word, and may need additional\n",
" subsampling or to be combined into a word phrase (Anwla, 2019).\n",
"- Word2vec isn’t always the best at handling out-of-vocabulary words\n",
" well (Chandran, 2021).\n",
"\n",
"Let’s begin our analysis!\n",
"\n",
"## Exercise #1: Eggs, Sausages and Bacon\n",
"\n",
"
\n",
"\n",
"In general, CBOW is is faster and does well with frequent words, while\n",
"Skip-Gram potentially represents rare words better.\n",
"\n",
"Since the word embedding is a vector, we are able perform tests like\n",
"cosine similarity (which we’ll learn more about in a bit!) and other\n",
"kinds of operations. Those operations can reveal many different kinds of\n",
"relationships between words, as we shall see.\n",
"\n",
"## Bias and Language Models\n",
"\n",
"You might already be piecing together that the encoding of meaning in\n",
"word embeddings is entirely shaped by patterns of language use captured\n",
"in the training data. That is, what is included in a word embedding\n",
"directly reflects the complex social and cultural biases of everyday\n",
"human language - in fact, exploring how these biases function and change\n",
"over time (as we will do later) is one of the most interesting ways to\n",
"use word embeddings in social research.\n",
"\n",
"#### It is simply impossible to have a bias-free language model (LM).\n",
"\n",
"In LMs, bias is not a bug or a glitch, rather, it is an essential\n",
"feature that is baked into the fundamental structure. For example, LMs\n",
"are not outside of learning and absorbing the pejorative dimensions of\n",
"language which in turn, can result in reproducing harmful correlations\n",
"of meaning for words about race, class or gender (among others). When\n",
"unchecked, these harms can be “amplified in downstream applications of\n",
"word embeddings” ([Arseniev-Koehler & Foster, 2020,\n",
"p. 1](https://osf.io/preprints/socarxiv/b8kud/)).\n",
"\n",
"Just like any other computational model, it is important to critically\n",
"engage with the source and context of the training data. One way that\n",
"[Schiffers, Kern and Hienert](https://arxiv.org/abs/2302.06174v1)\n",
"suggest doing this is by using domain specific models (2023). Working\n",
"with models that understand the nuances of your particular topic or\n",
"field can better account for “specialized vocabulary and semantic\n",
"relationships” that can help make applications of WE more effective.\n",
"\n",
"## Preparing for our Analysis\n",
"\n",
"#### Word2vec Features\n",
"\n",
"**Here are a few features of the word2vec tool that we can use to\n",
"customize our analysis:**\n",
"\n",
"- `size`: Number of dimensions for word embedding model\n",
" \n",
"- `window`: Number of context words to observe in each direction\n",
" \n",
"- `min_count`: Minimum frequency for words included in model\n",
" \n",
"- `sg` (Skip-Gram): ‘0’ indicates CBOW model; ‘1’ indicates Skip-Gram\n",
" \n",
"- `alpha`: Learning rate (initial); prevents model from\n",
" over-correcting, enables finer tuning\n",
" \n",
"- `iterations`: Number of passes through dataset\n",
" \n",
"- `batch size`: Number of words to sample from data during each pass\n",
" \n",
"\n",
"Note: the script uses default value for each argument.\n",
"\n",
"**Some limitations of the word2vec Model**\n",
"\n",
"- Within word2vec, common articles or conjunctions, called **stop\n",
" words** such as “the” and “and,” may not provide very rich\n",
" contextual information for a given word, and may need additional\n",
" subsampling or to be combined into a word phrase (Anwla, 2019).\n",
"- Word2vec isn’t always the best at handling out-of-vocabulary words\n",
" well (Chandran, 2021).\n",
"\n",
"Let’s begin our analysis!\n",
"\n",
"## Exercise #1: Eggs, Sausages and Bacon\n",
"\n",
" \n",
"\n",
"To begin, we are going to install and load a few packages that are\n",
"necessary for our analysis. Run the code cells below if these packages\n",
"are not already installed:\n",
"\n",
"``` r\n",
"# uncomment these by deleting the \"#\" to install them\n",
"\n",
"#install.packages(\"tidyverse\")\n",
"#install.packages(\"repr\")\n",
"#install.packages(\"proxy\")\n",
"#install.packages(\"scales\")\n",
"#install.packages(\"tm\")\n",
"#install.packages(\"MASS\")\n",
"#install.packages(\"SentimentAnalysis\")\n",
"#install.packages(\"reticulate\")\n",
"```\n",
"\n",
"``` r\n",
"# Load the required libraries\n",
"library(tidyverse)\n",
"library(repr)\n",
"library(proxy)\n",
"library(tm)\n",
"library(scales)\n",
"library(MASS)\n",
"\n",
"\n",
"# Set up figures to save properly\n",
"options(jupyter.plot_mimetypes = \"image/png\") \n",
"```\n",
"\n",
"``` r\n",
"# Time: 30s\n",
"library(reticulate)\n",
"gensim <- import(\"gensim\")\n",
"```\n",
"\n",
"#### Create a Document-Term Matrix (DTM) with a Few Pseudo-Texts\n",
"\n",
"To start off, we’re going to create a mini dataframe based on the use of\n",
"the words “eggs,” “sausages” and “bacon” found in three different\n",
"novels: A, B and C.\n",
"\n",
"``` r\n",
"# Construct dataframe\n",
"columns <- c('eggs', 'sausage', 'bacon')\n",
"indices <- c('Novel A', 'Novel B', 'Novel C')\n",
"dtm <- data.frame(eggs = c(50, 90, 20),\n",
" sausage = c(60, 10, 70),\n",
" bacon = c(60, 10, 70),\n",
" row.names = indices)\n",
"\n",
"# Show dataframe\n",
"print(dtm)\n",
"```\n",
"\n",
"#### Visualize\n",
"\n",
"``` r\n",
"# Then, we'll create the scatter plot of our data using ggplot2\n",
"ggplot(dtm, aes(x = eggs, y = sausage)) +\n",
" geom_point() +\n",
" geom_text(aes(label = rownames(dtm)), nudge_x = 2, nudge_y = 2, size = 3) +\n",
" xlim(0, 100) +\n",
" ylim(0, 100) +\n",
" labs(x = \"eggs\", y = \"sausage\")\n",
"```\n",
"\n",
"### Vectors\n",
"\n",
"At a glance, a couple of points are lying closer to one another. We used\n",
"the word frequencies of just two words in order to plot our texts in a\n",
"two-dimensional plane. The term frequency “summaries” of Novel A\n",
"& Novel C are pretty similar to one another: they both share a\n",
"major concern with “sausage”, whereas Novel B seems to focus\n",
"primarily on “eggs.”\n",
"\n",
"This raises a question: how can we operationalize our intuition that\n",
"spatial distance expresses topical similarity?\n",
"\n",
"## Cosine Similarity\n",
"\n",
"The most common measurement of distance between points is their [Cosine\n",
"Similarity](https://en.wikipedia.org/wiki/Cosine_similarity). Cosine\n",
"similarity can operate on textual data that contain word vectors and\n",
"allows us to identify how similar documents are to each other, for\n",
"example. Cosine Similarity thus helps us understand how much content\n",
"overlap a set of documents have with one another. For example, imagine\n",
"that we were to draw an arrow from the origin of the graph - point\n",
"(0,0) - to the dot representing each text. This arrow is called a\n",
"*vector*.\n",
"\n",
"Mathematically, this can be represented as:\n",
"\n",
"
\n",
"\n",
"To begin, we are going to install and load a few packages that are\n",
"necessary for our analysis. Run the code cells below if these packages\n",
"are not already installed:\n",
"\n",
"``` r\n",
"# uncomment these by deleting the \"#\" to install them\n",
"\n",
"#install.packages(\"tidyverse\")\n",
"#install.packages(\"repr\")\n",
"#install.packages(\"proxy\")\n",
"#install.packages(\"scales\")\n",
"#install.packages(\"tm\")\n",
"#install.packages(\"MASS\")\n",
"#install.packages(\"SentimentAnalysis\")\n",
"#install.packages(\"reticulate\")\n",
"```\n",
"\n",
"``` r\n",
"# Load the required libraries\n",
"library(tidyverse)\n",
"library(repr)\n",
"library(proxy)\n",
"library(tm)\n",
"library(scales)\n",
"library(MASS)\n",
"\n",
"\n",
"# Set up figures to save properly\n",
"options(jupyter.plot_mimetypes = \"image/png\") \n",
"```\n",
"\n",
"``` r\n",
"# Time: 30s\n",
"library(reticulate)\n",
"gensim <- import(\"gensim\")\n",
"```\n",
"\n",
"#### Create a Document-Term Matrix (DTM) with a Few Pseudo-Texts\n",
"\n",
"To start off, we’re going to create a mini dataframe based on the use of\n",
"the words “eggs,” “sausages” and “bacon” found in three different\n",
"novels: A, B and C.\n",
"\n",
"``` r\n",
"# Construct dataframe\n",
"columns <- c('eggs', 'sausage', 'bacon')\n",
"indices <- c('Novel A', 'Novel B', 'Novel C')\n",
"dtm <- data.frame(eggs = c(50, 90, 20),\n",
" sausage = c(60, 10, 70),\n",
" bacon = c(60, 10, 70),\n",
" row.names = indices)\n",
"\n",
"# Show dataframe\n",
"print(dtm)\n",
"```\n",
"\n",
"#### Visualize\n",
"\n",
"``` r\n",
"# Then, we'll create the scatter plot of our data using ggplot2\n",
"ggplot(dtm, aes(x = eggs, y = sausage)) +\n",
" geom_point() +\n",
" geom_text(aes(label = rownames(dtm)), nudge_x = 2, nudge_y = 2, size = 3) +\n",
" xlim(0, 100) +\n",
" ylim(0, 100) +\n",
" labs(x = \"eggs\", y = \"sausage\")\n",
"```\n",
"\n",
"### Vectors\n",
"\n",
"At a glance, a couple of points are lying closer to one another. We used\n",
"the word frequencies of just two words in order to plot our texts in a\n",
"two-dimensional plane. The term frequency “summaries” of Novel A\n",
"& Novel C are pretty similar to one another: they both share a\n",
"major concern with “sausage”, whereas Novel B seems to focus\n",
"primarily on “eggs.”\n",
"\n",
"This raises a question: how can we operationalize our intuition that\n",
"spatial distance expresses topical similarity?\n",
"\n",
"## Cosine Similarity\n",
"\n",
"The most common measurement of distance between points is their [Cosine\n",
"Similarity](https://en.wikipedia.org/wiki/Cosine_similarity). Cosine\n",
"similarity can operate on textual data that contain word vectors and\n",
"allows us to identify how similar documents are to each other, for\n",
"example. Cosine Similarity thus helps us understand how much content\n",
"overlap a set of documents have with one another. For example, imagine\n",
"that we were to draw an arrow from the origin of the graph - point\n",
"(0,0) - to the dot representing each text. This arrow is called a\n",
"*vector*.\n",
"\n",
"Mathematically, this can be represented as:\n",
"\n",
"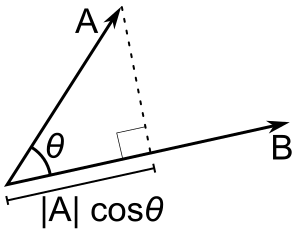 \n",
"\n",
"Using our example above, we can see that the angle from (0,0) between\n",
"Novel C and Novel A (orange triangle) is smaller than between Novel A\n",
"and Novel B (navy triangle) or between Novel C and Novel B (both\n",
"triangles together).\n",
"\n",
"
\n",
"\n",
"Using our example above, we can see that the angle from (0,0) between\n",
"Novel C and Novel A (orange triangle) is smaller than between Novel A\n",
"and Novel B (navy triangle) or between Novel C and Novel B (both\n",
"triangles together).\n",
"\n",
" \n",
"\n",
"Because this similarity measurement uses the cosine of the angle between\n",
"vectors, the magnitude is not a matter of concern (this feature is\n",
"really helpful for text vectors that can often be really long!).\n",
"Instead, the output of cosine similarity yields a value between 0 and 1\n",
"(we don’t have to work with something confusing like 18º!) that can be\n",
"easily interpreted and compared - and thus we can also avoid the\n",
"troubles associated with other dimensional distance measures such as\n",
"[Euclidean Distance](https://en.wikipedia.org/wiki/Euclidean_distance).\n",
"\n",
"### Calculating Cosine Distance\n",
"\n",
"``` r\n",
"# Assuming dtm_df is a data frame containing the document-term matrix\n",
"dtm_matrix <- as.matrix(dtm)\n",
"\n",
"# Calculate cosine similarity\n",
"cos_sim <- proxy::dist(dtm_matrix, method = \"cosine\")\n",
"\n",
"\n",
"# Although we want the Cosine Distance, it is mathematically simpler to calculate its opposite: Cosine Similarity\n",
"# The formula for Cosine Distance is = 1 - Cosine Similarity\n",
"\n",
"# Convert the cosine similarity matrix to a 2-dimensional array\n",
"# So we will subtract the similarities from 1\n",
"n <- nrow(dtm_matrix)\n",
"cos_sim_array <- matrix(1 - as.vector(as.matrix(cos_sim)), n, n)\n",
"\n",
"# Print the result\n",
"print(cos_sim_array)\n",
"```\n",
"\n",
"``` r\n",
"# Make it a little easier to read by rounding the values\n",
"cos_sim_rounded <- round(cos_sim_array, 2)\n",
"\n",
"# Label the dataframe rows and columns with eggs, sausage and bacon\n",
"cos_df <- data.frame(cos_sim_rounded, row.names = indices, check.names = FALSE)\n",
"colnames(cos_df) <- indices\n",
"\n",
"# Print the data frame\n",
"head(cos_df)\n",
"```\n",
"\n",
"## Exercise #2: Working with 18th Century Literature\n",
"\n",
"
\n",
"\n",
"Because this similarity measurement uses the cosine of the angle between\n",
"vectors, the magnitude is not a matter of concern (this feature is\n",
"really helpful for text vectors that can often be really long!).\n",
"Instead, the output of cosine similarity yields a value between 0 and 1\n",
"(we don’t have to work with something confusing like 18º!) that can be\n",
"easily interpreted and compared - and thus we can also avoid the\n",
"troubles associated with other dimensional distance measures such as\n",
"[Euclidean Distance](https://en.wikipedia.org/wiki/Euclidean_distance).\n",
"\n",
"### Calculating Cosine Distance\n",
"\n",
"``` r\n",
"# Assuming dtm_df is a data frame containing the document-term matrix\n",
"dtm_matrix <- as.matrix(dtm)\n",
"\n",
"# Calculate cosine similarity\n",
"cos_sim <- proxy::dist(dtm_matrix, method = \"cosine\")\n",
"\n",
"\n",
"# Although we want the Cosine Distance, it is mathematically simpler to calculate its opposite: Cosine Similarity\n",
"# The formula for Cosine Distance is = 1 - Cosine Similarity\n",
"\n",
"# Convert the cosine similarity matrix to a 2-dimensional array\n",
"# So we will subtract the similarities from 1\n",
"n <- nrow(dtm_matrix)\n",
"cos_sim_array <- matrix(1 - as.vector(as.matrix(cos_sim)), n, n)\n",
"\n",
"# Print the result\n",
"print(cos_sim_array)\n",
"```\n",
"\n",
"``` r\n",
"# Make it a little easier to read by rounding the values\n",
"cos_sim_rounded <- round(cos_sim_array, 2)\n",
"\n",
"# Label the dataframe rows and columns with eggs, sausage and bacon\n",
"cos_df <- data.frame(cos_sim_rounded, row.names = indices, check.names = FALSE)\n",
"colnames(cos_df) <- indices\n",
"\n",
"# Print the data frame\n",
"head(cos_df)\n",
"```\n",
"\n",
"## Exercise #2: Working with 18th Century Literature\n",
"\n",
" \n",
"\n",
"Workshop Run Here at Start\n",
"\n",
"``` r\n",
"# Load the required libraries\n",
"library(tidyverse)\n",
"library(repr)\n",
"library(proxy)\n",
"library(tm)\n",
"library(scales)\n",
"library(MASS)\n",
"\n",
"\n",
"# Set up figures to save properly\n",
"options(jupyter.plot_mimetypes = \"image/png\") \n",
"\n",
"# Time: 3 mins\n",
"# File paths and names\n",
"filelist <- c(\n",
" 'txtlab_Novel450_English/EN_1850_Hawthorne,Nathaniel_TheScarletLetter_Novel.txt',\n",
" 'txtlab_Novel450_English/EN_1851_Hawthorne,Nathaniel_TheHouseoftheSevenGables_Novel.txt',\n",
" 'txtlab_Novel450_English/EN_1920_Fitzgerald,FScott_ThisSideofParadise_Novel.txt',\n",
" 'txtlab_Novel450_English/EN_1922_Fitzgerald,FScott_TheBeautifulandtheDamned_Novel.txt',\n",
" 'txtlab_Novel450_English/EN_1811_Austen,Jane_SenseandSensibility_Novel.txt',\n",
" 'txtlab_Novel450_English/EN_1813_Austen,Jane_PrideandPrejudice_Novel.txt'\n",
")\n",
"\n",
"novel_names <- c(\n",
" 'Hawthorne: Scarlet Letter',\n",
" 'Hawthorne: Seven Gables',\n",
" 'Fitzgerald: This Side of Paradise',\n",
" 'Fitzgerald: Beautiful and the Damned',\n",
" 'Austen: Sense and Sensibility',\n",
" 'Austen: Pride and Prejudice'\n",
")\n",
"\n",
"# Function to read non-empty lines from the text file\n",
"readNonEmptyLines <- function(filepath) {\n",
" lines <- readLines(filepath, encoding = \"UTF-8\")\n",
" non_empty_lines <- lines[trimws(lines) != \"\"]\n",
" return(paste(non_empty_lines, collapse = \" \"))\n",
"}\n",
"\n",
"# Read non-empty texts into a corpus\n",
"text_corpus <- VCorpus(VectorSource(sapply(filelist, readNonEmptyLines)))\n",
"\n",
"# Preprocess the text data\n",
"text_corpus <- tm_map(text_corpus, content_transformer(tolower))\n",
"text_corpus <- tm_map(text_corpus, removePunctuation)\n",
"text_corpus <- tm_map(text_corpus, removeNumbers)\n",
"text_corpus <- tm_map(text_corpus, removeWords, stopwords(\"english\"))\n",
"text_corpus <- tm_map(text_corpus, stripWhitespace)\n",
"\n",
"## Time: 5 mins\n",
"# Create a custom control for DTM with binary term frequency\n",
"custom_control <- list(\n",
" tokenize = function(x) SentimentAnalysis::ngram_tokenize(x, ngmax = 1),\n",
" bounds = list(global = c(3, Inf)),\n",
" weighting = weightTf\n",
")\n",
"\n",
"# Convert the corpus to a DTM using custom control\n",
"dtm <- DocumentTermMatrix(text_corpus, control = custom_control)\n",
"\n",
"# Convert DTM to a binary data frame (0 or 1)\n",
"dtm_df_novel <- as.data.frame(as.matrix(dtm > 0))\n",
"colnames(dtm_df_novel) <- colnames(dtm)\n",
"\n",
"# Set row names to novel names\n",
"rownames(dtm_df_novel) <- novel_names\n",
"\n",
"# Print the resulting data frame\n",
"tail(dtm_df_novel)\n",
"```\n",
"\n",
"``` r\n",
"# Just as we did above with the small data frame, we'll find the cosine similarity for these texts\n",
"cos_sim_novel <- as.matrix(proxy::dist(dtm_df_novel, method = \"cosine\"))\n",
"\n",
"# Convert the cosine similarity matrix to a 2-dimensional array\n",
"n <- nrow(dtm_df_novel)\n",
"cos_sim_array <- matrix(1 - as.vector(as.matrix(cos_sim_novel)), n, n)\n",
"\n",
"# Round the cosine similarity matrix to two decimal places\n",
"cos_sim_novel_rounded <- round(cos_sim_array, 2)\n",
"\n",
"# Print the rounded cosine similarity matrix\n",
"print(cos_sim_novel_rounded)\n",
"```\n",
"\n",
"``` r\n",
"# Again, we'll make this a bit more readable\n",
"cos_df <- data.frame(cos_sim_novel_rounded, row.names = novel_names, check.names = FALSE)\n",
"\n",
"# Set column names to novel names\n",
"colnames(cos_df) <- novel_names\n",
"\n",
"# Print the DataFrame\n",
"head(cos_df)\n",
"```\n",
"\n",
"``` r\n",
"# Transform cosine similarity to cosine distance\n",
"cos_dist <- 1 - cos_sim_novel_rounded\n",
"\n",
"# Perform MDS\n",
"mds <- cmdscale(cos_dist, k = 2)\n",
"\n",
"# Extract x and y coordinates from MDS output\n",
"xs <- mds[, 1]\n",
"ys <- mds[, 2]\n",
"\n",
"# Create a data frame with x, y coordinates, and novel names\n",
"mds_df <- data.frame(x = xs, y = ys, novel_names = novel_names)\n",
"\n",
"ggplot(mds_df, aes(x, y, label = novel_names)) +\n",
" geom_point(size = 4) +\n",
" geom_text(hjust =0.6, vjust = 0.2, size = 4, angle = 45, nudge_y = 0.01) + # Rotate text and adjust y position\n",
" labs(title = \"MDS Visualization of Novel Differences\") +\n",
" theme_minimal() +\n",
" theme(\n",
" plot.title = element_text(size = 20, hjust = 0.6, margin = margin(b = 10)),\n",
" plot.margin = margin(5, 5, 5, 5, \"pt\"), # Adjust the margin around the plot\n",
" plot.background = element_rect(fill = \"white\"), # Set the background color of the plot to white\n",
" plot.caption = element_blank(), # Remove the default caption\n",
" axis.text = element_text(size = 12), # Adjust the size of axis text\n",
" legend.text = element_text(size = 12), # Adjust the size of legend text\n",
" legend.title = element_text(size = 14) # Adjust the size of legend title\n",
" )\n",
"```\n",
"\n",
"The above method has a broad range of applications, such as unsupervised\n",
"clustering. Common techniques include\n",
"K-Means\n",
"Clustering and\n",
"Hierarchical\n",
"Dendrograms. These attempt to identify groups of texts with shared\n",
"content, based on these kinds of distance measures.\n",
"\n",
"Here’s an example of a dendrogram based on these six novels:\n",
"\n",
"``` r\n",
"# Assuming you have already calculated the \"cos_dist\" matrix and have the \"novel_names\" vector\n",
"\n",
"# Perform hierarchical clustering\n",
"hclust_result <- hclust(as.dist(cos_dist), method = \"ward.D\")\n",
"\n",
"# Plot the dendrogram\n",
"plot(hclust_result, hang = -1, labels = novel_names)\n",
"\n",
"# Optional: Adjust the layout to avoid cutoff labels\n",
"par(mar = c(5, 4, 2, 10)) # Adjust margins\n",
"\n",
"# Display the dendrogram plot\n",
"```\n",
"\n",
"#### Vector Semantics\n",
"\n",
"We can also turn this logic on its head. Rather than produce vectors\n",
"representing texts based on their words, we will produce vectors for the\n",
"words based on their contexts.\n",
"\n",
"``` r\n",
"# Transpose the DTM data frame\n",
"transposed_dtm <- t(dtm_df_novel)\n",
"\n",
"# Display the first few rows of the transposed DTM\n",
"tail(transposed_dtm)\n",
"```\n",
"\n",
"Because the number of words is so large, for memory reasons we’re going\n",
"to work with just the last few, pictured above.\n",
"\n",
"- If you are running this locally, you may want to try this with more\n",
" words\n",
"\n",
"``` r\n",
"# Assuming dtm_df is a data frame containing the document-term matrix\n",
"tail_transposed_dtm <- tail(transposed_dtm)\n",
"\n",
"dtm_matrix <- as.matrix(tail_transposed_dtm) #remove 'tail_' to use all words\n",
"\n",
"# Calculate cosine similarity\n",
"cos_sim_words <- proxy::dist(dtm_matrix, method = \"cosine\")\n",
"\n",
"# Convert the cosine similarity matrix to a 2-dimensional array\n",
"n <- nrow(dtm_matrix)\n",
"cos_sim_words <- matrix(1 - as.vector(as.matrix(cos_sim_words)), n, n)\n",
"\n",
"# Print the result\n",
"head(cos_sim_words)\n",
"```\n",
"\n",
"``` r\n",
"# In readable format\n",
"\n",
"cos_sim_words <- data.frame(round(cos_sim_words, 2))\n",
"row.names(cos_sim_words) <- row.names(tail_transposed_dtm) #remove tail_ for all\n",
"colnames(cos_sim_words) <- row.names(tail_transposed_dtm) #remove tail_ for all\n",
"\n",
"head(cos_sim_words)\n",
"```\n",
"\n",
"Theoretically we could visualize and cluster these as well - but it\n",
"would a lot of computational power!\n",
"\n",
"We’ll instead turn to the machine learning version: word embeddings\n",
"\n",
"``` r\n",
"#check objects in memory; delete the big ones\n",
"\n",
"sort(sapply(ls(), function(x) format(object.size(get(x)), unit = 'auto')))\n",
" \n",
"rm(cos_sim_words, cos_sim_array, text_corpus, dtm_df_novel)\n",
" \n",
"sort(sapply(ls(), function(x) format(object.size(get(x)), unit = 'auto')))\n",
"```\n",
"\n",
"## Exercise #3: Using Word2vec with 150 English Novels\n",
"\n",
"In this exercise, we’ll use an English-language subset from a dataset\n",
"about novels created by [Andrew\n",
"Piper](https://www.mcgill.ca/langlitcultures/andrew-piper). Specifically\n",
"we’ll look at 150 novels by British and American authors spanning the\n",
"years 1771-1930. These texts reside on disk, each in a separate\n",
"plaintext file. Metadata is contained in a spreadsheet distributed with\n",
"the novel files.\n",
"\n",
"#### Metadata Columns\n",
"\n",
"
\n",
"\n",
"Workshop Run Here at Start\n",
"\n",
"``` r\n",
"# Load the required libraries\n",
"library(tidyverse)\n",
"library(repr)\n",
"library(proxy)\n",
"library(tm)\n",
"library(scales)\n",
"library(MASS)\n",
"\n",
"\n",
"# Set up figures to save properly\n",
"options(jupyter.plot_mimetypes = \"image/png\") \n",
"\n",
"# Time: 3 mins\n",
"# File paths and names\n",
"filelist <- c(\n",
" 'txtlab_Novel450_English/EN_1850_Hawthorne,Nathaniel_TheScarletLetter_Novel.txt',\n",
" 'txtlab_Novel450_English/EN_1851_Hawthorne,Nathaniel_TheHouseoftheSevenGables_Novel.txt',\n",
" 'txtlab_Novel450_English/EN_1920_Fitzgerald,FScott_ThisSideofParadise_Novel.txt',\n",
" 'txtlab_Novel450_English/EN_1922_Fitzgerald,FScott_TheBeautifulandtheDamned_Novel.txt',\n",
" 'txtlab_Novel450_English/EN_1811_Austen,Jane_SenseandSensibility_Novel.txt',\n",
" 'txtlab_Novel450_English/EN_1813_Austen,Jane_PrideandPrejudice_Novel.txt'\n",
")\n",
"\n",
"novel_names <- c(\n",
" 'Hawthorne: Scarlet Letter',\n",
" 'Hawthorne: Seven Gables',\n",
" 'Fitzgerald: This Side of Paradise',\n",
" 'Fitzgerald: Beautiful and the Damned',\n",
" 'Austen: Sense and Sensibility',\n",
" 'Austen: Pride and Prejudice'\n",
")\n",
"\n",
"# Function to read non-empty lines from the text file\n",
"readNonEmptyLines <- function(filepath) {\n",
" lines <- readLines(filepath, encoding = \"UTF-8\")\n",
" non_empty_lines <- lines[trimws(lines) != \"\"]\n",
" return(paste(non_empty_lines, collapse = \" \"))\n",
"}\n",
"\n",
"# Read non-empty texts into a corpus\n",
"text_corpus <- VCorpus(VectorSource(sapply(filelist, readNonEmptyLines)))\n",
"\n",
"# Preprocess the text data\n",
"text_corpus <- tm_map(text_corpus, content_transformer(tolower))\n",
"text_corpus <- tm_map(text_corpus, removePunctuation)\n",
"text_corpus <- tm_map(text_corpus, removeNumbers)\n",
"text_corpus <- tm_map(text_corpus, removeWords, stopwords(\"english\"))\n",
"text_corpus <- tm_map(text_corpus, stripWhitespace)\n",
"\n",
"## Time: 5 mins\n",
"# Create a custom control for DTM with binary term frequency\n",
"custom_control <- list(\n",
" tokenize = function(x) SentimentAnalysis::ngram_tokenize(x, ngmax = 1),\n",
" bounds = list(global = c(3, Inf)),\n",
" weighting = weightTf\n",
")\n",
"\n",
"# Convert the corpus to a DTM using custom control\n",
"dtm <- DocumentTermMatrix(text_corpus, control = custom_control)\n",
"\n",
"# Convert DTM to a binary data frame (0 or 1)\n",
"dtm_df_novel <- as.data.frame(as.matrix(dtm > 0))\n",
"colnames(dtm_df_novel) <- colnames(dtm)\n",
"\n",
"# Set row names to novel names\n",
"rownames(dtm_df_novel) <- novel_names\n",
"\n",
"# Print the resulting data frame\n",
"tail(dtm_df_novel)\n",
"```\n",
"\n",
"``` r\n",
"# Just as we did above with the small data frame, we'll find the cosine similarity for these texts\n",
"cos_sim_novel <- as.matrix(proxy::dist(dtm_df_novel, method = \"cosine\"))\n",
"\n",
"# Convert the cosine similarity matrix to a 2-dimensional array\n",
"n <- nrow(dtm_df_novel)\n",
"cos_sim_array <- matrix(1 - as.vector(as.matrix(cos_sim_novel)), n, n)\n",
"\n",
"# Round the cosine similarity matrix to two decimal places\n",
"cos_sim_novel_rounded <- round(cos_sim_array, 2)\n",
"\n",
"# Print the rounded cosine similarity matrix\n",
"print(cos_sim_novel_rounded)\n",
"```\n",
"\n",
"``` r\n",
"# Again, we'll make this a bit more readable\n",
"cos_df <- data.frame(cos_sim_novel_rounded, row.names = novel_names, check.names = FALSE)\n",
"\n",
"# Set column names to novel names\n",
"colnames(cos_df) <- novel_names\n",
"\n",
"# Print the DataFrame\n",
"head(cos_df)\n",
"```\n",
"\n",
"``` r\n",
"# Transform cosine similarity to cosine distance\n",
"cos_dist <- 1 - cos_sim_novel_rounded\n",
"\n",
"# Perform MDS\n",
"mds <- cmdscale(cos_dist, k = 2)\n",
"\n",
"# Extract x and y coordinates from MDS output\n",
"xs <- mds[, 1]\n",
"ys <- mds[, 2]\n",
"\n",
"# Create a data frame with x, y coordinates, and novel names\n",
"mds_df <- data.frame(x = xs, y = ys, novel_names = novel_names)\n",
"\n",
"ggplot(mds_df, aes(x, y, label = novel_names)) +\n",
" geom_point(size = 4) +\n",
" geom_text(hjust =0.6, vjust = 0.2, size = 4, angle = 45, nudge_y = 0.01) + # Rotate text and adjust y position\n",
" labs(title = \"MDS Visualization of Novel Differences\") +\n",
" theme_minimal() +\n",
" theme(\n",
" plot.title = element_text(size = 20, hjust = 0.6, margin = margin(b = 10)),\n",
" plot.margin = margin(5, 5, 5, 5, \"pt\"), # Adjust the margin around the plot\n",
" plot.background = element_rect(fill = \"white\"), # Set the background color of the plot to white\n",
" plot.caption = element_blank(), # Remove the default caption\n",
" axis.text = element_text(size = 12), # Adjust the size of axis text\n",
" legend.text = element_text(size = 12), # Adjust the size of legend text\n",
" legend.title = element_text(size = 14) # Adjust the size of legend title\n",
" )\n",
"```\n",
"\n",
"The above method has a broad range of applications, such as unsupervised\n",
"clustering. Common techniques include\n",
"K-Means\n",
"Clustering and\n",
"Hierarchical\n",
"Dendrograms. These attempt to identify groups of texts with shared\n",
"content, based on these kinds of distance measures.\n",
"\n",
"Here’s an example of a dendrogram based on these six novels:\n",
"\n",
"``` r\n",
"# Assuming you have already calculated the \"cos_dist\" matrix and have the \"novel_names\" vector\n",
"\n",
"# Perform hierarchical clustering\n",
"hclust_result <- hclust(as.dist(cos_dist), method = \"ward.D\")\n",
"\n",
"# Plot the dendrogram\n",
"plot(hclust_result, hang = -1, labels = novel_names)\n",
"\n",
"# Optional: Adjust the layout to avoid cutoff labels\n",
"par(mar = c(5, 4, 2, 10)) # Adjust margins\n",
"\n",
"# Display the dendrogram plot\n",
"```\n",
"\n",
"#### Vector Semantics\n",
"\n",
"We can also turn this logic on its head. Rather than produce vectors\n",
"representing texts based on their words, we will produce vectors for the\n",
"words based on their contexts.\n",
"\n",
"``` r\n",
"# Transpose the DTM data frame\n",
"transposed_dtm <- t(dtm_df_novel)\n",
"\n",
"# Display the first few rows of the transposed DTM\n",
"tail(transposed_dtm)\n",
"```\n",
"\n",
"Because the number of words is so large, for memory reasons we’re going\n",
"to work with just the last few, pictured above.\n",
"\n",
"- If you are running this locally, you may want to try this with more\n",
" words\n",
"\n",
"``` r\n",
"# Assuming dtm_df is a data frame containing the document-term matrix\n",
"tail_transposed_dtm <- tail(transposed_dtm)\n",
"\n",
"dtm_matrix <- as.matrix(tail_transposed_dtm) #remove 'tail_' to use all words\n",
"\n",
"# Calculate cosine similarity\n",
"cos_sim_words <- proxy::dist(dtm_matrix, method = \"cosine\")\n",
"\n",
"# Convert the cosine similarity matrix to a 2-dimensional array\n",
"n <- nrow(dtm_matrix)\n",
"cos_sim_words <- matrix(1 - as.vector(as.matrix(cos_sim_words)), n, n)\n",
"\n",
"# Print the result\n",
"head(cos_sim_words)\n",
"```\n",
"\n",
"``` r\n",
"# In readable format\n",
"\n",
"cos_sim_words <- data.frame(round(cos_sim_words, 2))\n",
"row.names(cos_sim_words) <- row.names(tail_transposed_dtm) #remove tail_ for all\n",
"colnames(cos_sim_words) <- row.names(tail_transposed_dtm) #remove tail_ for all\n",
"\n",
"head(cos_sim_words)\n",
"```\n",
"\n",
"Theoretically we could visualize and cluster these as well - but it\n",
"would a lot of computational power!\n",
"\n",
"We’ll instead turn to the machine learning version: word embeddings\n",
"\n",
"``` r\n",
"#check objects in memory; delete the big ones\n",
"\n",
"sort(sapply(ls(), function(x) format(object.size(get(x)), unit = 'auto')))\n",
" \n",
"rm(cos_sim_words, cos_sim_array, text_corpus, dtm_df_novel)\n",
" \n",
"sort(sapply(ls(), function(x) format(object.size(get(x)), unit = 'auto')))\n",
"```\n",
"\n",
"## Exercise #3: Using Word2vec with 150 English Novels\n",
"\n",
"In this exercise, we’ll use an English-language subset from a dataset\n",
"about novels created by [Andrew\n",
"Piper](https://www.mcgill.ca/langlitcultures/andrew-piper). Specifically\n",
"we’ll look at 150 novels by British and American authors spanning the\n",
"years 1771-1930. These texts reside on disk, each in a separate\n",
"plaintext file. Metadata is contained in a spreadsheet distributed with\n",
"the novel files.\n",
"\n",
"#### Metadata Columns\n",
"\n",
"