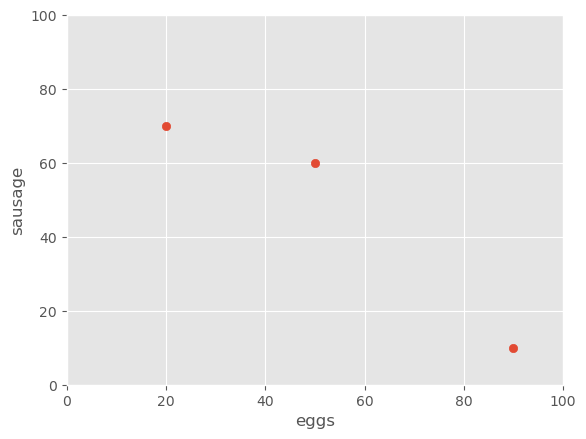
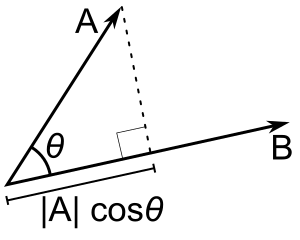
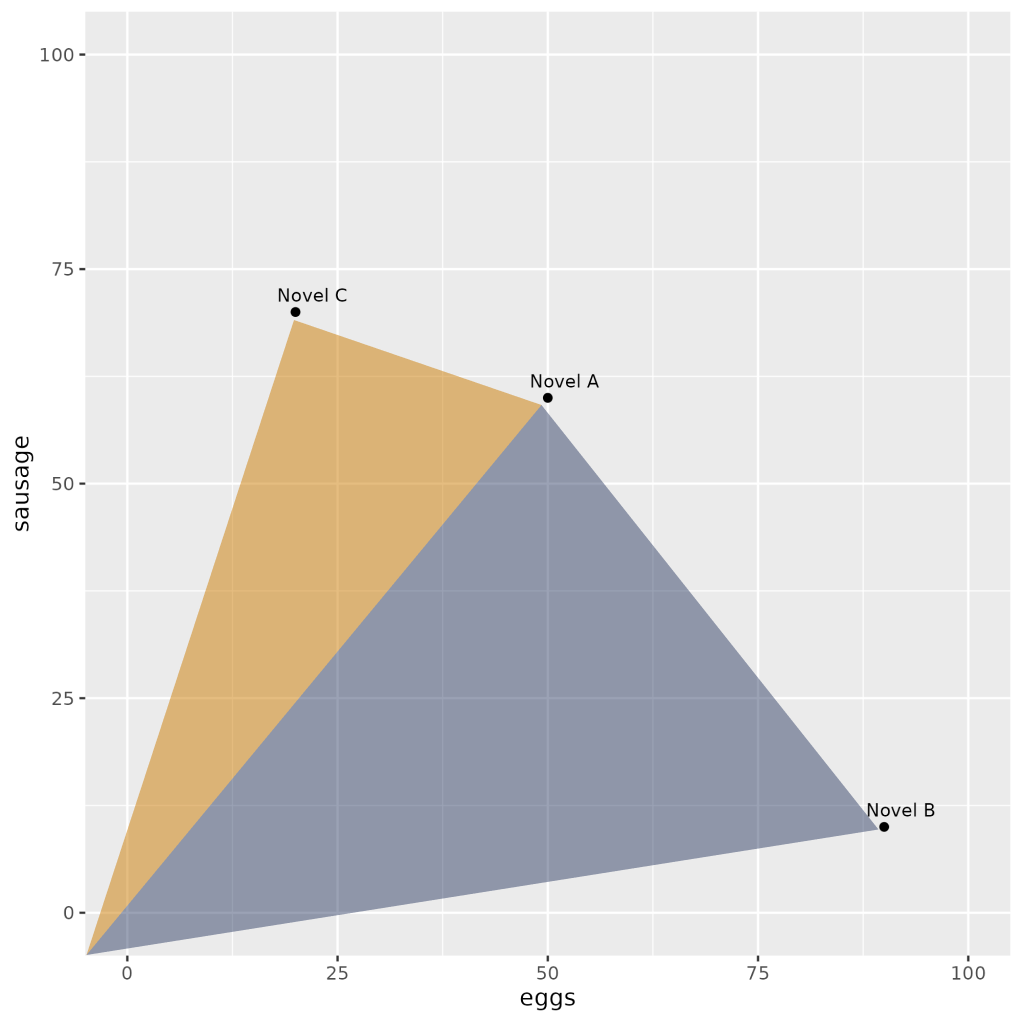
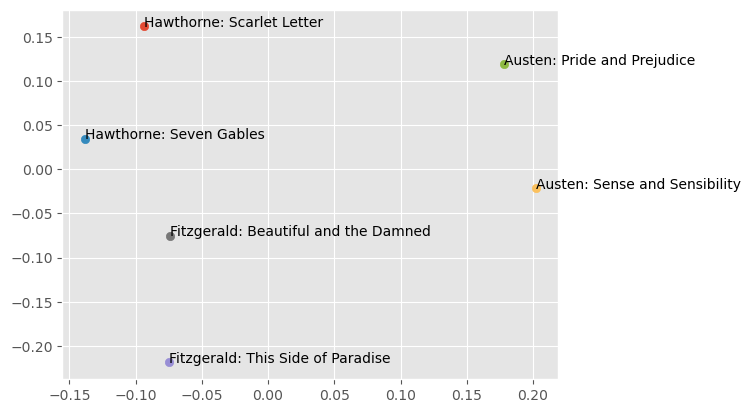
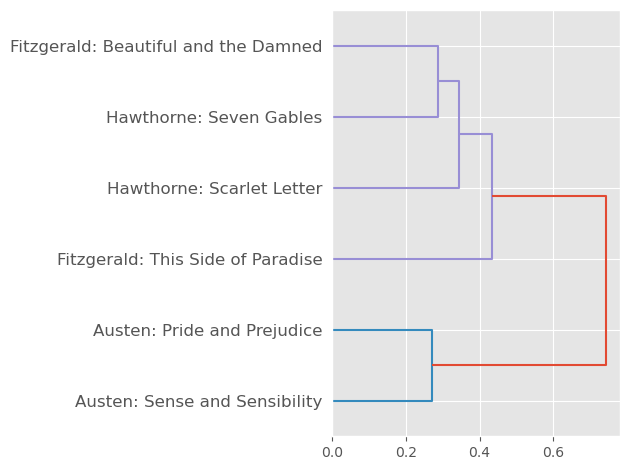
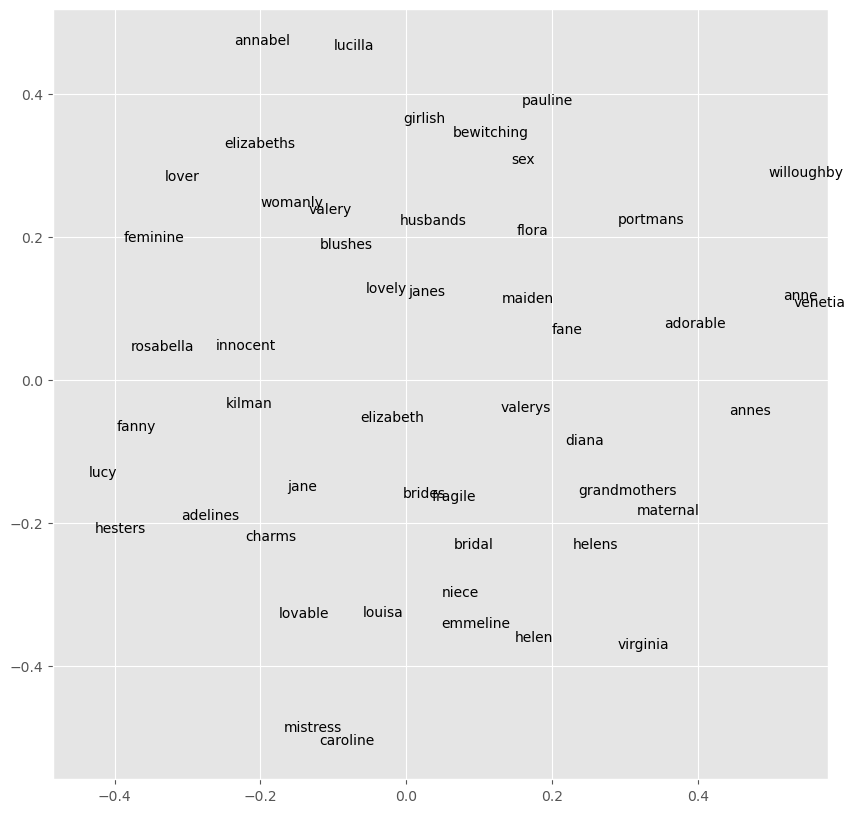
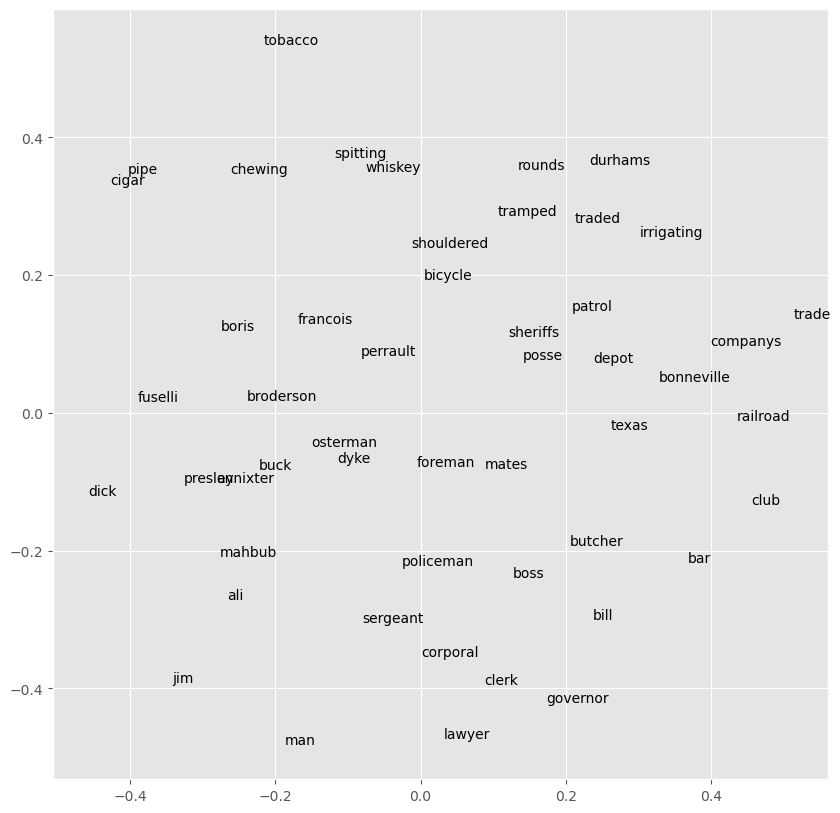
{'': 0,
'the': 1,
'and': 2,
'of': 3,
'to': 4,
'a': 5,
'i': 6,
'in': 7,
'was': 8,
'he': 9,
'that': 10,
'it': 11,
'her': 12,
'his': 13,
'you': 14,
'she': 15,
'had': 16,
'with': 17,
'as': 18,
'for': 19,
'not': 20,
'but': 21,
'at': 22,
'be': 23,
'is': 24,
'on': 25,
'him': 26,
'my': 27,
'have': 28,
'me': 29,
'said': 30,
'all': 31,
'which': 32,
'by': 33,
'so': 34,
'this': 35,
'from': 36,
'they': 37,
'were': 38,
'would': 39,
'no': 40,
'one': 41,
'if': 42,
'there': 43,
'what': 44,
'been': 45,
'an': 46,
'when': 47,
'or': 48,
'could': 49,
'who': 50,
'them': 51,
'do': 52,
'we': 53,
'their': 54,
'out': 55,
'up': 56,
'will': 57,
'are': 58,
'very': 59,
'now': 60,
'your': 61,
'more': 62,
'then': 63,
'mr': 64,
'little': 65,
'into': 66,
'about': 67,
'some': 68,
'like': 69,
'than': 70,
'did': 71,
'man': 72,
'time': 73,
'any': 74,
'know': 75,
'only': 76,
'see': 77,
'its': 78,
'never': 79,
'well': 80,
'should': 81,
'upon': 82,
'how': 83,
'has': 84,
'much': 85,
'such': 86,
'before': 87,
'mrs': 88,
'must': 89,
'over': 90,
'after': 91,
'own': 92,
'down': 93,
'come': 94,
'good': 95,
'think': 96,
'made': 97,
'can': 98,
'other': 99,
'go': 100,
'old': 101,
'say': 102,
'might': 103,
'am': 104,
'too': 105,
'again': 106,
'thought': 107,
'himself': 108,
'great': 109,
'way': 110,
'two': 111,
'dont': 112,
'came': 113,
'our': 114,
'long': 115,
'first': 116,
'here': 117,
'may': 118,
'day': 119,
'back': 120,
'us': 121,
'even': 122,
'eyes': 123,
'where': 124,
'life': 125,
'went': 126,
'miss': 127,
'make': 128,
'these': 129,
'just': 130,
'every': 131,
'away': 132,
'last': 133,
'shall': 134,
'hand': 135,
'young': 136,
'still': 137,
'yet': 138,
'most': 139,
'without': 140,
'though': 141,
'being': 142,
'nothing': 143,
'ever': 144,
'lady': 145,
'face': 146,
'looked': 147,
'seemed': 148,
'look': 149,
'through': 150,
'house': 151,
'tell': 152,
'those': 153,
'while': 154,
'herself': 155,
'always': 156,
'take': 157,
'once': 158,
'men': 159,
'father': 160,
'why': 161,
'mind': 162,
'let': 163,
'love': 164,
'off': 165,
'head': 166,
'saw': 167,
'get': 168,
'mother': 169,
'moment': 170,
'oh': 171,
'sir': 172,
'knew': 173,
'many': 174,
'room': 175,
'heart': 176,
'quite': 177,
'place': 178,
'poor': 179,
'something': 180,
'left': 181,
'right': 182,
'things': 183,
'felt': 184,
'going': 185,
'thing': 186,
'took': 187,
'people': 188,
'found': 189,
'heard': 190,
'dear': 191,
'put': 192,
'night': 193,
'better': 194,
'under': 195,
'another': 196,
'got': 197,
'yes': 198,
'give': 199,
'same': 200,
'home': 201,
'asked': 202,
'enough': 203,
'door': 204,
'told': 205,
'new': 206,
'done': 207,
'woman': 208,
'world': 209,
'because': 210,
'against': 211,
'voice': 212,
'myself': 213,
'rather': 214,
'want': 215,
'few': 216,
'between': 217,
'hands': 218,
'almost': 219,
'seen': 220,
'perhaps': 221,
'till': 222,
'however': 223,
'having': 224,
'morning': 225,
'turned': 226,
'far': 227,
'whom': 228,
'soon': 229,
'indeed': 230,
'course': 231,
'three': 232,
'round': 233,
'stood': 234,
'words': 235,
'ill': 236,
'side': 237,
'sure': 238,
'years': 239,
'im': 240,
'anything': 241,
'friend': 242,
'looking': 243,
'both': 244,
'began': 245,
'each': 246,
'whole': 247,
'hope': 248,
'part': 249,
'work': 250,
'kind': 251,
'find': 252,
'gave': 253,
'word': 254,
'days': 255,
'believe': 256,
'half': 257,
'sat': 258,
'since': 259,
'hear': 260,
'gone': 261,
'wife': 262,
'speak': 263,
'light': 264,
'name': 265,
'white': 266,
'nor': 267,
'answered': 268,
'cried': 269,
'lord': 270,
'really': 271,
'best': 272,
'next': 273,
'among': 274,
'end': 275,
'called': 276,
'wish': 277,
'girl': 278,
'o': 279,
'feel': 280,
'set': 281,
'together': 282,
'brought': 283,
'child': 284,
'full': 285,
'alone': 286,
'keep': 287,
'passed': 288,
'leave': 289,
'whose': 290,
'replied': 291,
'least': 292,
'money': 293,
'matter': 294,
'god': 295,
'air': 296,
'does': 297,
'often': 298,
'family': 299,
'cant': 300,
'talk': 301,
'evening': 302,
'help': 303,
'cannot': 304,
'manner': 305,
'less': 306,
'mean': 307,
'present': 308,
'hour': 309,
'letter': 310,
'towards': 311,
'friends': 312,
'taken': 313,
'rose': 314,
'feeling': 315,
'small': 316,
'boy': 317,
'business': 318,
'open': 319,
'coming': 320,
'care': 321,
'behind': 322,
'spoke': 323,
'read': 324,
'also': 325,
'john': 326,
'thou': 327,
'ask': 328,
'thats': 329,
'husband': 330,
'lay': 331,
'whether': 332,
'happy': 333,
'true': 334,
'children': 335,
'answer': 336,
'dark': 337,
'black': 338,
'call': 339,
'others': 340,
'rest': 341,
'along': 342,
'suppose': 343,
'given': 344,
'death': 345,
'suddenly': 346,
'near': 347,
'says': 348,
'women': 349,
'already': 350,
'hard': 351,
'sort': 352,
'returned': 353,
'certain': 354,
'within': 355,
'margaret': 356,
'chapter': 357,
'table': 358,
'used': 359,
'themselves': 360,
'everything': 361,
'else': 362,
'kept': 363,
'person': 364,
'high': 365,
'times': 366,
'sense': 367,
'ive': 368,
'fire': 369,
'either': 370,
'country': 371,
'large': 372,
'until': 373,
'making': 374,
'known': 375,
'certainly': 376,
'wanted': 377,
'held': 378,
'master': 379,
'power': 380,
'yourself': 381,
'strange': 382,
'lost': 383,
'wont': 384,
'sister': 385,
'remember': 386,
'street': 387,
'pretty': 388,
'nature': 389,
'feet': 390,
'continued': 391,
'idea': 392,
'itself': 393,
'strong': 394,
'question': 395,
'bed': 396,
'doubt': 397,
'live': 398,
'truth': 399,
'ought': 400,
'fear': 401,
'didnt': 402,
'case': 403,
'dead': 404,
'reason': 405,
'understand': 406,
'fell': 407,
'window': 408,
'arms': 409,
'possible': 410,
'short': 411,
'fact': 412,
'sometimes': 413,
'thus': 414,
'during': 415,
'saying': 416,
'son': 417,
'brother': 418,
'hair': 419,
'above': 420,
'eye': 421,
'return': 422,
'met': 423,
'soul': 424,
'walked': 425,
'silence': 426,
'daughter': 427,
'beautiful': 428,
'turn': 429,
'close': 430,
'fine': 431,
'aunt': 432,
'point': 433,
'gentleman': 434,
'added': 435,
'glad': 436,
'appeared': 437,
'water': 438,
'sight': 439,
'year': 440,
'tone': 441,
'exclaimed': 442,
'afraid': 443,
'subject': 444,
'arm': 445,
'bad': 446,
'low': 447,
'across': 448,
'hours': 449,
'means': 450,
'use': 451,
'became': 452,
'tom': 453,
'around': 454,
'state': 455,
'doing': 456,
'sent': 457,
'late': 458,
'ready': 459,
'tried': 460,
'taking': 461,
'thinking': 462,
'pleasure': 463,
'longer': 464,
'theres': 465,
'london': 466,
'red': 467,
'cold': 468,
'neither': 469,
'past': 470,
'change': 471,
'smile': 472,
'order': 473,
'followed': 474,
'town': 475,
'interest': 476,
'lips': 477,
'hes': 478,
'thee': 479,
'ye': 480,
'quiet': 481,
'ah': 482,
'hardly': 483,
'body': 484,
'become': 485,
'deep': 486,
'five': 487,
'need': 488,
'opened': 489,
'entered': 490,
'forward': 491,
'fellow': 492,
'spirit': 493,
'bring': 494,
'able': 495,
'deal': 496,
'four': 497,
'show': 498,
'sound': 499,
'hold': 500,
'walk': 501,
'thy': 502,
'loved': 503,
'therefore': 504,
'mine': 505,
'conversation': 506,
'minutes': 507,
'none': 508,
'ten': 509,
'party': 510,
'dinner': 511,
'tears': 512,
'road': 513,
'thoughts': 514,
'character': 515,
'hundred': 516,
'meet': 517,
'try': 518,
'silent': 519,
'girls': 520,
'trouble': 521,
'youre': 522,
'fathers': 523,
'received': 524,
'human': 525,
'fair': 526,
'ground': 527,
'beauty': 528,
'married': 529,
'general': 530,
'usual': 531,
'bear': 532,
'church': 533,
'different': 534,
'wonder': 535,
'second': 536,
'early': 537,
'laura': 538,
'feelings': 539,
'stand': 540,
'seeing': 541,
'book': 542,
'chair': 543,
'beyond': 544,
'real': 545,
'except': 546,
'talking': 547,
'length': 548,
'wrong': 549,
'seem': 550,
'week': 551,
'stay': 552,
'mary': 553,
'standing': 554,
'company': 555,
'seems': 556,
'thousand': 557,
'laid': 558,
'english': 559,
'chance': 560,
'de': 561,
'drew': 562,
'presence': 563,
'sitting': 564,
'nearly': 565,
'sleep': 566,
'several': 567,
'scarcely': 568,
'attention': 569,
'ran': 570,
'write': 571,
'horse': 572,
'ago': 573,
'whatever': 574,
'natural': 575,
'struck': 576,
'george': 577,
'doctor': 578,
'led': 579,
'clear': 580,
'ladies': 581,
'slowly': 582,
'account': 583,
'stopped': 584,
'living': 585,
'wild': 586,
'happened': 587,
'sit': 588,
'wished': 589,
'cause': 590,
'run': 591,
'wait': 592,
'earth': 593,
'dr': 594,
'story': 595,
'getting': 596,
'lived': 597,
'speaking': 598,
'edward': 599,
'knows': 600,
'please': 601,
'blue': 602,
'laughed': 603,
'afternoon': 604,
'uncle': 605,
'immediately': 606,
'reached': 607,
'comes': 608,
'duty': 609,
'mouth': 610,
'city': 611,
'free': 612,
'sudden': 613,
'heavy': 614,
'sun': 615,
'robert': 616,
'expression': 617,
'secret': 618,
'pay': 619,
'common': 620,
'sea': 621,
'impossible': 622,
'society': 623,
'turning': 624,
'purpose': 625,
'play': 626,
'save': 627,
'effect': 628,
'bright': 629,
'beside': 630,
'moved': 631,
'grey': 632,
'blood': 633,
'forth': 634,
'figure': 635,
'form': 636,
'hall': 637,
'sweet': 638,
'meant': 639,
'months': 640,
'heaven': 641,
'age': 642,
'sorry': 643,
'marry': 644,
'front': 645,
'appearance': 646,
'mothers': 647,
'wouldnt': 648,
'opinion': 649,
'position': 650,
'trust': 651,
'pale': 652,
'youth': 653,
'caught': 654,
'expected': 655,
'visit': 656,
'ones': 657,
'honour': 658,
'elizabeth': 659,
'happiness': 660,
'corner': 661,
'remained': 662,
'madame': 663,
'dress': 664,
'marriage': 665,
'instead': 666,
'big': 667,
'further': 668,
'thank': 669,
'captain': 670,
'waiting': 671,
'youll': 672,
'desire': 673,
'sake': 674,
'tomorrow': 675,
'carried': 676,
'grew': 677,
'broken': 678,
'view': 679,
'pass': 680,
'observed': 681,
'likely': 682,
'minute': 683,
'strength': 684,
'send': 685,
'cousin': 686,
'six': 687,
'pain': 688,
'cut': 689,
'england': 690,
'necessary': 691,
'st': 692,
'liked': 693,
'boys': 694,
'trying': 695,
'easy': 696,
'horses': 697,
'today': 698,
'mans': 699,
'besides': 700,
'although': 701,
'green': 702,
'scene': 703,
'bit': 704,
'act': 705,
'pleasant': 706,
'instant': 707,
'comfort': 708,
'circumstances': 709,
'books': 710,
'wind': 711,
'object': 712,
'rich': 713,
'forget': 714,
'leaving': 715,
'fancy': 716,
'step': 717,
'spoken': 718,
'king': 719,
'isnt': 720,
'line': 721,
'garden': 722,
'future': 723,
'perfectly': 724,
'probably': 725,
'started': 726,
'distance': 727,
'foot': 728,
'paper': 729,
'giving': 730,
'helen': 731,
'philip': 732,
'carriage': 733,
'charles': 734,
'laugh': 735,
'die': 736,
'talked': 737,
'shook': 738,
'couldnt': 739,
'river': 740,
'joy': 741,
'anxious': 742,
'amy': 743,
'watch': 744,
'worse': 745,
'fall': 746,
'art': 747,
'surely': 748,
'land': 749,
'countenance': 750,
'trees': 751,
'moments': 752,
'note': 753,
'looks': 754,
'occasion': 755,
'letters': 756,
'raised': 757,
'mere': 758,
'knowledge': 759,
'hat': 760,
'toward': 761,
'office': 762,
'floor': 763,
'pleased': 764,
'presently': 765,
'beginning': 766,
'soft': 767,
'showed': 768,
'makes': 769,
'smiled': 770,
'surprise': 771,
'smiling': 772,
'merely': 773,
'cry': 774,
'tea': 775,
'entirely': 776,
'repeated': 777,
'determined': 778,
'influence': 779,
'breath': 780,
'colonel': 781,
'shes': 782,
'music': 783,
'companion': 784,
'exactly': 785,
'changed': 786,
'sisters': 787,
'danger': 788,
'angry': 789,
'judge': 790,
'fixed': 791,
'worth': 792,
'died': 793,
'closed': 794,
'promise': 795,
'grave': 796,
'written': 797,
'creature': 798,
'prince': 799,
'id': 800,
'quick': 801,
'broke': 802,
'perfect': 803,
'shut': 804,
'public': 805,
'stop': 806,
'somewhat': 807,
'dare': 808,
'oclock': 809,
'service': 810,
'tonight': 811,
'watched': 812,
'affection': 813,
'particular': 814,
'terrible': 815,
'news': 816,
'quickly': 817,
'fanny': 818,
'guy': 819,
'later': 820,
'arrived': 821,
'glance': 822,
'phineas': 823,
'forgotten': 824,
'ears': 825,
'aware': 826,
'knowing': 827,
'reply': 828,
'threw': 829,
'straight': 830,
'youve': 831,
'private': 832,
'tired': 833,
'spite': 834,
'placed': 835,
'passion': 836,
'fresh': 837,
'laughing': 838,
'outside': 839,
'spirits': 840,
'school': 841,
'evil': 842,
'court': 843,
'peace': 844,
'force': 845,
'altogether': 846,
'follow': 847,
'remembered': 848,
'fast': 849,
'latter': 850,
'pity': 851,
'glass': 852,
'situation': 853,
'steps': 854,
'believed': 855,
'reading': 856,
'tall': 857,
'em': 858,
'paid': 859,
'wall': 860,
'notice': 861,
'seat': 862,
'pride': 863,
'especially': 864,
'filled': 865,
'fingers': 866,
'shoulder': 867,
'quietly': 868,
'noble': 869,
'nobody': 870,
'neck': 871,
'understood': 872,
'simple': 873,
'considered': 874,
'weeks': 875,
'french': 876,
'summer': 877,
'walking': 878,
'village': 879,
'speech': 880,
'yours': 881,
'opportunity': 882,
'aint': 883,
'hell': 884,
'afterwards': 885,
'touch': 886,
'gentlemen': 887,
'unless': 888,
'warm': 889,
'sky': 890,
'waited': 891,
'whispered': 892,
'beneath': 893,
'listened': 894,
'sad': 895,
'conduct': 896,
'obliged': 897,
'fortune': 898,
'gentle': 899,
'following': 900,
'twenty': 901,
'gold': 902,
'former': 903,
'surprised': 904,
'law': 905,
'watching': 906,
'pray': 907,
'allowed': 908,
'servant': 909,
'meeting': 910,
'listen': 911,
'grand': 912,
'below': 913,
'effort': 914,
'respect': 915,
'single': 916,
'everybody': 917,
'hung': 918,
'easily': 919,
'safe': 920,
'proud': 921,
'plain': 922,
'carry': 923,
'learned': 924,
'memory': 925,
'vain': 926,
'nice': 927,
'passing': 928,
'lucy': 929,
'handsome': 930,
'wrote': 931,
'acquaintance': 932,
'mamma': 933,
'picture': 934,
'darkness': 935,
'holding': 936,
'dropped': 937,
'breakfast': 938,
'opposite': 939,
'flowers': 940,
'begin': 941,
'simply': 942,
'ways': 943,
'settled': 944,
'train': 945,
'kindness': 946,
'duke': 947,
'honest': 948,
'anne': 949,
'fond': 950,
'offered': 951,
'expect': 952,
'confidence': 953,
'burst': 954,
'telling': 955,
'whats': 956,
'gate': 957,
'running': 958,
'henry': 959,
'fit': 960,
'hill': 961,
'conscious': 962,
'faith': 963,
'taste': 964,
'evidently': 965,
'difficulty': 966,
'lie': 967,
'putting': 968,
'touched': 969,
'stranger': 970,
'top': 971,
'sharp': 972,
'mistress': 973,
'bent': 974,
'experience': 975,
'serious': 976,
'lives': 977,
'fallen': 978,
'clothes': 979,
'break': 980,
'bound': 981,
'engaged': 982,
'windows': 983,
'supposed': 984,
'learn': 985,
'spent': 986,
'major': 987,
'brown': 988,
'hot': 989,
'regard': 990,
'offer': 991,
'eat': 992,
'drawingroom': 993,
'greater': 994,
'dog': 995,
'isabel': 996,
'paused': 997,
'rate': 998,
'piece': 999,
...}